



目录
1.安装
elasticsearch下载地址
下载完成后解压,这里已window版本为例
解压完成后打开bin目录,打开elasticsearch.bat

在浏览器上输入:localhost:9200
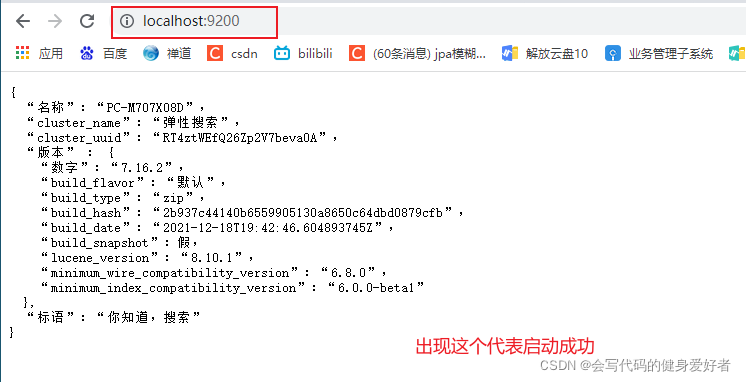
2.安装elasticsearch可视化工具
下载可视化工具之前,要配置一下跨域,不然可能无法连接,在elasticsearch文件目录下有个config目录,下面有个elasticsearch.yml,打开配置如下配置即可:
