




 本文详细介绍了C++11及后续版本引入的新特性,包括变量模板、一致初始化、显式关键字、范围基For循环、右值引用、完美转发、移动构造和赋值等。这些特性提升了代码的效率、可读性和安全性,为C++程序员提供了更强大的工具箱。
本文详细介绍了C++11及后续版本引入的新特性,包括变量模板、一致初始化、显式关键字、范围基For循环、右值引用、完美转发、移动构造和赋值等。这些特性提升了代码的效率、可读性和安全性,为C++程序员提供了更强大的工具箱。
1、演化、环境与资源

std命名空间,包含即可;


参考书籍:

2、variadic Templates(数量不定的模板参数)
--表示可以接受任意变化的东西;
c++2.0还可以表示一包东西;

const Type&…args 可以传入任意的模板参数

- 当参数包变为0时,需要写一个函数专门针对参数为空时进行处理;这里是print();
- 想知道参数包时多少个时:sizeof…(args)
上面数量不定的模板参数有里两种的表达方式:



tuple --元组,里面可以放置任意参数类型,任意数量;
3、Spaces in Template Expressions(模板表达式中的空格)
在c++11之前,模板之间有模板,必须用空格将其隔开;
vector<list<int> >;
c++11出现后,就不需要加空格了
vector<list<int>>;

4、nullptr和std::nullptr_t
nullptr: c++11允许使用nullptr来代替0 or NULL
std::nullptr的类型也是nullptr

5、auto关键字
使用auto特别有用在type很长,很复杂;

auto后面,必须要写东西,让编译器能够推导;
auto i;(错误)
使用场合:
- lambda函数:没有名称的函数,仿函数
lambda表达式,很难写出它的类型,用auto;
- 迭代器使用auto关键字;
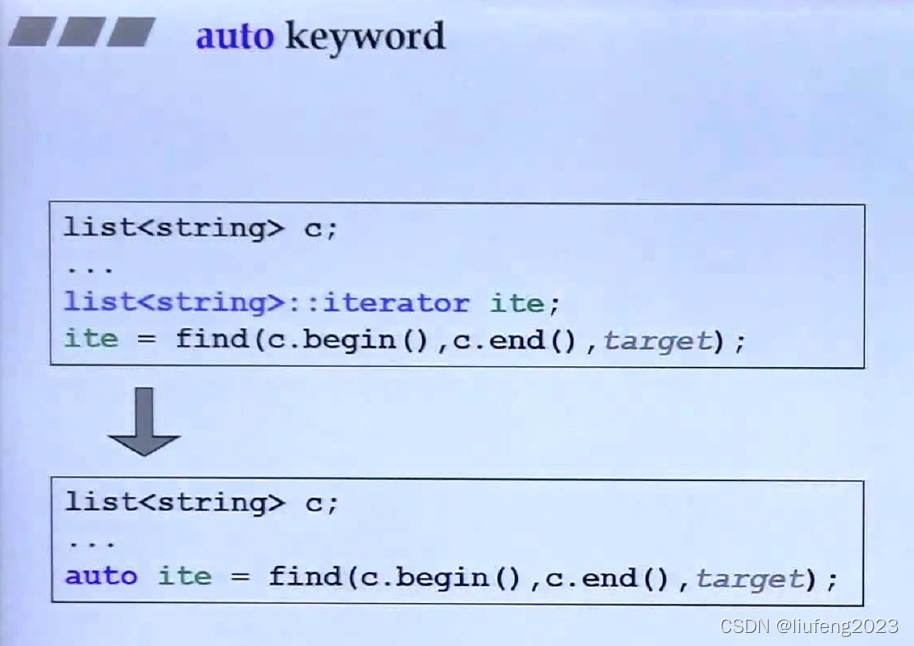

differnce_type就是两个迭代器之间的距离,通过萃取机进行萃取。
6、Uniform Initialization—一致性的初始化
c++11之前,程序员对变量、对象的初始化怎么写比较头疼;因为初始化可能发生在:(),{},=赋值符号;

因此,c++11导入了一致性初始化,就是任何初始化语言都可以用一种通用语法,就是大括号{},在变量的后面直接放初始值
7、explicit

编译器自己会进行一个隐式的转换,将5转换为5+0*i
如果不想这样自动转换;在构造函数前面加explicit

8、range-based for
将coll容器中的元素一个个拿出来哦,放入decl变量中;


