



当你欲爬取某网页的信息数据时,发现通过浏览器可正常访问,而通过代码请求失败,换了随机ua头IP等等都没什么用时,有可能识别了你的TLS指纹做了验证。
解决办法:
1、修改 源代码
2、使用第三方库 curl-cffi
from curl_cffi import requests as curl_req
def Use_curl():
res = curl_req.get(
url='https://cn.investing.com/equities/amazon-com-inc-historical-data',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
},
impersonate="chrome101"
)
res.encoding = 'utf-8'
print(res.text)
获取到网页:
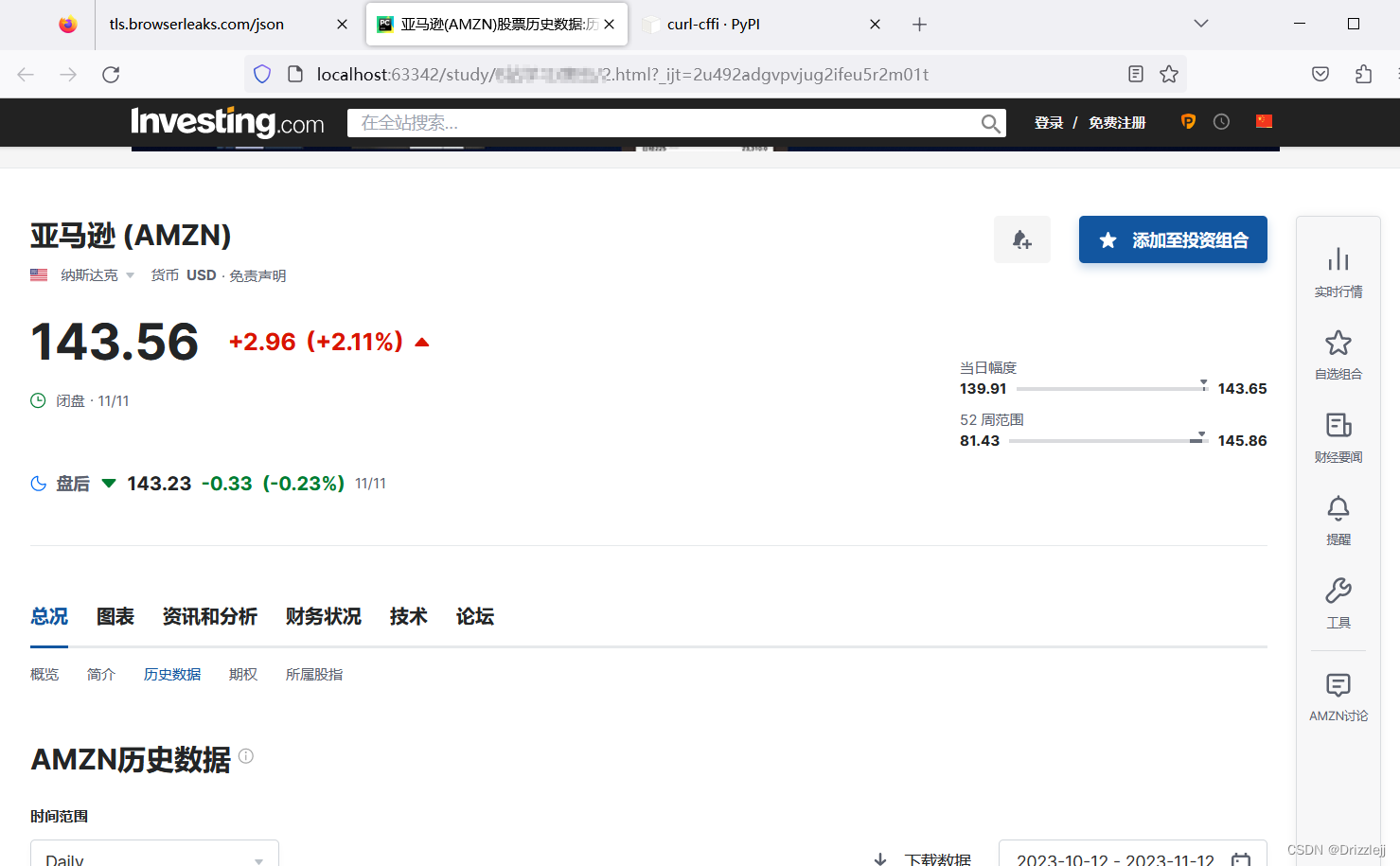
原理解析:
1、什么是TLS 指纹校验