# 开启跨域
http.cors.enabled: true
# 所有人访问
http.cors.allow-origin: "*"

下载解压后进入,输入cmd命令即可
之后npm install ,npm run start
如果下载npm install 失败可能是npm下载的服务器都在国外,网络不好,这边可以用淘宝的镜像下载,cnpm install ,如果没有安装自行装一下即可
地址:npm install -g cnpm --registry=https://registry.npm.taobao.org
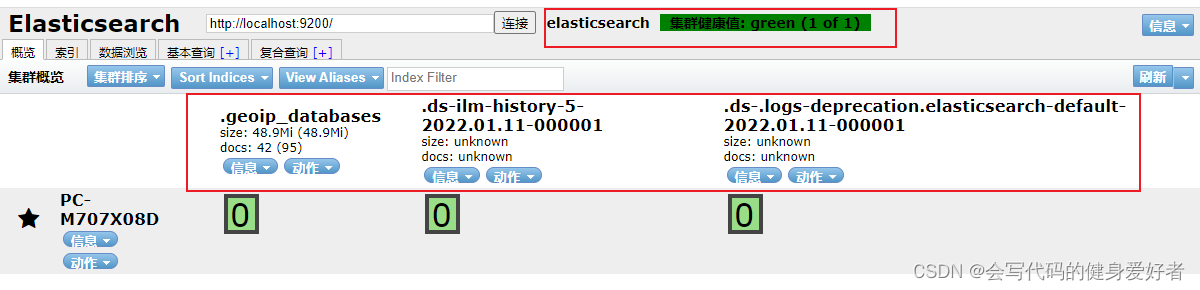
npm run start 之后,可以看见可视化工具的地址

打开即可看见:
3.ik分词器
下载解压到elasticsearch目录下面的plugins文件里面,elasticsearch的插件一般都在这个文件夹里面,注意要版本对应一致
ik分词器有2个分词算法,一个是ik_max_word是最细分词划分,一个是ik_smart是最少切分