auto:在块作用域、命名作用域、循环初始化语句等等 中声明变量时,关键词auto用作类型指定符。
-- auto
auto即 for(auto x:range) 这样会拷贝一份range元素,而不会改变range中元素;
-- auto&
当需要修改range中元素,用for(auto& x:range)
-- const auto&
当只想读取range中元素时,使用const auto&,如:for(const auto&x:range),它不会进行拷贝,也不会修改range\
-- const auto
当需要拷贝元素,但不可修改拷贝出来的值时,使用 for(const auto x:range),避免拷贝开销
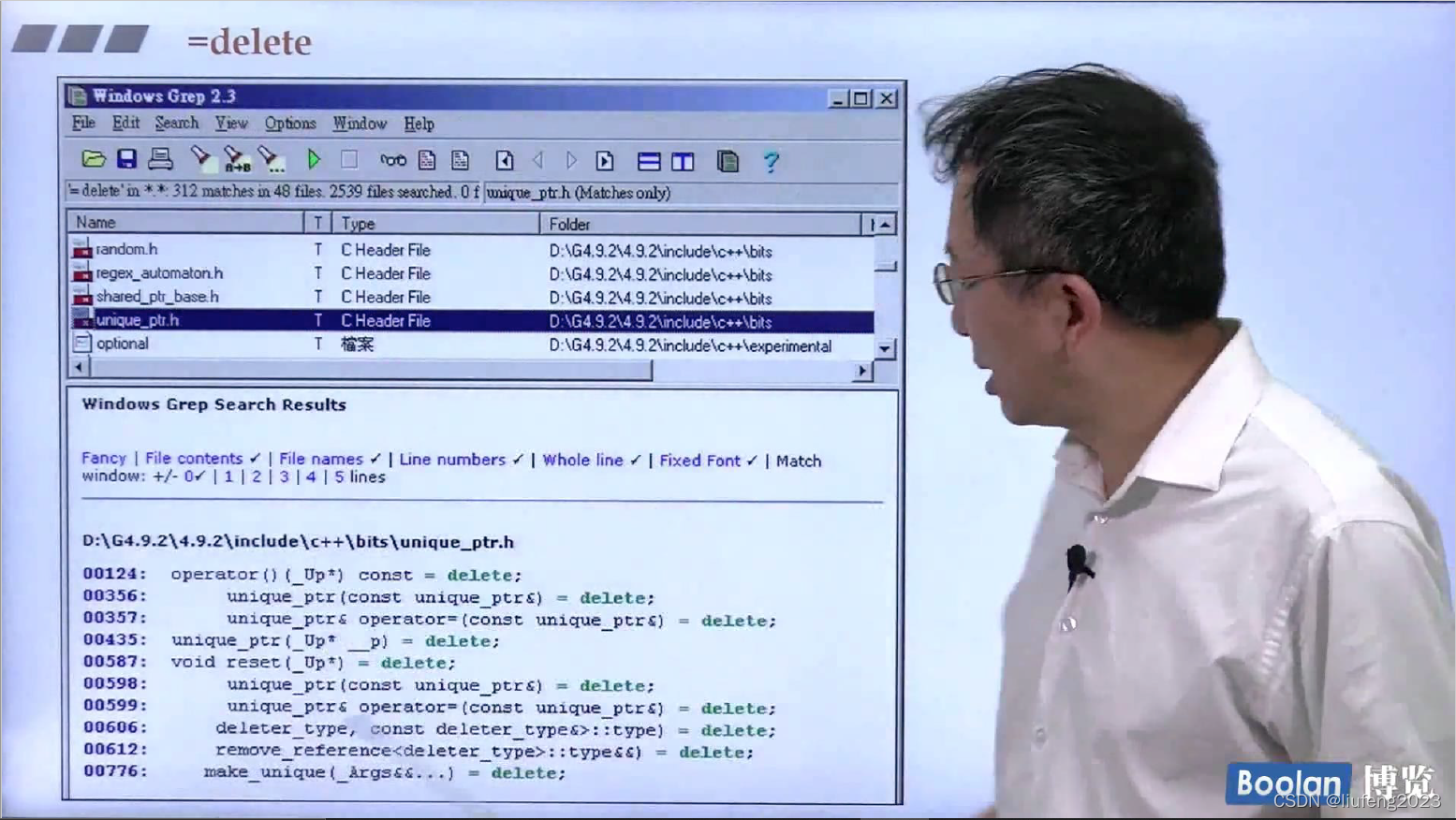
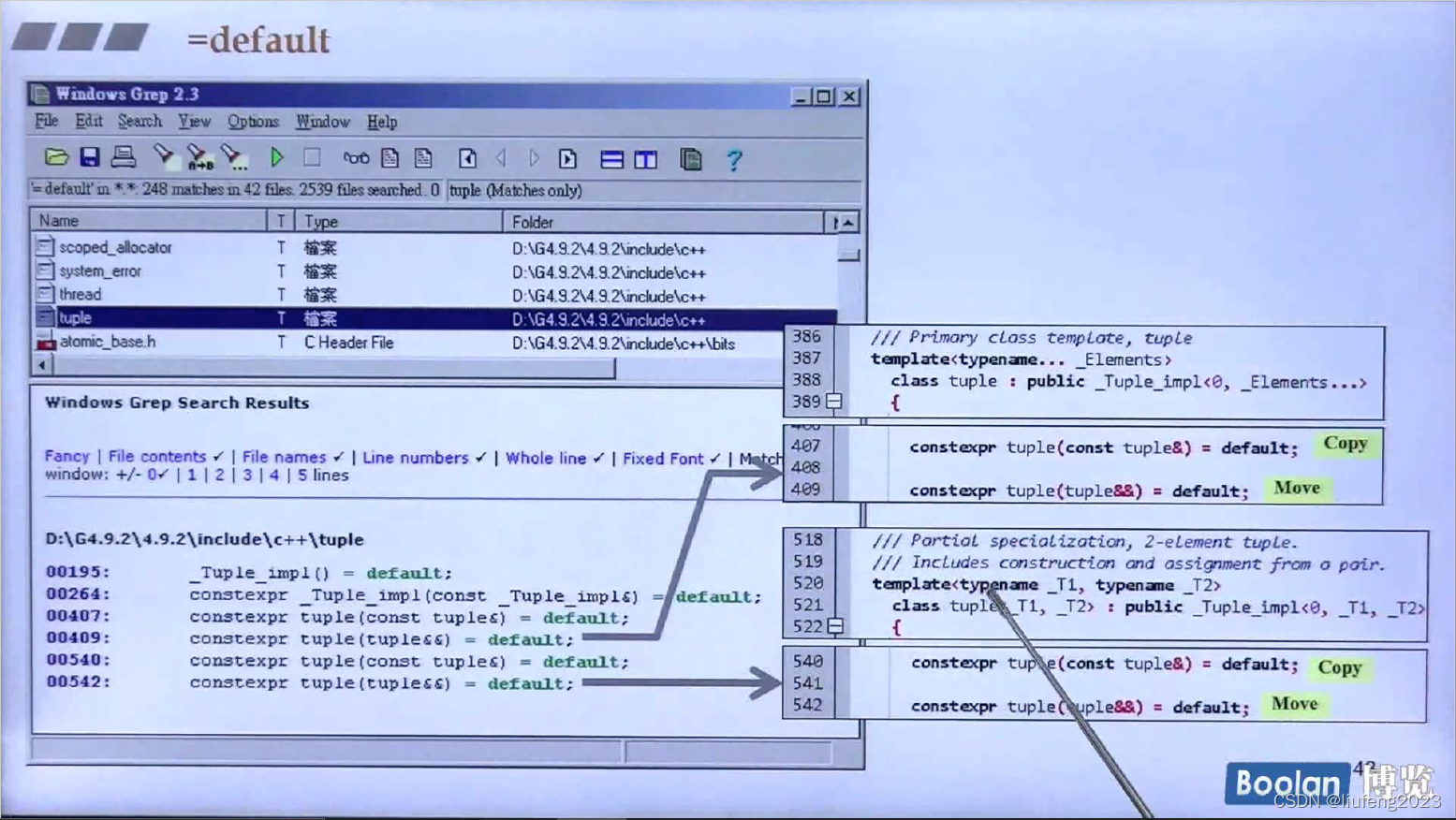
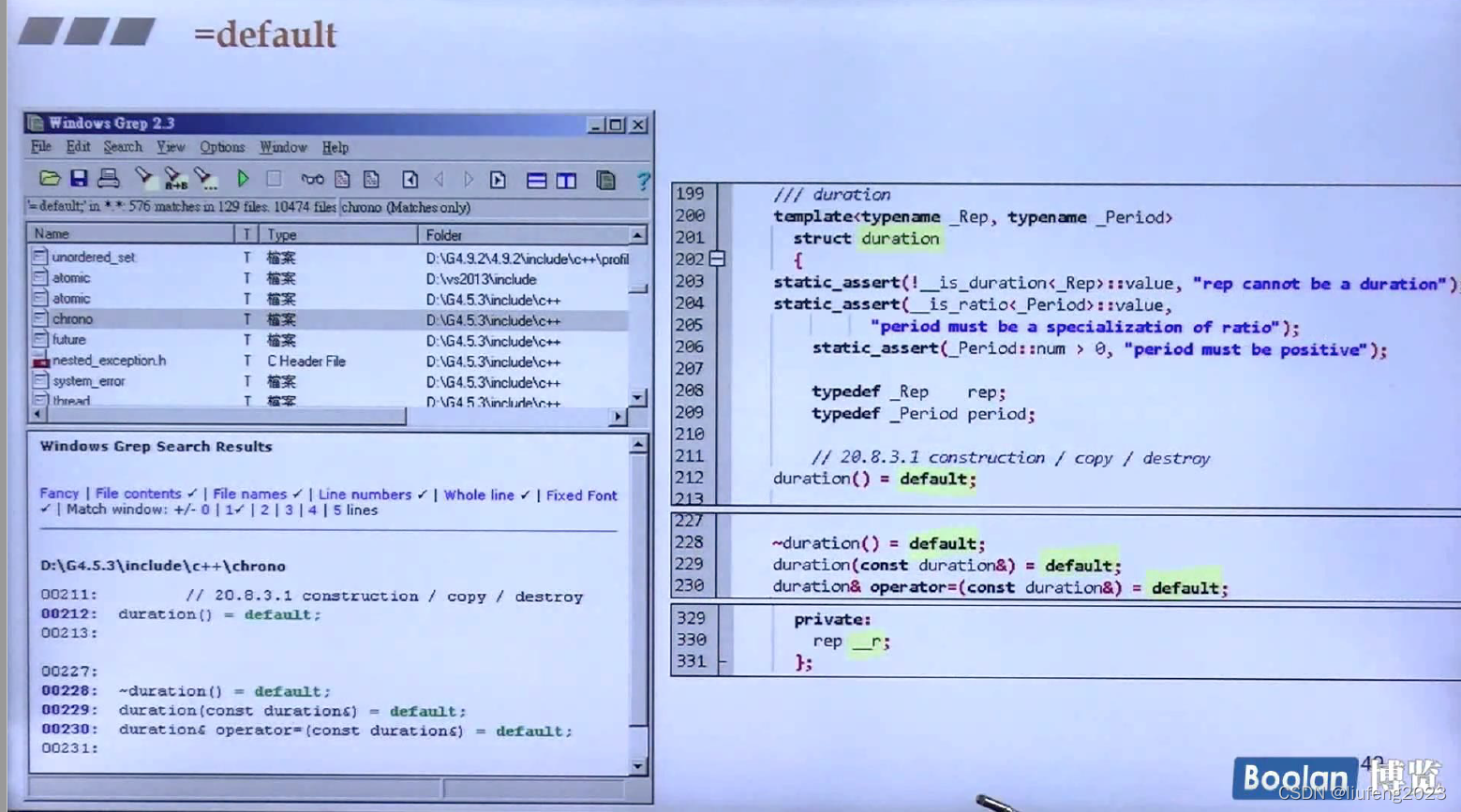
9、=default,=delete
构造函数,如果你没写,编译器会给你一个;
如果写了,编译器就不会给你默认的构造函数;
但是如果我还想要系统提供的构造函数,尽管系统提供的构造函数什么都没做;在后面加上=default;
=delete: 表示删除这个函数;
=default: 表示还是使用编译器给我默认提供的;

