



在数据科学领域,因果推断的应用一直是学界和业界关注的焦点。近期,我发现一篇剖析学术与工业场景下因果推断异同的博客 ——[How is Causal Inference Different in Academia and Industry?]。为了让更多读者深入了解,我将对其进行翻译分享,希望能给大家带来启发与思考 。
不同点
学术研究和业界应用在性质与目的上有着显著差异,这也导致二者因果推断工作流程截然不同。
速度
学术研究从构思到得出结论,节奏往往偏慢。研究人员不仅关注因果结论本身是否可靠,对研究涉及的数据、采用的方法,以及研究的稳健性也十分在意。为了验证数据的适用性,开展敏感性分析,测试因果结构,整个研究周期通常会拉长。
对企业而言,时间就是金钱,科技公司尤为务实。他们更愿意把资源集中在开发可扩展的应用程序上,这些程序能迅速投入生产,带来收益。等待一个完美且通用的模型,成本过高。所以,业界更倾向于先搭建一个基准模型,之后再进行微调与优化。

方法
学术研究无疑是理论研究人员获取新方法和新机制的源头。不过,从事观察性研究或实验的实证研究人员,通常会采用标准且成熟的方法,如双重差分法(DID)、工具变量法(IV)、**倾向得分匹配法(PSM)**等。使用这些得到广泛认可的方法,能降低他人对研究结论的质疑。
业界对前沿技术向来持开放态度,带有热门术语的技术更容易被接受。一个效果良好,又融入最新热门概念的模型,很容易吸引利益相关者的目光。当然,搭建起商业影响和技术术语之间的沟通桥梁,同样至关重要。

反馈循环
研究人员取得初步成果后,会通过参加会议等活动分享成果,收集反馈。发表研究论文更是需要依据专家和编辑的反馈,反复进行修改。
科技公司一旦拥有性能良好的因果模型,就会将其应用到商业决策中。反馈主要来自客户对模型的实时反应,或者特定时段的关键绩效指标(KPI)。比如,一家公司发现某产品具有价格弹性,便决定降价以提升利润。要是降价后,公司利润不升反降,那就必须重新审视模型。