重启elasticsearch即可
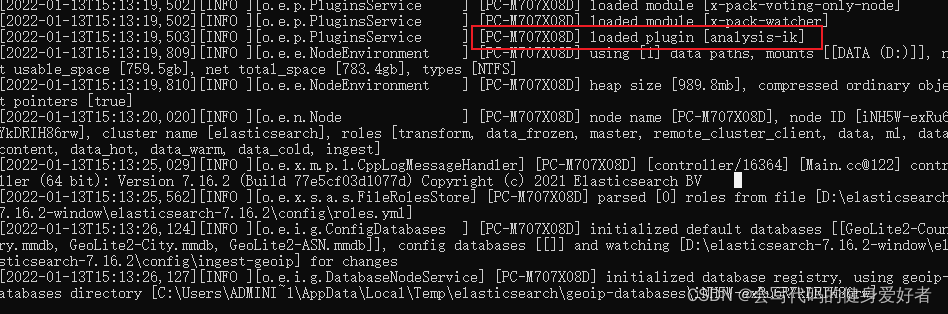
进入kibana看下ik分词器的效果,随便输入几个字,分成了4个一样的字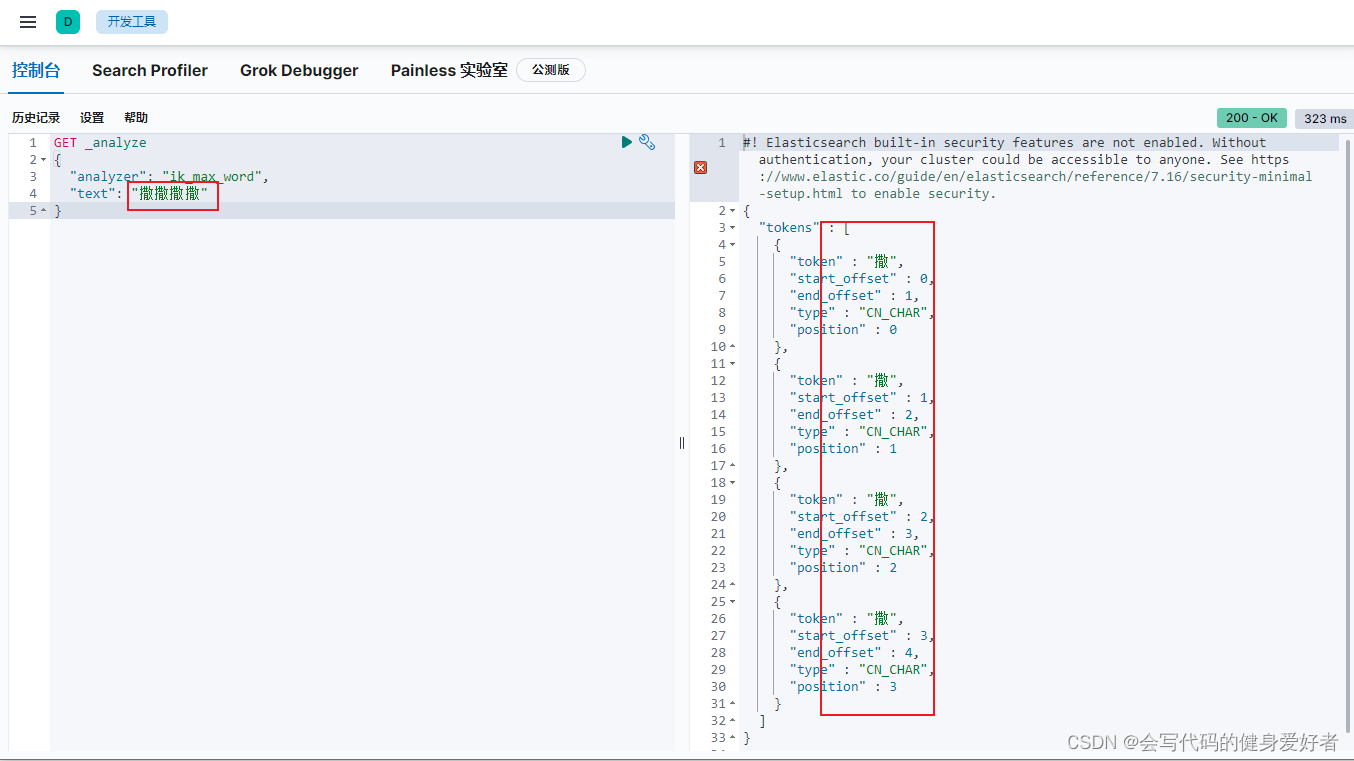
但是我如果想要"撒撒撒撒"这个词呢,ik分词器提供自己配置,在ik分词器下的config目录下面,新建一个.dic的文件,名词随意,然后在同级目录下有个IKAnalyzer.cfg.xml文件,打开把新建的文件配置一下即可
