







 本文介绍了机器学习的基础知识,包括监督学习和无监督学习两大分类,重点讲解了单变量线性回归。内容涵盖模型描述、代价函数、梯度下降及其优化过程,并对学习效率(学习率)的影响进行了说明。
本文介绍了机器学习的基础知识,包括监督学习和无监督学习两大分类,重点讲解了单变量线性回归。内容涵盖模型描述、代价函数、梯度下降及其优化过程,并对学习效率(学习率)的影响进行了说明。
1机器学习算法的分类
1.1 监督学习
- 回归问题。 一般数处理连续值,比如提到的房屋售价预测
- 分类问题。 一般事处理离散值,比如判断肿瘤是良性还是恶性
1.2 无监督学习
- 聚类问题 。将收集到的新闻分成不同的专题,事先不知道有哪些专题
2 单变量线性回归
2.1 模型描述
-
常用的符号语言,
m代表训练样本的数量x输入变量,属性y输出变量,结果(x,y)一个训练样本(x^i,y^i)第i个训练样本
-
机器学习算法的目的,是通过训练数据集得到一个假设函数h(hypothesis) h ( x ) = θ 0 + θ 1 x h(x)=\theta_0 + \theta_1 x h(x)=θ0+θ1x,这个h的作用是,输入一个x可以得到一个输出变量y
2.2 代价函数
- 代价函数(cost function)在单变量线性回归中一般选择平方误差函数(square error function):
(2.1)
J
(
θ
0
,
θ
1
)
=
1
2
m
∑
i
=
0
m
(
h
(
x
(
i
)
)
−
y
(
i
)
)
J(\theta_0,\theta_1)=\displaystyle\frac{1}{2m} \displaystyle\sum^{m}_{i=0}\Big({h(x^{(i)}) - y^{(i)}}\Big) \tag{2.1}
J(θ0,θ1)=2m1i=0∑m(h(x(i))−y(i))(2.1)
需要做的是找到使
J
(
θ
0
,
θ
1
)
J(\theta_0,\theta_1)
J(θ0,θ1)最小的
θ
0
,
θ
1
\theta_0,\theta_1
θ0,θ1
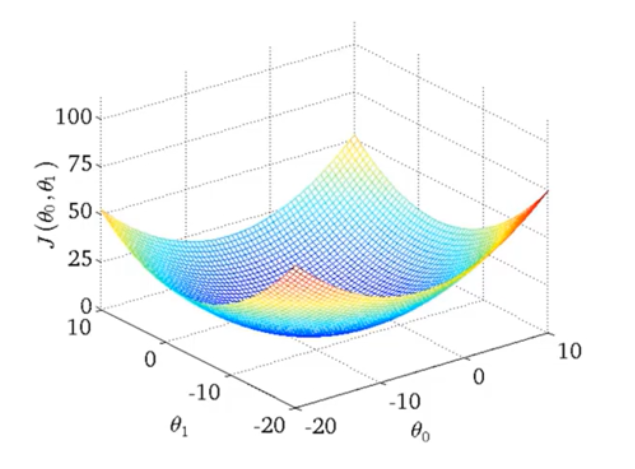
- 代价函数中的一个点,代表了一组 θ 0 , θ 1 \theta_0,\theta_1 θ0,θ1的取值,即一个假设函数 h h h
2.3 梯度下降
- 梯度下降是一种最小化代价函数的方法,不仅适用于平方误差函数
- 思想是:先任取一组 θ 0 , θ 1 \theta_0,\theta_1 θ0,θ1的值,然后不断改变 θ 0 , θ 1 \theta_0,\theta_1 θ0,θ1的值来减少 J ( θ 0 , θ 1 ) J(\theta_0,\theta_1) J(θ0,θ1),直到 J J J的最小值(或者极小值)
- 表达式:
(3.1) r e p e a t u n t i l c o n v e r g e n c e { θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) ( f o r j = 0 a n d j = 1 ) } repeat\ until\ convergence\{ \\ \quad \theta_j := \theta_j - \alpha \frac{\partial}{\partial {\theta_j}} J(\theta_0,\theta_1) \quad (for\ j = 0 \ and\ j = 1) \tag{3.1} \\ \} repeat until convergence{θj:=θj−α∂θj∂J(θ0,θ1)(for j=0 and j=1)}(3.1) - 具体的计算过程:

2.4其他需要注意的
-
-
:=是赋值的意思 -
每次计算必须同时更新 θ 0 , θ 1 \theta_0,\theta_1 θ0,θ1,即更新顺序为
(3.2) t e m p 0 : = θ 0 : = θ 0 − α ∂ ∂ θ 0 J ( θ 0 , θ 1 ) t e m p 1 : = θ 1 : = θ 1 − α ∂ ∂ θ 1 J ( θ 0 , θ 1 ) θ 0 : = t e m p 0 θ 1 : = t e m p 1 temp0 := \theta_0 := \theta_0 - \alpha \frac{\partial}{\partial {\theta_0}} J(\theta_0,\theta_1) \tag{3.2} \\ temp1 := \theta_1 := \theta_1 - \alpha \frac{\partial}{\partial {\theta_1}} J(\theta_0,\theta_1) \\ \theta_0 := temp0 \\ \theta_1 := temp1 temp0:=θ0:=θ0−α∂θ0∂J(θ0,θ1)temp1:=θ1:=θ1−α∂θ1∂J(θ0,θ1)θ0:=temp0θ1:=temp1(3.2) -
α \alpha α是学习效率(learning rate),决定着 θ 0 , θ 1 \theta_0,\theta_1 θ0,θ1的更新速度, α \alpha α太小可能收敛速度会很慢, α \alpha α太大可能导致不收敛或者发散
-
-
梯度下降的直观理解:
以只考虑一个变量 θ 1 \theta_1 θ1为例,
[外链图片转存失败(img-9u86zUha-1563951056546)(.\images\1.png)]
粉红色的点为初始点为初始点,在该点求出对 θ 1 \theta_1 θ1的导数(不是偏导是因为在这里只考虑一个变量),乘以学习效率 α \alpha α,更新 θ 1 \theta_1 θ1得到绿色的第二个点,重复这个步骤,直到到达最低点。
需要明确的是,在上述迭代过程中不需要更新 α \alpha α,因为 ( 3.1 ) (3.1) (3.1)中的偏导数(导数部分)会随着 θ 0 , θ 1 \theta_0,\theta_1 θ0,θ1接近局部最低值而减小 -
有时候也称为批量梯度下降法(batch gradient descent),因为在梯度下降的每一步中,我们都用到了所有的训练样本。
-
梯度下降法有时候会局限于局部最优解,但是绝大部分时候,代价函数都是一个弓形函数,即凸函数,只有一个全局最优解,所以不用担心。

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