TLS 及其前身 SSL 用于为常见应用程序和恶意软件加密通信,以确保数据安全,因此可以隐藏在噪音中。要启动 TLS 会话,客户端将在 TCP 3 次握手之后发送 TLS 客户端 Hello 数据包。此数据包及其生成方式取决于构建客户端应用程序时使用的包和方法。服务器如果接受 TLS 连接,将使用基于服务器端库和配置以及 Client Hello 中的详细信息制定的 TLS Server Hello 数据包进行响应。由于 TLS 协商以明文形式传输,因此可以使用 TLS Client Hello 数据包中的详细信息来指纹和识别客户端应用程序。
JA3 是一种创建 SSL/TLS 客户端指纹的方法,它应该易于在任何平台上生成,并且可以轻松共享以用于威胁情报。
在三次握手之后,客户端向服务端发起client hello包,这个包里带了客户端这边的一些特征发给服务端,服务端拿来解析数据包,然后回发一个hello给客户端,之后再进行ssl数据交互
通过浏览器访问 TLS指纹信息 ( https://tls.browserleaks.com/json )
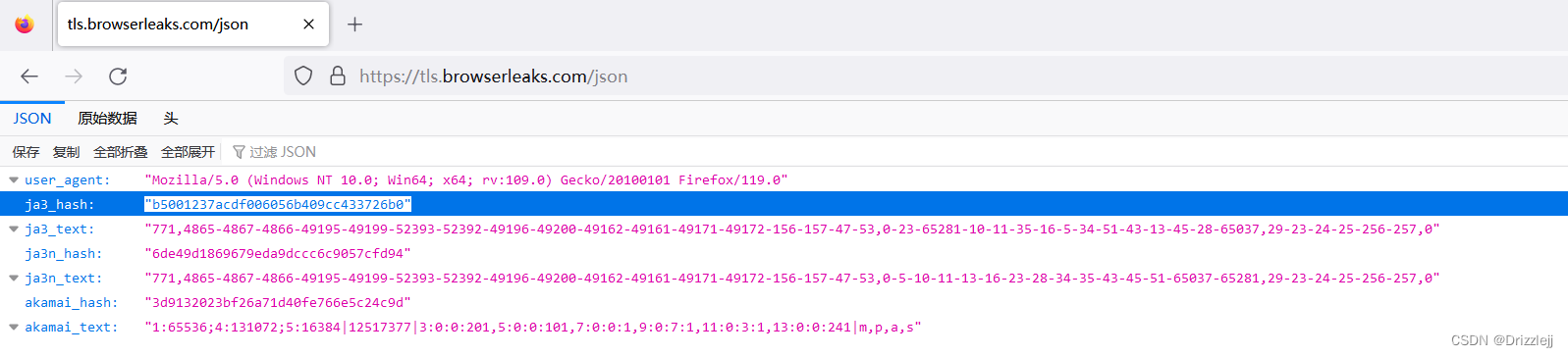
| ja3_hash | "b5001237acdf006056b409cc433726b0" |