构造函数可以重载;
拷贝构造函数只能有一个(不能进行重载);
拷贝赋值函数也不能重载;


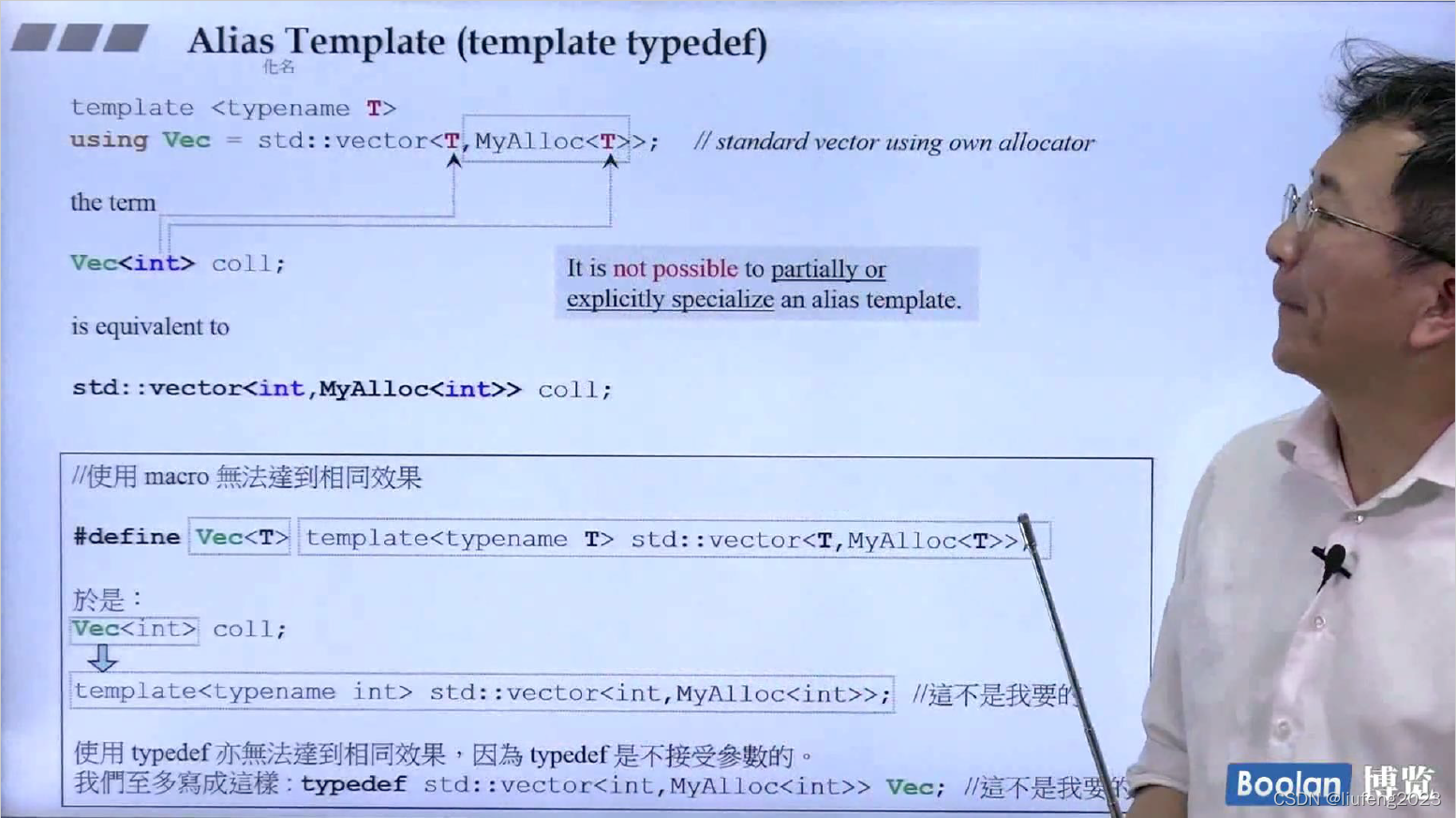
10、Alias Template(template typdef)—模板的化名
Alias:化名,别名。
使用using来取别名,define和typedef都不可以(没办法指定参数)。
11、template template parameter—模板模板参数

上面基本语法是对的,但是使用时还是出错。
因为vector在模板模板参数中使用时,编译器无法自己给vector第二个参数分配默认值,在外面单独使用时可以。

使用using解决,将vector的第二个参数进行封装。
using Vec = vector<T,allocate<T>>;

12、Type Alias(similar to typedef)—类型的化名
typedef void(*func)(int); --c语言,是一个函数指针
using func = void(*)(int,int); --func是一个函数指针,非常的清楚
函数的名称就是函数的地址,就是函数指针。

using出现的可能性:

13、noexcept
保证不会丢成异常,noexcept放在函数小括号的后面,大括号的前面
noexcept(noexcept(x.swap(y))) --后面小括号保证是复合某个条件不会丢出异常
符合x.swap(y)函数不丢异常的话,外面的函数就不丢异常

异常一定要被处理,异常如果一直没有处理的话,会一直向上处理,最后程序就会abort(),结束程序。
和move有关的右值引用:

必须通知vector它的移动构造和移动赋值都是noexcept的,这样才能让vector进行两倍的容量成长。
vector在进行扩容时间,调用移动构造(设置move系列函数时,移动构造,移动赋值,一定不能出现错误,且要告诉我们这个没有发生异常的)(因此需要告诉vector,放心的调用这个函数)
只有vector会大幅度的成长。
14、override—复写,改写
override:复写,改写,运用在虚函数上。
函数的声明一定要完全相同。
在虚函数后面表名override,如果写错了,编译器就会提醒你;

**注意:**这里并没有复写,是两个函数;

但是,如果你不小心写错了,编译器会认为它是两个函数,而不是子类重写父类的函数;
c++2.0时,我们可以加上override关键字,如果不是重写的话,编译器会进行报错;

15、final
针对类: 表示我是继承体系的最后一个,不要再有人继承我了;
针对虚函数: 添加virtual关键字之后,虚函数不可以被复写;

16、decltype
使用decltype可以找到一个变量、表达式的类型;


作用:
1. 声明返回值类型:
lambda:就是临时写出的一段函数,没有名称;
注意:传进来的必须是一个容器;(传进去的是非容器,就会没有迭代器;)

