





📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


概述
2022年,清华大学软件学院的学者提出了Autoformer:用于长期时间序列预测的自相关分解Transformer延长预测时间是实际应用的关键需求,如极端天气预警和长期能耗规划。本文研究了时间序列的长期预测问题。先前的基于 Transformer 的模型采用各种自注意力机制来发现长期依赖关系。然而,长期未来复杂的时间模式禁止模型找到可靠的依赖关系。本文通过对Transformer进行改进,通过序列分解和全新的自相关机制对时序数据进行建模,在各种公开的数据集上达到了很好的效果
代码转载自 Autoformer
一、论文思路
为了解决长期未来复杂的时间模式,作者将Autoformer作为分解体系结构,通过设计内部分解模块,使深度预测模型具有内在的渐进分解能力。同时作者提出了一种在序列级别上具有依赖关系发现和信息聚合的自相关机制。我们的机制超出了以前的自注意力家族,可以同时提高计算效率和信息利用率。
本文所涉及的所有资源的获取方式:这里
二、论文模型
作者改进了经典的Transformer模型,包括内部序列分解块、自相关机制以及相应的编码器和解码器。
(1).作者首先通过原数据减去池化平均项,获得分解项备用
(2).编码器,待训练的原始时序数据经过自相关机制,时序分解模块,前馈神经网络以及再一次时序分解模块获得编码器的结果,其中,从输入到第一个时序分解和从第一个时序分解模块到最后一个有一个残差连接。
(3).解码器,将(1)中获得的分解项和(2)的输出结果一并输入到解码器中,解码器会经过两次自相关机制和时序分解,在第二次自相关中会接受来自编码器的输出和自身模型前一个阶段的输出同时作为输入。最后经过前馈网络和序列分解。其中每一个序列分解都会加入原始的序列数据作为残差连接。
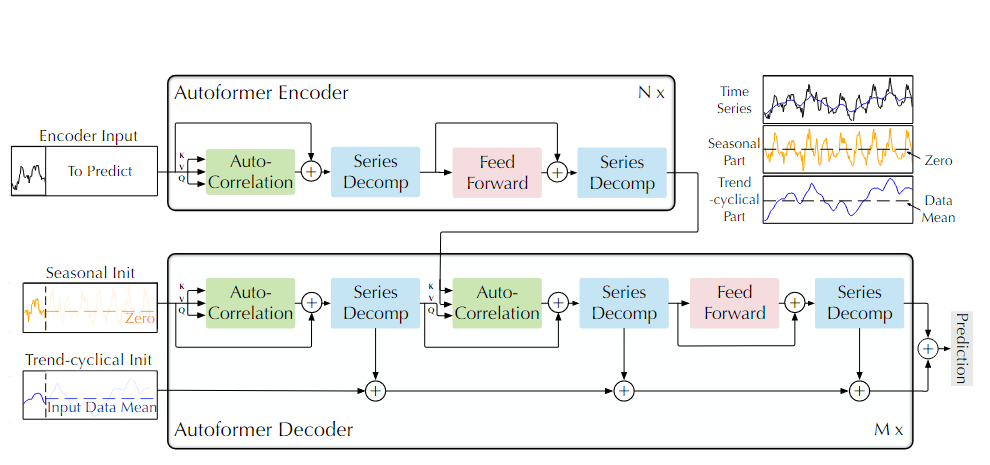
三、实现方法
1.TimesDecomp
主要是对原始项进行池化得到池化项,在相减获得剩余项,由此进行序列分解