| ja3_text | "771,4865-4867-4866-49195-49199-52393-52392-49196-49200-49162-49161-49171-49172-156-157-47-53,0-23-65281-10-11-35-16-5-34-51-43-13-45-28-65037,29-23-24-25-256-257,0" |
通过代码访问 TLS 指纹信息 ( https://tls.browserleaks.com/json )
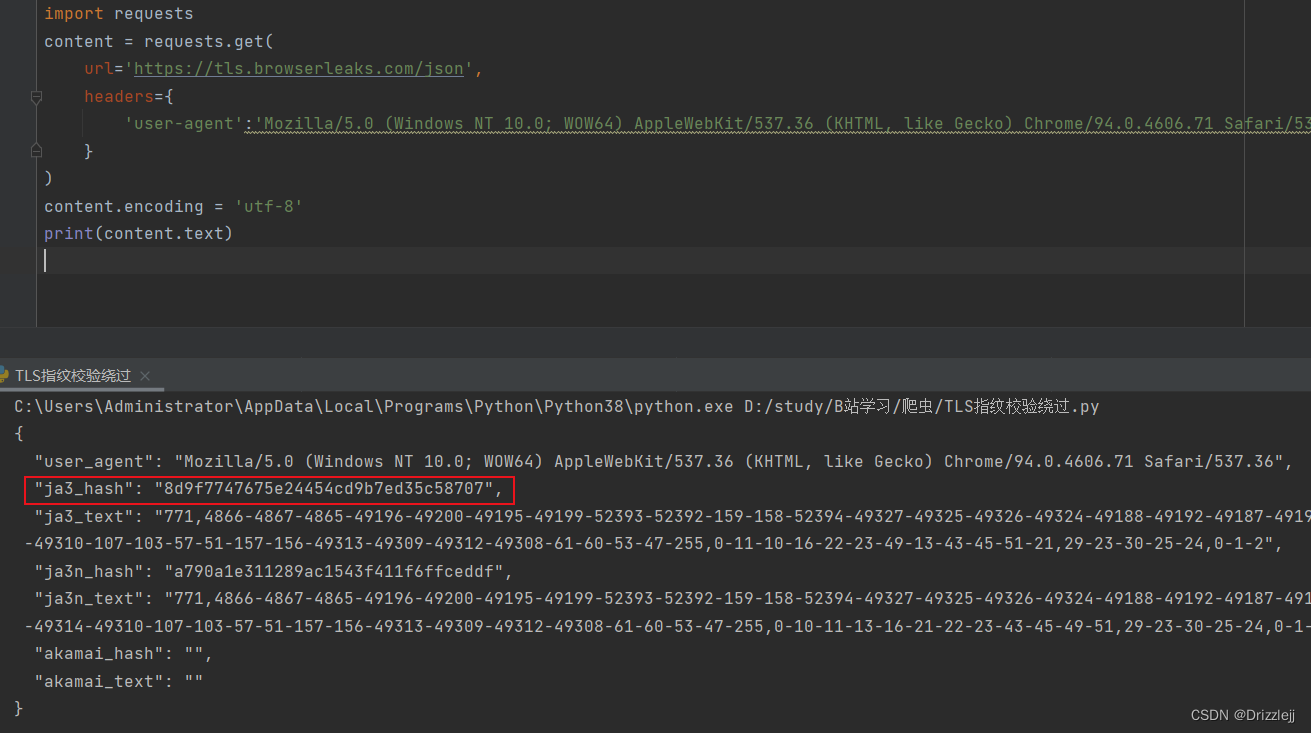
"ja3_hash": "8d9f7747675e24454cd9b7ed35c58707",
通过抓包工具 whireshark 抓包
771,4865-4867-4866-49195-49199-52393-52392-49196-49200-49162-49161-49171-49172-156-157-47-53
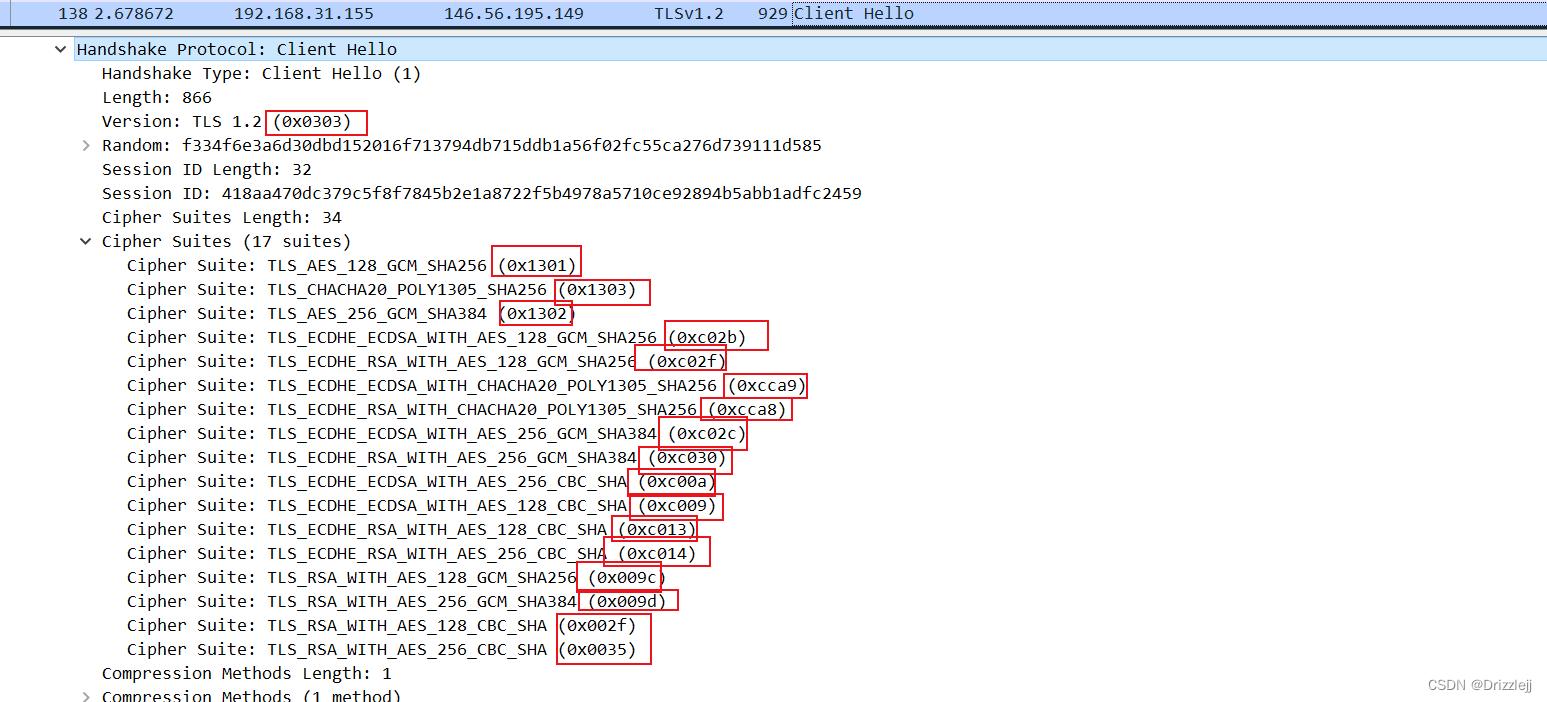
0-23-65281-10-11-35-16-5-34-51-43-13-45-28-65037