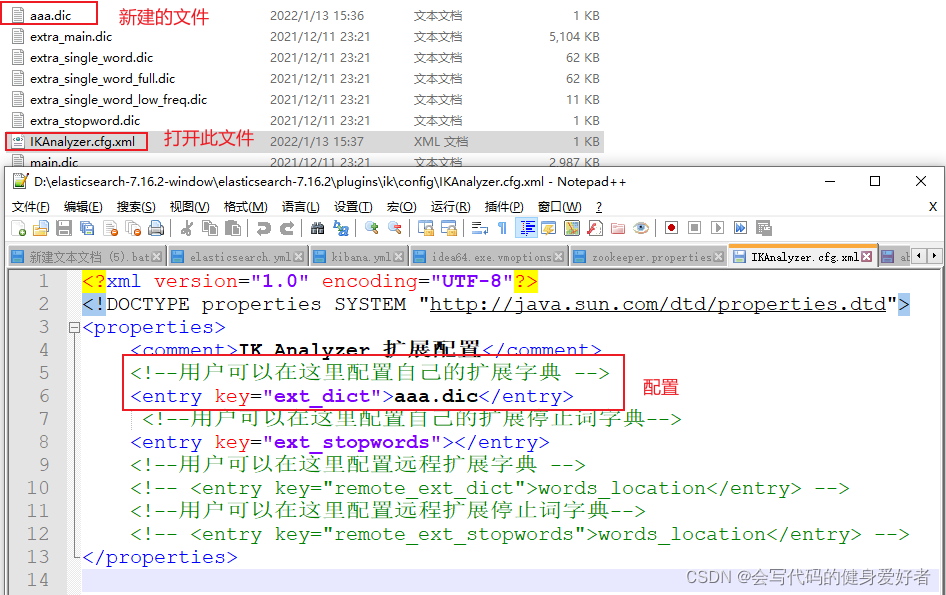
配置的文件如下

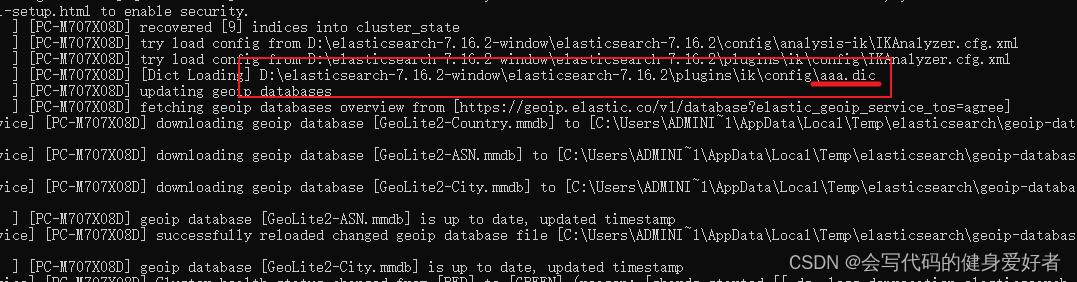
重启elasticsearch可以看见es加载了刚刚新建的文件
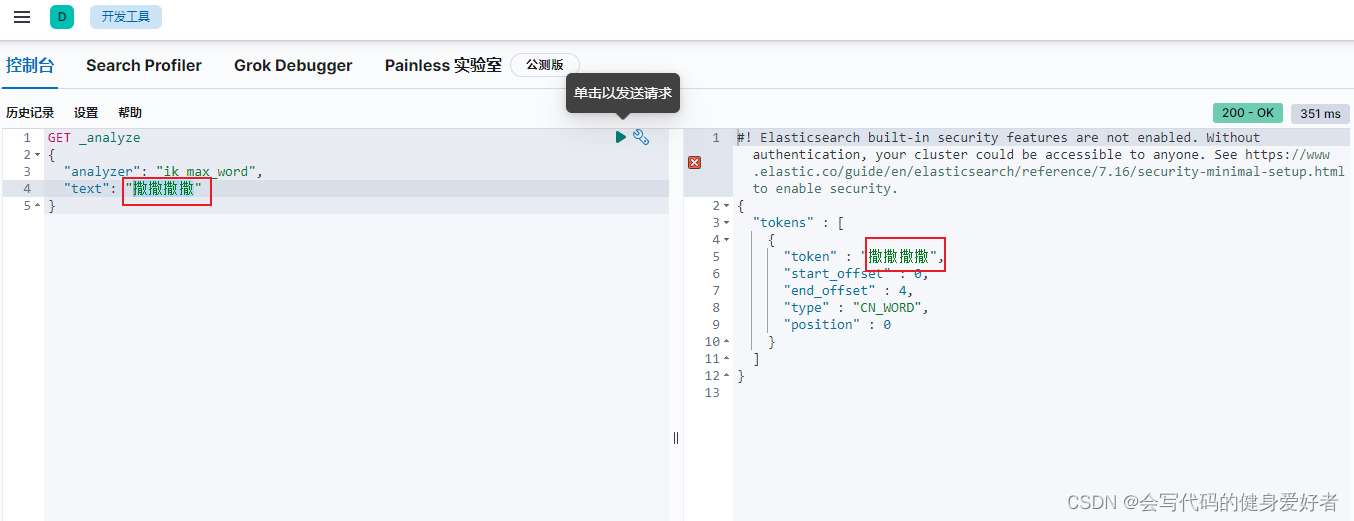
测试验证
5.关于 elasticsearch的curd
使用restful进行curd操作
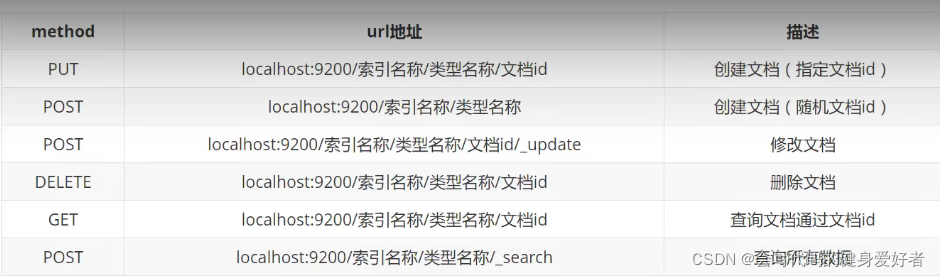
