




 本文详细介绍了Apache Flink的运行架构,包括JobManager、ResourceManager、TaskManager和Dispatcher的角色和交互,以及任务提交流程。此外,还深入探讨了Flink的并行度、任务链和ExecutionGraph。同时,文章讲解了Flink的API,涵盖Environment、Source、Sink和Transform等关键概念,为读者提供了丰富的代码示例。
本文详细介绍了Apache Flink的运行架构,包括JobManager、ResourceManager、TaskManager和Dispatcher的角色和交互,以及任务提交流程。此外,还深入探讨了Flink的并行度、任务链和ExecutionGraph。同时,文章讲解了Flink的API,涵盖Environment、Source、Sink和Transform等关键概念,为读者提供了丰富的代码示例。
文章目录
前言
你们好我是啊晨
今儿继续更新Flink技术。
废话不多说,内容很多选择阅读,详细。
请:
第四章 Flink 运行架构
4.1 Flink 运行时的组件
Flink 运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:
作业管理器(JobManager)、资源管理器(ResourceManager)、任务管理器(TaskManager), 以及分发器(Dispatcher)。因为 Flink 是用 Java 和 Scala 实现的,所以所有组件都会运行在Java
虚拟机上。每个组件的职责如下:
作业管理器(JobManager) JobManager要实现高可用
控制一个应用程序执行的主进程(JVM),也就是说,每个应用程序都会被一个不同的
JobManager 所控制执行。JobManager 会先接收到要执行的应用程序,这个应用程序会包括:
作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它
资源的 JAR 包。JobManager 会把 JobGraph 转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。JobManager 会向资源管
理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上
的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的
TaskManager 上。而在运行过程中,JobManager 会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。定期把快照存到检查点。
作业图JobGraph -> 执行图ExecutionGraph
作业图JobGraph、执行图ExecutionGraph是在JobManager 上生成的。
快照是在内存中,检查点是在hdfs中。
资源管理器(ResourceManager)
主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是 Flink 中
定义的处理资源单元。Flink 为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及 standalone 部署。当 JobManager 申请插槽资源时,ResourceManager会将有空闲插槽的 TaskManager 分配给 JobManager。如果 ResourceManager 没有足够的插槽来满足 JobManager 的请求,它还可以向资源提供平台发起会话,以提供启动 TaskManager进程的容器。另外,ResourceManager 还负责终止空闲的 TaskManager,释放计算资源。
任务管理器(TaskManager)
Flink 中的工作进程(JVM)。通常在 Flink 中会有多个 TaskManager 运行,每一个 TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了 TaskManager 能够执行的任务数量。启动之后,TaskManager 会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager 就会将一个或者多个插槽提供给 JobManager 调用。JobManager 就可以向插槽分配任务(tasks)来执行了。在执行过程中,一个 TaskManager 可以跟其它运行同一应用程序的 TaskManager 交换数据(有分区,分组的时候groupby、keyby,就会有数据在TaskManager 间交换)。
分发器(Dispatcher)
可以跨作业运行,它为应用提交提供了 REST 接口。当一个应用被提交执行时,分发器
就会启动并将应用移交给一个 JobManager。由于是 REST 接口,所以 Dispatcher 可以作为集群的一个 HTTP 接入点,这样就能够不受防火墙阻挡。Dispatcher 也会启动一个 Web UI,用来方便地展示和监控作业执行的信息。Dispatcher 在架构中可能并不是必需的,这取决于应用提交运行的方式。
4.2 任务提交流程
我们来看看当一个应用提交执行时,Flink 的各个组件是如何交互协作的:
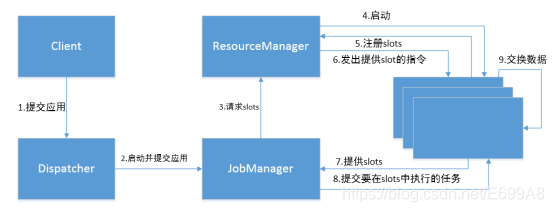
上图是从一个较为高层级的视角,来看应用中各组件的交互协作。如果部署的集群环境
不同(例如 YARN,Mesos,Kubernetes,standalone 等),其中一些步骤可以被省略,或是有些组件会运行在同一个 JVM 进程中。
1、2、当一个应用被提交执行时,分发器就会启动并将应用移交给一个 JobManager。
3、JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。
4、5、TaskManager 启动之后,TaskManager 会向资源管理器注册它的插槽
6、当 JobManager 申请插槽资源时,ResourceManager会将有空闲插槽的 TaskManager 分配给 JobManager。
7、当 JobManager 申请插槽资源时,ResourceManager会将有空闲插槽的 TaskManager 分配给 JobManager。
8、一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager 上。而在运行过程中,JobManager 会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。定期把快照存到检查点。
9、TaskManager 间会有数据的交互。
具体地,如果我们将 Flink 集群部署到 YARN 上,那么就会有如下的提交流程:
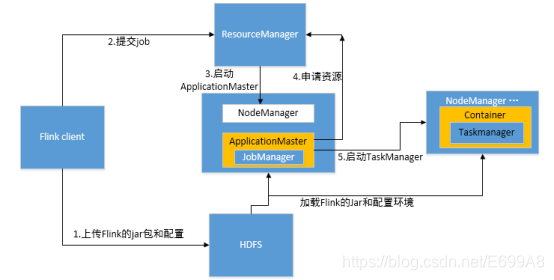
1、Flink 任务提交后,Client 向 HDFS 上传 Flink 的 Jar 包和配置
2、之后向 Yarn ResourceManager 提交任务
3、ResourceManager 分配 Container 资源并通知对应的NodeManager 启动 ApplicationMaster
4、ApplicationMaster 启动后加载 Flink 的 Jar 包和配置构建环境,然后启动 JobManager,之后 ApplicationMaster 向 ResourceManager申请资源启动 TaskManager
