






Stable Diffusion 3.5 重磅登场,带来诸多惊喜!它最大的亮点之一便是免费可商用,这对于创作者和商业项目来说极具吸引力。
在与 Flux 的比较中,各有千秋。Stable Diffusion 3.5 凭借其成熟的技术体系,在图像生成质量上表现卓越。它能够根据输入的描述精准地生成细腻、逼真的图像,色彩还原度高,细节丰富。

本文不仅深入探讨其特性,还为您呈上详细的使用教程。通过 ComfyUI 工作流与整合包,即使是新手也能快速上手。从参数设置到模型导入,一步步引导您充分发挥 Stable Diffusion 3.5 的强大功能。无论是艺术创作、广告设计还是影视特效等领域,了解和掌握 Stable Diffusion 3.5 都将为您开启全新的创作之门,助力您在数字创作的世界里游刃有余,收获更多令人惊艳的成果。
目前SD3.5适配度最高的还是ComfyUI,还是推荐大家先把ComfyUI先下载好。
显卡方面推荐N卡,如果打算用Large的话最好是24GB以上的显存、Medium最少16GB、量化版Medium至少12GB。
而内存需求如果用原版T5文本编码器的话需要64GB,而量化版T5文本编码器则是至少32GB。

图片来源:Nenly同学
当然如果没能达到上述需求的配置也能运行模型,但可能生成速度会很慢,也可能爆显存导致系统报错等问题。如果以上配置需求达标的话就可以进行本地部署,如果不达标的话我会比较推荐进行云端部署“在线”的ComfyUI。
本地部署的话可以看我之前的这篇笔记:什么!还有高手?(AI绘画:ComfyUI的基本安装和使用)
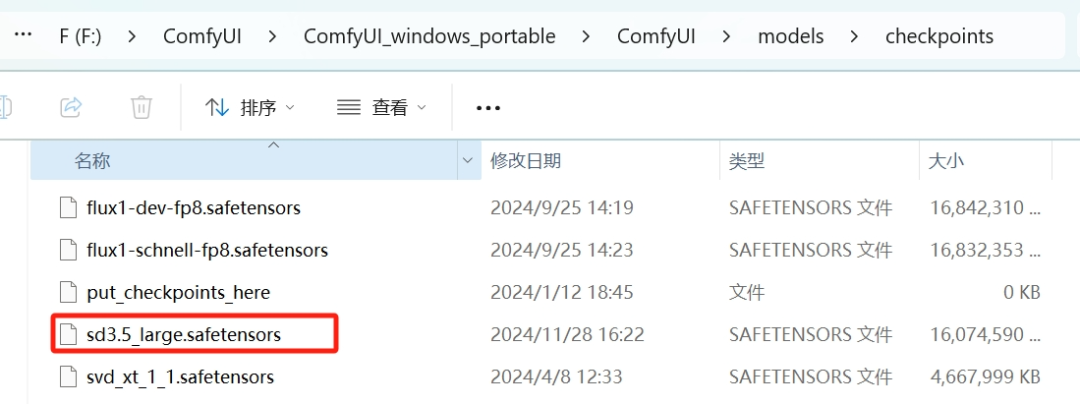
在昨天的笔记中下载好SD3.5基础模型本体之后,将其放在这个路径下方:
ComfyUI(根目录)/models/checkpoints
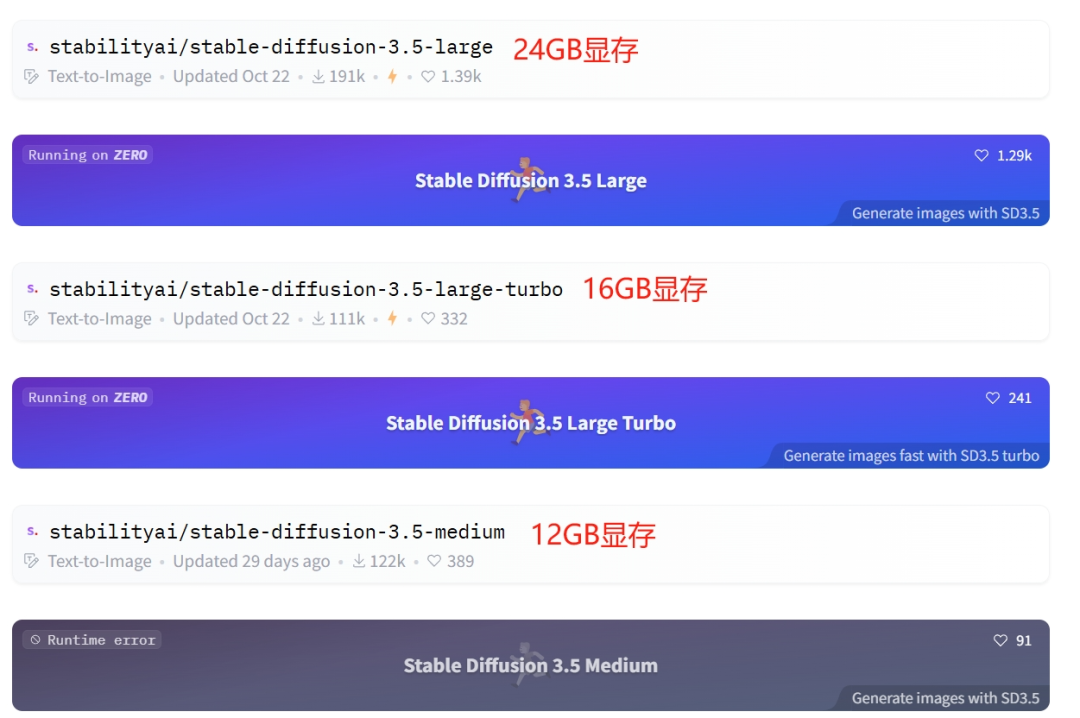
