






前言
在大语言模型(LLM)落地的过程中,“生成效率”始终是绕不开的核心痛点——传统自回归模型像“挤牙膏”一样逐词元(Token)生成文本,不仅推理速度慢,训练效率也难以满足大规模应用需求。而多标记预测(Multi-Token Prediction, MTP) 作为解决这一问题的关键技术,正在成为LLM性能优化的核心方向。本文将从技术本质、执行流程、实战示例到落地应用,全方位拆解MTP技术。
MTP核心定义:不止于“一次生成多个Token”
多标记预测(MTP)是一种让大语言模型在单次前向传播中同时预测多个后续词元的技术,核心目标是打破传统“单Token逐次生成”的效率枷锁。
与传统单标记预测(NTP)的核心差异:
- 传统NTP:输入文本→模型预测第t+1个Token→以t+1为新输入→预测t+2个Token(循环往复);
- MTP:输入文本→模型单次前向传播→同时预测t+1、t+2…t+n个Token,直接完成多步生成。
简单来说,MTP让模型从“一步走一格”变成“一步走多格”,既提升训练时的信号密度,又大幅降低推理时的迭代次数。
MTP核心执行流程
MTP的执行流程分为训练阶段和推理阶段,其中推理阶段结合“推测解码(Speculative Decoding)”时效果最优。
1. 基础MTP训练流程
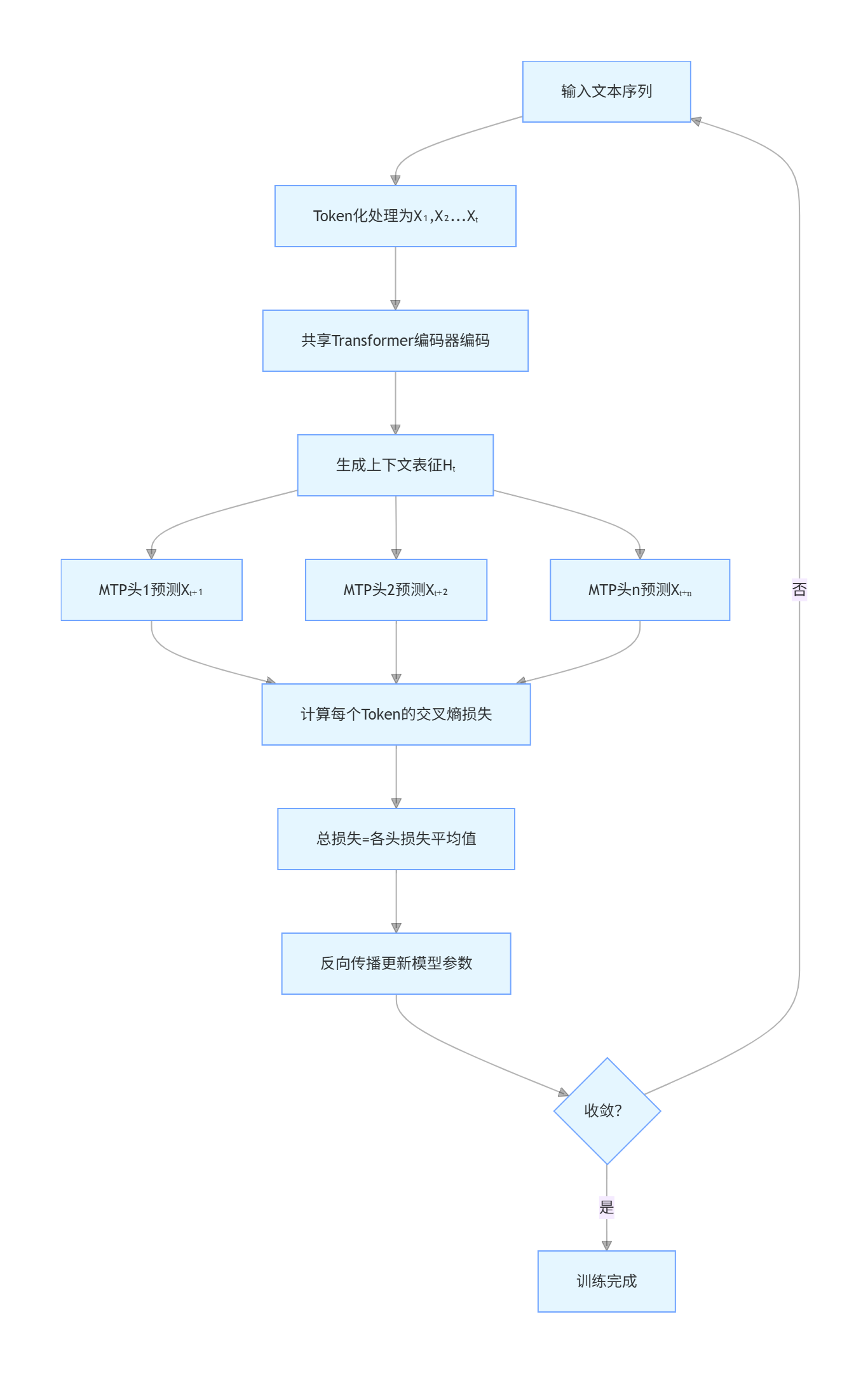
流程拆解:
- 输入文本经Token化转为序列
X₁,X₂...Xₜ; - 共享Transformer编码器将序列编码为上下文表征
Hₜ; - 多个独立的MTP输出头基于
Hₜ,并行预测t+1到t+n个Token; - 计算每个MTP头的预测损失(交叉熵),总损失为所有头损失的平均值;
- 反向传播更新模型参数,直到模型收敛。
2. MTP+推测解码推理流程(主流落地方案)
单纯的MTP可能存在“多Token预测不连贯”的问题,结合推测解码后,既能保效率又能保质量:
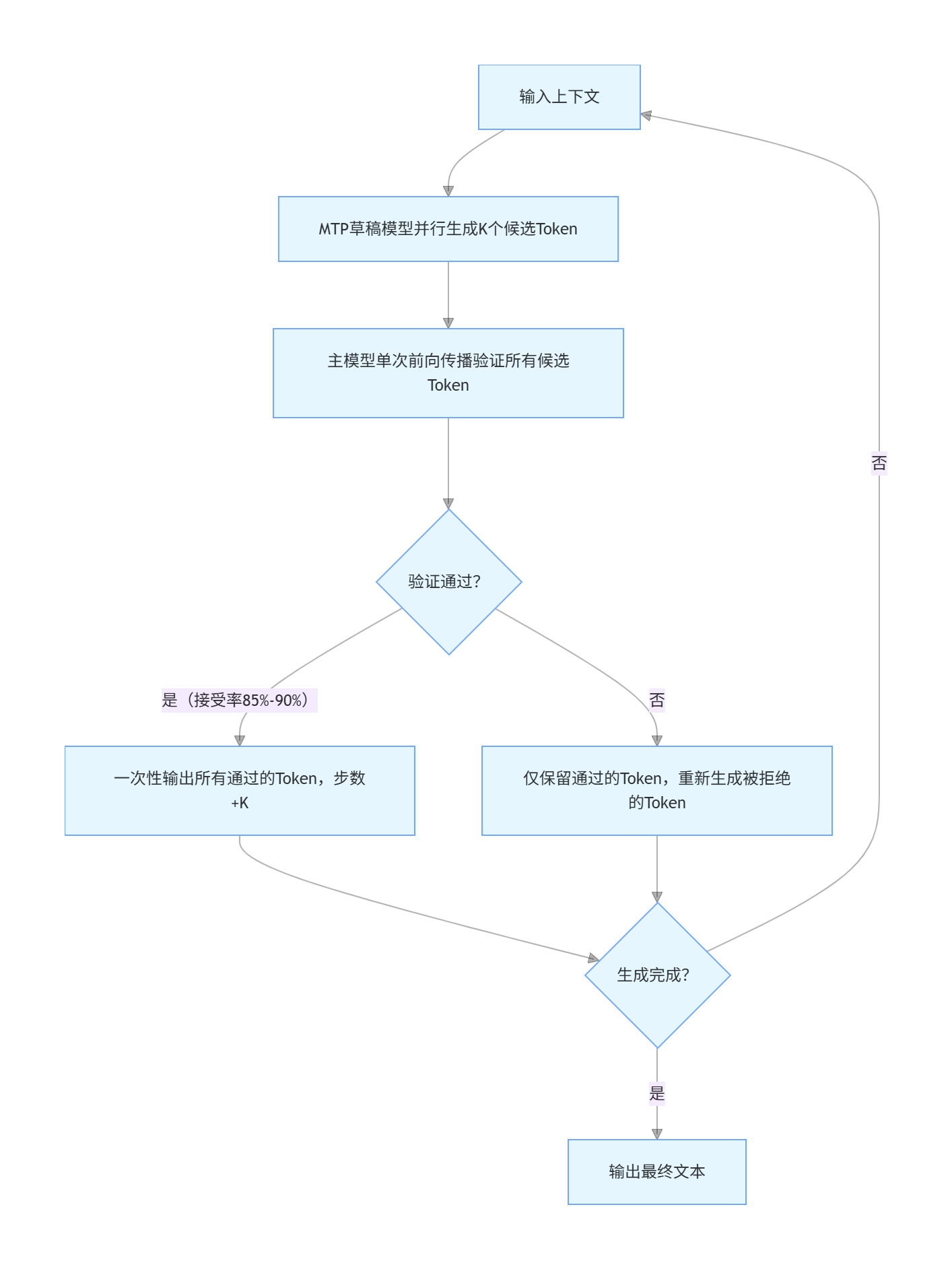
流程拆解:
- 轻量级MTP“草稿模型”基于输入上下文,并行生成K个候选Token(比如K=4);
- 高精度主模型通过单次前向传播,批量验证这K个候选Token的合理性;
- 若验证通过(DeepSeek实测接受率85%-90%),直接输出这K个Token,模型步数一次性+K;
- 若部分Token验证失败,仅保留通过的Token,重新生成被拒绝的部分;
- 重复上述步骤,直到生成满足长度要求的文本。
3. DeepSeek依赖链式MTP架构(保连贯的进阶方案)
为解决“独立多头MTP生成不连贯”的问题,DeepSeek设计了依赖链式MTP架构:

核心逻辑:后一个MTP头的预测依赖前一个头的输出表征,既保留了“多Token预测”的效率,又保证了文本的语义连贯性。
MTP实战示例:极简PyTorch实现框架
以下是一个简化版的MTP模型实现,帮助你理解核心代码逻辑(仅保留关键模块,无复杂优化):
import torch
import torch.nn as nn
import torch.optim as optim
# 超参数设置
VOCAB_SIZE = 10000 # 词汇表大小
EMBED_DIM = 256 # 嵌入维度
HIDDEN_DIM = 512 # Transformer隐藏层维度
NUM_HEADS = 8 # 注意力头数
NUM_LAYERS = 2 # Transformer层数
MTP_NUM = 3 # 一次预测3个Token(t+1/t+2/t+3)
# 1. 共享Transformer编码器(基础编码模块)
class SharedEncoder(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(VOCAB_SIZE, EMBED_DIM)
self.transformer_encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(EMBED_DIM, NUM_HEADS, HIDDEN_DIM),
num_layers=NUM_LAYERS
)
def forward(self, x):
# x: [seq_len, batch_size]
embed = self.embedding(x) # [seq_len, batch_size, embed_dim]
enc_out = self.transformer_encoder(embed) # [seq_len, batch_size, embed_dim]
return enc_out[-1] # 返回最后一个Token的表征: [batch_size, embed_dim]
# 2. MTP多输出头(并行预测多个Token)
class MTPModel(nn.Module):
def __init__(self):
super().__init__()
self.encoder = SharedEncoder()
# 定义MTP_NUM个独立的输出头
self.mtp_heads = nn.ModuleList([
nn.Linear(EMBED_DIM, VOCAB_SIZE) for _ in range(MTP_NUM)
])
def forward(self, x):