5、ResourceManager 分 配 Container 资 源 后 , 由ApplicationMaster 通 知 资 源 所 在 节 点 的 NodeManager 启 动 TaskManager ,
6、NodeManager 加载 Flink 的 Jar 包和配置构建环境并启动 TaskManager,TaskManager启动后向 JobManager 发送心跳包,并等待 JobManager 向其分配任务
4.3 任务调度原理
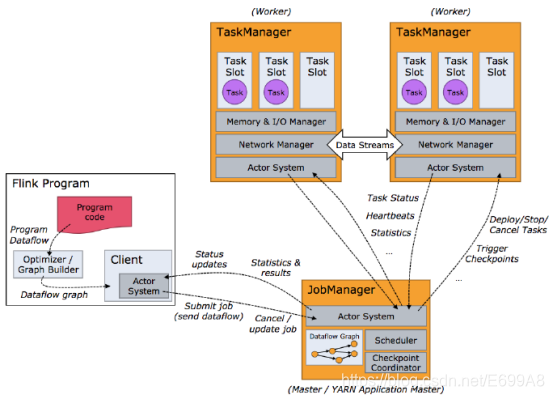
客户端不是运行时和程序执行的一部分,但它用于准备并发送dataflow(JobGraph)给 Master(JobManager),然后,客户端断开连接或者维持连接以等待接收计算结果。
当 Flink 集 群 启 动 后 , 首 先 会 启 动 一 个 JobManger 和一个或多个的TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者Jobmanager,TaskManager均为独立的 JVM 进程。
Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming 的任务),也可以不结束并等待结果返回。
JobManager 主 要 负 责 调 度 Job 并 协 调 Task 做 checkpoint, 职 责 上 很 像Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
4.3.1 TaskManger 与 Slots
Flink 中每一个 worker(TaskManager)都是一个 JVM 进程,它可能会在独立的线程上执行一个或多个 subtask。为了控制一个 worker 能接收多少个 task,worker 通 过 task slot 来进行控制(一个 worker 至少有一个 task slot)。
每个 task slot 表示 TaskManager 拥有资源的一个固定大小的子集。假如一个TaskManager 有三个 slot,那么它会将其管理的内存分成三份给各个 slot。资源 slot化意味着一个 subtask 将不需要跟来自其他 job 的 subtask 竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备(slot主要是用来隔绝内存)。需要注意的是,这里不会涉及到 CPU 的隔离,slot 目前仅仅用来隔离 task 的受管理的内存。
通过调整 task slot 的数量,允许用户定义 subtask 之间如何互相隔离。如果一个TaskManager 一个 slot,那将意味着每个 task group 运行在独立的 JVM 中(该 JVM可能是通过一个特定的容器启动的),而一个 TaskManager 多个 slot 意味着更多的subtask 可以共享同一个 JVM。而在同一个 JVM 进程中的 task 将共享 TCP 连接(基于多路复用)和心跳消息。它们也可能共享数据集和数据结构,因此这减少了每个task 的负载。
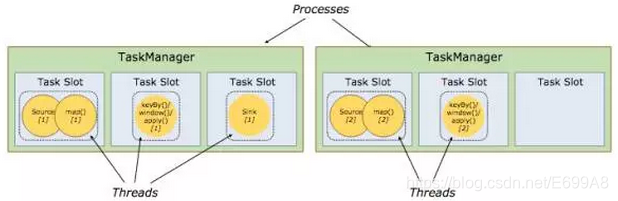
图taskManager和slots
如图有两个Taskmanager,每个Taskmanager有3个slot,共有六个插槽,能同时执行六个并行的任务,这个例子里有5个任务:第一个TaskSlot中有一个source, 有一个map ,source、map是一个任务 ,这个任务有两个并行的子任务,细分后有两个子任务。后面Keyby windowapply也有两个并行的子任务。总共并行分配的任务有5个。
默认情况下,Flink 允许子任务共享 slot,即使它们是不同任务的子任务(前提是它们来自同一个 job)。 这样的结果是,一个 slot 可以保存作业的整个管道。
Task Slot 是静态的概念,是指 TaskManager 具有的并发执行能力,可以通过参数 taskmanager.numberOfTaskSlots 进行配置;而并行度 parallelism 是动态概念,即 TaskManager 运行程序时实际使用的并发能力,可以通过参数 parallelism.default进行配置。
也就是说,假设一共有 3 个 TaskManager,每一个 TaskManager 中的分配 3 个TaskSlot,也就是每个 TaskManager 可以接收 3 个 task,一共 9 个 TaskSlot,如果我们设置 parallelism.default=1,即运行程序默认的并行度为 1,9 个 TaskSlot 只用了 1个,有 8 个空闲,因此,设置合适的并行度才能提高效率。
4.3.2 程序与数据流(DataFlow)
所有的 Flink 程序都是由三部分组成的: Source 、Transformation 和 Sink。Source 负责读取数据源,Transformation 利用各种算子进行处理加工,Sink 负责输出。
在运行时,Flink 上运行的程序会被映射成“逻辑数据流”(dataflows),它包含了这三部分。每一个 dataflow 以一个或多个 sources 开始以一个或多个 sinks 结 束。dataflow 类似于任意的有向无环图(DAG)。在大部分情况下,程序中的转换运算(transformations)跟 dataflow 中的算子(operator)是一一对应的关系,但有时候,一个 transformation 可能对应多个 operator。
4.3.3 执行图(ExecutionGraph)
dataFlow(StreamGraph)->JobGraph ->ExecutionGraph ->物理执行图
由 Flink 程序直接映射成的数据流图是 StreamGraph(client上生成),也被称为逻辑流图(dataFlow),因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink 需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。
StreamGraph、JobGraph (client上生成) ExecutionGraph jobmanager上生成 物理执行图
taskmananger上运行
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
ExecutionGraph : JobManager 根 据 JobGraph 生 成 ExecutionGraph 。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
4.3.4 并行度(Parallelism)
Flink 程序的执行具有并行、分布式的特性。
在执行过程中,一个流(stream)包含一个或多个分区(stream partition),而每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中彼此互不依赖地执行。
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
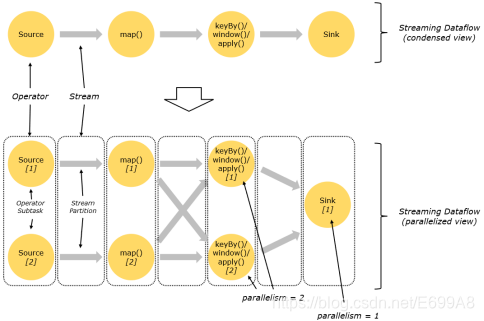
Stream 在算子之间传输数据的形式可以是 one-to-one(forwarding)的模式也可以
是 redistributing 的模式,具体是哪一种形式,取决于算子的种类。