下载地址:https://huggingface.co/collections/stabilityai/stable-diffusion-35-671785cca799084f71fa2838
除了基础模型本体以外还需要下载文本编码器:
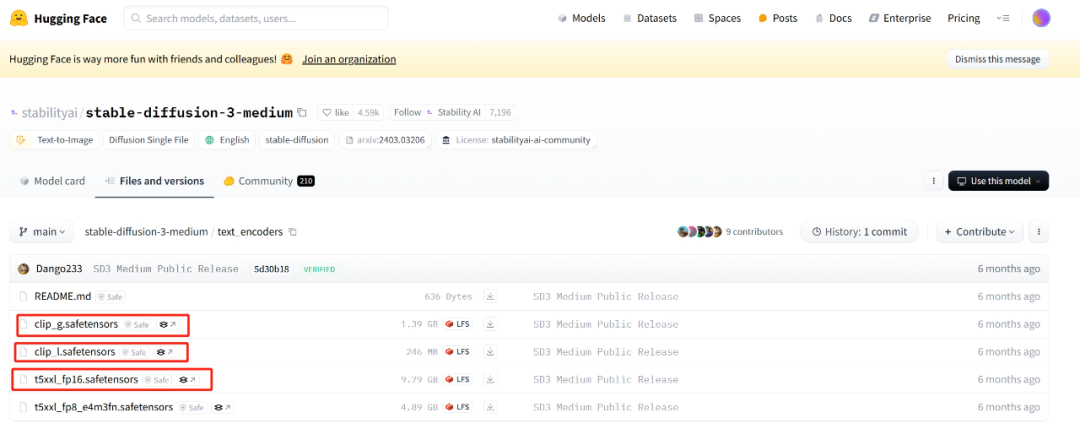
https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main/text_encoders
文件放置路径在这里:
**ComfyUI(根目录)/models/clip
**
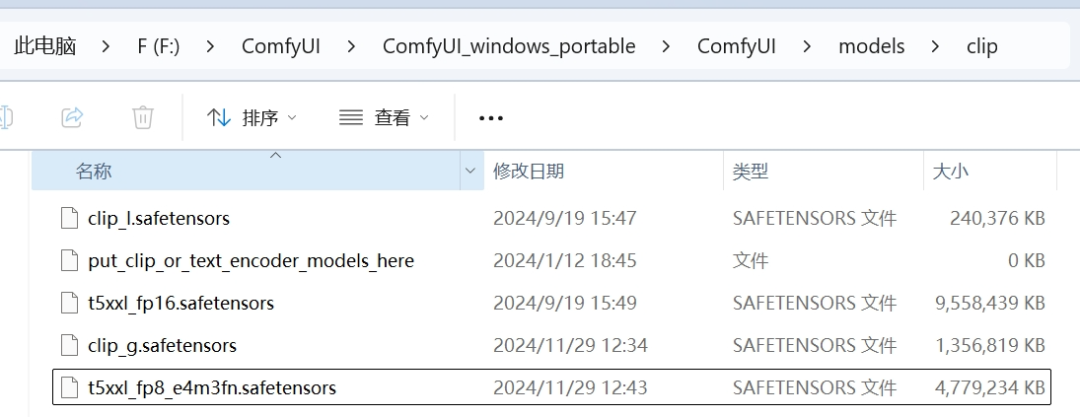
不过我这里要提一嘴,因为模型都是16GB起步需要下载的时间比较久,如果显存在8-16GB之间的小伙伴最好先用Medium模型试试,24GB的小伙伴就可以都下载了。