29-23-24-25-256-257
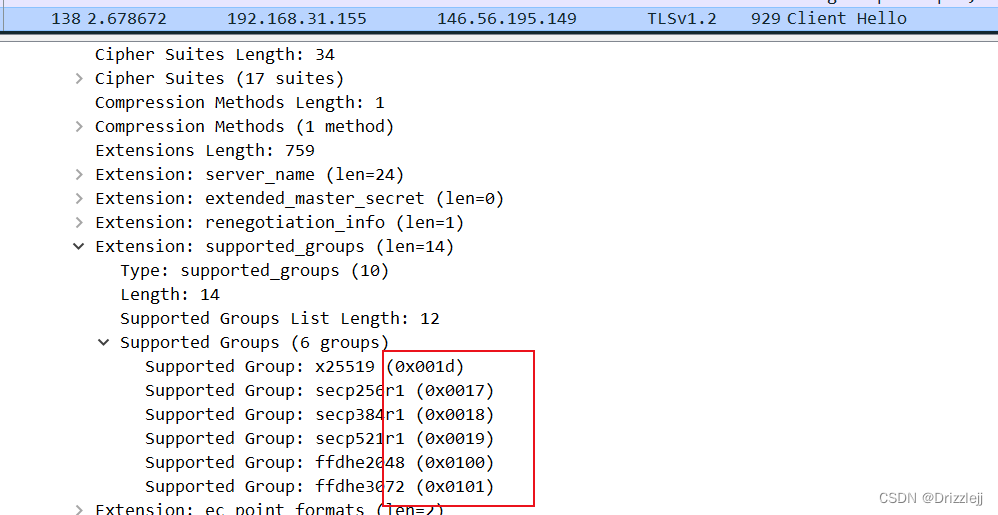 0
0
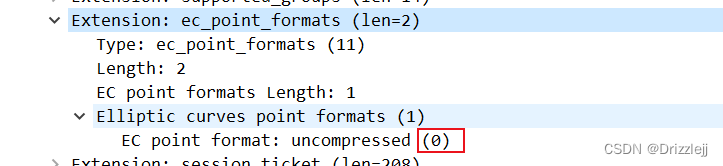
tips :wireshark的最新版可以直接看到ja3指纹
1.JA3 不是简单地查看使用的证书,而是解析在 SSL 握手期间发送的 TLS 客户端 hello 数据包中设置的多个字段。然后可以使用生成的指纹来识别、记录、警报和/或阻止特定流量。
2.JA3 在 SSL 握手中查看客户端 hello 数据包以收集 SSL 版本和支持的密码列表。如果客户端支持,它还将使用所有支持的 SSL 扩展、所有支持的椭圆曲线,最后是椭圆曲线点格式。这些字段以逗号分隔,多个值用短划线分隔(例如,每个支持的密码将在它们之间用短划线列出)
3. JA3 方法用于收集 Client Hello 数据包中以下字段的字节的十进制值:版本、接受的密码、扩展列表、椭圆曲线和椭圆曲线格式。然后按顺序将这些值连接在一起,使用“,”分隔每个字段,使用“-”分隔每个字段中的每个值
2、TLS校验
TLS/SSL + http(数据)