One-to-one:stream(比如在 source 和 map operator 之间)维护着分区以及元素的顺序。那意味着 map 算子的子任务看到的元素的个数以及顺序跟 source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap 等算子都是 one-to-one 的对应关系。类似于 spark 中的窄依赖。
Redistributing:stream(map()跟 keyBy/window 之间或者 keyBy/window 跟 sink之间)的分区会发生改变。每一个算子的子任务依据所选择的 transformation 发送数据到不同的目标任务。例如,keyBy() 基于 hashCode 重分区、broadcast 和 rebalance会随机重新分区,这些算子都会引起 redistribute 过程,而 redistribute 过程就类似于Spark 中的 shuffle 过程。类似于 spark 中的宽依赖。
4.3.5 任务链(Operator Chains)
相同并行度的 one to one 操作,Flink 这样相连的算子链接在一起形成一个 task,原来的算子成为里面的一部分。将算子链接成 task 是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程 API 中进行指定。

第五章 Flink API
Flink处理主要是分为流处理和批量处理。流处理、批量处理使用的api也大致相同,两者有很多相似之处,但是也有略微的不同之处,下面就两者api共同介绍一下。
最难写最复杂就是tramsform,这里面涉及到业务,不同的业务有不同的处理规则。
5.1 Environment
5.1.1 getExecutionEnvironment(常用)
创建一个执行环境,表示当前执行程序的上下文。 如果程序是独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,也就是说,getExecutionEnvironment 会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
如果没有设置并行度,会以 flink-conf.yaml 中的配置为准,默认是 1。

5.1.2 createLocalEnvironment
返回本地执行环境,需要在调用时指定默认的并行度。
val env = StreamExecutionEnvironment.createLocalEnvironment(1)
5.1.3 createRemoteEnvironment
返回集群执行环境,将 Jar 提交到远程服务器。需要在调用时指定 JobManager的 IP 和端口号,并指定要在集群中运行的 Jar 包。Jobmanager rpc端口是6123
val env = ExecutionEnvironment.createRemoteEnvironment(“jobmanage-hostname”, 6123,“YOURPATH//wordcount.jar”)
5.2 Source
5.2.1 基于本地集合的source
在一个本地内存中,生成一个集合作为Flink处理的source。
离线处理代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object ListSource {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[String] = env.fromCollection(List("hadoop spark","hive hbase"))
listDataSet.print()
}
}
实时处理代码如下:
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object ListSourceStream {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val listDataStream: DataStream[String] = env.fromCollection(List("hadoop spark","hive hbase"))
listDataStream.print()
env.execute("ListSourceStream is runned")
}
}
5.2.2 基于本地文件的source
导入本地文本数据作为数据源。
离线处理代码如下:
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
object FileSource {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val fileDataSet: DataSet[String] = env.readTextFile("C:\\Users\\thinkpad\\Desktop\\words.txt")
fileDataSet.print()
}
}
实时处理代码如下:
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object FileSourceStream {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val fileDataStream: DataStream[String] = env.readTextFile("C:\\Users\\thinkpad\\Desktop\\words.txt")
fileDataStream.print()
env.execute("FileSourceStream is runned")
}
}
5.2.3 基于HDFS的source
读取hdfs文件,作为数据源。
离线处理代码如下:
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
object hdfsSource {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val hdfsDataSet: DataSet[String] = env.readTextFile("hdfs://linux01:9000/a.txt")
hdfsDataSet.print()
}
}
实时处理代码如下:
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object hdfsSourceStream {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val hdfsDataStream: DataStream[String] = env.readTextFile("hdfs://linux01:9000/a.txt")
hdfsDataStream.print()
env.execute("hdfsSourceStream is runned")
}
}
5.2.4 基于 kafka 消息队列的source
需要引入 kafka 连接器的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>1.7.0</version>
</dependency>
处理代码如下:
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
import org.apache.flink.api.scala._
