




目录
4. 二维数组的下标、元素存放、数组大小的特性与一维数组相同
前言
写完上一篇文章后,作者在构思后认为掌握了前三篇文章的内容后,如果直接做扫雷小游戏,有些细节还是不太好说明,所以这里继续介绍一些必要的知识点。即关于数组、函数、生成随机数的知识点
一、数组
1. 数组
数组是一组相同类型元素的集合,存放在数组内的值被称为数组的元素。
• 数组存放的元素个数不能为0个
• 数组存放的元素数据类型相同
• 可以分为一维数组和多维数组(2维及以上),最常用的是一维数组和二维数组。
2. 一维数组
1.创建语法
type arr_name[常量值];
//比如
int age[10];• type指定数组内存放元素的数据类型,可以是内置类型(如int,float,short,double,bool等等),也可以是自定义类型。
• arr_name是指数组的名字,可以根据定义标示符的规则自己创建。
• [ ]中的常量值表示创建的数组可以容纳多少个元素。不进行初始化时不能省略。
• 数组也是有类型的,是type[常量]类型,如图中的例子age数组的类型是int[10]
2. 初始化
type arr_name[常量]={元素,元素,..... };
//例如
int age1[1]={ 13 };
int age2[]={ 1,2,3,4 };
int age3[4]={1};上面的语法都是符合规则的,从中我们可以发现下面几个特性。
• 数组的初始化需要使用{ }来存放元素,元素的个数不能超过[ ]内常量的值
• 一维数组的初始化可以省略常量值,这时编译器会根据你初始化时存放元素的个数自动匹配数组的大小
• 初始化时若元素的个数小于数组的容量,那么空位将会进行默认初始化,对于int类型,会用0来填补空位(其他类型可以使用监视来查看)
3.数组下标