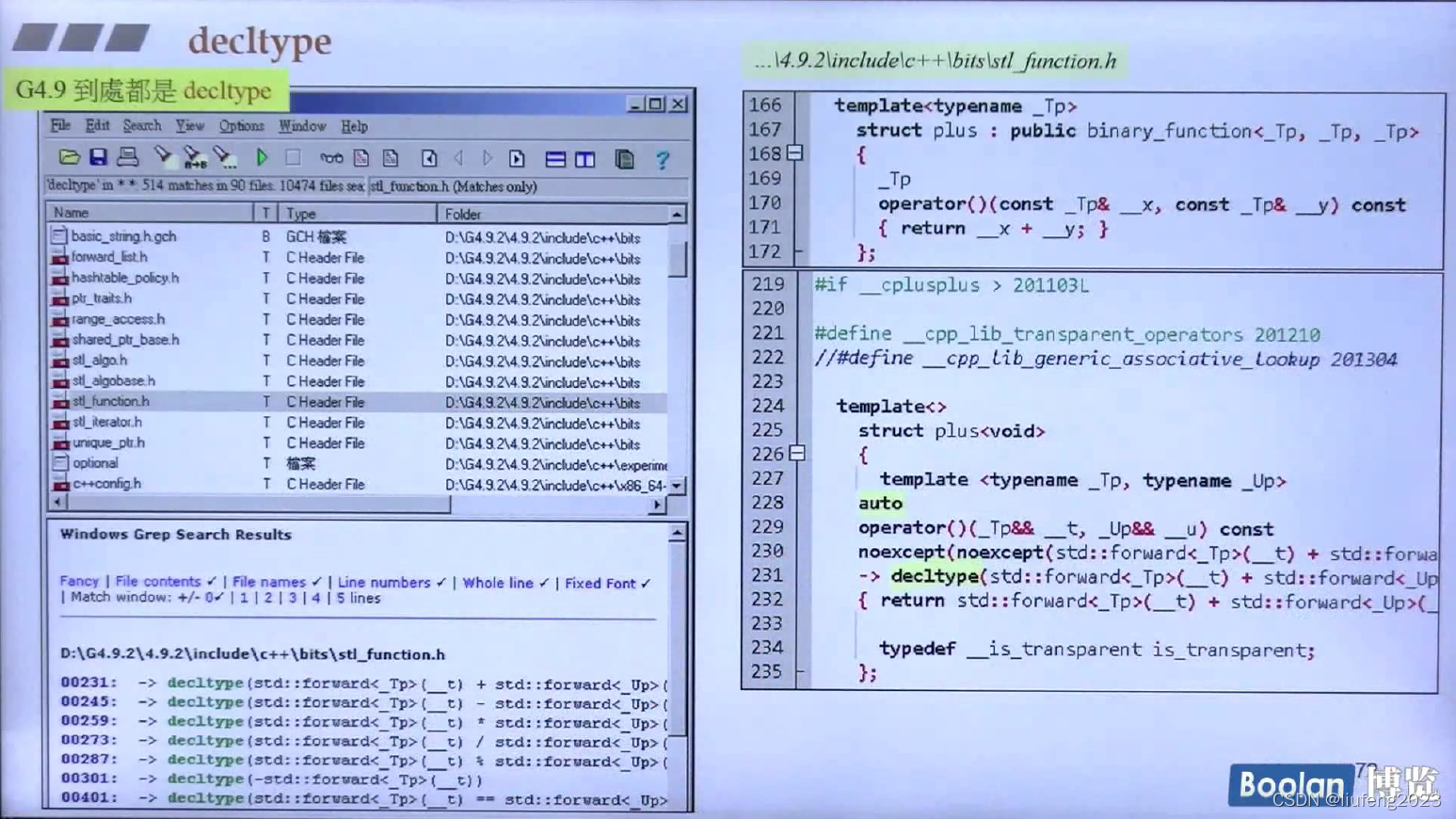
2、元编程

3、用在lamada表达式中,decltype(cmp):表示推导变量的类型

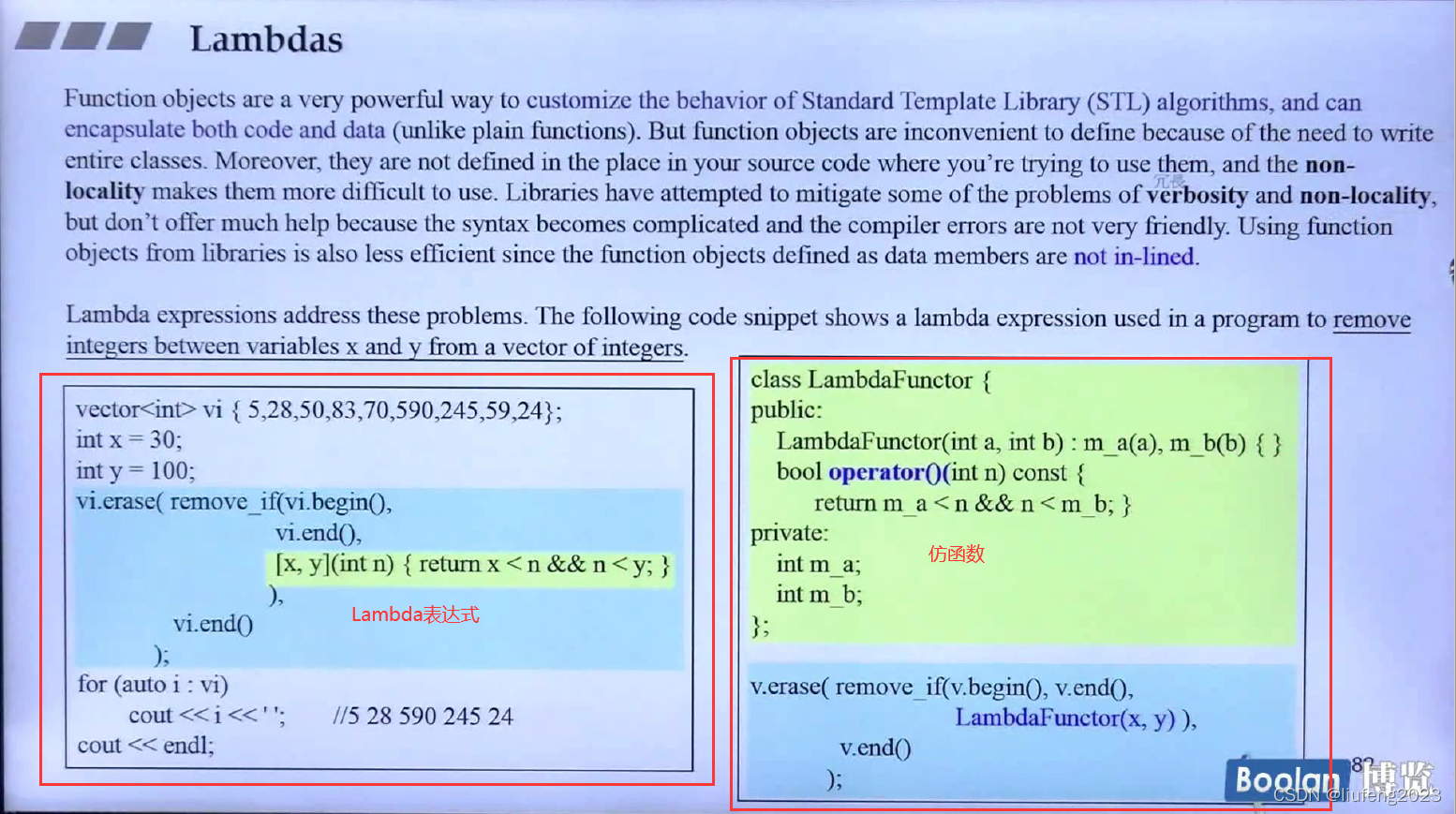
17、Lambdas
c++11使用Lambdas允许你定义inline 函数,可以被用来当做一个东西(参数或者object)
注意: Lambda表达式是一个inline Function
Lambda可以你临时想用来做一些东西,直接写Lambda表达式后,就可以直接拿来用。
比如排序时,我们会写一个小的东西(直接使用Lambda表达式),来说明排序的准则,是从大到小函数从小到大.


[]:看到它就知道是Lambda,用来取用外部的变量;
- pass by value[变量名]
- pass by reference[&变量名]
- [=]表示可以使用所有的外部变量
():里面放的是参数;
**{}:**函数本体;
- **throwSpec:**函数是否可以抛出异常;