object kafkaSourceStream {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")
props.setProperty("group.id", "consumer-group")
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("auto.offset.reset", "latest")
//SimpleStringSchema反序列化工具
val kafkaDataStream: DataStream[String] =
env.addSource(new FlinkKafkaConsumer010[String]("test",new SimpleStringSchema(),props))
kafkaDataStream.print()
env.execute(“kafkaSourceStream is runned”)
}
}
5.2.5 自定义 Source作为数据源
除了以上的source数据来源,我们还可以自定义source,只是继承SourceFunction即可。
自定义source代码如下:
import org.apache.flink.streaming.api.functions.source.SourceFunction
class MySource extends SourceFunction[String] {
//定义标志位用来标记是否正常运行
var running = true
override def cancel(): Unit = {
running = false
}
override def run(sourceContext: SourceFunction.SourceContext[String]): Unit = {
val data: Range.Inclusive = 1.to(10)
while (running) {
data.foreach(t => {
sourceContext.collect(t.toString)
})
}
}
}
调用自定义source代码如下:
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
object DefineSource {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val defineSource: DataStream[String] = env.addSource(new MySource())
defineSource.print()
env.execute("DefineSource is runned")
}
}
5.3 Sink
sink 也就是Flink运行完后,最终要将数据输出到哪儿。
5.3.1基于本地内存集合的sink
将数据最终输出到内存中的集合中。
示例代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object listSink {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[String] = env.fromCollection(List("hadoop","spark","hive"))
val list: Seq[String] = listDataSet.collect()
list.foreach(println(_))
}
}
5.3.2基于本地文件的sink
将结果输出到本地文件系统中。
示例代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object fileSink {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val fileDataSet: DataSet[String] = env.fromCollection(List("hadoop","spark"))
fileDataSet.writeAsText("C:\\Users\\thinkpad\\Desktop\\print.txt")
env.execute("fileSink is runned")
}
}
5.3.3基于HDFS文件系统的sink
将结果输出到hdfs文件系统中。
示例代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object hdfsSink {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val hdfsDataSet: DataSet[String] = env.fromCollection(List("hadoop","spark"))
hdfsDataSet.writeAsText("hdfs://linux01:9000/hdfsSink")
env.execute("hdfsSink is runned")
}
}
5.3.4基于Kafka消息队列的sink
将结果输出到kafka文件系统中,用flink作为kafka的生产者。
示例代码如下:
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010
object kafkaSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")
props.setProperty("group.id", "consumer-group")
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("auto.offset.reset", "latest")
val listDataStream: DataStream[String] = env.fromCollection(List("hadoop","spark"))
listDataStream.addSink(new FlinkKafkaProducer010[String]("linux01:9092,linux02:9092,linux03:9092","test",new SimpleStringSchema()))
env.execute("kafkaSink is runned")
}
}
5.3.5基于Redis非关系型数据库的sink
将计算结果存储到redis非关系数据库中。
导入flink-redis依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.0</version>
</dependency>
定义一个redis的mapper类,继承RedisMapper类,用于定义保存到 redis时调用的命令,代码如下:
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
class MyRedisMapper extends RedisMapper[String]{
//定义保存到redis中的命令
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET,"redis")
}
override def getKeyFromData(t: String): String = {
t.hashCode.toString
}
override def getValueFromData(t: String): String = {
t
}
}
将结果输入到redis代码如下:
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
object RedisSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val listDataStream: DataStream[String] = env.fromCollection(List("hadoop","spark"))
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).setDatabase(0).build()
listDataStream.addSink(new RedisSink[String](conf,new MyRedisMapper))
env.execute("RedisSink is runned")
}
}
5.3.6基于JDBC自定义sink
将计算结果存储到关系数据库中,如mysql等。
导入依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
实现MyJdbcSink类,继承RichSinkFunction,用来是实现保存到mysql中调用的命令。
代码如下:重写方法的时候将原有的super调用都删除
import java.sql
import java.sql.DriverManager
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
//为什么继承的是富函数
class MyJdbcSink extends RichSinkFunction[String] {
//定义连接参数成员属性
var conn: sql.Connection = _
var insertStmt: sql.PreparedStatement = _
//打开连接
override def open(parameters: Configuration): Unit = {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test",
"root", "root")
insertStmt = conn.prepareStatement("INSERT INTO infoTest VALUES (?, ?)")
}
//执行sql语句
override def invoke(value: String, context: SinkFunction.Context[_]): Unit = {
insertStmt.setString(1,value.hashCode.toString)
insertStmt.setString(2,value)
insertStmt.execute()
}
//关闭资源
override def close(): Unit = {
insertStmt.close()
conn.close()
}
}
将结果写入mysql,调用自定义mysql类,代码如下:
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
object mysqlSInk {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val listDataSream: DataStream[String] = env.fromCollection(List("hadoop","spark"))
listDataSream.addSink(new MyJdbcSink())
env.execute("mysqlSInk is runned")
}
}
5.4 Transform
在flink中有类似于spark的一类转换算子,就是transform,在Flink的编程体系中,我们获取到数据源之后,需要经过一系列的处理即transformation操作,再将最终结果输出到目的Sink使数据落地。
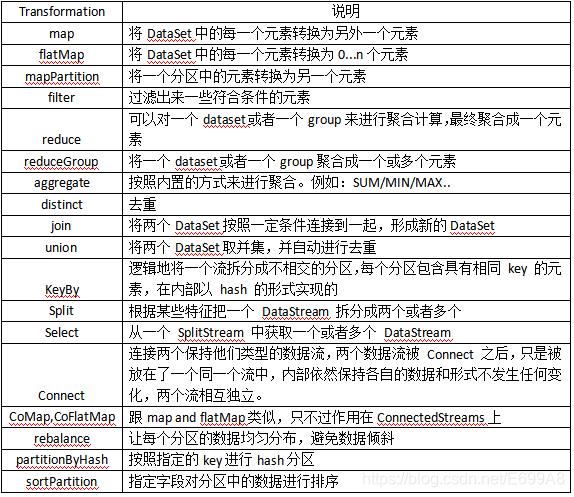
常用的transform转换算子如下:
5.4.1 map
将DataSet中的每一个元素转换为另外一种形式的元素
示例代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[Int] = env.fromCollection(List(1,2,3))
val result: DataSet[Int] = listDataSet.map(_*2)
result.print()
}
}
5.4.2 flatMap
flatMap也是一种类似于遍历循环,是将每一个元素按照特定的标识切分,变成多个元素。
如将集合中每个元素按照空格切分,示例代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[String] = env.fromCollection(List("hadoop spark","hive mysql","hbase kafka"))
val result: DataSet[String] = listDataSet.flatMap(_.split(" "))
result.print()
}
}
5.4.3 mapPartition
mapPartition:中的函数是在每个分区运行一次
map :每个元素运行一次
mapPartition是按照分区进行处理数据,mapPartition传入是一个迭代,是将分区中的元素进行转换,map 和 mapPartition 的效果是一样的,但如果在map的函数中,需要访问一些外部存储。例如:
访问mysql数据库,需要打开连接,此时map效率较低。而使用 mapPartition 可以有效减少连接数,提高效率。
示例代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[String] = env.fromCollection(List("hadoop spark","hive mysql","hbase kafka"))
val result: DataSet[String] = listDataSet.mapPartition(iter => {
iter.flatMap(_.split(" "))
})
result.print()
}
}
5.4.4 Filter
filter是遍历循环dataset中每一个元素,filter中满足表达式的过滤出来,不满足表达式的过滤掉。
示例代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[String] = env.fromCollection(List("hadoop spark","hive","hbase kafka"))
val result: DataSet[String] = listDataSet.filter(_.length>=5)
result.print()
}
}
5.4.5 reduce
reduce是对一个 dataset 或者一个 group 来进行聚合计算,按照表达逻辑最终聚合成一个元素。
示例代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[Int] = env.fromCollection(List(1,2,3,4))
val result = listDataSet.reduce(_+_)
result.print()
}
}
5.4.6 reduceGroup
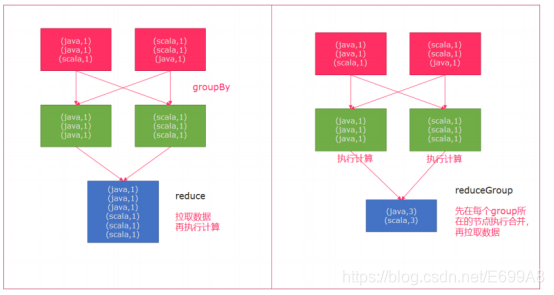