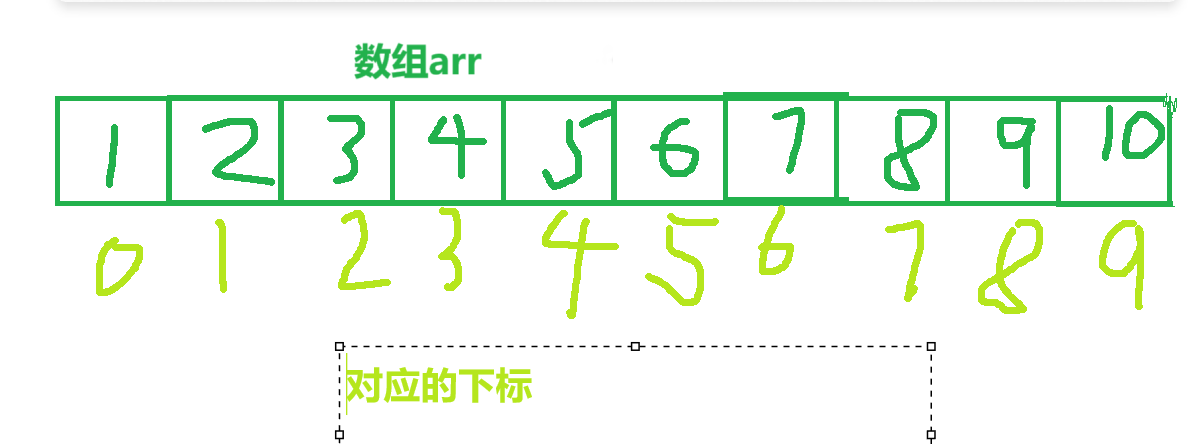
数组中有很多元素,如何精准地选取其中一个进行操作呢?此时需要引入数组下标的概念。下标就是表示这是数组中第几个元素的序号。
C语言规定,下标从0开始,数组有n个元素,就对应有n-1个下标。比如
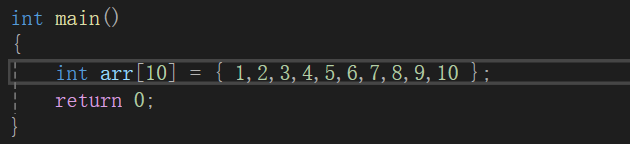
4.使用数组中的元素
想对数组中的元素操作只需要写出数组名,再使用下标引用操作符[ ],并写入元素对应的下标即可。比如

代码运行后打印了arr中下标为4的元素,即5。在对下标为4的元素输入了8后,打印出来的结果又变成了8。
5. 数组中元素的存放
数组中元素在内存中的存放是连续的,并且存放的地址通常是由低到高的。这是一个重要的特性。
这里用代码来验证,不理解没关系,后续文章中作者会介绍,只需知道这个特性即可。
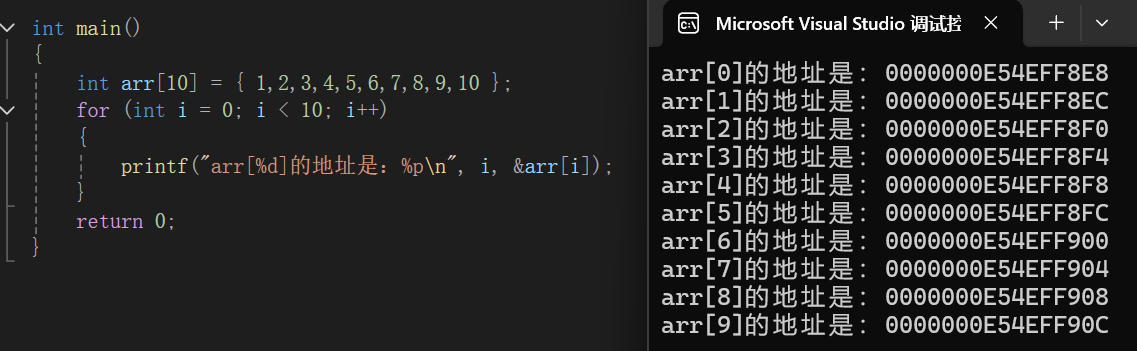
6. 数组的大小
数组的大小由存放元素的数据类型和个数决定,是 元素类型大小*个数,即所有元素的大小之和。
可以用sizeof()得到,由此也实现了求出数组元素个数的方式,即sizeof(arr) / sizeof(arr[0])求得。
这里也顺便推荐下作者常用的一种在循环中使用数组的方式。
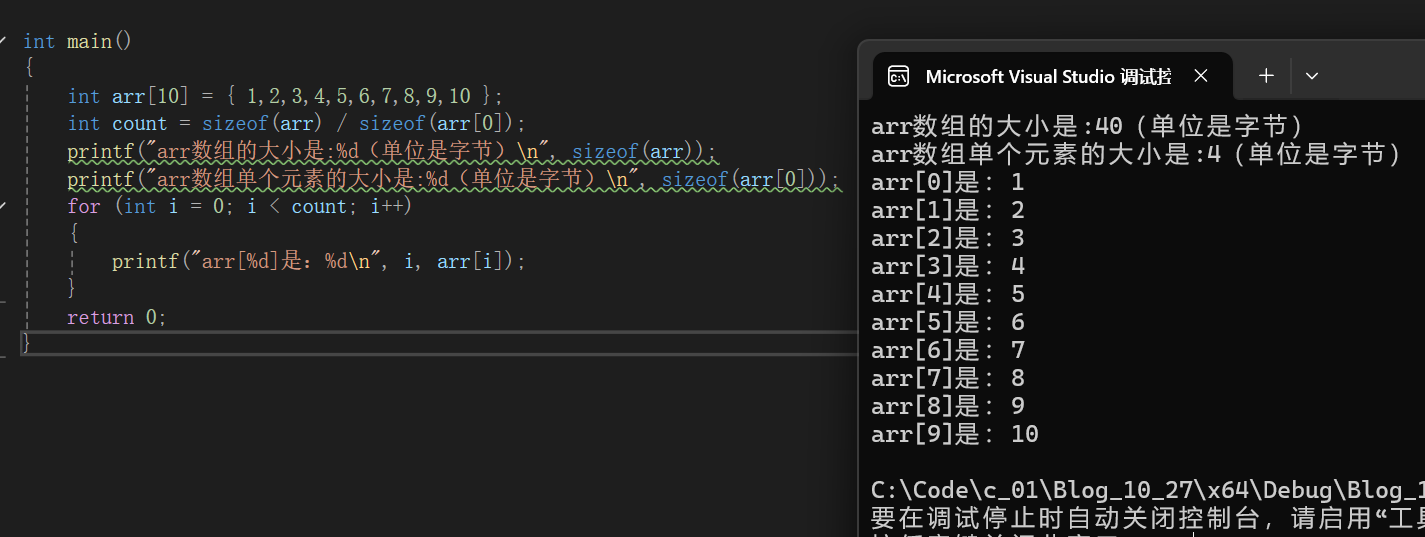
即先求得数组元素的个数count,然后让一个变量 i 从0开始,循环条件为 i < count,调整为 i++,这样就可以对数组中所有的元素一次操作。
3. 二维数组
1. 二维数组和多维数组
一个二维数组由多个一维数组组成。即二维数组的元素是一维数组。更高维的数组同理。
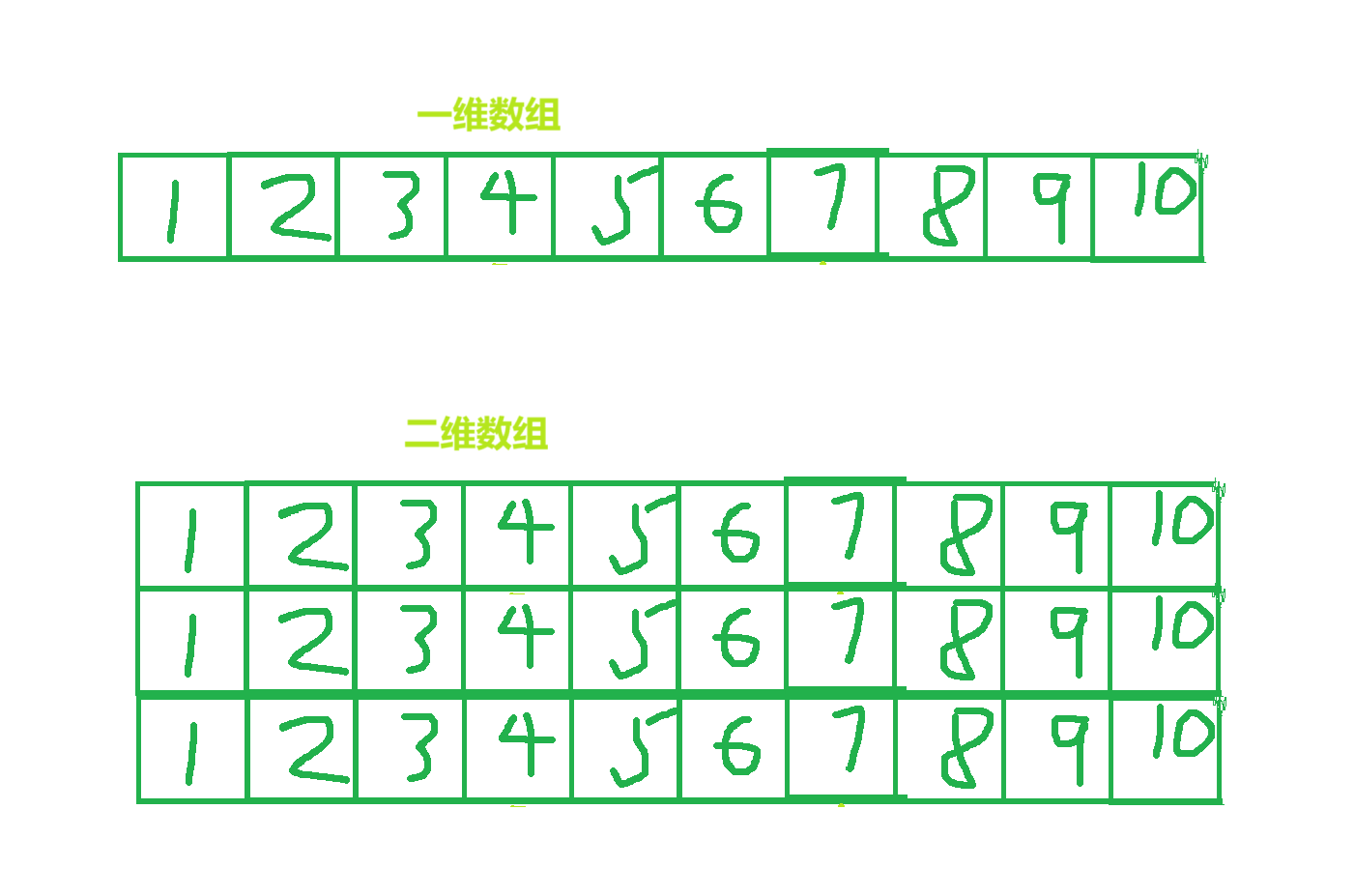