在准备好了这些之后启动ComfyUI,在网盘链接中也有工作流的下载,直接将工作流拖拽到ComfyUI中。
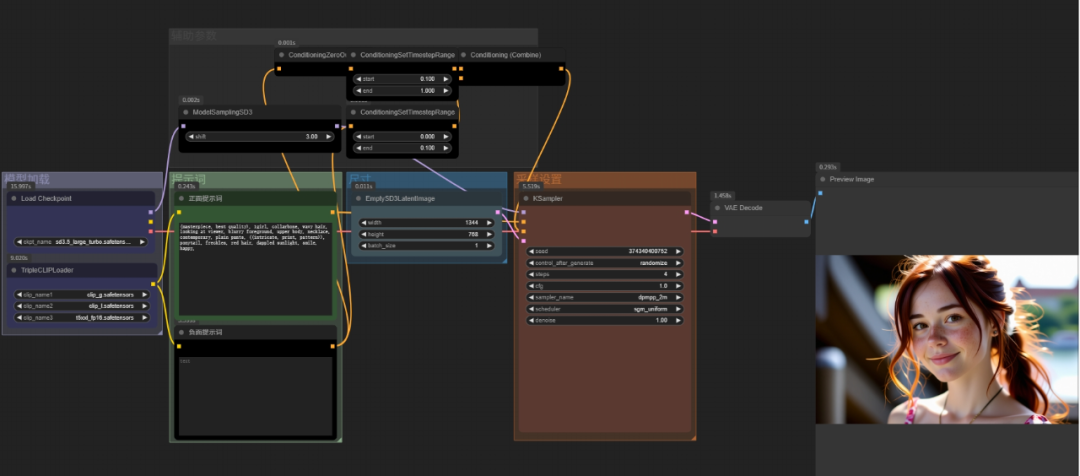
这里简单解析一下Large工作流的用法:
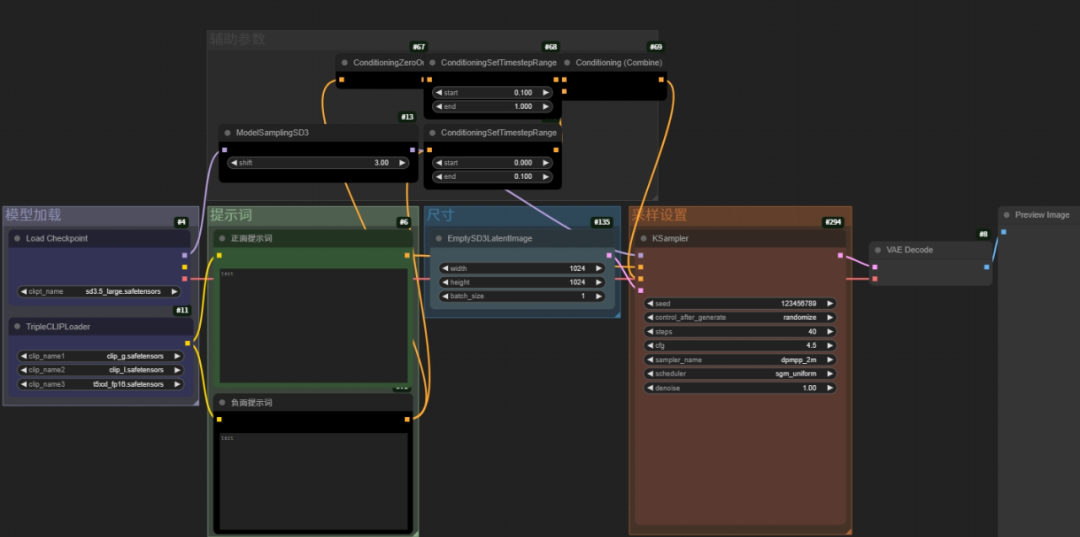
只需要四步操作:
第一步在最左侧的模型加载板块选择模型和CLIP
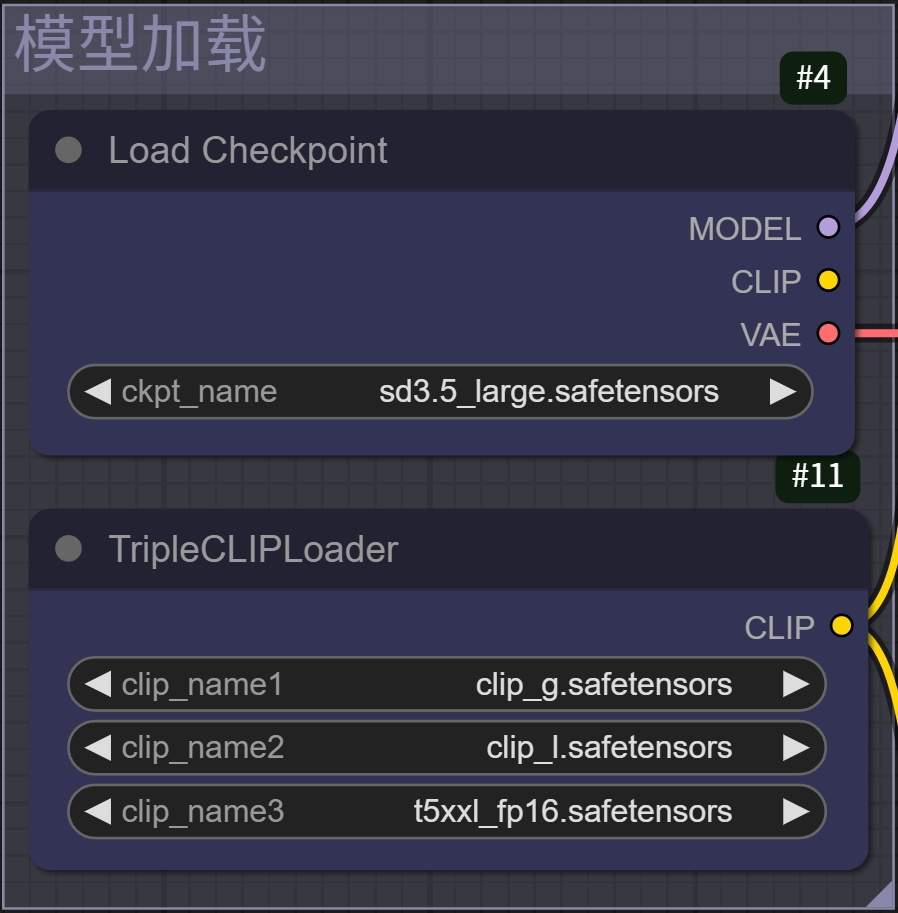
如果没有更改默认名称的话,现在是处于默认选中了的状态,保守起见还是手动再选择一次确保主要模型是sd3.5_large.safetensors
第二步,在右侧的提示词把板块用准确的语言描述想要生成的内容
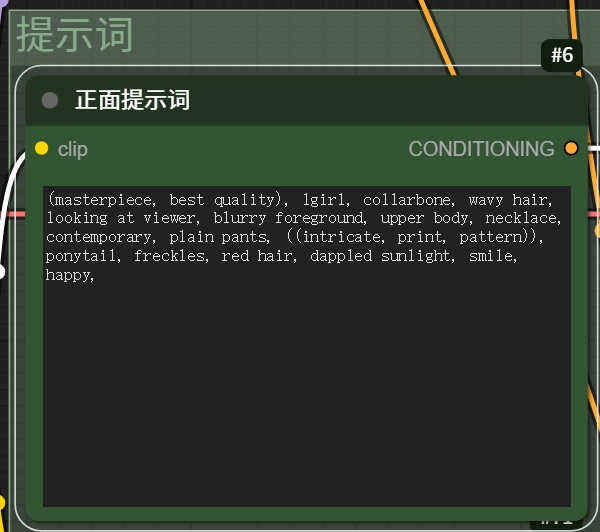
这里不太需要太多的修辞用自然语言即可,我是懒得写直接先抄一段提示词试试。