reduceGroup是对一个dataset或者一个group来进行聚合计算,按照表达逻辑最终聚合成一个元素。reduce是将数据一个个拉取到另外一个节点,然后再执行计算。reduceGroup是先在每个group所在的节点上执行计算,然后再拉取。执行效率上reduceGroup效率更高,两者区别如图:
示例代码如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[Int] = env.fromCollection(List(1,2,3,4))
val result = listDataSet.reduceGroup(iter=>{
iter.reduce(_+_)
})
result.print()
}
}
5.4.7 aggregate
按照内置的方式来进行聚合。例如:SUM/MIN/MAX等,要使用aggregate,只能使用字段名或索引名称来进行分组 groupBy(0)。
示例代码如下:
import org.apache.flink.api.java.aggregation.Aggregations
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[(String,Int)] = env.fromCollection(List(("java",1),("spark",2),("spark",3),("java",4)))
val result = listDataSet.groupBy(0).aggregate(Aggregations.SUM, 1)
result.print()
}
}
//groupBy(1).sum(2) 后面的数字是表示第几个字段,小标是从0开始
//groupBy(1) 按照第几个元素分组
//sum(2) 对几个字段累加
//没分组的字段 没有累加字段? 这些字段在结果中会出现吗? 这个字段在这个分组中最后一次出现数值
5.4.8 distinct
将元素去重。
示例代码如下:
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet: DataSet[(String,Int)] = env.fromCollection(List(("java",4),("spark",2),("spark",3),("java",4)))
val result = listDataSet.distinct()
result.print()
}
}
5.4.9 join
将两个特殊的dataset进行关联,要求dataset必须是(k,v)类型,按照k进行关联。
示例代码如下:
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val listDataSet1: DataSet[(String, Int)] = env.fromCollection(List(("java", 4), ("spark", 2), ("mysql", 3), ("hbase", 4)))
val listDataSet2: DataSet[(String, Int)] = env.fromCollection(List(("java", 1), ("spark", 1),("hive",1)))
val result: JoinDataSet[(String, Int), (String, Int)] = listDataSet1.join(listDataSet2).where(0).equalTo(0)
result.print()
}
}
5.4.10 Union
DataStream → DataStream:对两个或者两个以上的 DataStream 进行 union 操作,产生一个包含所有 DataStream 元素的新 DataStream。
Connect 与 Union 区别:
1. Union 之前两个流的类型必须是一样,Connect 可以不一样,在之后的 coMap
中再去调整成为一样的。
2.Connect 只能操作两个流,Union 可以操作多个。
示例代码如下:
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object Transform {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val listDataStream1: DataStream[String] = env.fromCollection(List("1","2","3","4"))
val listDataStream2: DataStream[String] = env.fromCollection(List("mysql hive", "hbase", "hadoop", "hbase"))
val dataStream3 = env.fromCollection(List("tom jerry", "hauhau dahuang", "xiaoming", "xiaohong"))
val result: DataStream[String] = listDataStream1.union(listDataStream2)
val result1 = dataStream1.union(dataStream2,dataStream3)
result.print()
env.execute("Transform is runned")
}
}
5.4.11 KeyBy
DataStream → KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同 key 的元素,在内部以 hash 的形式实现的。
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object Transform {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val listDataStream: DataStream[(String, Int)] = env.fromCollection(List((“spark”, 4), (“spark”, 2), (“spark”, 3), (“hbase”, 4)))
val result: DataStream[(String, Int)] = listDataStream.keyBy(0).sum(1)
result.print()
env.execute(“Transform is runned”)
}
}
5.4.12 Split 和 Select
Split:
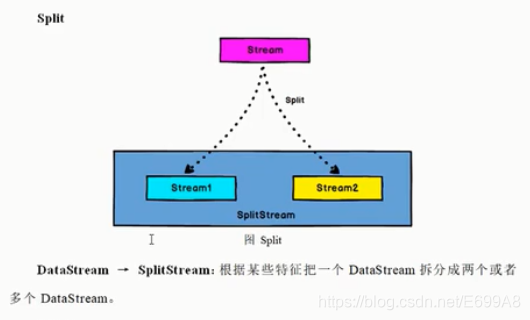
DataStream → SplitStream:根据某些特征把一个 DataStream 拆分成两个或者多个 DataStream。
Select:
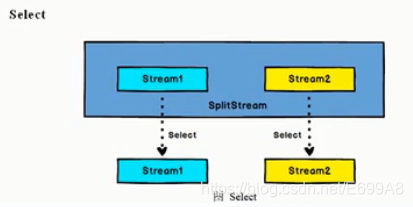
SplitStream→DataStream:从一个 SplitStream 中获取一个或者多个 DataStream。
示例代码如下:
object Transform {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val listDataStream: DataStream[(String, Int)] = env.fromCollection(List(("hdfs", 4), ("hive", 2), ("zookeeper", 3), ("hbase", 4)))
val splitStream = listDataStream.split(x => {