- **mutable:**影响着[]中的数据是否可以被改写;
- **->reType:**表示返回值类型
如果上面三个不写,()可写可不写;有一个写了,就要写()。

**左边程序:**就是直接操作的是外面的id,因为加了mutable,不是操作拷贝的id,直接对传入的全局变量进行操作。
**右边程序:**如果没有mutable,直接对()进行重载。
没加mutlable,{}里面不可以进行++id,传入的参数是不可以改变的;
对于需要传入排序的准则,写成一个仿函数(类)是一个更好的选择;

Lambda表达式和仿函数的使用对比:
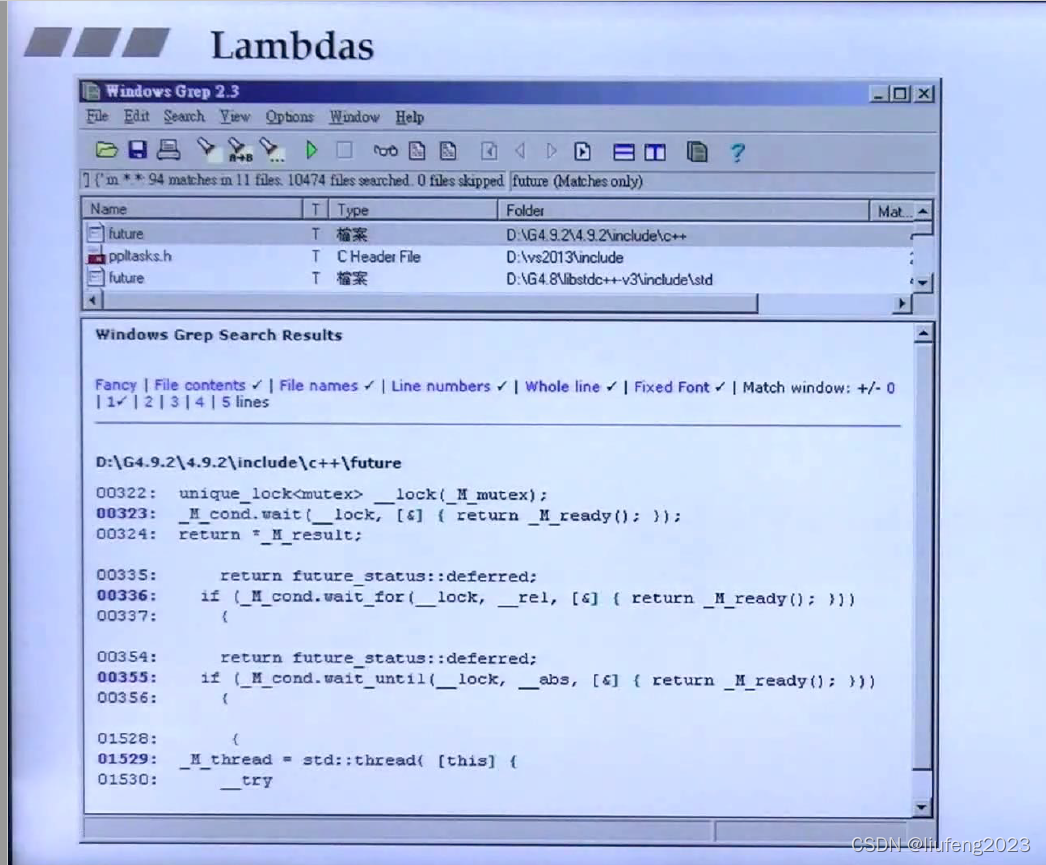
标准库,其他使用Lambda表达式的地方:
20、右值引用
会在move中使用,move语义对容器的性能有大幅度的改善;
新的引用类型;
会帮助解决不必要的copy;
右边是一个右值,左手边接收的可以去"偷"右边资源,而不需要重新分配内存。
左值:变量就是左值, 可以出现在=的左侧,也可以出现在右侧;
右值: 不能放在=的左边,只能出现在=的右边;(最常见的右值就是临时对象)

