




1.基本文本卷积
- For more information refer to:
Kim 2014
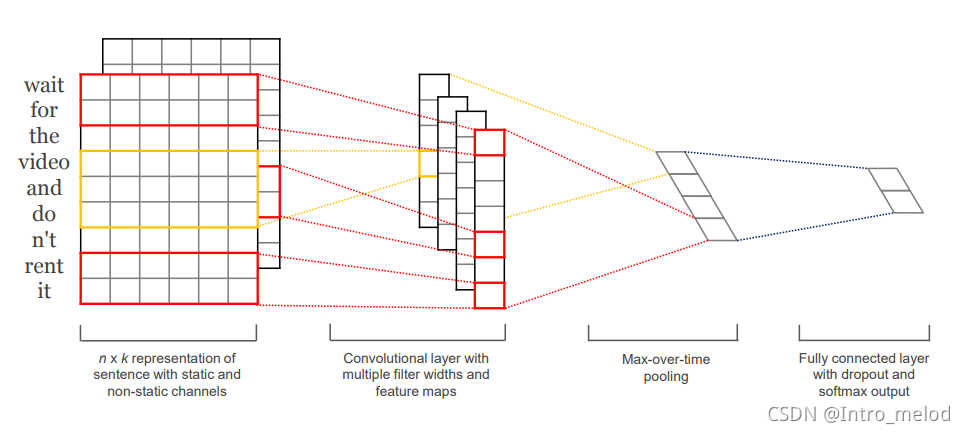
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.preprocessing.sequence import pad_sequences
num_features = 3000
sequence_length = 300
embedding_dimension = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=num_features)