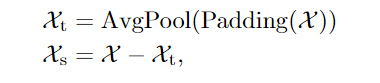
2Auto-Correlation
作者提出了具有串联连接的自相关机制来扩展信息利用率。自相关通过计算序列自相关来发现基于周期的依赖关系,并通过时间延迟聚合聚合相似的子序列。
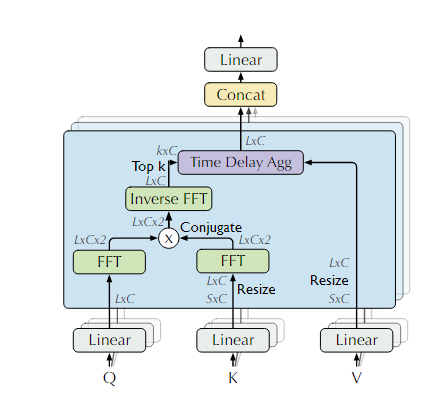
类似Transformer 输入的数据经过Linear层变换得到Query,Key,Value.不同于attention机制,Q,K经过快速傅里叶变换后 K经过共轭操作和Q相乘后,经过傅里叶反变换,和V做 time delay agg 操作。
3.time delay agg操作基于所选时间延迟τ1,···,τk对序列进行滚动。该操作可以对齐在估计周期的同一相位位置相似的子序列,这与自我注意家族中的逐点点积聚合不同。最后,我们通过 softmax 归一化置信度聚合子序列。
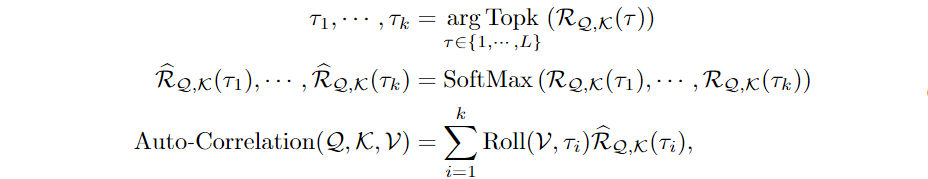
4.前馈网络(FFN):与前向传播类似,包含多层感知机(MLP)和归一化层(LN)。
损失函数:L1 loss 和 L2 loss,或二者结合。
四 复现论文
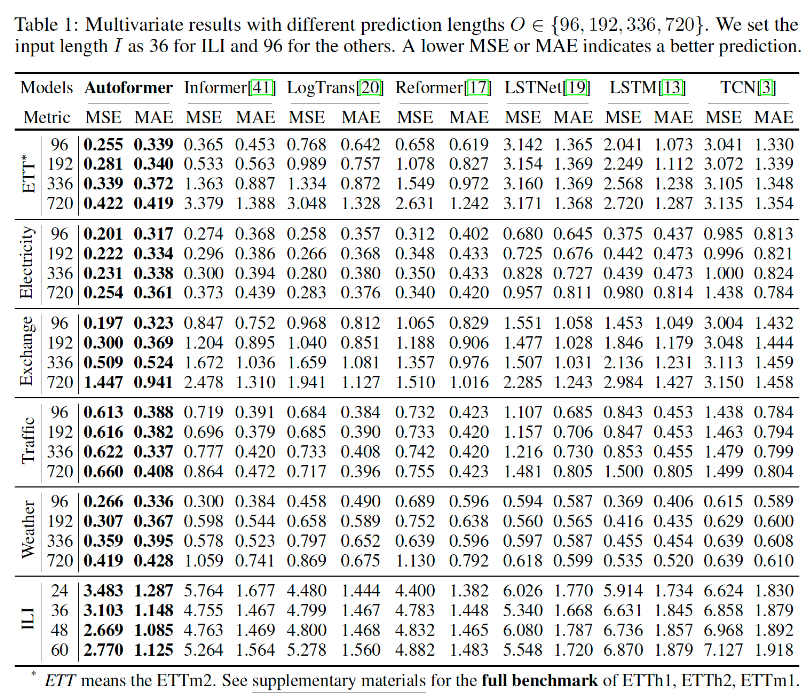
论文中的结果显示该模型的效果非常好。
使用方式
代码结构
总程序入口在 run.py,运行之前注意请新建一个 data的文件夹,把需要训练的数据放进文件夹中:
相关的数据位于
Google Drive中。注意科学上网。
附件中也包含数据。
作者准备了相关脚本,直接运行即可一键训练,开箱即用
bash ./scripts/ETT_script/Autoformer_ETTm1.sh
bash ./scripts/ECL_script/Autoformer.sh
bash ./scripts/Exchange_script/Autoformer.sh
bash ./scripts/Traffic_script/Autoformer.sh