2. 二维数组的创建
type arr_name[常量值1][常量值2];
//如
int arr[2][3];• 常量值1表示行,常量值2表示列,例子中是一个有2行3列的二维数组。
• 其他规则与一维数组相同
3.二维数组的初始化
int age1[2][3]={ {1,2,3} , {4,5,6} };
int age2[2][3]={ 1,2,3,4 };
int age3[][3] ={ 1,2,3,4 };上面的语法都是符合规则的,从中我们可以发现下面几个特性。
• 第一种被成为完全初始化,再一次验证了二维数组的元素是一维数组。
• 从第二种可以发现,同样可以只初始化部分元素,剩余位置会进行默认初始化。元素会先按顺序先填第一行的每一列,再填入下一行(下面有图片说明)
• 从第三种中可以发现,在二维数组初始化时,行数可以省略,列数不能省略。这也好理解,上面我们有说,二维数组的元素是一维数组,列数也可以理解为这个一维数组中元素的个数;如果我们不归定一维数组中元素的个数,那究竟要向第一个一维数组中填入多少个元素后,再填入下一个数组呢?显然这是不确定的,编译器也不知道。
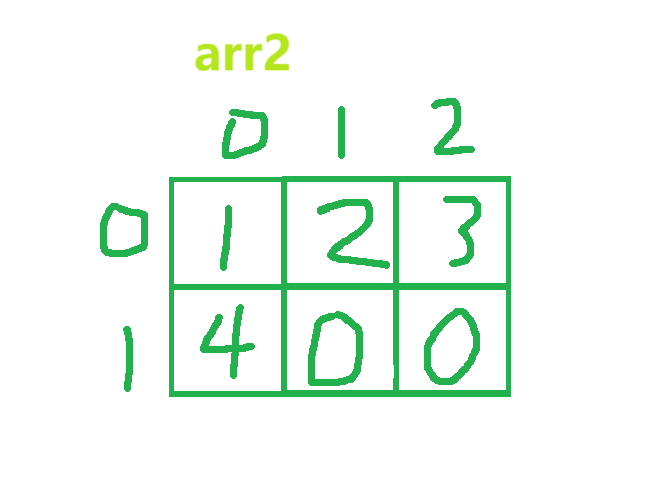
4. 二维数组的下标、元素存放、数组大小的特性与一维数组相同
• 无论是行还是列,下标均从0开始
• 无论跨不跨行,在内存中的存放都连续,且由低到高
• 数组的大小也是每个元素大小的和
4. 变长数组
在C99前,数组的创建时,数组大小只能使用常量,这十分不方便。而在C99中引入列变长数组(简称VLA)的规则,允许我们可以用变量表示数组的大小。比如下面的操作是允许的。
int n = a + b;
int arr[n];• 变长数组并不是说它的大小可以变化,而是指可以用变量描述它的大小,当它创建后,是不可以改变大小的。