x_train = pad_sequences(x_train, maxlen=sequence_length)
x_test = pad_sequences(x_test, maxlen=sequence_length)
print(x_train.shape)#(25000, 300)
print(x_test.shape)#(25000, 300)
print(y_train.shape)#(25000,)
print(y_test.shape)#(25000,)
2.构造基本句子分类器
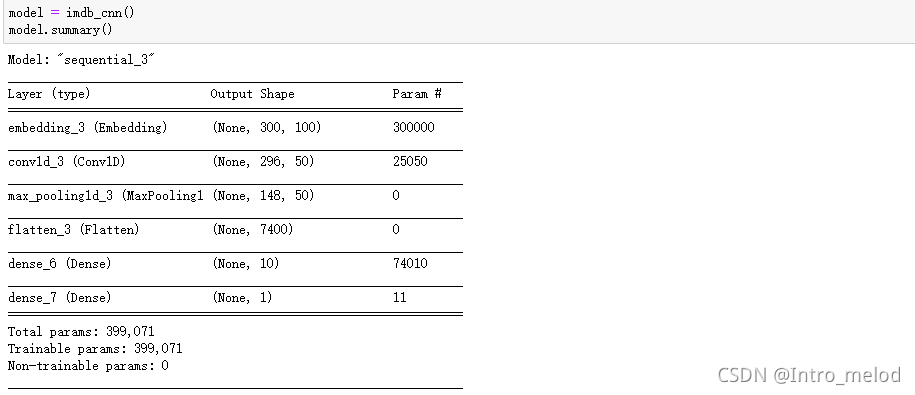
def imdb_cnn():
model=keras.Sequential([
layers.Embedding(input_dim=num_features,output_dim=embedding_dimension,input_length=sequence_length),
layers.Conv1D(filters=50,kernel_size=5,strides=1,padding='valid'),#卷积
layers.MaxPool1D(2,padding='valid'),#池化
layers.Flatten(),#全连接
layers.Dense(10,activation='relu'),
layers.Dense(1,activation='sigmoid')#2分类分类层
])
#模型配置
model.compile(optimizer=keras.optimizers.Adam(1e-3),
loss=keras.losses.BinaryCrossentropy(),
metrics=['accuracy'])
return model
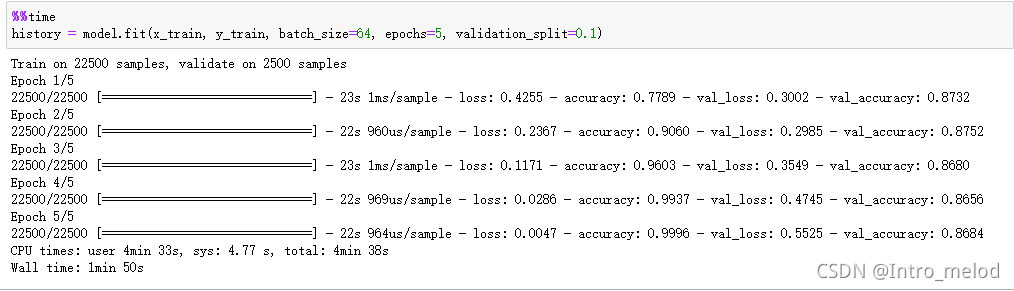
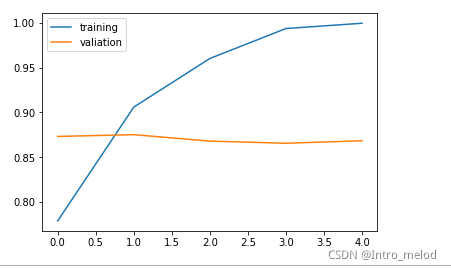
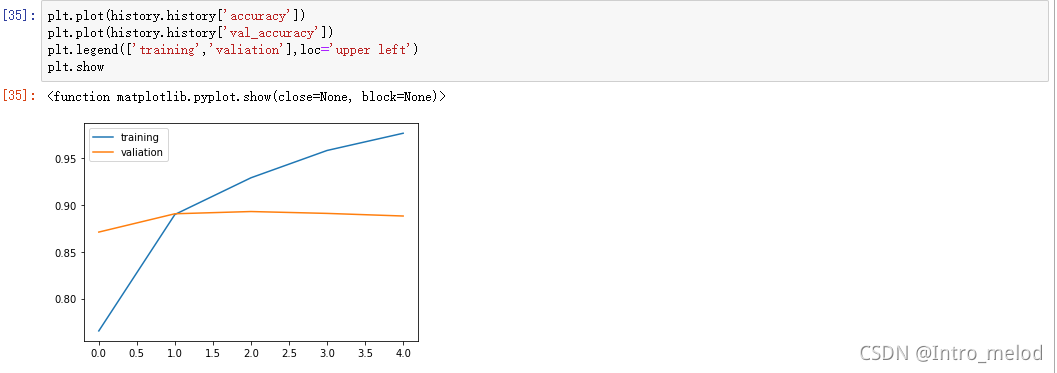
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'valiation'], loc='upper left')
plt.show()
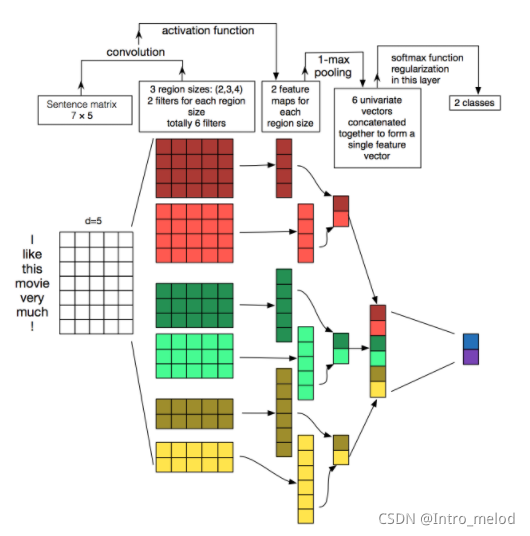
3.多核卷积网络
filter_sizes=[3,4,5]
def convolution():
inn = layers.Input(shape=(sequence_length,embedding_dimension,1))#(300,100)
cnns=[]
for size in filter_sizes:
conv = layers.Conv2D(filters=64,kernel_size=(size,embedding_dimension),#([3,4,5],100)
strides=1,padding='valid',activation='relu')(inn)
pool = layers.MaxPool2D(pool_size=(sequence_length-size+1,1),padding='valid')(conv)
cnns.append(pool)
outt = layers.concatenate(cnns)
model = keras.Model(inputs=inn,outputs=outt)
return model
def cnn_mulfilter():
model = keras.Sequential([
layers.Embedding(input_dim = num_features,output_dim=embedding_dimension,
input_length=sequence_length),#(300,100)
layers.Reshape((sequence_length,embedding_dimension,1)),#(300,100,1)
convolution(),#up
layers.Flatten(),
layers.Dense(10,activation='relu'),
layers.Dropout(0.2),
layers.Dense(1,activation='sigmoid')
])
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.BinaryCrossentropy(),
metrics=['accuracy'])
return model
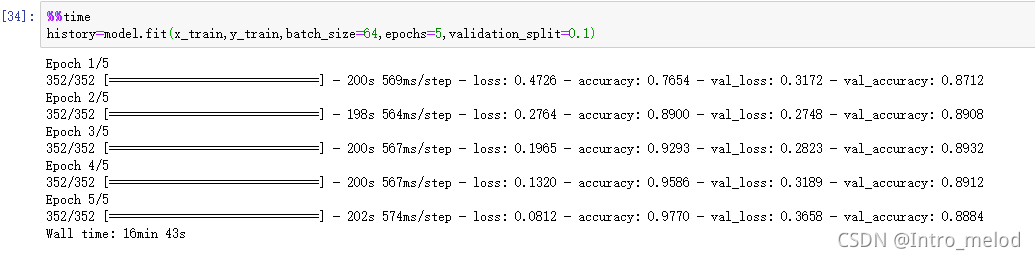
model = cnn_mulfilter()
model.summary()





















 3091
3091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