上面string和complex类推翻了右值,不管他。
a+b是一个右值;
函数返回的东西是一个右值,对右值取地址是不行的;

拷贝构造会分配另一块内存(多消耗内存):

Vtype(buf): 临时对象,是一个右值。
move就是一个指针的浅拷贝,move之后原来的就不可以使用了。
右值(传入的参数是右值,说明允许被偷),编译器一定会用偷的方式(move,移动构造)进行构造;

如果是左值,也想要要用偷的方式进行操作,使用move函数(将左值变成右值);

vector中insert的源代码:

21、Perfect Forwarding—完美转发

上面虚线的过程在转发的过程中可能会遗漏一些数据信息。
类中有指针数据,就一定要写big-three,拷贝构造,拷贝赋值、析构函数;
完美转发:

不完美的转发:
forward(2): 右值放进去之后就会变成左值,forward设计有问题。
forward(move(a)) 同上一样的错误;
forward(a): 左值根本就不能传入;
标准库的完美转发:

move之前就会调用forward,就是用了完美转发(也就是做了完美的转交);
22、move移动构造和move移动赋值
带move的class;
MyString类中有指针数据,就一定要写big-three,拷贝构造,拷贝赋值、析构函数;
最终的目标,是生成一个类型,声称是可以被偷的,这样就可以对容器的性能有大幅度提升;
注意:
- 拷贝构造和拷贝赋值都是在做拷贝;参数类型是引用;
- 移动构造和移动赋值传入的参数是右值引用;
- 新指针move原来指针后,原来的指针一定要赋值为NULL,不然会两个指针指向同一处,在析构函数时会出错,并且在析构函数汇总再将原来指针删除;


各个容器的测试:
- MyString:有move构造和赋值;
- MyStrNoMove:没有move构造和赋值。

Vector测试:

3000000个元素,为什么会调用构造函数7000000多次?
因为vector容器空间不够时,回进行两倍成长,会将原来的数据(拷贝/移动)到新的地方。

为什么三种方式的时间差距那么大?
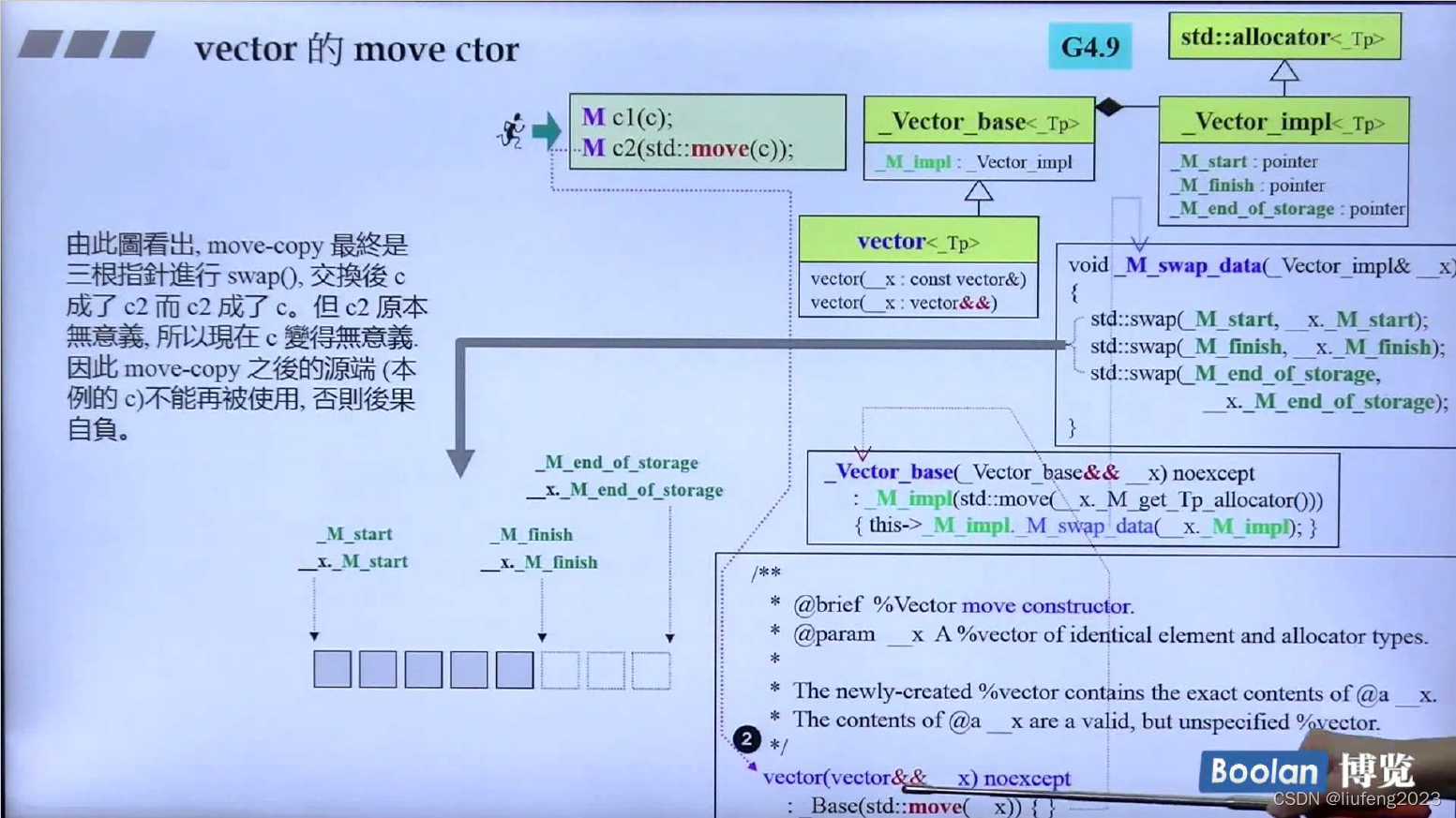
M cl1(c1): 将 来源端容器数据 的头尾,一个个拷到目的端去;