• 变长数组不能初始化,这是因为变长数组的长度是在程序运行时确定的,而一般的数组通常在编译时确定大小。
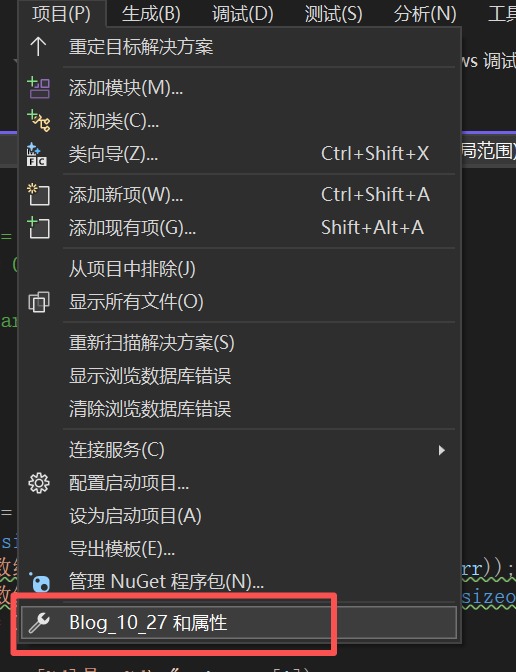
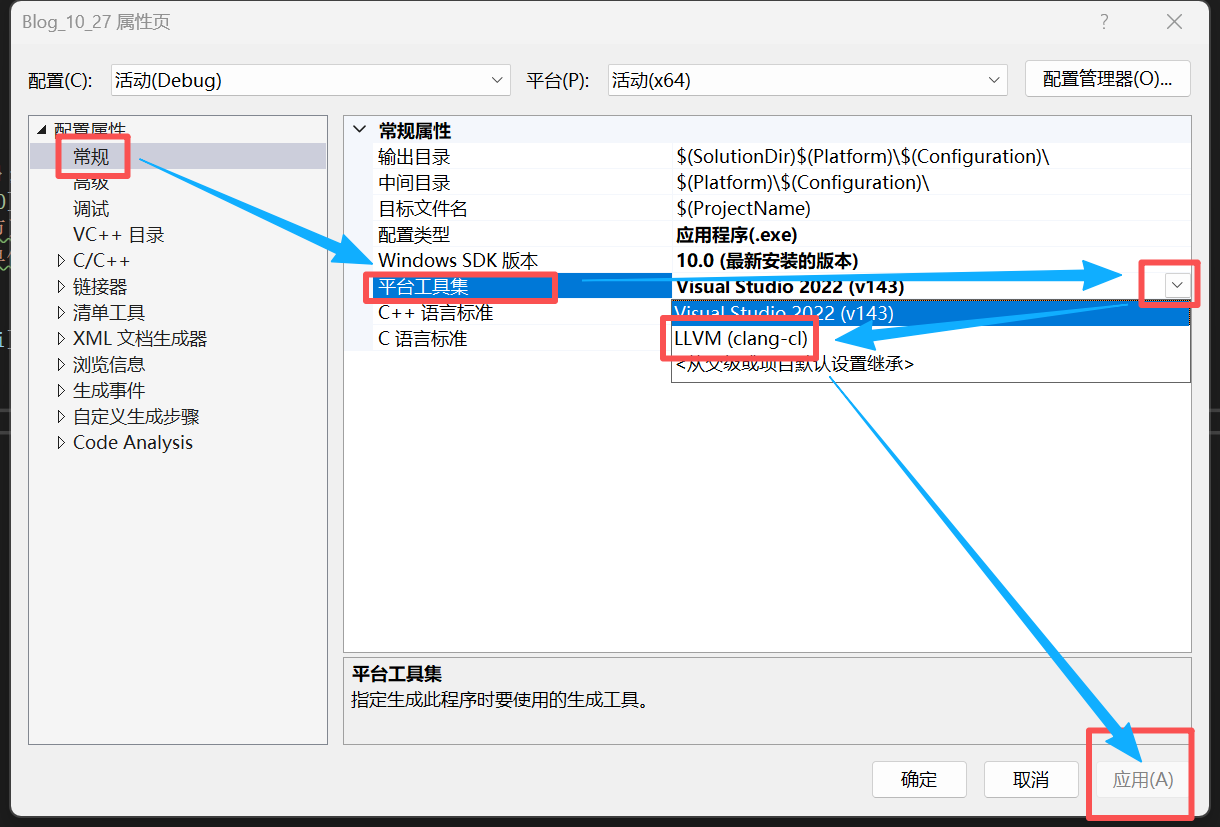
但我们发现,在VS2022中这样的操作仍然会报错,因为它并不支持使用这个特性。所以我们需要更换编译器。
• 更换Clang编译器
首先要下载Clang编译器,如果在安装时已下载可以跳过本步骤。
先去找到这个应用

下载好后按下面的图片继续操作

二、函数
1.函数
函数(function),又叫子程序。 是为了完成某项特定任务的一小段代码。
• 函数可以大致分为库函数和自定义函数
• 一个好的函数应满足高内聚、低耦合的特性:即专注于单一职责,尽量减少对于其他模块的依赖
2.库函数
C语言的国际标准ANSI C规定了一些常用函数的标准,被称为标准库。各个编译器厂商根据这个标准,给出了一些可以实现标准中功能的函数,被称为库函数。
• 使用库函数需要包含对应的头文件。比如用printf()需要先写 #include <stdio.h>
• 不同厂商中,相同的库函数实现逻辑很可能是不同的。因为标准库只给出了返回值,功能等标准,具体的实现并没有给出规定
下面是C语言官网给出的库函数标准,在里面可以了解到各种库函数的标准,如返回值,功能介绍,参数类型等等。
C Standard Library headers - cppreference.com
3. 自定义函数
自定义函数顾名思义,是程序员自己设计的函数。这使得对于重复性高的某些工作,我们可以实现“一劳永逸”的效果。
1. 自定义函数的语法
ret_type fun_name(形式参数)
{
}
//例如
int ADD(int x, int y)
