




BERT:一种新型预训练语言表示模型
1. BERT的由来
BERT(Bidirectional Encoder Representations from Transformers)是由Google AI的研究团队于2018年提出的一种深度学习模型,旨在提升自然语言处理(NLP)任务的性能。在BERT问世之前,NLP领域主要依赖于RNN(循环神经网络)和LSTM(长短期记忆网络)等模型,这些模型在处理上下文信息时通常是单向的,无法充分理解句子中的双向依赖关系。因此,BERT的诞生可以视为对传统模型的一次突破。BERT利用Transformer架构的优势,能够同时考虑上下文的左右两侧,从而更好地理解句子含义。此外,BERT的出现也推动了预训练模型的潮流,使得模型可以在多个下游任务中通过微调来适应不同的应用场景。这种预训练与微调的策略不仅提高了模型的泛化能力,还显著降低了对标注数据的需求。
2. BERT解决了什么问题
BERT的主要目标是解决自然语言理解中的上下文依赖问题。传统的NLP模型在处理句子时往往只考虑前文或后文,这导致了对一些语义信息的丢失。而BERT的双向特性允许模型在预测词语时同时参考前后的上下文,从而提升了对句子含义的理解能力。此外,BERT通过Masked Language Model(MLM)和Next Sentence Prediction(NSP)两种预训练任务,使得模型不仅能够生成合理的句子,还能够理解句子之间的关系。这一特性使得BERT在各种下游任务中,如问答系统、文本分类和命名实体识别等,表现得更加优越。在这些任务中,BERT显著提高了准确率和F1分数,成为NLP领域的重要里程碑。
3. BERT的创新点
BERT的创新主要体现在其模型架构和训练策略上。首先,BERT采用了Transformer架构中的自注意力机制,使得模型能够有效捕捉词与词之间的关系。这种机制相比于传统的序列模型,如LSTM,能够并行处理输入数据,从而加快训练速度。其次,BERT引入了双向训练,通过同时考虑上下文的左侧和右侧,增强了模型的理解能力。此外,BERT的预训练任务MLM和NSP为模型提供了丰富的上下文信息,极大地提高了其在下游任务中的表现。最后,BERT的开源使得研究者和开发者能够广泛使用这一强大的工具,从而推动了NLP领域的快速发展。这些创新点不仅提升了BERT的性能,还为后续模型的设计和研究提供了重要的参考。
4. BERT的工作原理
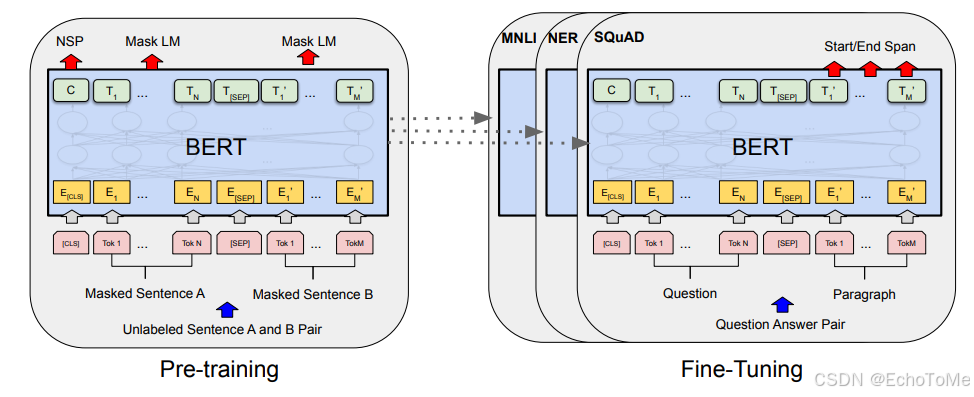
BERT的工作原理可以分为两个主要阶段:预训练和微调。在预训练阶段,BERT首先在大规模的文本数据集上进行训练,主要包括两个任务:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
在MLM任务中,模型随机选择输入句子中的一些单词进行遮盖,然后训练模型预测这些被遮盖的单词,这一过程帮助模型学习到丰富的上下文信息。
在NSP任务中,模型接受一对句子,判断它们是否在原文中相邻。这一任务使模型能够理解句子间的关系。在微调阶段,BERT针对特定的下游任务(如文本分类或问答系统)进行优化,通常只需在少量标注数据上进行训练,这使得BERT能够快速适应各种应用场景。
5. BERT的优势
BERT相较于传统的NLP模型具有显著的优势。首先,BERT的双向特性使得它能够更全面地理解句子的上下文,这对于许多需要上下文理解的任务至关重要。其次,BERT的预训练和微调策略极大地减少了对标注数据的需求,这对于许多低资源领域的应用尤其重要。此外,BERT在多个NLP基准测试中的表现超越了以往的模型,特别是在GLUE基准测试中表现优异,这使得BERT成为NLP领域的一个重要标准。最后,BERT的开源和社区支持促进了其在学术界和工业界的广泛应用,许多后续模型(如RoBERTa和DistilBERT)也在BERT的基础上进行了改进和优化。这些优势使得BERT成为现代NLP研究和应用的一个基石。
6.BERT代码实现
导入需要的包
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import BertTokenizer
import math
在这里需要注意的是,如果我们的环节中没有transformers库的话,可以用如下的指令来下载
pip install transformers
设置的超参数
class BertConfig:
def __init__(self, vocab_size=30522, hidden_size=768, num_hidden_layers=12,
num_attention_heads=12, intermediate_size=3072, hidden_act='gelu',
max_pos_embedding=512, type_vocab_size=2, init_range=0.02,