bash ./scripts/Weather_script/Autoformer.sh
bash ./scripts/ILI_script/Autoformer.sh
注意如果需要使用论文以外的数据,请保证数据是csv格式,且在 data_provider/data_loader.py 中进行类的改写
如果不想采用脚本,可以通过以下命令启动程序:
python -u run.py \
--is_training 1 \ ##是否训练
--root_path ./dataset/ETT-small/ \ 数据集类型
--data_path ETTh1.csv \ ##数据文件
--model_id ETTh1_96_24 \ ##模型id
--model Autoformer \
--data ETTh1 \ ##数据类型
--features M \ ##数据特征维度
--seq_len 96 \ ##输入长度
--label_len 48 \ ##标签长度 该项不得高于 seq_len
--pred_len 24 \ ##预测长度
--e_layers 2 \ ## 编码器层数
--d_layers 1 \ ## 解码器层数
--factor 3 \
--enc_in 7 \ ## 编码器特征维度
--dec_in 7 \ ## 解码器特征维度
--c_out 7 \ ##输出维度
--des 'Exp' \
--itr 1 ## 训练epochs
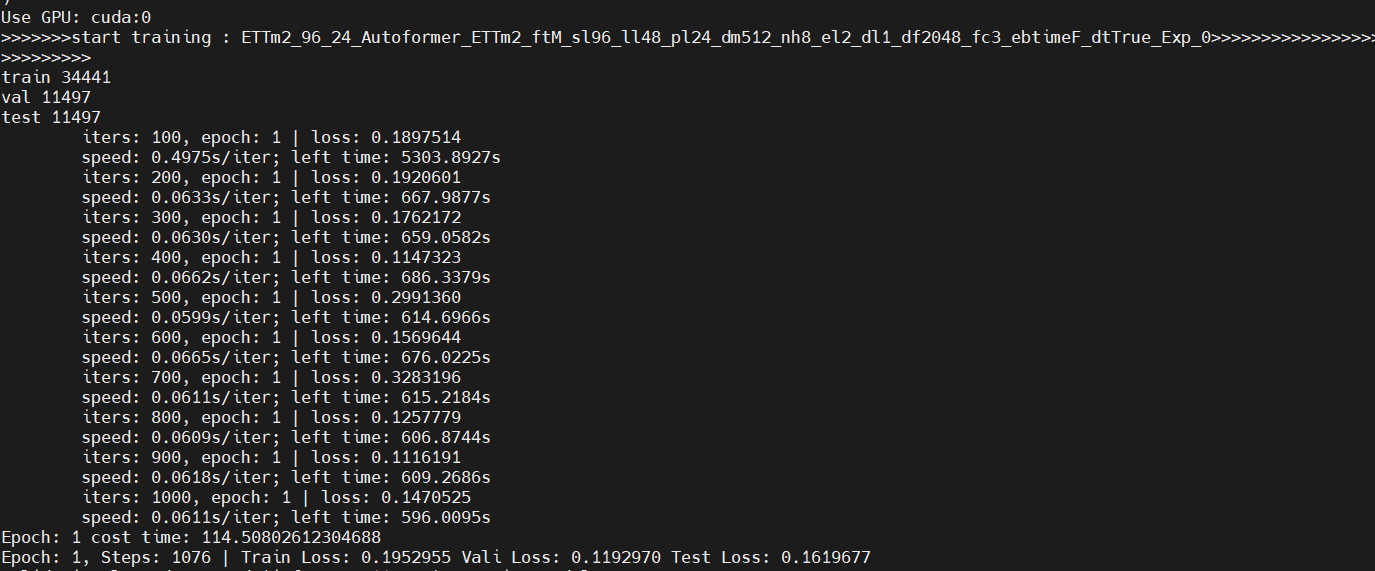
训练演示截图

训练结果,使用的ETTm2 数据集可以看到和论文中的数字相差不大
部署方式
Python 3.6, PyTorch 1.9.0. 相关库在requirements.txt中
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里

















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