{
int c = x + y;
return c;
}• ret_type 指返回值的类型,函数也可以没有返回值,这时写void。如果不写,默认为返回int类型的值。
• fun_name是函数名。同样可以遵循标示符的创建规则去创建。
• 形式参数的写法是 数据类型+变量名。不同的形参用 , 隔开。
• 函数是可以没有参数的。但是()不能省略。如int fuc(); ()是函数调用操作符,调用无参数的函数时,()也不能省略
• 形参的名字可以和实际参数等参数的名字重合,这是因为形参是对实际参数的一份临时拷贝,只有在调用函数时才会使用,调用完毕后后面的数据会对它进行覆盖,通常不会对实际参数造成影响。(这一点我们可以用反汇编观察到,后续作者可能会在其他文章中介绍)
• { }括起来的是函数体,即真正实现功能的代码。
• return是用来返回函数的返回值的,可以返回数值或者表达式。对于void类型的函数可以不写,也可以写成return; 。
• 当执行到return语句时,函数会获得返回值,并立即停止调用(就像循环中的break;一样,读到后,后面的代码将不会执行)
• return返回的值如果与函数描述的返回值类型不同,将会将其强制转化为符合类型的值
• 非void类型的函数,如果有分支语句,必须保证每种情况下都有return返回值,否则编译会出错
• 非void类型的函数,如果不写return返回值,将返回未知的值
2. 自定义函数的使用
下面的使用方式都是合规的
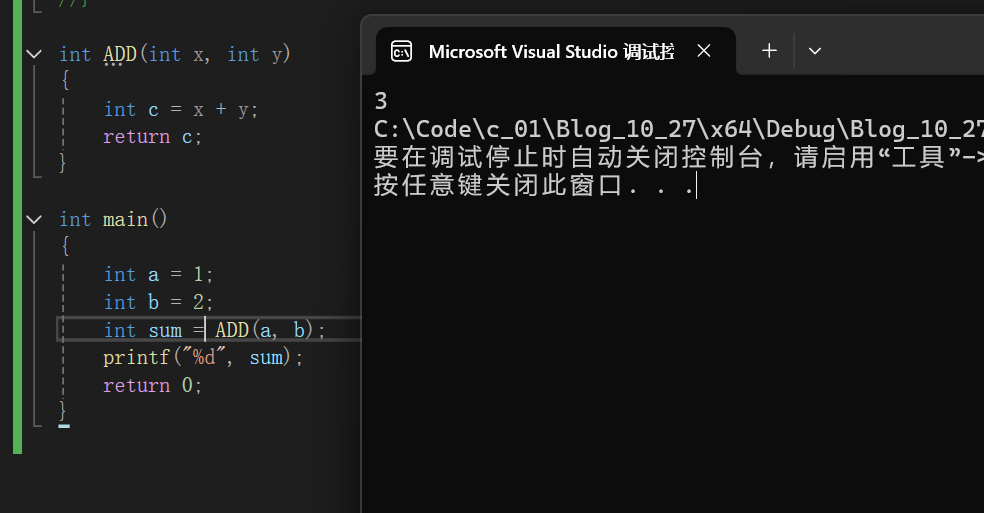
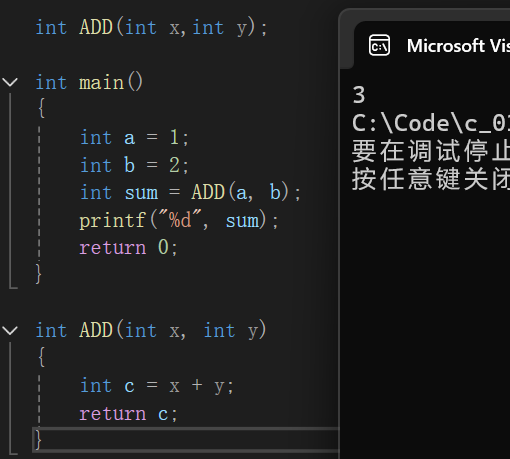
函数使用时的语法为Fuc(传入的实际参数); 如图中的ADD(a,b);
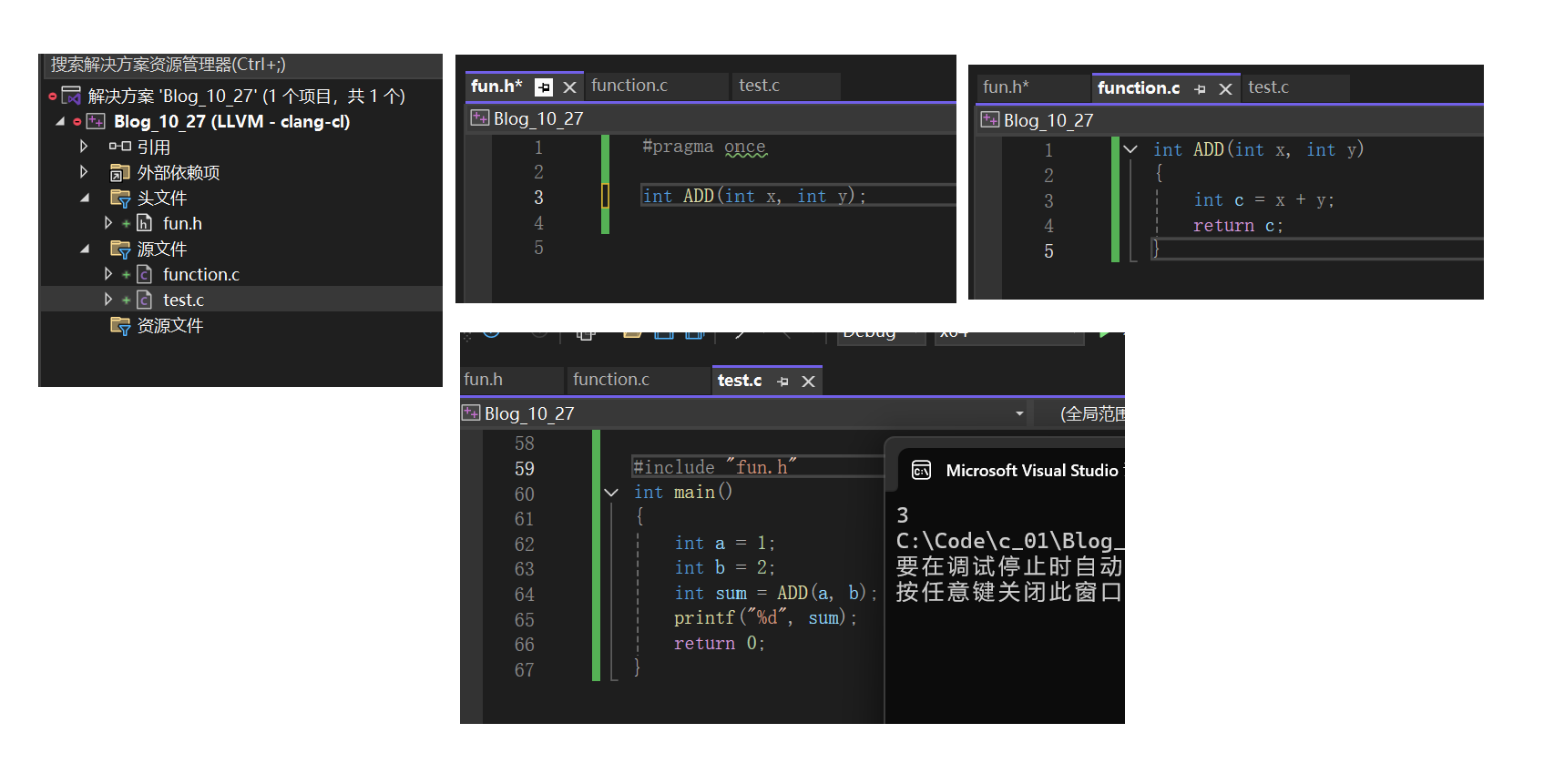
