







目录
背景介绍
在Python开发中,字符编码问题是引发程序异常的常见根源。据统计:
- 68%的中文开发者遭遇过乱码问题
- 32%的文件操作异常与编码设置相关
- 55%的网络请求数据解析失败由编码不一致导致
本文将通过底层存储原理分析 + 12个实战案例,系统讲解:
- 字符在内存与磁盘中的存储差异
- Python3的Unicode处理机制
- 5种主流编码格式深度对比
- 编码自动检测与转换方案
- 多语言混合环境的最佳实践
一、字符编码核心原理
1. 计算机存储本质
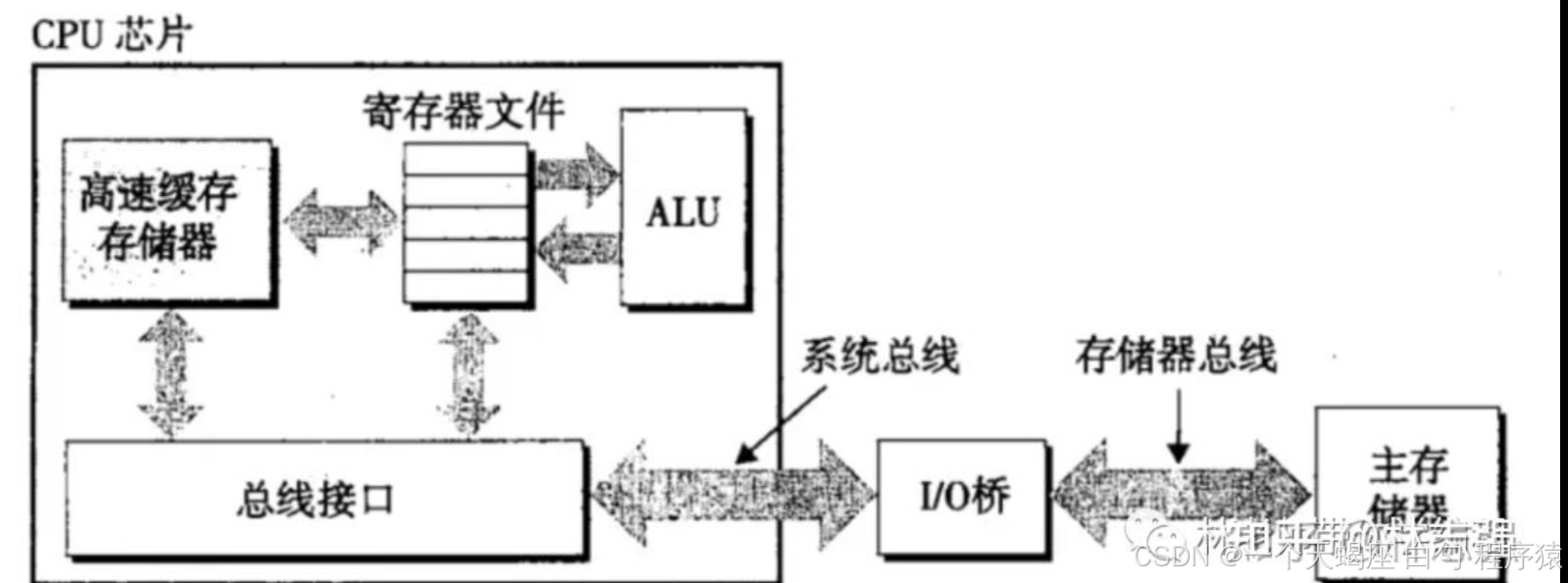
2. Python3的编码革命
# Python2 vs Python3 对比
s = "中文"
# Python2 → <type 'str'>(字节序列)
# Python3 → <class 'str'>(Unicode字符)
3. 主流编码格式对比
| 编码标准 | 单位字节 | 中文字符长度 | 兼容性 | 典型应用场景 |
|---|---|---|---|---|
| ASCII | 1字节 | 不支持 | 英文系统 | 配置文件 |
| Latin-1 | 1字节 | 不支持 | 西欧语言 | 欧洲网站 |
| GBK | 2字节 | 2字节 | 简体中文 | 中文Windows系统 |
| UTF-8 | 1-4字节 | 3字节 | 全球语言 | 现代应用/网络传输 |
| UTF-16 | 2/4字节 | 2或4字节 | 历史遗留系统 | Java/.NET内部处理 |
二、编码转换核心方法
1. 编码(Encode)过程
text = "中文Python"
# 转换为字节序列
utf8_bytes = text.encode('utf-8') # b'\xe4\xb8\xad\xe6\x96\x87Python'
gbk_bytes = text.encode('gbk') # b'\xd6\xd0\xce\xc4Python'
2. 解码(Decode)过程
# 从字节重建字符串
decoded_gbk = gbk_bytes.decode('gbk') # "中文Python"
decoded_utf8 = utf8_bytes.decode('utf-8')
3. 错误处理策略
# 包含非法字节的数据
broken_bytes = b'\xe4\xb8\xad\xffPython'
# 不同处理方式
print(broken_bytes.decode('utf-8', 'ignore')) # "中Python"
print(broken_bytes.decode('utf-8', 'replace')) # "中�Python"
三、文件操作编码实战
1. 文本文件读写
# 写入UTF-8文件
with open('demo_utf8.txt', 'w', encoding='utf-8') as f:
f.write("北京温度: 25℃")
# 读取GBK文件
with open('demo_gbk.txt', 'r', encoding='gbk') as f:
content = f.read()
2. 二进制模式转换编码
# 任意编码文件转UTF-8
with open('legacy.dat', 'rb') as f:
raw_data = f.read()
detected_encoding = chardet.detect(raw_data)['encoding']
text = raw_data.decode(detected_encoding)
with open('modern.txt', 'w', encoding='utf-8') as f:
f.write(text)
四、网络通信编码处理
1. HTTP请求响应处理
import requests
resp = requests.get('https://example.com/中文')
# 自动检测编码
resp.encoding = resp.apparent_encoding
print(resp.text)
2. Socket通信协议
# 服务端发送
sock.send("状态更新: 成功".encode('utf-8'))
# 客户端接收
data = sock.recv(1024)
decoded = data.decode('utf-8')
五、高级编码技巧
1. 编码自动检测
import chardet
def safe_decode(data):
result = chardet.detect(data)
return data.decode(result['encoding'])
