



一起来轻松玩转文心大模型吧一文心大模型免费下载地址:GitCode - 全球开发者的开源社区,开源代码托管平台GitCode是面向全球开发者的开源社区,包括原创博客,开源代码托管,代码协作,项目管理等。与开发者社区互动,提升您的研发效率和质量。![]() https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
此次我们分三个方面分别来探索一下文心大模型4.5,DeepSeek、Qwen3都能给我们带来哪些帮助。
目录
此次我们分三个方面分别来探索一下文心大模型4.5,DeepSeek、Qwen3都能给我们带来哪些帮助。
对三款大模型说:给定一个链表,请判断该链表是否为回文结构(java编写)
一,发展历程:
文心大模型4.5:
文心大模型是百度自主研发的产业级知识增强大模型。它于 2019 年 3 月发布 1.0 版本,历经多次迭代,推出了多个升级版本,在自然语言处理、视觉、跨模态等领域不断取得突破。2019 年 3 月,文心大模型 1.0 版本发布,迈出了探索的第一步。 同年 7 月,2.0 版本推出,在 1.0 的基础上进行了初步优化。 2021 年 12 月,百度联合鹏城实验室发布全球首个知识增强千亿大模型 —— 鹏城 - 百度・文心,参数规模达 2600 亿,实现了一次重要跨越。 2023 年 10 月,文心大模型 4.0 正式发布,基础模型全面升级。 2025 年 3 月 16 日,文心大模型 4.5 和文心大模型 X1 亮相。 2025 年 6 月 30 日,百度开源文心大模型 4.5 系列模型,涵盖多种参数的混合专家(MoE)模型与稠密型模型等 10 款模型,进一步扩大了其应用范围。
DeepSeek:
DeepSeek 于 2023 年 5 月成立,由中国对冲基金 High-Flyer 创立并资助 ,其核心成员来自清华、北大及国际顶尖实验室。在成立初期,团队专注技术研发,虽未大规模曝光,但迅速推出首个千亿参数模型 DeepSeek - v1,在次年又推出了V2版本。通过私有化部署为金融、医疗等企业客户提供服务。
Qwen3:
Qwen3.0 是阿里巴巴通义千问团队开发的大模型,于 2025 年 4 月 29 日正式发布并开源,其发展建立在 Qwen 系列前序版本基础上,历经多次迭代优化。引入渐进式长文本预训练和长文本后训练,支持思考模式与非思考模式无缝切换,外部工具调用能力加强。
二,功能特点:
文心大模型4.5:
引入知识图谱,将数据与知识融合,提升了学习效率和可解释性;支持文本、图像、语音等多种数据形式的处理和生成,从单模态发展到跨模态;包括对话、搜索、信息抽取、智能创作等任务,具备强大的零样本和小样本学习能力;采用目前最先进的自适应混合并行训练技术及混合精度计算策略,加快了模型迭代速度,提升了模型效果和安全性。
DeepSeeK:
采用混合专家(MoE)架构和多头潜在注意力机制,动态分配任务,减少计算量,提升灵活性。 通过FP8混合精度训练和多种并行策略,节省资源并加快训练速度。推理速度比传统模型快30%以上,文本生成速度提升2倍,支持高效处理任务。训练和部署成本低,可在边缘设备运行。支持多语言,能提供个性化服务,在内容创作、代码生成等领域表现佳。模型、代码和论文公开,便于开发者使用和社区协作。采用加密技术,遵守隐私法规,保障用户数据安全。
Qwen3:
支持 “快慢思考” 模式切换,简单问题快速响应,复杂任务深度推导,还能按需控制推理程度。 对数学、代码推理能力大幅提升,多语言支持超 100 种,人类偏好对齐更自然。支持原生工具调用,结合框架可高效完成复杂任务,降低开发门槛。 含多种参数量的 MoE 和 dense 模型,均开源供免费使用。 通过优化技术降低显存占用(仅为同类模型 1/3),资源受限场景也易部署。
三,用户体验:
日常问题提问:
对三款大模型说:女神不喜欢我,怎么一句话让她改变对我的态度
文心大模型4.5的表现:

DeepSeeK的表现:

Qwen3的表现:
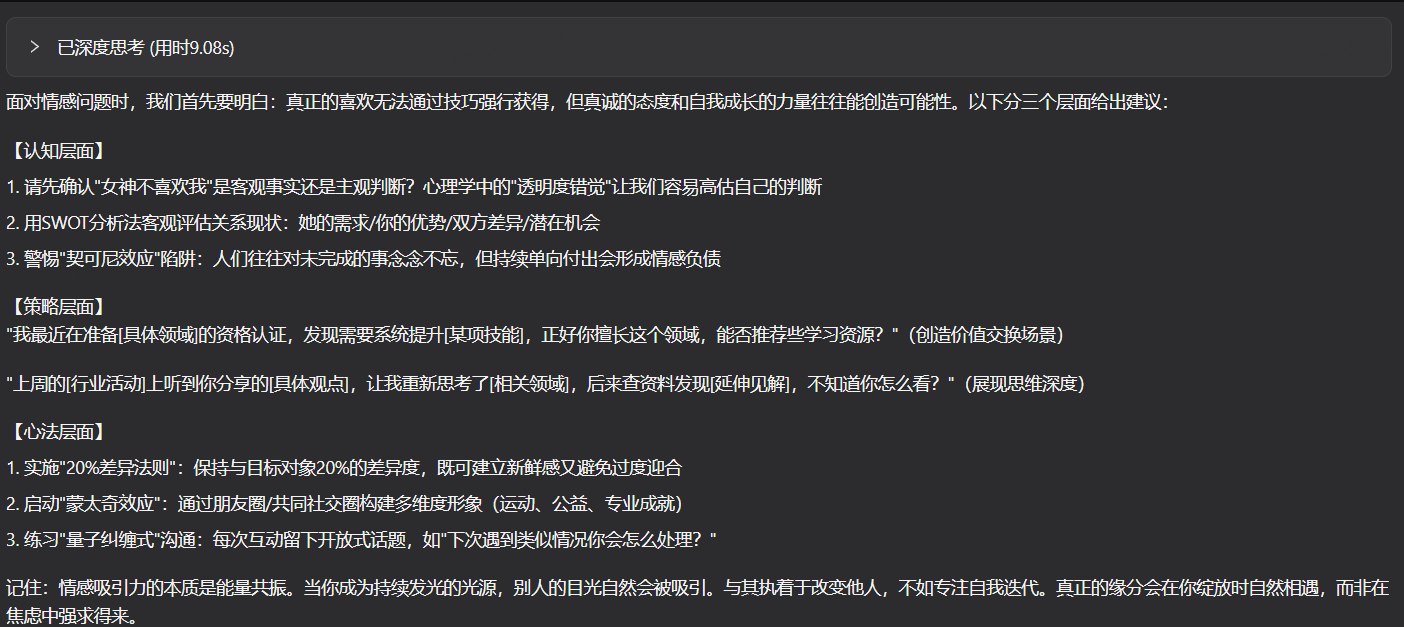
小结:博主这里简单列举了一个问题,这是产出的结果。结合日常用到的情况进行说明一下
文心 4.5 属于 “稳重型”,日常问事儿最靠谱。中文语境下理解得特到位,你说的话再绕,它也能抓准意思。逻辑这块儿没的说,一步一步推导得清清楚楚,不像有些模型答着答着就跑偏。生成速度不算特别快,但也不拖后腿,日常用着足够了。
DeepSeek 更像 “技术宅”,复杂问题能给你挖得很深,有时以为产出结果了,它却又反思一下给你认为完美的结果,总之说出来的东西挺有料。但日常聊天就差点意思,有时候会把简单问题搞复杂,偶尔还会 “断片”—— 前面说的和后面接的对不上。速度嘛,只能算中等,不算快。
Qwen3.0 是 “急性子”,反应最快,问个简单问题秒回。多轮聊天时接话接得特顺,不会冷场。但复杂逻辑推理就差点火候,有时候说的话看似有道理,细想一下逻辑不太顺。日常简单问答够用,复杂的就别太指望它了。
日常聊天、想要回答的更现实直白逻辑更好,选文心 4.5;搞专业领域深度问答,找 DeepSeek;简单交流,要快的,Qwen3.0 合适。
代码生成:
对三款大模型说:给定一个链表,请判断该链表是否为回文结构(java编写)
大家看看谁的水平更高,更符合你的需求和想法
文心大模型4.5:
class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
public class PalindromeLinkedList {
// 方法1:使用快慢指针和栈
public boolean isPalindromeWithStack(ListNode head) {
if (head == null || head.next == null) return true;
Stack<Integer> stack = new Stack<>();
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
stack.push(slow.val);
slow = slow.next;
fast = fast.next.next;
}
if (fast != null) slow = slow.next;
while (slow != null) {
if (slow.val != stack.pop()) return false;
slow = slow.next;
}
return true;
}
// 方法2:反转后半部分链表
public boolean isPalindromeByReverse(ListNode head) {
if (head == null || head.next == null) return true;
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
ListNode prev = null;
while (slow != null) {
ListNode next = slow.next;
slow.next = prev;
prev = slow;
slow = next;
}
ListNode left = head, right = prev;
while (right != null) {
if (left.val != right.val) return false;
left = left.next;
right = right.next;
}
return true;
}
}
DeepSeek:
import java.util.Stack;
class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
public class PalindromeLinkedList {
