




 博主接触计算机专业后对机器学习感兴趣,决定学习西瓜书。文中介绍了机器学习的定义,阐述了数据集、样本、特征等基本术语,还提及假设空间、归纳偏好等概念,如奥卡姆剃刀原则、“没有免费的午餐”定理,最后提到了机器学习的发展历程。
博主接触计算机专业后对机器学习感兴趣,决定学习西瓜书。文中介绍了机器学习的定义,阐述了数据集、样本、特征等基本术语,还提及假设空间、归纳偏好等概念,如奥卡姆剃刀原则、“没有免费的午餐”定理,最后提到了机器学习的发展历程。
第一章 绪论
1.1引言
接触计算机专业有一段时间后,我发现了自己对机器学习深感兴趣,决定学有余力之时,对机器学习的入门之作的西瓜书进行学习,希望自己能够静下心来,慢慢将书中知识点吃透,对机器学习有更深的理解。我资历尚浅,希望有看到笔记的大神们能多多指教。
机器学习正是这样的一门学科,致力于研究如何通过计算的手段,利用经验来改善系统自身的性能,人的“经验”对应计算机中的“数据”,让计算机来学习这些经验数据,生成一个算法模型,在面对新的情况中,计算机便能作出有效的判断,这便是机器学习。
1.2基本术语
-
所有记录的集合为:数据集。
-
每一条记录为:一个实例(instance)或样本(sample)。
例如:西瓜的色泽或敲声,单个的特点为特征(feature)或属性(attribute)。
对于一条记录,如果在坐标轴上表示,每个西瓜都可以用坐标轴中的一个点表示,一个点也是一个向量,例如(青绿,蜷缩,浊响),即每个西瓜为:一个特征向量(feature vector)。
-
一个样本的特征数为:维数(dimensionality),当维数非常大时,也就是现在说的“维数灾难”。
-
计算机程序学习经验数据生成算法模型的过程中,每一条记录称为一个“训练样本”,同时在训练好模型后,我们希望使用新的样本来测试模型的效果,则每一个新的样本称为一个“测试样本”。
-
所有训练样本的集合为:训练集(trainning set)——特殊。
-
所有测试样本的集合为:测试集(test set)——一般。
-
机器学习出来的模型适用于新样本的能力称为:泛化能力(generalization),即从特殊到一般。
-
预测值为离散值的问题为:分类(classification)。
-
预测值为连续值的问题为:回归(regression)。
-
将目标数据集分为若干个互不相交的样本簇: 聚类(clustering)
-
训练数据有标记信息的学习任务为:监督学习(supervised learning),分类和回归都是监督学习的范畴。
-
训练数据没有标记信息的学习任务为:无监督学习(unsupervised learning),常见的有聚类和关联规则。
-
学得模型适用于新样本的能力为:泛化能力(generalization),具有强泛化能力的模型能很好的适用于整个样本空间,希望模型能很好地反应出样本空间的特性。
1.3假设空间
归纳和演绎是科学推理的两大基本手段。
-
归纳:具体事实 -->一般性规律
-
演绎:原理--> 具体状况
概念学习:狭义的归纳学习要求从训练数据中学得概念(concept)
假设空间:把学习过程看作为一个在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集“匹配”的假设; 在这个假设空间中,可能有多个假设和训练集一致,我们称之为“版本空间”
1.4归纳偏好
归纳偏好:机器学习算法在学习过程中对某种类型假设的偏好。(理解:感觉就是不同的属性所对应的权重不同,不同影响因素的影响能力不同)
-
奥卡姆剃刀:是一种常用的、自然科学研究中最基本的原则,即“若有多个假设与观察一致,选最简单的那个”。
-
“没有免费的午餐”定理(No Free Lunch Theorem):
可以看出无论算法有多聪明,最后的期望性能竟然相同,但是别慌:NFL免费的午餐定理的前提条件是所有问题同等重要,所以说什么都要联系实际,实践是真理的唯一标准。
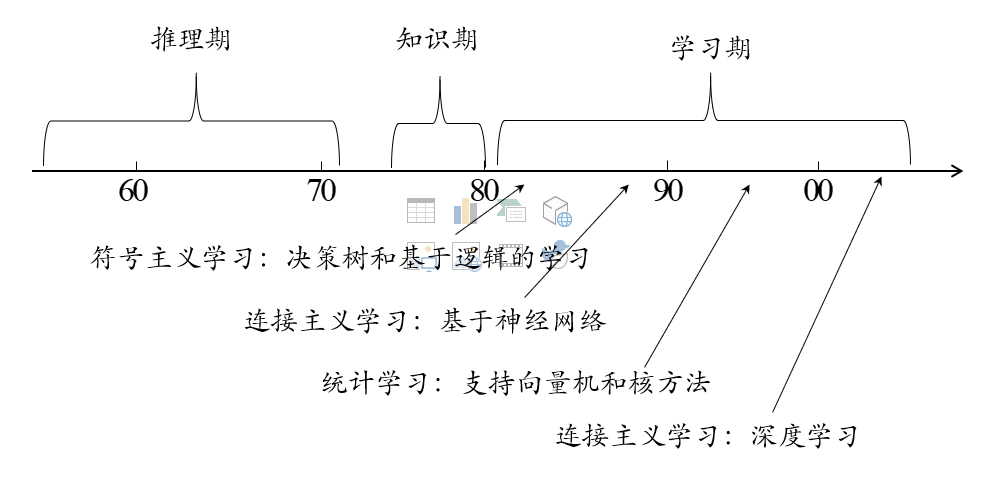
1.5发展历程

















 3052
3052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









