






1.二级指针:
二级指针就和套娃一样,假如我现在定义:
int a=3;
int* p=&a;
*p=20;这很好理解,我用指针变量p把a的地址存起来了,并且可以通过把地址解引用修改a的值。
那如果我这样写呢?
int a=3;
int* p=&a;
int** p2=&p;
**p2=20;上一篇博客就说过,存指针变量的空间和指针变量指向的空间是两个不同的空间。所以指针变量肯定有自己的地址。
在第三行我对指针变量取地址存到了p2里面。
此时p2就是我定义的二级指针。
然后我对p2(即p的地址)解引用(*)得到a的地址,然后再一次解引用(*)得到a的值,将它修改为20。
这里有一个误区,为什么我定义p2时用了2个 * ?仅仅只是代表它是个二级指针变量吗?
其实不是,这2个 * 有它们自己的含义。下面详细解释:
当我定义int*p时,int* 是它的类型,* 代表p是一个指针变量,int 代表这个指针要指向一个int 类型的变量。
同理,当我定义int** p2时,int** 是它的类型,此时第二个 * 代表p2是一个指针变量,而前面的 int* 代表它指向的是一个 int* 类型的指针变量。
2.指针数组:
听名字大概能猜到,这个数组里存的应该是指针。
下面尝试构建一个指针数组:
#include<stdio.h>
int main()
{
int a = 10, b = 20, c = 30;
int* arr[3] = { &a,&b,&c };
for (int i = 0;i < 3;i++)
{
printf("%d ", *(arr + i));
}
return 0;
}一运行吓一跳: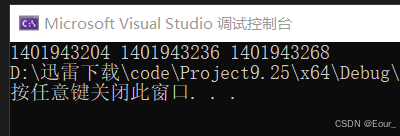
这输出的好像是地址?反正肯定不对。
分析一下:arr(数组名)代表首元素的地址,让它加 i 相当于跳到下一个元素,然后解引用就能找到每一个元素。但每一个元素又代表一个地址!所以要再次解引用。
#include<stdio.h>
int main()
{
int a = 10, b = 20, c = 30;
int* arr[3] = { &a,&b,&c };
for (int i = 0;i < 3;i++)
{
printf("%d ", *(*(arr + i)));
}
return 0;
}现在结果就正确了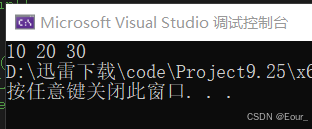
又因为:数组本质就是指针。
arr[i]=*(arr+i);
所以输出这一行也可以这样写:
printf("%d ", *(arr[i]));那指针数组可不可以是二维的呢?
当然可以,看下面的代码:
#include<stdio.h>
int main()
{
int arr1[4] = { 1,2,3,4 };
int arr2[4] = { 5,6,7,8 };
int arr3[4] = { 9,10,11,12 };
int* arr[3] = { arr1,arr2,arr3 };
int i = 0;
for (i = 0;i < 3;i++)
{
int j = 0;
for (j = 0;j < 4;j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}看一下运行结果: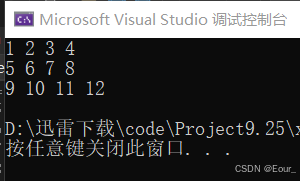
我确实输出了一个二维数组。
但这串代码里可能有几个让人疑惑的地方:
先看这个:
int* arr[3] = { arr1,arr2,arr3 };我在上面定义了三个int类型的数组,现在我把每个数组首元素的地址放到了指针数组arr里。(至于为什么只写数组名,那是因为数组名就代表首元素地址)
再来看这串代码:
int i = 0;
for (i = 0;i < 3;i++)
{
int j = 0;
for (j = 0;j < 4;j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}这里居然只用 arr[i][j] 就输出了每个元素,甚至都不需要解引用(*)。为什么?
i是0到3,代表遍历arr1,arr2,arr3这三个数组的首地址(即arr[0],arr[1]和arr[2])。
j是0到4,代表每获得一个数组首地址,就让这个地址(即指针)不断向后移动,遍历每一个元素的地址。
照这样分析,其实printf那一行应该写成这样:
printf("%d ", *(arr[i]+j));形式为 “(数组首元素地址+移动距离)再解引用”。
但咱们上面不是说了吗:arr[i]=*(arr+i);
把arr[i]当成arr(它们都代表首元素地址),j 当成 i (都代表指针移动距离),那就可以简化成这样:
printf("%d ", arr[i][j]);很奇妙吧~~
3.结构体的定义和初始化:
数组是一个集合,但它要求元素类型必须相等。
结构体也是一个集合,但它包含的元素可以是各种类型,甚至再包含一个结构体也是可以的。
看下面的代码:
#include<stdio.h>
struct stu //定义一个结构体
{
char name[20];
char tele[12];
char sex[5];
int height;
};
struct str
{
struct stu p;
int num;
float score;
};
int main()
{
struct stu p1 = { "hehe","17333997878","男",181 };//结构体变量初始化
//struct stu p1 = { 0 };//也可以这样初始化,后面再设值
struct str p2 = { {"haha","17334560987","女",170},100,78.9f};
printf("%s %s %s %d\n", p1.name, p1.tele, p1.sex, p1.height);
printf("%s %s %s %d %d %f\n", p2.p.name, p2.p.tele, p2.p.sex, p2.p.height, p2.num, p2.score);
return 0;
}有几个要注意的点:
struct str
{
struct stu p;
int num;
float score;
};我定义了一个新的结构体“struct str”,在这里面我又定义了一个结构体变量p(注意:这里必须是之前定义过的结构体,才可以创建结构体变量)。
在主函数中,我对struct str p2进行初始化时,用了两对花括号,原因就是p2中还包含着结构体变量p。
输出的时候也要注意:
"."左边是结构体变量名,右边是结构体成员。如:p1.name。