下面还有一个用于输入负面提示词的框,但是新版本的ComfyUI不需要专门输入一些诸如worst quality、ugly之类的
第三步,在尺寸板块中输入生成图像的尺寸。
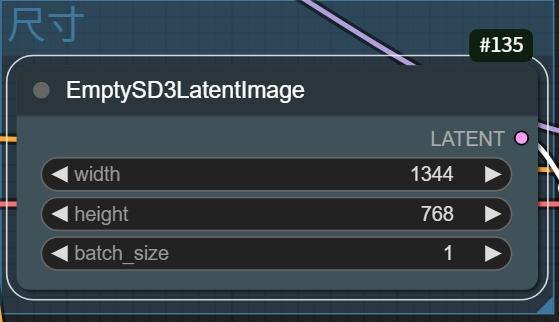
推荐输入的生成像素在100万像素左右,这里是尺寸参考:
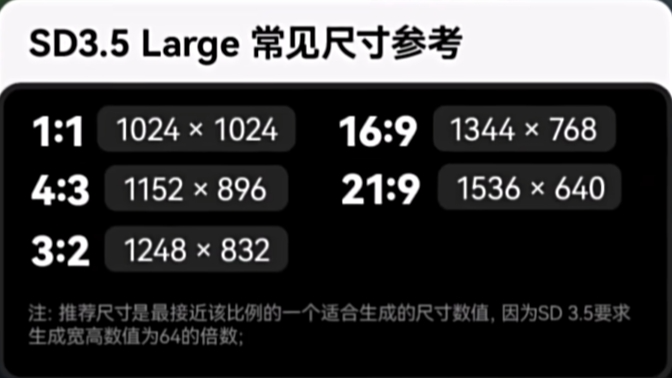
图片来源:Nenly同学
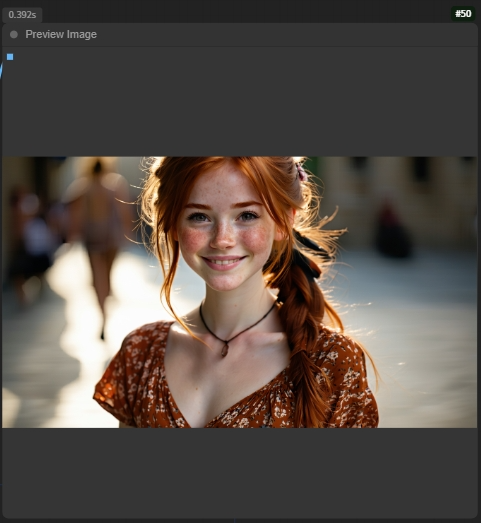
然后就可以点击生成了,等一会会在最右侧的预览图像窗口中生成图像:
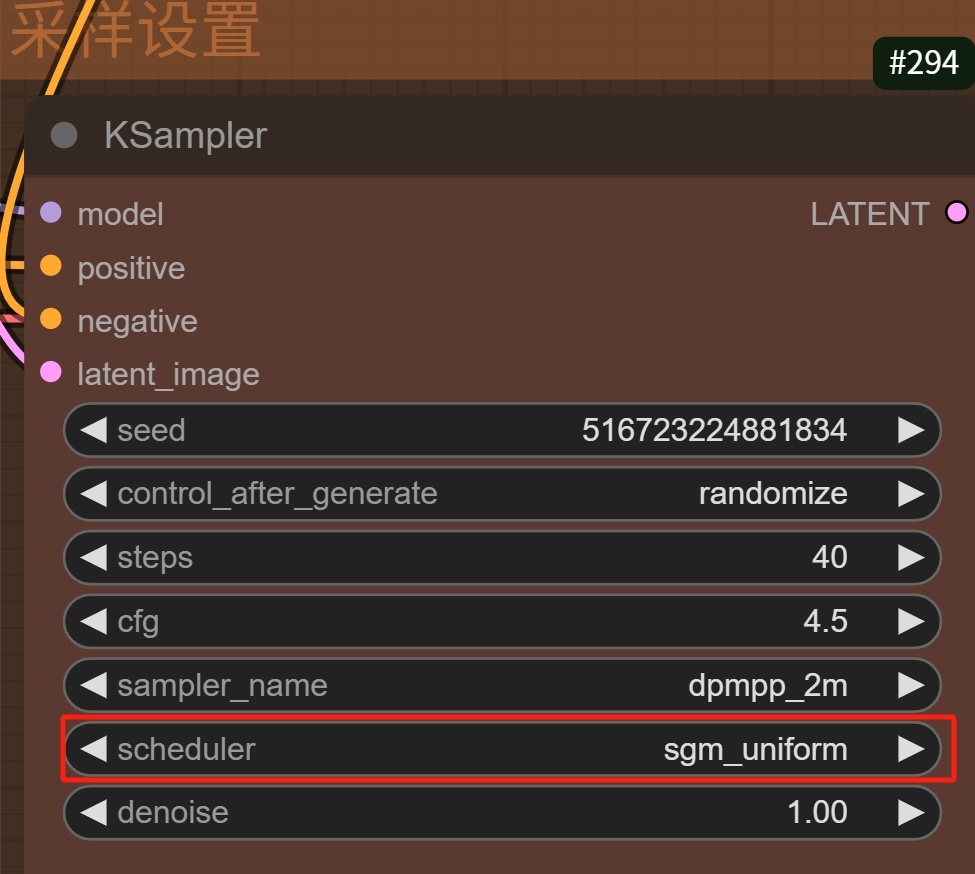
在采样的地方一般维持官方给的默认参数,如果要自己尝试的话可以更改采样器但是不要碰调度器。
在上方还有一些辅助参数,一般不需要更改
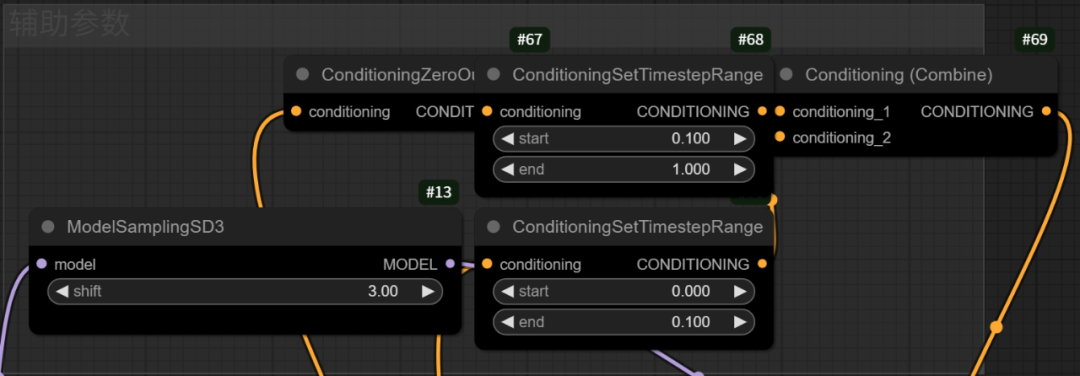