• 函数需要先声明再使用,如上图二。函数的定义是一种特殊的声明,如果前文已经有了定义,就不用再声明了,如上图一。函数的定义也可以在其他文件中,使用前先声明即可,库函数实际上就是这样操作的,库函数的声明在头文件中。我们也可以如此操作,下面有图像演示。需要注意的是,自己定义的头文件用 " "括起来,而不是 < >
• 函数的形参和实参必须匹配。个数,顺序,类型都得一致。
3. 嵌套调用和链式访问
函数支持嵌套调用和链式访问。
其中嵌套调用是指函数之间相互调用;链式访问指的是将一个函数的返回值作为另一个函数的参数。
4.作用域和生命周期
作用域:某个名字可以作用的范围。
生命周期:变量的创建(申请内存)到变量的销毁(回收内存)之间的时间段。
• 局部变量的作用域是变量所在的局部范围;生命周期是从创建开始,到出作用域后。
• 全局变量的作用域是整个项目;生命周期是整个程序的生命周期
5. static和extern
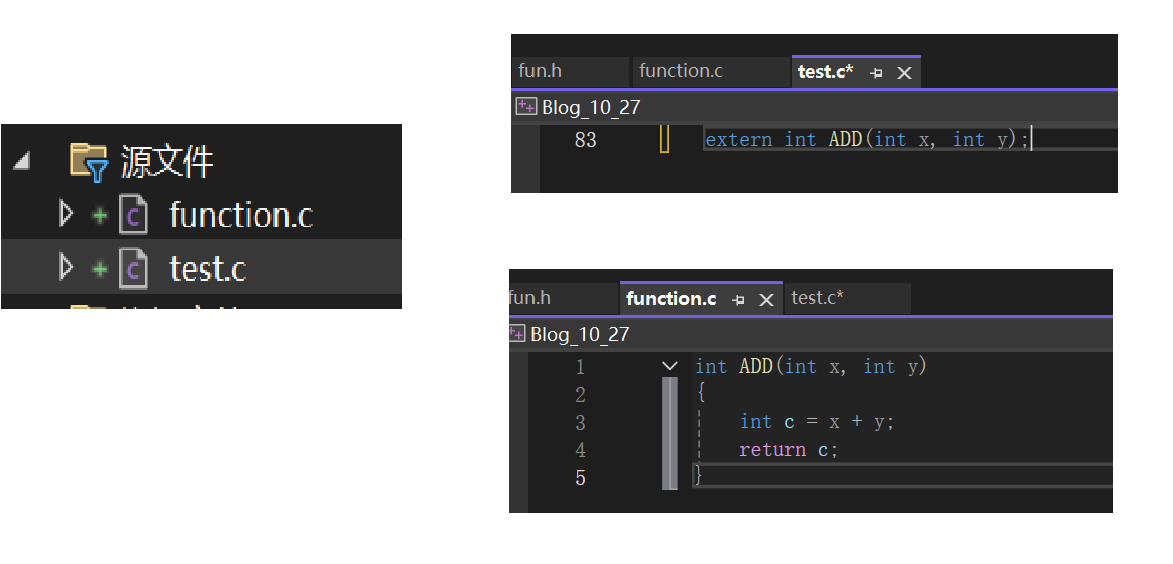
• extern用来声明外部符号
具有外部链接属性的变量,函数等,通过extern声明可以实现跨源文件使用。如图操作,即可在test.c中使用function.c中的自定义函数ADD()了
• static修饰局部变量
static表示静止的,当static修饰局部变量时,它的作用域不变,但生命周期会变长,不会随着出作用域而销毁,当程序结束时才会销毁。本质是:被static修饰的局部变量不再在栈区创建,而是在静态区创建。我们可以对比下面两段代码。
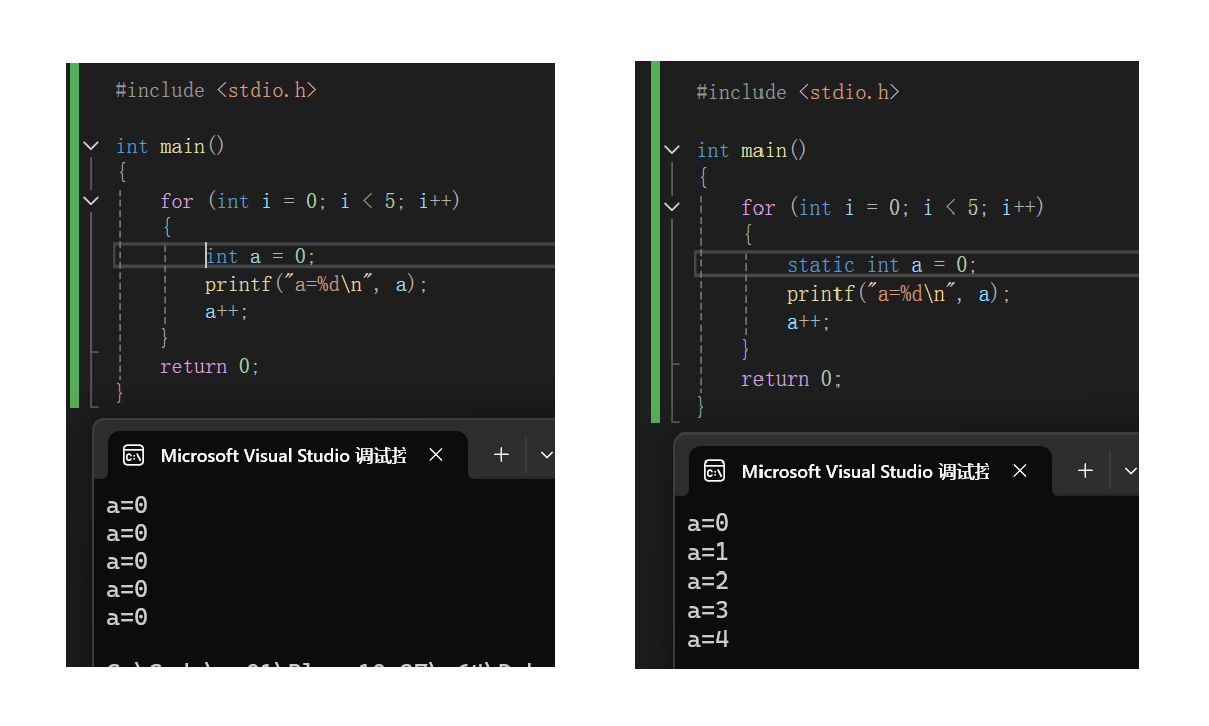
可见,当用static修饰时,局部变量a在每次循环时不会再重置。
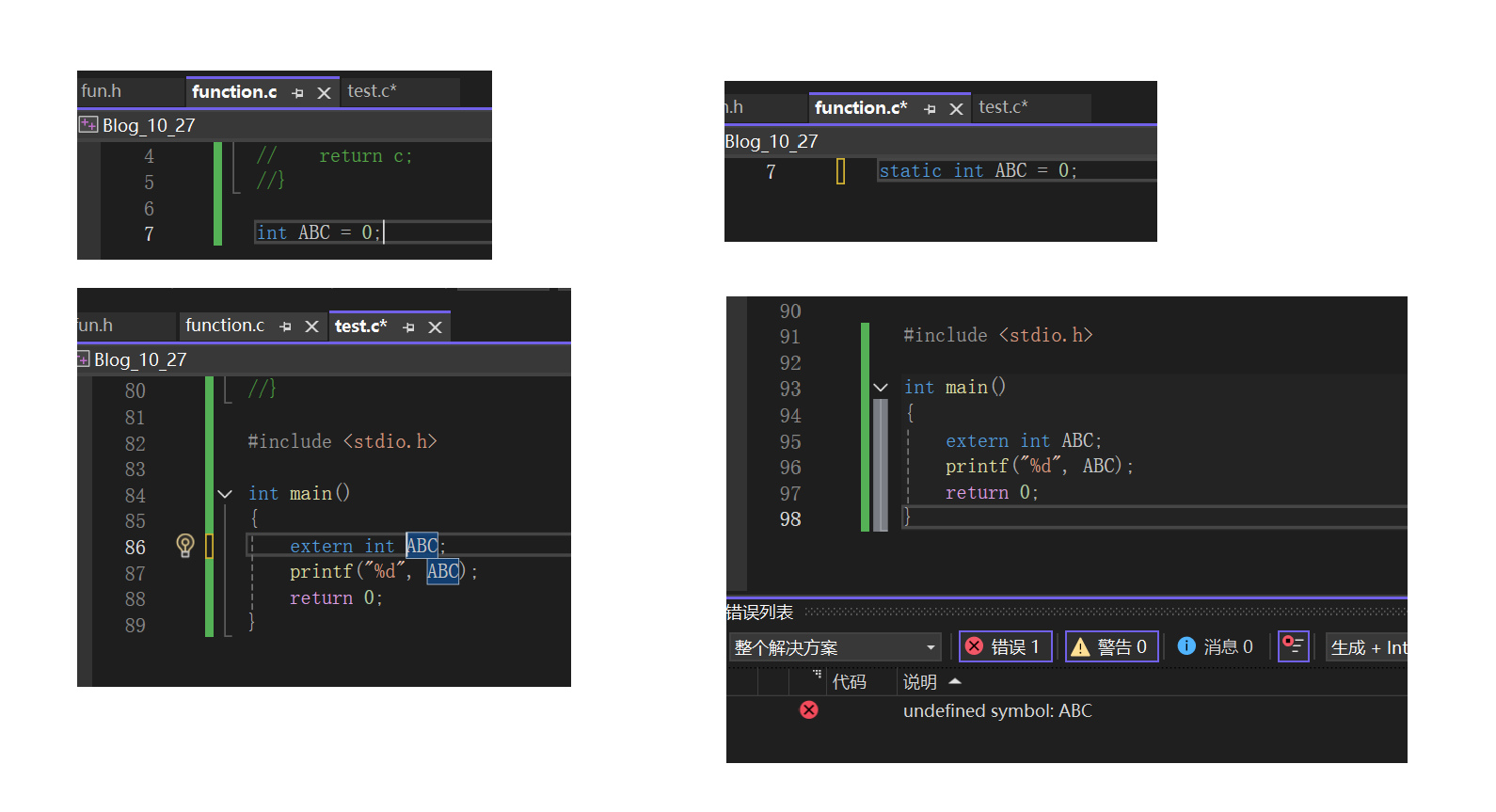