平均处理效应(ATE)与个体处理效应(ITE)
在学术界,通常评估某一总体或子总体的平均处理效应(ATE)。这既与学术研究的目的有关,也受数据可用性的限制。一方面,学术研究旨在为制定一般性政策提供依据,或者推导出具有普适性、值得信赖的理论;另一方面,研究人员常基于宏观层面的数据展开分析,如国家人口信息、种族收入水平、学校考试成绩等。
与之相反,业界的因果应用更侧重于个体层面的决策,因此**个体处理效应(ITE)**更为关键。例如,向某位客户发送促销邮件,客户会下单购买,还是维持现有订阅?个体层面的因果关系对企业意义重大,因为针对客户定制商业决策的成本较低,却能大幅提升利润。而且,业界拥有丰富的客户交易数据,便于在更精细的层面做出决策。
模型效率
业界应用有时需要投入生产,以实现实时商业决策。例如,当客户点击“取消订阅”时,模型需立刻决定是否提供折扣,以及折扣的幅度。因此,将因果引擎融入商业决策时,必须考虑模型的运行时间和可扩展性,而这在学术研究中关注度相对较低。
结尾
学术研究似乎永无止境。即便论文发表后,也常基于不同群体或时间段对因果关系进行测试,衍生出一系列研究。毕竟研究的本质是拓展知识边界,过程中获取的任何知识都有价值。
而业界应用更关注关键绩效指标(KPI)的提升。如果一个预测客户行为的模型能提高客户留存率和利润,就会被推广并持续维护。
相同点
尽管存在差异,学术研究和业界应用在很多方面也有共通之处。
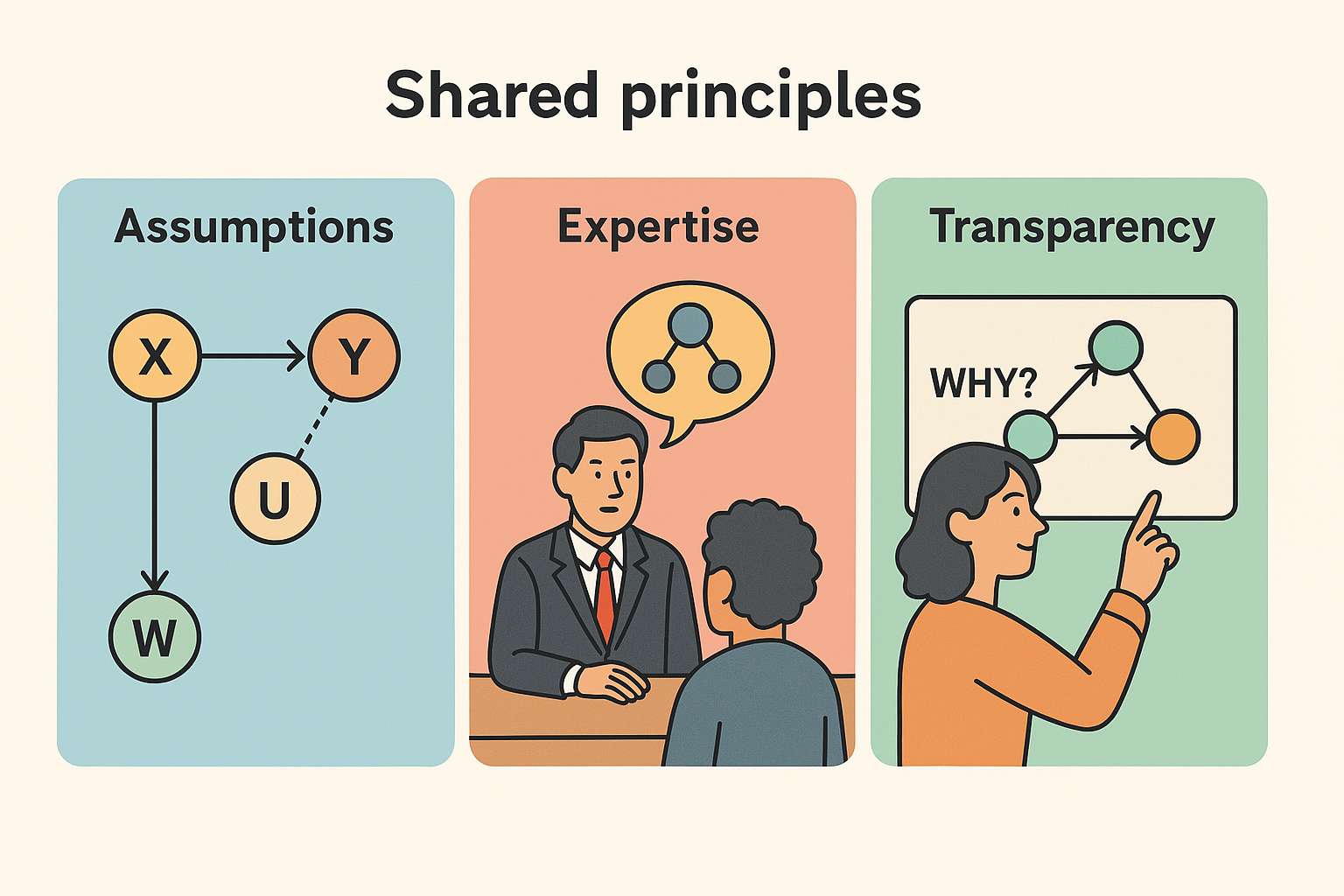
假设
现实世界并非完美,因此学术研究和业界应用通常从假设起步。例如,假设变量X和Y呈线性关系,未观测到的混杂因素U可以用变量W替代,或者在特定因果结构下,变量Z是理想的工具变量等。研究和应用过程中,需要对这些假设进行验证,判断其合理性,以及是否会对结论造成影响。
专家意见
无论是学术研究还是业界应用,制定因果结构时都离不开专家的参与。领域知识在识别混杂因素、中介变量、替代未观测混杂因素的变量,以及工具变量等方面,发挥着重要作用。不了解背后的机制,就无法绘制因果图。
透明度
在因果关系的应用上,学术研究和业界应用都重视透明度。正如珀尔在《为什么之书》最后一章提到的,很多算法虽能有效解决问题,但将因果关系融入系统,能让我们更深入地理解其原理。就像有人所说:“……我总是试图弄清楚‘为什么会发生这种情况?’或者‘为什么我们的用户会有这样的行为’,以便根据用户需求和我们的价值主张,为不同用户群体提供相应解决方案……”理解“为什么”,不仅对商业决策至关重要,对于理解世界运行规律和机制实施,也有着深远意义。
尽管学术研究和业界应用因数据可用性和分析目的不同存在差异,但最终二者会通过相互借鉴、汲取灵感,实现共同发展。


















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