if (x._1.length >= 5) {
Seq("max")
} else {
Seq("min")
}
})
val max = splitStream.select("max")
val min = splitStream.select("min")
val all = splitStream.select("max","min")
all.print()
env.execute("Transform is runned")
}
}
5.4.13 Connect 和 CoMap
Connect:
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
CoMap,CoFlatMap:
跟map and flatMap类似,只不过作用在ConnectedStreams上。
示例代码如下:
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.functions.co.{CoFlatMapFunction, CoMapFunction}
import org.apache.flink.streaming.api.scala.{ConnectedStreams, DataStream, StreamExecutionEnvironment}
import org.apache.flink.util.Collector
object Transform {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val listDataStream1: DataStream[Int] = env.fromCollection(List(1,2,3,4))
Val listDataStream2: DataStream[String] = env.fromCollection(List("mysql hive", "hbase", "hadoop", "hbase"))
val connectStream: ConnectedStreams[Int, String] = listDataStream1.connect(listDataStream2)
val result = connectStream.flatMap(new CoFlatMapFunction[Int, String, String] {
override def flatMap1(in1: Int, collector: Collector[String]): Unit = {
val string = in1.toString
collector.collect(string)
}
override def flatMap2(in2: String, collector: Collector[String]): Unit = {
val strings = in2.split(" ")
for (word <- strings) {
collector.collect(word)
}
}
})
result.print()
env.execute("Transform is runned")
}
}
5.4.14 rebalance
让每个分区的数据均匀分布,避免数据倾斜。
示例代码如下:
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet: DataSet[Long] = env.generateSequence(0,100)
val result: DataSet[(Long, Long)] = dataSet.map(new RichMapFunction[Long, (Long, Long)] {
override def map(in: Long): (Long, Long) = {
(getRuntimeContext.getIndexOfThisSubtask, in)
}
})
val dataSet2: DataSet[Long] = dataSet.rebalance()
val result2 = dataSet2.map(new RichMapFunction[Long, (Long, Long)] {
override def map(in: Long): (Long, Long) = {
(getRuntimeContext.getIndexOfThisSubtask, in)
}
})
result2.print()
}
}
5.4.15 partitionByHash
按照指定的key进行hash分区。
示例代码如下:
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet: DataSet[Long] = env.generateSequence(0,100)
val dataSet1: DataSet[Long] = dataSet.partitionByHash(_.toString)
val result = dataSet1.map(new RichMapFunction[Long, (Long, Long)] {
override def map(in: Long): (Long, Long) = {
(getRuntimeContext.getIndexOfThisSubtask, in)
}
})
result.print()
}
}
5.4.16 sortPartition
指定字段对分区中的数据进行排序。
分区之内的数据是有序,分区间的数据是无序
示例代码如下:
import org.apache.flink.api.common.operators.Order
import org.apache.flink.api.scala._
object Transform {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet: DataSet[Int] = env.fromCollection(List[Int](1,2,3,4,5))
dataSet.setParallelism(2)
val result = dataSet.sortPartition(_.toInt,Order.DESCENDING)
result.print()
}
}
5.5 支持的数据类型
Flink 流应用程序处理的是以数据对象表示的事件流。所以在 Flink 内部,我们需要能够处理这些对象。它们需要被序列化和反序列化,以便通过网络传送它们;或者从状态后端、检查点和保存点读取它们。为了有效地做到这一点,Flink 需要明确知道应用程序所处理的数据类型。Flink 使用类型信息的概念来表示数据类型,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
Flink 还具有一个类型提取系统,该系统分析函数的输入和返回类型,以自动获取类型信息,从而获得序列化器和反序列化器。但是,在某些情况下,例如 lambda函数或泛型类型,需要显式地提供类型信息,才能使应用程序正常工作或提高其性
能。
Flink 支持 Java 和 Scala 中所有常见数据类型。使用最广泛的类型有以下几种。
基本数据类型:
Flink 支持所有的 Java 和 Scala 基础数据类型,Int, Double, Long, String, …
val dataSet1 = env.fromElements(1, 2, 3, 4, 5)
val dataSet2 = env.fromElements("zhangsan", "lisi")
val dataSet3 = env.fromElements(1L, 2L, 3L, 4L, 5L)