客户端要与服务端建立通信,需要先进行握手,验证通过之后再进行数据的传输。
当我们使用python 的 requests或urllib 包发送请求时,他们的指纹信息都是确定的、固定的,每个浏览器都有自己的指纹信息。服务端通过搜集不同的网络请求模块的指纹信息,建立一个黑名单,当有外来访问时,服务端检测便该指纹信息是否在自己的黑名单内,若是,便不允许其访问。
3、如何绕过TLS 校验
通过修改请求模块的指纹信息或模拟正确的浏览器指纹信息即可绕过校验。
修改请求模块的指纹信息 urllib3.util.ssl_
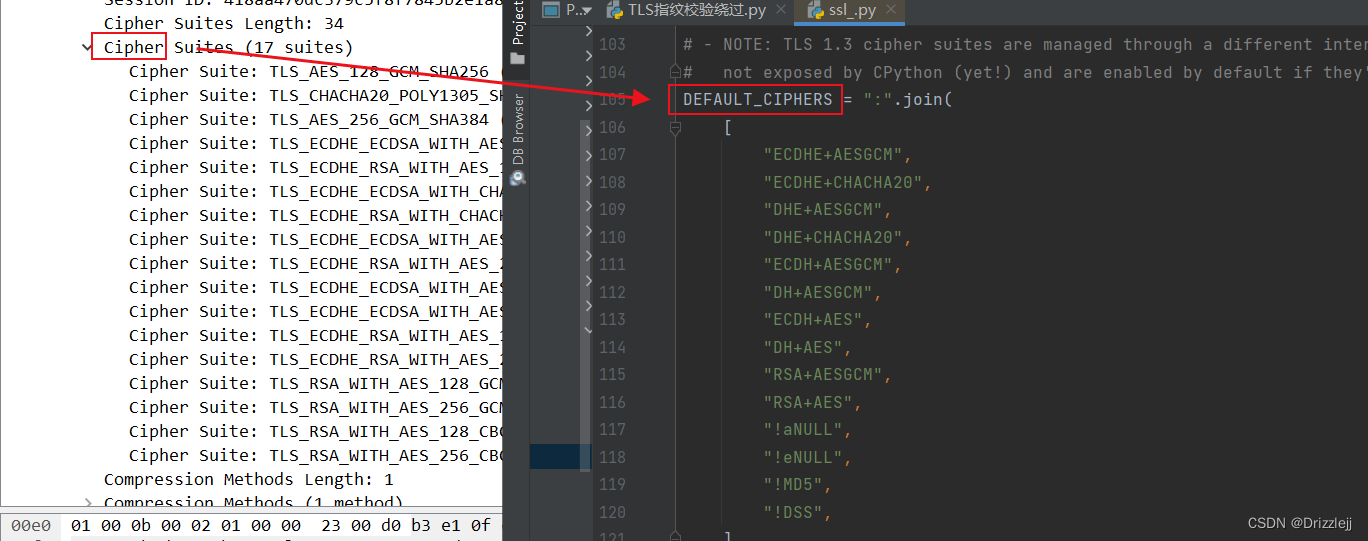
模拟正确的浏览器指纹信息 pip install curl-cffi
curl 模块可以伪造发送请求,它是通过二次开发集成了常见浏览器指纹,比如发送请求,使用谷歌浏览器,版本101 。
详细模块使用请见 curl-cffi · PyPI
结果如图所示:
图一使用 request 访问获取不到网页信息。
图二使用 curl-cffi 成功获取网页信息

















 1580
1580






 到【灌水乐园】发言
到【灌水乐园】发言