// 方法1:使用栈
public boolean isPalindrome(ListNode head) {
if (head == null || head.next == null) {
return true;
}
Stack<Integer> stack = new Stack<>();
ListNode slow = head;
ListNode fast = head;
// 快慢指针找到中点,并将前半部分压入栈
while (fast != null && fast.next != null) {
stack.push(slow.val);
slow = slow.next;
fast = fast.next.next;
}
// 处理奇数长度情况
if (fast != null) {
slow = slow.next;
}
// 比较后半部分与栈中元素
while (slow != null) {
if (slow.val != stack.pop()) {
return false;
}
slow = slow.next;
}
return true;
}
// 方法2:反转后半部分链表
public boolean isPalindrome2(ListNode head) {
if (head == null || head.next == null) {
return true;
}
ListNode slow = head;
ListNode fast = head;
// 找到中点
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
// 反转后半部分
ListNode prev = null;
while (slow != null) {
ListNode next = slow.next;
slow.next = prev;
prev = slow;
slow = next;
}
// 比较前后两部分
ListNode left = head;
ListNode right = prev;
while (right != null) {
if (left.val != right.val) {
return false;
}
left = left.next;
right = right.next;
}
return true;
}
}
Qwen3:
public class Solution {
public boolean isPalindrome(ListNode head) {
if (head == null) {
return true;
}
// 找到前半部分的尾节点
ListNode slow = head;
ListNode fast = head;
while (fast.next != null && fast.next.next != null) {
slow = slow.next;
fast = fast.next.next;
}
// 反转后半部分链表
ListNode prev = null;
ListNode curr = slow.next;
while (curr != null) {
ListNode nextTemp = curr.next;
curr.next = prev;
prev = curr;
curr = nextTemp;
}
// 比较前半部分和反转后的后半部分
ListNode p1 = head;
ListNode p2 = prev;
boolean result = true;
while (p2 != null) {
if (p1.val != p2.val) {
result = false;
break;
}
p1 = p1.next;
p2 = p2.next;
}
return result;
}