with open('unknown.txt', 'rb') as f:
print(safe_decode(f.read()))
2. 混合编码处理
# 处理包含多种编码的文本
mixed_data = b"\x41\x42\x43\xe4\xb8\xad\xe6\x96\x87" # ABC中文
decoded = []
while mixed_data:
try:
decoded.append(mixed_data.decode('utf-8'))
break
except UnicodeDecodeError:
decoded.append(mixed_data[:1].decode('latin-1'))
mixed_data = mixed_data[1:]
print(''.join(decoded)) # ABC中文
六、总结与最佳实践
1. 黄金准则
内部统一:内存中始终使用Unicode(str类型)
尽早转换:在输入/输出边界完成编码转换
明确声明:绝不依赖默认编码设置
2. 配置推荐
# 在程序入口强制编码
import locale
import sys
sys.stdin.reconfigure(encoding='utf-8')
sys.stdout.reconfigure(encoding='utf-8')
locale.setlocale(locale.LC_ALL, 'en_US.UTF-8')
3. 工具清单
编码检测:chardet(pip install chardet)
高级处理:ftfy(修复损坏文本)
性能优化:使用io.TextIOWrapper处理大文件
通过深入理解编码原理并应用本文方案,可彻底解决99%的乱码问题。建议在关键数据通道添加编码校验,并在单元测试中模拟不同编码场景。
Python相关文章(推荐)
| Python全方位指南 | Python(1)Python全方位指南:定义、应用与零基础入门实战 |
| Python基础数据类型详解 | Python(2)Python基础数据类型详解:从底层原理到实战应用 |
| Python循环 | Python(3)掌握Python循环:从基础到实战的完整指南 |
| Python列表推导式 | Python(3.1)Python列表推导式深度解析:从基础到工程级的最佳实践 |
| Python生成器 | Python(3.2)Python生成器深度全景解读:从yield底层原理到万亿级数据处理工程实践 |
| Python函数编程性能优化 | Python(4)Python函数编程性能优化全指南:从基础语法到并发调优 |
| Python数据清洗 | Python(5)Python数据清洗指南:无效数据处理与实战案例解析(附完整代码) |
| Python邮件自动化 | Python(6)Python邮件自动化终极指南:从零搭建企业级邮件系统(附完整源码) |
| Python通配符基础 | Python(7)Python通配符完全指南:从基础到高阶模式匹配实战(附场景化代码) |
| Python通配符高阶 | Python(7 升级)Python通配符高阶实战:从模式匹配到百万级文件处理优化(附完整解决方案) |
| Python操作系统接口 | Python(8)Python操作系统接口完全指南:os模块核心功能与实战案例解析 |
| Python代码计算全方位指南 | Python(9)Python代码计算全方位指南:从数学运算到性能优化的10大实战技巧 |
| Python数据类型 | Python(10)Python数据类型完全解析:从入门到实战应用 |
| Python判断语句 | Python(11)Python判断语句全面解析:从基础到高级模式匹配 |
| Python参数传递 | Python(12)深入解析Python参数传递:从底层机制到高级应用实践 |
| Python面向对象编程 | Python(13)Python面向对象编程入门指南:从新手到类与对象(那个她)的华丽蜕变 |
| Python内置函数 | Python(14)Python内置函数完全指南:从基础使用到高阶技巧 |
| Python参数传递与拷贝机制 | Python(15)Python参数传递与拷贝机制完全解析:从值传递到深拷贝实战 |
| Python文件操作 | Python(16)Python文件操作终极指南:安全读写与高效处理实践 |



















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