对于p2.p.name其实也好理解,p相当于是p2的成员,而name又是p的成员,所以用两个“.”。
试试自定义函数输出:
#include<stdio.h>
struct stu
{
char name[20];
char tele[12];
char sex[5];
int height;
};
void print(struct stu p)
{
printf("%s %s %s %d\n", p.name, p.tele, p.sex, p.height);
}
int main()
{
struct stu p1 = { "hehe","17333997878","男",181 };
printf("%s %s %s %d\n", p1.name, p1.tele, p1.sex, p1.height);
print(p1);
return 0;
}注意在自定义函数中一定要把形参的类型写清楚,比如p1是一个结构体变量, 在函数后面就应该写“struct stu p”。
在这里实际上传的是值,是p1里面存的name,tele....。所以print函数会自己再向内存申请一块空间去存放这些数据。
其实这是很浪费空间的,把地址传到函数中是更好的选择。
既然传的是地址,就应该用指针来接收。代码如下:
#include<stdio.h>
struct stu
{
char name[20];
char tele[12];
char sex[5];
int height;
};
void print(struct stu* p)
{
printf("%s %s %s %d", (*p).name, (*p).tele, (*p).sex, (*p).height);
}
int main()
{
struct stu p1 = { "hehe","17333997878","男",181 };
printf("%s %s %s %d\n", p1.name, p1.tele, p1.sex, p1.height);
print(&p1);
return 0;
}函数中printf那一行其实还有另一种写法:
printf("%s %s %s %d", p->name, p->tele, p->sex, p->height);当结构体变量是指针的时候(上面的p就是指针),“.”和"->"均可使用。
4.float = 3.14 和float = 3.14f 的区别:
其实凡是带小数点的数,在内存中都是被当成double(双精度)类型的,在后面加上 f 相当于强制性让3.14变成单精度。
5.逗号表达式的优先级是很低的,一般情况下都是最后再看它。
6.求一个数补码中 1 的个数:
这个题我在之前的博客中已经写过了,当时是这样写的:
#include<stdio.h>
int main()
{
int n = 0, count = 0;
scanf("%d", &n);
for (int i = 0;i < 32;i++)
{
if (n & 1 == 1) count++;
n >>= 1;
}
printf("%d", count);
return 0;
}利用按位与操作符(&)的性质,不断地让每一位来到最后一位按位与1。
这次再补充两种新方法:
方法一:
现在有一个整数:15,它在内存中存储的二进制码为1111。
我们进行这样的操作:
15%2=1;15/2=7(整数除法);
7%2=1;7/2=3;
3%2=1;3/2=1;
1%2=1;1/2=0;
可以发现,15的补码中的1都被我们算出来了。实际上,这也是十进制转二进制的方法。
用代码表示如下:
#include<stdio.h>
int find(int n)
{
int count = 0;
while (n)
{
if (n % 2 == 1) count++; //如果这一位是 1,就让计数器++。
n /= 2;
}
return count;
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = find(n);
printf("%d", ret);
return 0;
}测试发现,它对负数不能正确求解。其实也好理解,毕竟正数的原 反 补码相同,而负数不是这样,它需要通过转换。
但这并不意味着这串代码没用了。实际上,只要稍微修改一下就好了:
int find(unsigned int n) //无符号整数
{
int count = 0;
while (n)
{
if (n % 2 == 1) count++; //如果这一位是 1,就让计数器++。
n /= 2;
}
return count;
}现在正负数通用了。
当我把形参改成无符号整数时,它就默认传过来的是正数了,-1的补码是32个1,函数会把它当成一个特别大的正数处理。
方法二:
这次还是要用到按位与操作符(&)
还拿15举例子,它的补码是1111。现在把它减1,得到:1110
1111&1110=1110,把1110再减1,得到1101
1110&1101=1100,把1100再减1,得到1011
1100&1011=1000。
到这里就发现规律了吧,我每次减1后按位与都会“消去一个1”。
直到没有1时,它会变成0。
代码如下:
#include<stdio.h>
int main()
{
int n = 0, count = 0;
scanf("%d", &n);
while (n) //直到n的补码里没有1,n变成0,循环停止
{
n = n & (n - 1);
count++; //每进行一次循环,就让计数器++。
}
printf("%d", count);
return 0;
}"n & (n - 1)"可不止这一个用途!
它还可以用来判断一个数是不是2的n次方:
一个数(比如a)如果是2的n次方,那它的补码一定只有一个1。而n & (n - 1)会消去一个1。也就是说:如果a & (a - 1)=0,a一定是2的n次方。
7.求两个数补码中有几个不同的二进制位:
显然,这也要用到位运算。代码如下:
#include<stdio.h>
int main()
{
int a, b, count = 0;
scanf("%d %d", &a, &b);
for (int i = 0;i < 32;i++)
{
if ((a & 1) != (b & 1)) count++;
a >>= 1;b >>= 1;
}
printf("%d", count);
return 0;
}利用右移操作符一位一位的按位与,再比较是否相等就好了。
8.如果a是数组名,puts(a)就可以直接输出整个数组了。

















 6198
6198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