1.创建一个索引
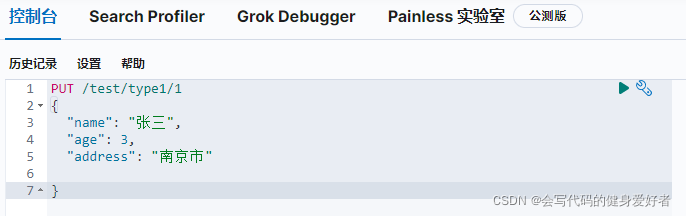
PUT /test(索引名)/type1(类型名)/1(文档id)
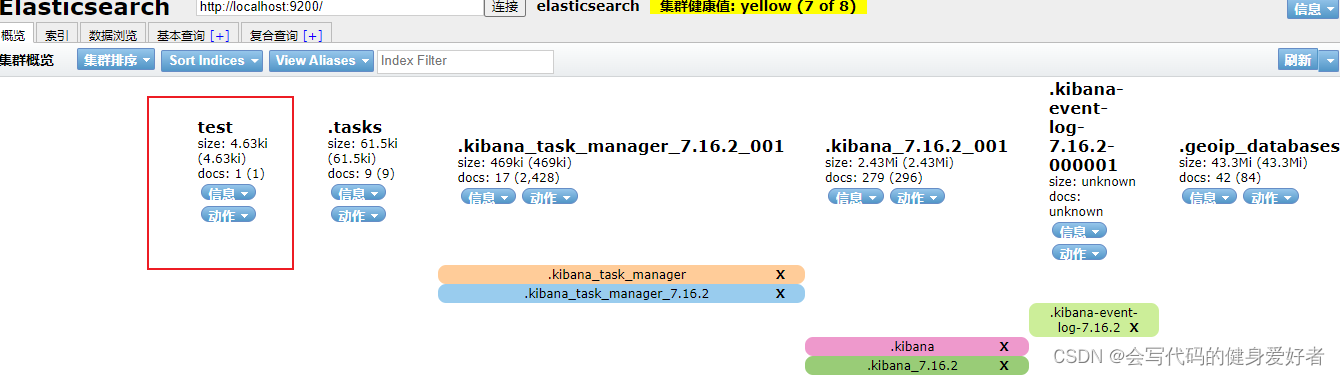
创建完成之后在elasticsearch-head里面查看可以看见,多了一个名为test索引库
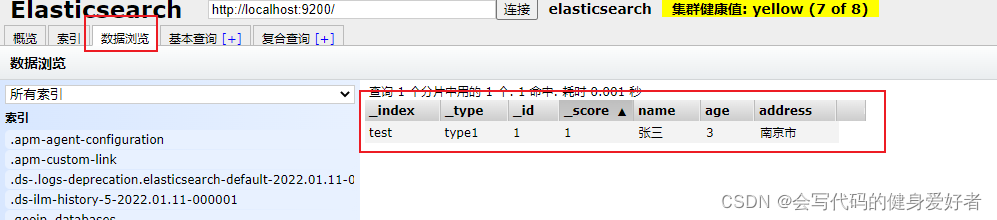
查看下具体数据