layer_norm_eps=1e-12, hidden_dropout_prob=0.1, attention_probs_dropout=0.1):
"""
Bert模型的配置
:param vocab_size:词汇表的大小 词嵌入的维度
:param hidden_size:隐藏层的大小
:param num_hidden_layers:隐藏层的数量
:param num_attention_heads:注意力头的个数
:param intermediate_size:中间层大小 表示BERT模型中每个Transformer块中全连接层的隐藏单元数量。
:param hidden_act:激活函数
:param max_pos_embedding:最大位置嵌入 BERT模型能处理的最大序列长度
:param type_vocab_size:类型词汇表大小 表示BERT模型中标记句子类型的标记数量。通常为2,表示句子A和句子B
:param init_range:参数初始化范围
:param layer_norm_eps:层归一化的eps
:param hidden_dropout_prob:隐藏层dropout概率
:param attention_probs_dropout:注意力dropout概率
"""
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.max_position_embeddings = max_pos_embedding
self.type_vocab_size = type_vocab_size
self.initializer_range = init_range
self.layer_norm_eps = layer_norm_eps
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout
在这里我们可以任意的设置超参数,超参数的含义已经在代码的注释中写的比较清楚了。
嵌入层
class BertEmbeddings(nn.Module):
def __init__(self, config):
"""
初始化Bert嵌入层
:param config: Bert的配置
"""
super(BertEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, token_type_ids=None):
"""
前向传播
:param input_ids: 输入的token id
:param token_type_ids: 输入的token类型 id
:return: 嵌入层的输出
"""
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
# 词嵌入,位置嵌入,类型嵌入
input_embed = self.word_embeddings(input_ids)
pos_embed = self.position_embeddings(
torch.arange(input_ids.size(1), device=input_ids.device).unsqueeze(0).expand_as(input_ids))
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = input_embed + pos_embed + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
在这里的嵌入层分为词嵌入层、位置嵌入层和句子的类型嵌入层
在这里我们需要额外解释的是句子的类型嵌入层:这个是因为Bert在训练的会设计到一个NSP的任务,需要判断两个句子是否响铃,而我们需要在训练的时候对数据进行标注哪个句子在前面哪个句子在后面。
自注意力层
class BertSelfAttention(nn.Module):
"""
Bert自注意力层 对于Transformer的自注意力层
"""
def __init__(self, config):
"""
初始化Bert的注意力机制
:param config: 配置
"""
super(BertSelfAttention, self).__init__()
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose(self, x):
"""
转置输入张量以便于计算得分
:param x: 输入张量 (batch_size,seq_len,hidden_size)
:return: 转换后的张量 (batch_size,num_attention_heads,seq_len,attention_head_size)
"""
# 拿出x的batch_size,seq_len维度
x_shape = x.size()[:-1] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









