




 本文介绍了如何创建一个静态网页爬虫,包括url管理器、下载器、解析器和输出模块。重点提到在输出阶段,将爬取的数据转化为DataFrame并使用pandas.to_csv()方法保存到CSV文件,同时强调了选择'utf-8'编码以避免无法识别的文本问题。
本文介绍了如何创建一个静态网页爬虫,包括url管理器、下载器、解析器和输出模块。重点提到在输出阶段,将爬取的数据转化为DataFrame并使用pandas.to_csv()方法保存到CSV文件,同时强调了选择'utf-8'编码以避免无法识别的文本问题。
记小白的第一次爬虫经历。
实验环境:Python3.6 IDE :Spyder
需要用到的包:urllib.request(必备),bs4(必备),re,pandas
目标:爬取股吧论坛个股吧(每支股票)第一页帖子内容(股票代码、帖子url、帖子标题、帖子内容),并输出到csv文件
爬虫框架:

调度器class SpiderMain(object):
创建四个对象(分别为url管理器对象,下载对象,解析对象,输出对象):

爬虫函数def crawl(self, root_url):
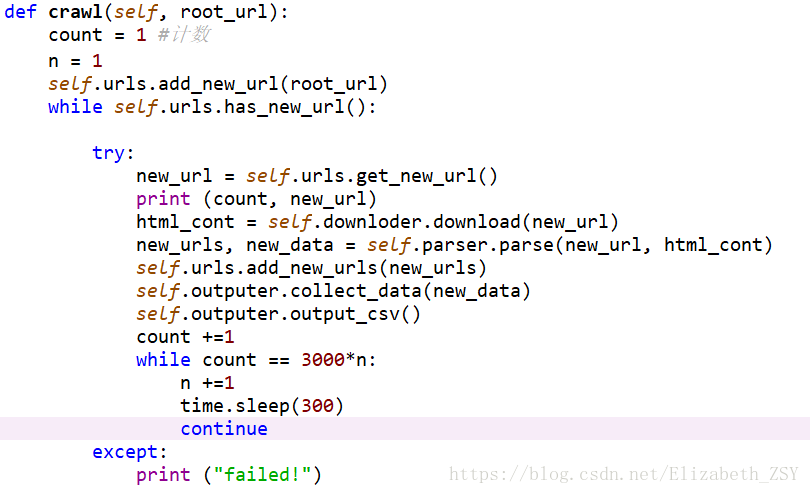
本段代码的主要逻辑很简单,就是从未爬取的url集合中取出一个一个url,下载url页面内容,解析页面内容,输出爬取价值信息内容,并将该url放入已爬取url集合中。
第二个while循环是为了设计每爬3000个url
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