• static修饰全局变量
当static修饰全局变量时,该变量将只能在本源文件中使用,不能在其他源文件中使用。
这是因为,全局变量默认有外部链接属性,而static修饰后,外部链接属性变成了内部链接属性。即使在其他文件中声明了,也不能使用。
具体对比下面的两种操作。
三、生成随机数
生成随机数是我们会经常用到的一种操作,下面为大家介绍一种方式。
1. rand函数
C语言中提供了一个叫rand的函数,可以用来生成随机数。它包含在头文件<stdlib.h>中。函数原型如下
int rand(void);rand会返回一个伪随机数(即该随机数是有一个“种子”决定的),随机数的范围是0~RAND_MAX,最大值在不通编译器上可能不同,但大部分是32767。
这里我们来测试一下
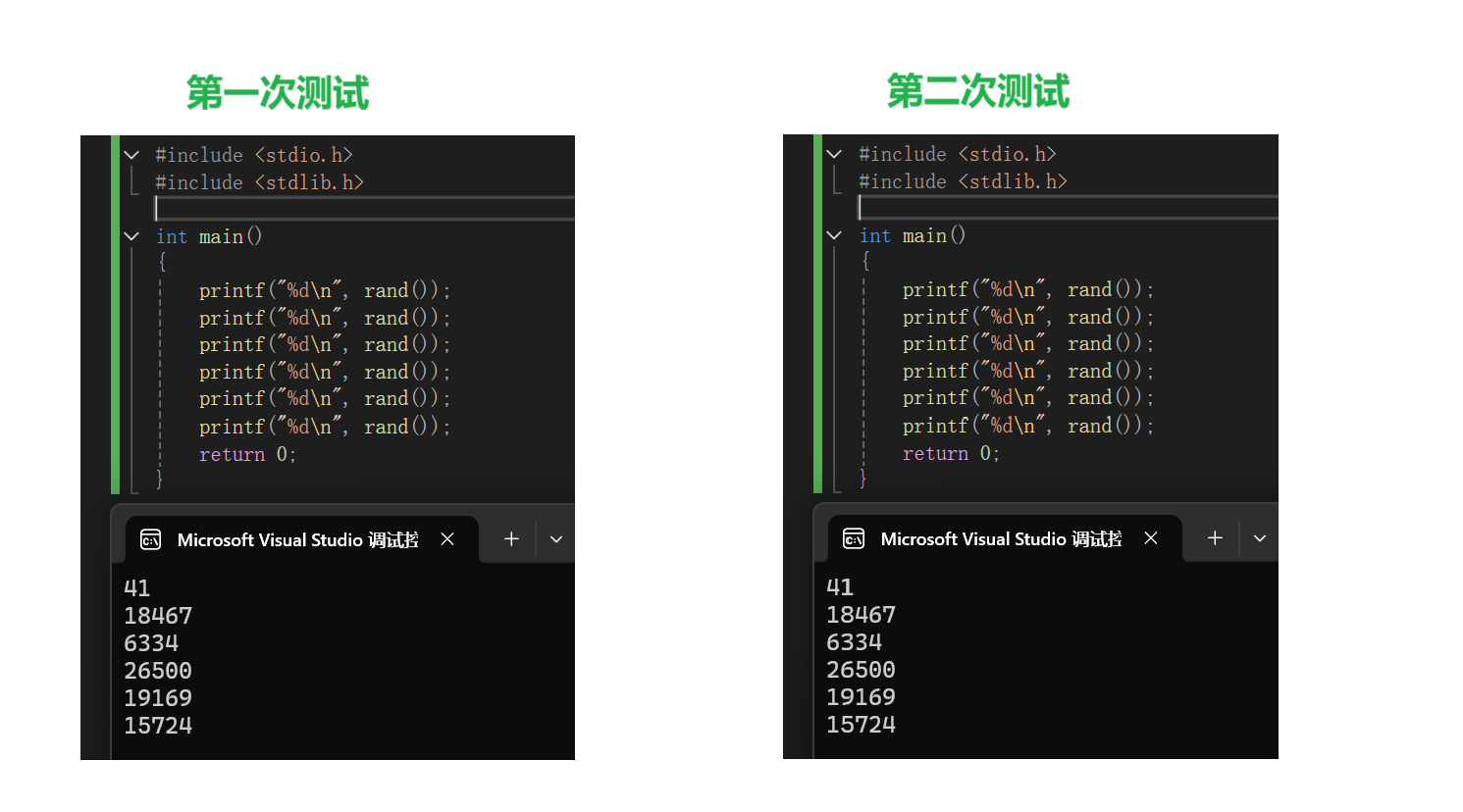
发现两次执行的结果居然是一模一样的。这是因为rand的种子默认是1,两次使用并没有改变种子。
所以要想生成真正的随机数,需要改变种子。
2. srand函数
srand函数是用来初始化随机数生成器的,可以改变rand函数生成随机数时使用的种子。
所以在使用rand函数前,通常会先用srand函数。
它同样包含在头文件stdlib.h中。
原型如下
void srand(unsigned int seed);3.time函数
C语言中有一个叫time的函数,可以获得时间戳。它包含在头文件time.h中。它的原型如下。
time_t time(time_t*timer);• time函数的返回值类型为time_t,本质上是32位或者64位的整数类型
• time函数的返回值是时间戳,时间戳指的是用当前日历的时间减掉1970年1月1日0时0秒0分的差值,单位是秒。