元组:
val dataSet1 = env.fromElements((1, 2), (3, 4), (5,6))
Scala样例类:
case class People(name:String,age:Int)
val dataSet: DataSet[People] = env.fromElements(People("zhangsan",12),People("lisi",25))
对象:
class People {
var name = "lisi"
var id = 2
def this(name: String, id: Int) {
this()
this.name = name
this.id = id
}
}
val dataSet = env.fromElements(new People("zhangsan",12),new People("lisi",25))
其它(Arrays, Lists, Maps, Enums, 等等):
Flink 对 Java 和 Scala 中的一些特殊目的的类型也都是支持的,比如 Java 的ArrayList,HashMap,Enum 等等。
月报表:批处理 实时性要求不高 每个月1开始处理上个月数据,3号汇报
流处理 实时性要求高 每个月1早上就要汇报
5.6 实现 UDF 函数——更细粒度的控制流
5.6.1 函数类(Function Classes)
Flink 暴露了所有 udf 函数的接口(实现方式为接口或者抽象类)。例如
MapFunction, FilterFunction, ProcessFunction 等等。
下面例子实现了 FilterFunction 接口:
class FilterFun extends FilterFunction[String]{
override def filter(t: String): Boolean = {
t.startsWith("h")
}
}
调用代码如下:
object DefineFun{
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet: DataSet[String] = env.fromElements("hadoop","spark","hive")
val result: DataSet[String] = dataSet.filter(new FilterFun)
result.print()
}
}
还可以将函数实现成匿名类,示例代码如下:
object DefineFun{
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet: DataSet[String] = env.fromElements("hadoop","spark","hive")
val result: DataSet[String] = dataSet.filter(new RichFilterFunction[String] {
override def filter(t: String): Boolean = {
t.startsWith("h")
}
})
result.print()
}
}
给自定义udf传参。
自定义udf代码如下:
class FilterFun(word:String) extends FilterFunction[String]{
override def filter(t: String): Boolean = {
t.startsWith(word)
}
}
调用代码如下:
object DefineFun{
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet: DataSet[String] = env.fromElements("hadoop","spark","hive")
val result: DataSet[String] = dataSet.filter(new FilterFun("h"))
result.print()
}
}
5.6.2 匿名函数(Lambda Functions)
示例代码如下:
object DefineFun{
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet: DataSet[String] = env.fromElements("hadoop","spark","hive")
val result: DataSet[String] = dataSet.filter(_.startsWith("h"))
result.print()
}
}
5.6.3 富函数(Rich Functions)
“富函数”是 DataStream API 提供的一个函数类的接口,所有 Flink 函数类都有其 Rich 版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
RichMapFunction
RichFlatMapFunction
RichFilterFunction
…
Rich Function 有一个生命周期的概念。典型的生命周期方法有:
open()方法是 rich function 的初始化方法,当一个算子例如 map 或者 filter
被调用之前 open()会被调用。
close()方法是生命周期中的最后一个调用的方法,做一些清理工作。
getRuntimeContext()方法提供了函数的 RuntimeContext 的一些信息,例如函数执行的并行度,任务的名字,以及 state 状态。
自定义富函数代码如下:
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.configuration.Configuration
import org.apache.flink.util.Collector
import org.apache.flink.api.scala._
class defineMap extends RichFlatMapFunction[String, (Int, String)] {
var subTaskIndex = 0
override def open(parameters: Configuration): Unit = {
subTaskIndex = getRuntimeContext.getIndexOfThisSubtask
}
override def flatMap(in: String, collector: Collector[(Int, String)]): Unit = {
collector.collect(subTaskIndex,in)
}
override def close(): Unit = {
}
}
调用自定义富函数代码如下:
object DefineUDF{
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataSet: DataSet[String] = env.fromElements("hadoop", "spark", "hive")
val result = dataSet.flatMap(new defineMap)
result.print()
}
}
❤ღ( ´・ᴗ・` )比心
未完结,一定敲敲敲着去理解,下篇继续更新大数据其他内容,谢谢观看

















 6301
6301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