# x: [seq_len, batch_size]
context_feat = self.encoder(x) # [batch_size, embed_dim]
# 每个头并行预测一个Token
mtp_outputs = [head(context_feat) for head in self.mtp_heads]
# 返回t+1/t+2/t+3的预测logits: [MTP_NUM, batch_size, vocab_size]
return torch.stack(mtp_outputs)
# 3. 训练流程示例
def train_mtp_model():
model = MTPModel()
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 模拟训练数据:输入序列[1,2,3,4],目标Token为[5,6,7](t+1=5, t+2=6, t+3=7)
batch_size = 2
input_seq = torch.tensor([[1,2,3,4], [1,2,3,4]]).T # [seq_len=4, batch_size=2]
target_tokens = torch.tensor([[5,6,7], [5,6,7]]).T # [MTP_NUM=3, batch_size=2]
model.train()
for epoch in range(100):
optimizer.zero_grad()
# 前向传播:获取3个Token的预测logits
mtp_logits = model(input_seq) # [3, 2, 10000]
# 计算总损失:每个MTP头的损失相加
total_loss = 0.0
for i in range(MTP_NUM):
# logits: [2, 10000], target: [2]
loss = criterion(mtp_logits[i], target_tokens[i])
total_loss += loss
# 反向传播
total_loss.backward()
optimizer.step()
if (epoch+1) % 20 == 0:
print(f"Epoch {epoch+1}, Total Loss: {total_loss.item():.4f}")
# 执行训练
if __name__ == "__main__":
train_mtp_model()
代码关键说明:
SharedEncoder:共享的Transformer编码器,为所有MTP头提供统一的上下文表征;MTPModel:包含3个独立的线性输出头,并行预测t+1、t+2、t+3三个Token;- 训练阶段:计算每个MTP头的交叉熵损失,求和后作为总损失反向传播,让模型学习“一次预测多个Token”的能力;
- 输出示例:训练100轮后损失会逐步下降,说明模型已学会从输入
[1,2,3,4]预测目标[5,6,7]。
MTP vs 传统单标记预测(NTP)核心对比
| 特性 | 传统单标记预测(NTP) | 多标记预测(MTP) |
|---|---|---|
| 预测方式 | 每次生成1个Token | 一次生成n个Token |
| 推理速度 | 基准值(1倍) | 1.8~2.6倍(结合推测解码) |
| 训练信号密度 | 低(每步1个损失) | 高(每步n个损失) |
| 文本连贯性 | 一般(仅依赖前1个Token) | 优秀(依赖链式表征) |
| 硬件资源利用率 | 低(单次前向传播仅用1次) | 高(单次前向传播用n次) |
| 典型落地场景 | 小模型、低延迟要求场景 | 大模型、长文本生成、移动端 |
MTP的落地应用与核心优势
1。 核心优势
- 效率翻倍:推理速度提升1.8~2.6倍,训练时信号密度更高,收敛更快;
- 语义更连贯:依赖链式架构让多Token生成符合语言逻辑,避免“前言不搭后语”;
- 硬件适配性好:联发科天玑9400+等芯片已集成MTP硬件加速,适配移动端部署;
- 成本降低:减少推理时的前向传播次数,大幅降低算力消耗(小米MiMo模型仅用1/50算力达到同等性能)。
2. 典型落地案例
- DeepSeek-V3:依赖链式MTP+推测解码,推理速度提升1.8倍,生成质量与原生模型持平;
- 小米MiMo模型:MTP+在线策略蒸馏,32并发时推理速度达1146 Tokens/秒;
- 联发科天玑9400+:硬件级MTP加速,支持手机端高效运行Qwen3等大模型。
总结
MTP技术的核心价值,是在不牺牲LLM生成质量的前提下,解决了自回归模型“逐Token生成”的效率瓶颈。从技术演进来看,未来MTP将朝着“更高并行度、更强语义连贯性、更低硬件依赖”方向发展:
- 结合MoE(混合专家模型),进一步提升MTP的并行计算效率;
- 优化依赖链式架构,平衡“并行度”与“连贯性”;
- 轻量化MTP模块,让中小模型也能享受效率提升。
对于开发者而言,理解MTP的核心逻辑(共享编码+多输出头+损失融合),并掌握“MTP+推测解码”的落地范式,将成为优化LLM应用的核心能力。


















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