M c2(std::move(c1)): 将来源端当成右值,这样就可以偷了;(注意往下,c1是不可以在用了,它的资源已经被偷了)
cl1.swap(cl2): 只是交换指针,目的端和来源端指向同一块东西,再将初始的指针置为空,最后将它释放掉。
容器array
内部是一个c++数组,将他包装成c++的一个类;

没有构造函数,没有析构函数;

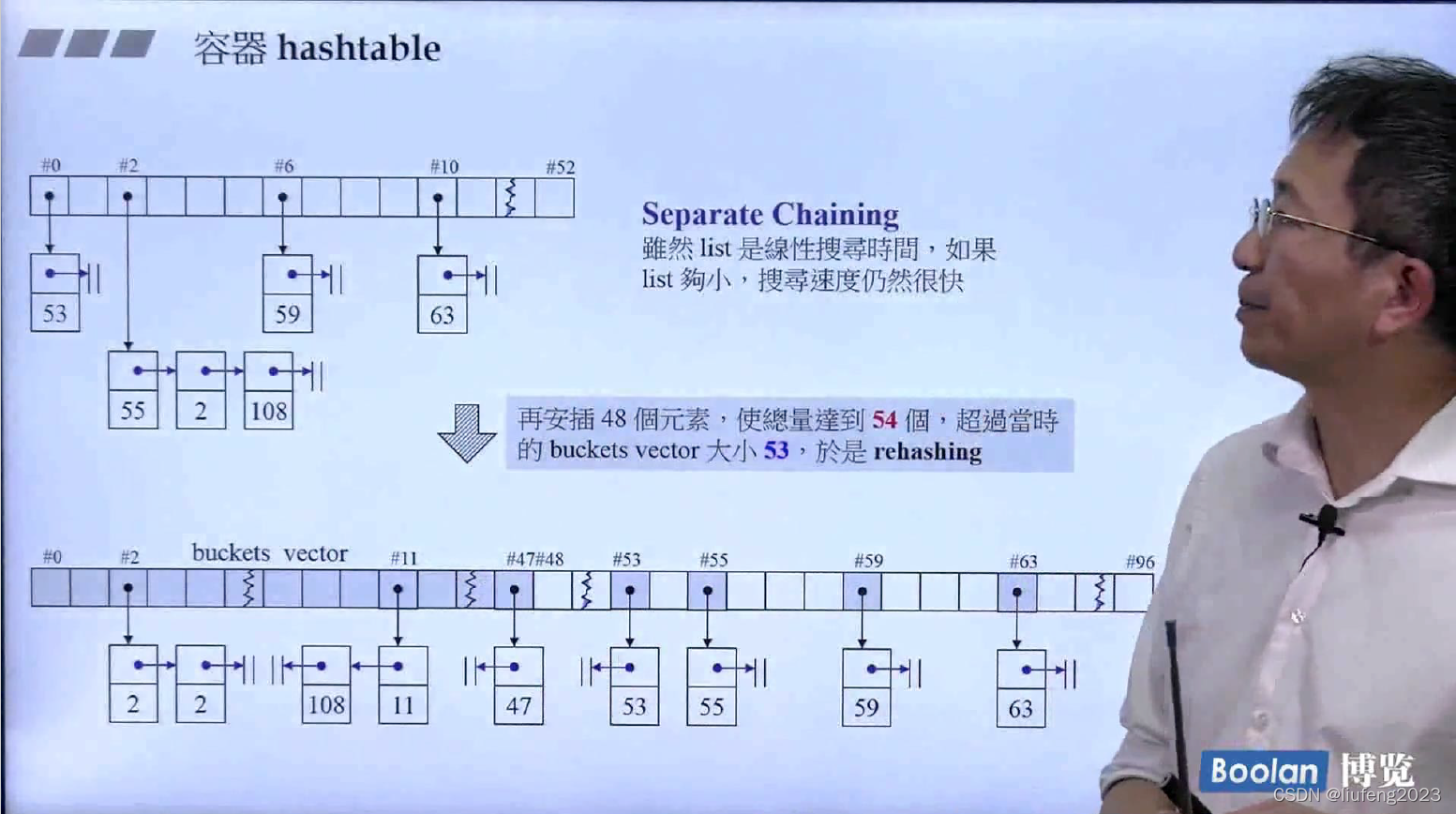
容器hashtable
篮子是vector,每个篮子下都有一个链表;
容器的元素大于 篮子的个数时,篮子的个数就增加两倍;
篮子扩容时,需要进行扩容;元素需要重新排序:rehashing;
hashcode;


















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