• time函数的参数timer如果是非NULL指针,函数会将差值放在timer指向的内存中带回去(只需理解这样得到的不是时间戳,后续作者会有对指针讲解的文章)
• 如果timer是NULL,就只返回时间戳
4. 生成随机数
有了上面三种函数,我们就可以用下面的方法生成随机数了。
srand((unsigned int)time(NULL));
rand();• 用时间戳来获取一个种子,这样每次运行程序时,时间戳都不同,获得的种子就不同。
• 由于time函数返回的值是time_t类型,不满足srand函数的参数类型,所以我们强制转换。
• 这种方式下,如果要多次生成随机数,srand函数也只需使用一次,不要频繁使用。因为计算机执行程序的时间非常短,而时间戳的单位是秒,这就使得多次调用可能并不会改变种子。’
我们再用上面rand中的代码测试一下。
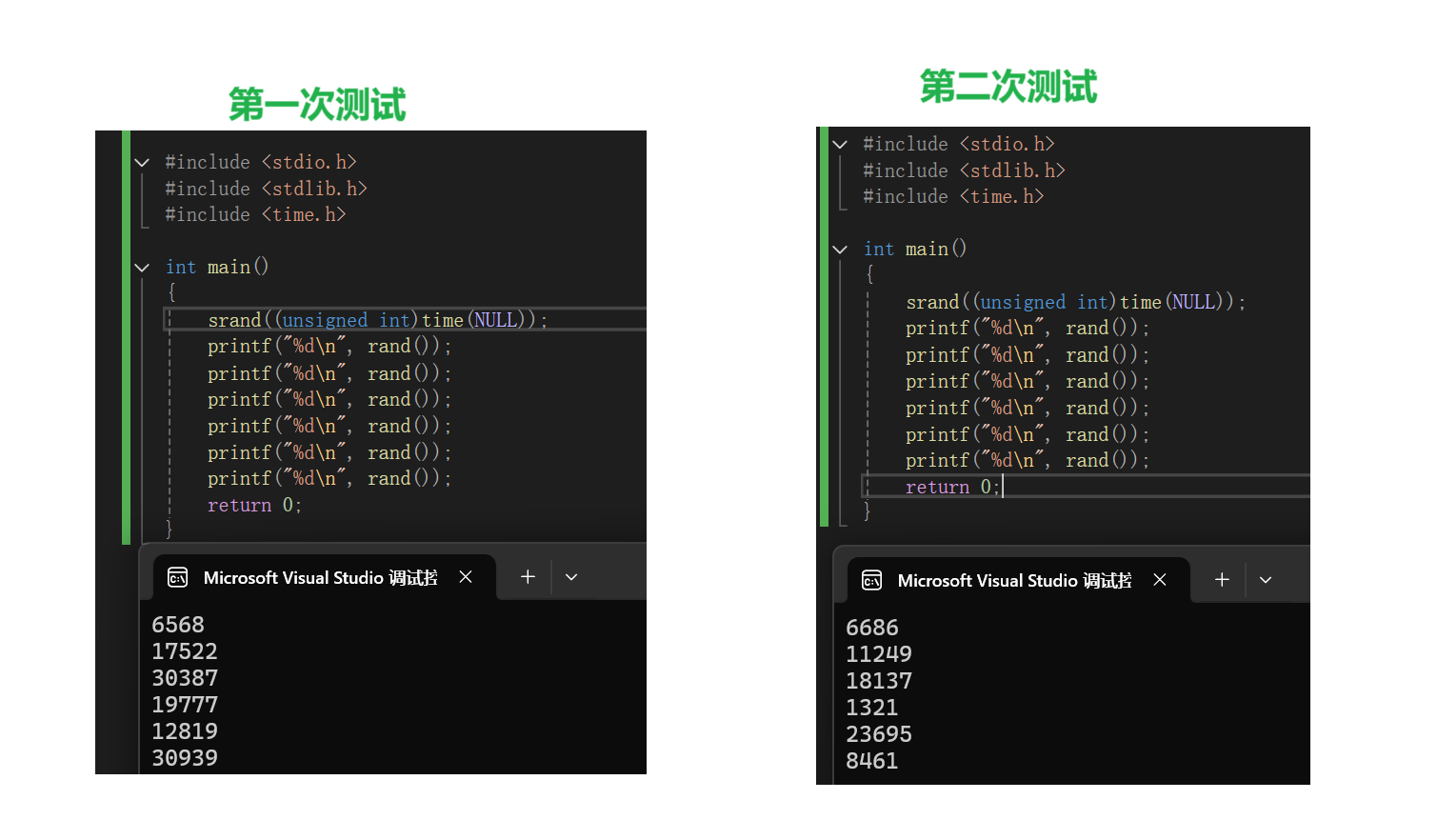
这下两次执行后生成的随机数就不同了。
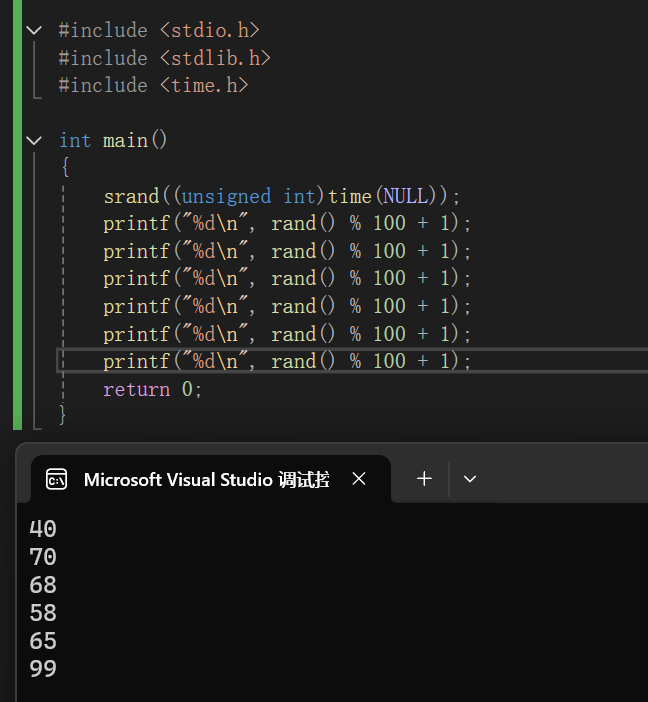
如果想将随机数的生成限定在一个范围内,我们可以结合前面的知识,使用一些算术操作符。
比如将随机数的生成限定在1~100内
总结
本文为大家介绍了数组、函数和生成随机数的一种方法。学完本篇文章和前面的文章,我们就可以完成很多程序的设计了。包括实现经典的扫雷游戏。考虑到扫雷游戏将会写出大概200行代码,结合作者自己的经验,这对于一个新手来说,是很容易出现各种意想不到的失误的。所以下篇作者将会编辑一个番外篇,简单介绍一下可能会用到的基础调试技巧,然后写扫雷游戏的实现,帮助大家练习几篇文章中学到的知识点。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