这里有个ModelSamplingSD(模型的采样偏移数值)是一个用于稳定高分辨率不下生成效果的因素。
其他的节点则是在利用负面条件清零机制(Conditioning Zero Out)影响负面提示词的作用,通过将清零后的条件作用在特定时间步数内(除去开头10%的其他步数)可以实现对图像生成的精细控制,同时避免它们影响过渡生成。
在掌握了简单的Large模型生成步骤之后,其他的两个生成流程其实是大差不差的,这个Large Turbo相当于是一个加速模型,生成的时间只需要Large模型的十分之一。
其实现加速的方式是缩短了采样所需的步数,整个流程的步骤和Large的一致,唯一不同的是采样参数里的步数。
常规模型需要20步以上来完成一张图片的生成,这里只需要4步,与此同时对应的CFG数值需要降低到1。
生成速度确实很快,不过在同一提示词下,原版Large模型的生成效果是明显要优于Turbo的。
不过要知道一点,Turbo是生成速度更快,但是比起原版的Large并不会降低配置占有,这个时候就是用到Medium模型的时候了。
Medium的参数量只有Large模型的30%左右,其工作流大部分地方和Large一样,不一样的只有CFG、零化的步骤分配。
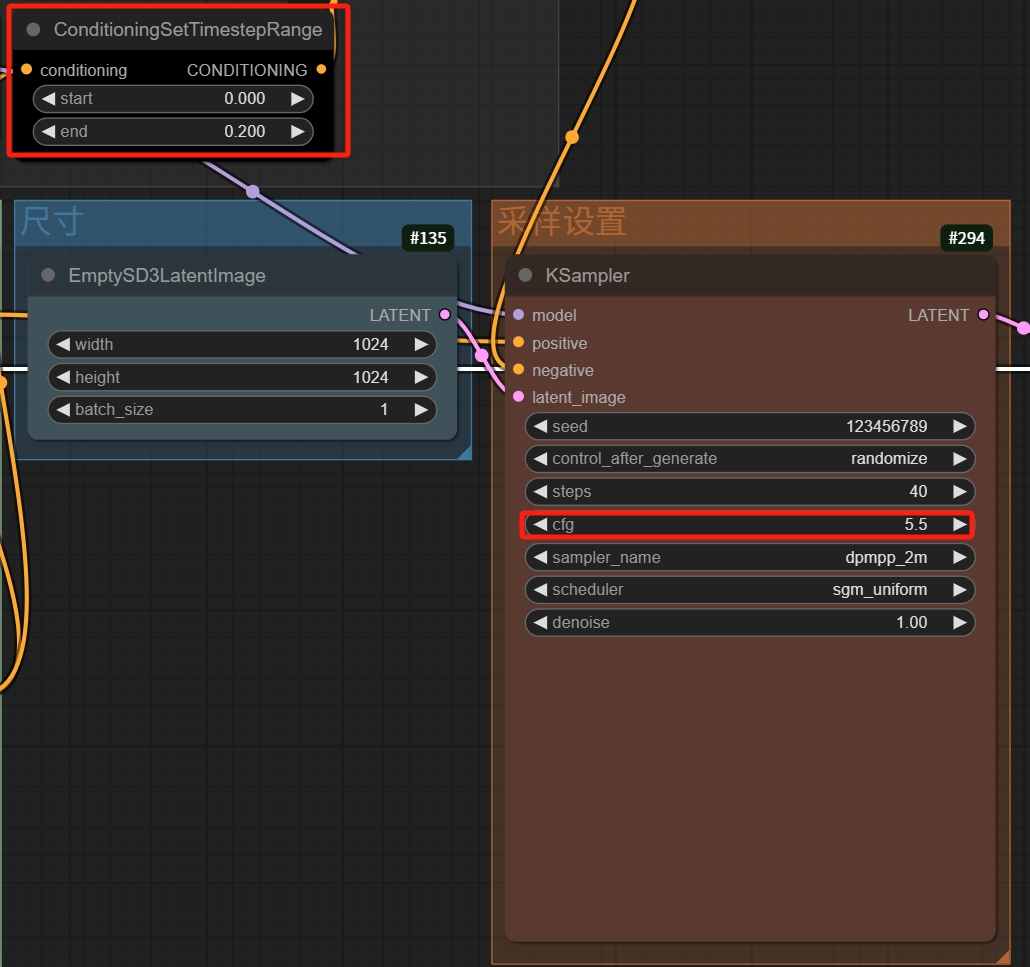
用Medium生成速度会非常快且占用显存很低
而实际生成效果呢?

好像还可以,不过根据一些原视频评论区的小伙伴和UP主有提到Medium的语义细节的实现上要比Large马虎一些。
但是转念一想这个Medium的训练量是和SDXL一个级别的,再加上低配置需求带来效率上的提升,这样一看Medium其实还不错。
Medium很适合去做各种风格类型的尝试,反复的快速抽卡能够让我更快得到想要的成品。
。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