}小结:博主这里简单列举了一个问题针对“回文数”这一基础编程任务,文心大模型4.5、DeepSeek 和 Qwen 3.0 均给出了正确的实现,但在代码细节、空格处理方式以及讲解风格等方面各具特色,适合不同的用户需求和使用场景。
文心大模型4.5
- 优势:
- 两种方法都有,且方法名一看就知道用了啥思路(带 Stack 就是用栈,带 Reverse 就是反转),好区分。
- 空链表、单个节点这些特殊情况都考虑到了,不容易出错。
- 劣势:
- 注释少,新手可能得琢磨半天步骤。
- 代码有小疏漏(链表节点类的大括号没关),直接用可能报错,得改。
DeepSeek
- 优势:
- 注释超详细,每步干啥都写明白了,哪怕是新手也能看懂。
- 格式规整,该有的括号、该导入的工具包都齐,拿来就能用,不用自己补东西。
- 劣势:
- 两种方法名字起得一般(一个叫 isPalindrome,一个叫 isPalindrome2),不看注释不知道区别。
Qwen 3.0
- 优势:
- 代码短,没废话,直接塞项目里用很方便。
- 不占啥内存,处理大数据时更给力。
- 劣势:
- 只有一种方法,想换思路得自己写。
- 没定义链表节点类,得自己提前准备好,不然用不了。
总结:
从语言反馈和代码生成逻辑上来看:
| 模型 | 语言反馈特点 | 代码生成特点 |
| 文心大模型 4.5 | 中文语境理解强,长文本处理突出,回答详尽、逻辑清晰,结构化表达能力佳,适合对准确性、严谨性要求高场景,但回答可能较长 | 代码结构清晰,注释丰富且以中文口语形式解释,适合编程教学,注重保留原始格式,能解决实际工程问题 |
| DeepSeek | 在多轮对话和复杂推理任务有优势,尤其专业领域问答精准,日常提问回答风格简洁,但法律依据等可能不足 | 支持多语言编程,可处理复杂编程任务,代码风格稳健,但有时忽略实际工程限制 |
| Qwen3.0 | 短文本即时反应和语境转化出色,多轮对话中能快速适应用户需求,擅长跨领域问题回答,阅读轻松 | 代码实现紧凑高效,讲解采用 Markdown 模块化风格,逻辑清晰,提供丰富示例,对边界情况有深入考量,适合快速集成和生产代码参考 |
客观表述:
这次的测评中,三款大模型都可圈可点,尤其是文心大模型4.5的表现,回答的精准,简洁,还快。
大模型在日常干活能当外挂,写个报告、改段文案、查点资料,它能快速给个初稿,省得自己从头憋;学新东西也能当,比如问个代码问题、理解个专业概念,它能用大白话给你捋明白,比自己啃文档快;甚至偶尔摸鱼想个点子、编个段子,它也能搭把手,可以当个灵感触发器。但是有时坑也不少,有时它回答的头头是道,但结果细节全是错的,一些潜台词的话或者描述的不够标准,就会遇到答非所问。
总之:对于我们程序员而言,大模型更像是一位得力的辅助伙伴,能在不少场景中提供支持,但要说完全替代我们处理核心工作,目前来看还不太现实。 比如面对一些重复性的代码编写,它可以先搭建好基础框架,我们再在此基础上进行优化调整,能节省不少时间;查阅API文档时,它也能帮忙提炼关键信息,让我们不用在冗长的文档里逐行查找,效率会高很多。 不过在核心逻辑设计、复杂算法实现这些关键环节,还是需要我们自己亲力亲为把控好。如果指望它独立完成核心业务代码的编写,可能会出现一些考虑不周全的地方,后续还需要我们花精力去完善,反而可能影响整体进度。
希望大家能合理运行大模型,要把它当做是你生活或工作中处理事情的加速器,不要对其产生过度依赖。
一起来轻松玩转文心大模型吧一文心大模型免费下载地址:GitCode - 全球开发者的开源社区,开源代码托管平台GitCode是面向全球开发者的开源社区,包括原创博客,开源代码托管,代码协作,项目管理等。与开发者社区互动,提升您的研发效率和质量。![]() https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle

















 2万+
2万+


 到【灌水乐园】发言
到【灌水乐园】发言