指定字段类型 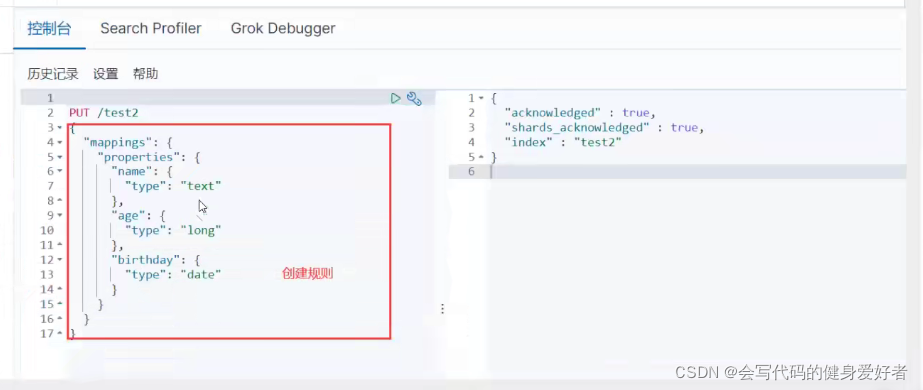
2.查询索引库
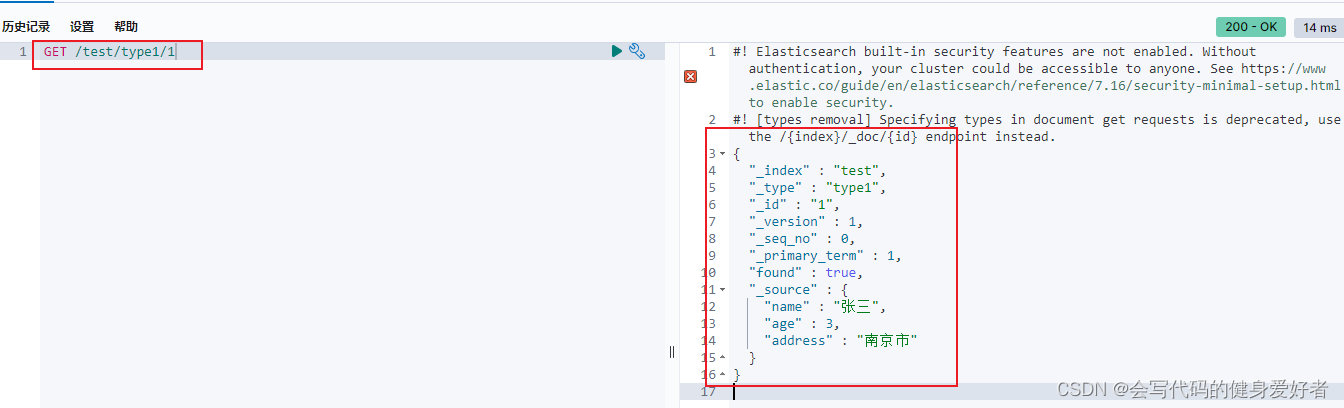
3.修改索引库内容
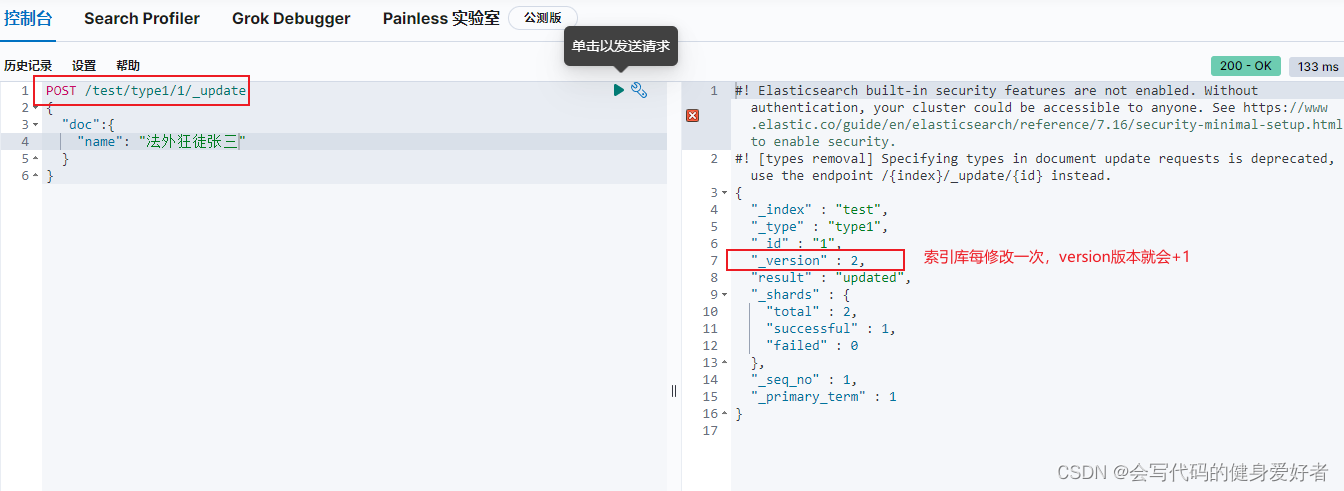
修改结果

4.删除所有库
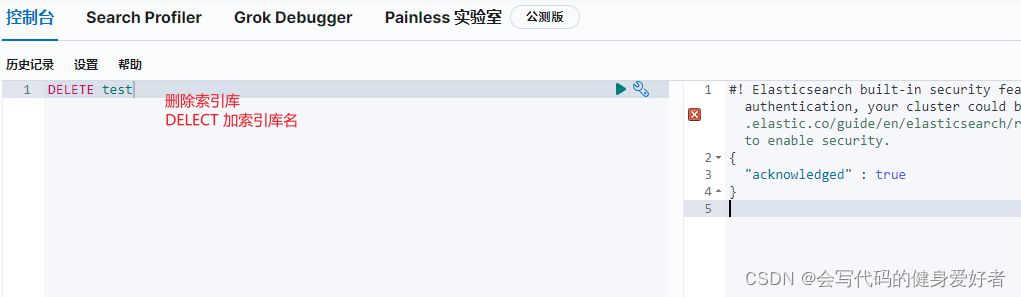
5.简单的根据字段名称查询
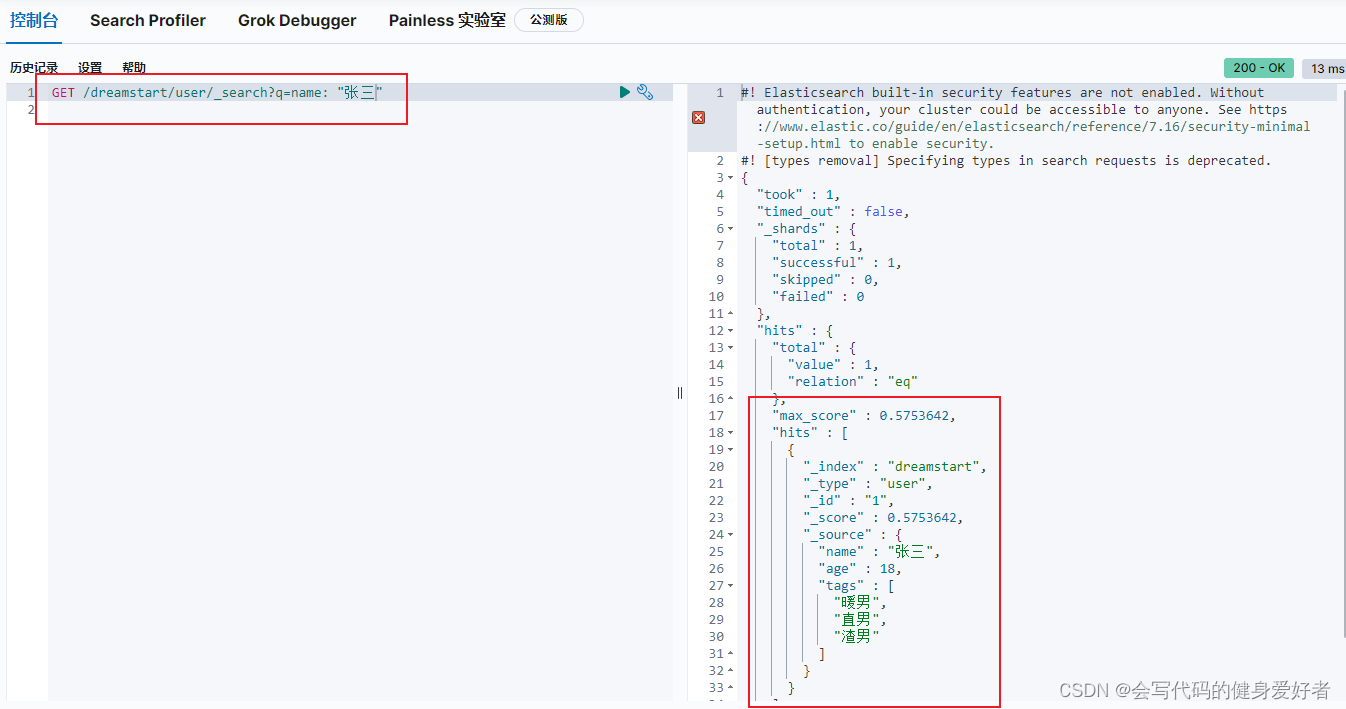
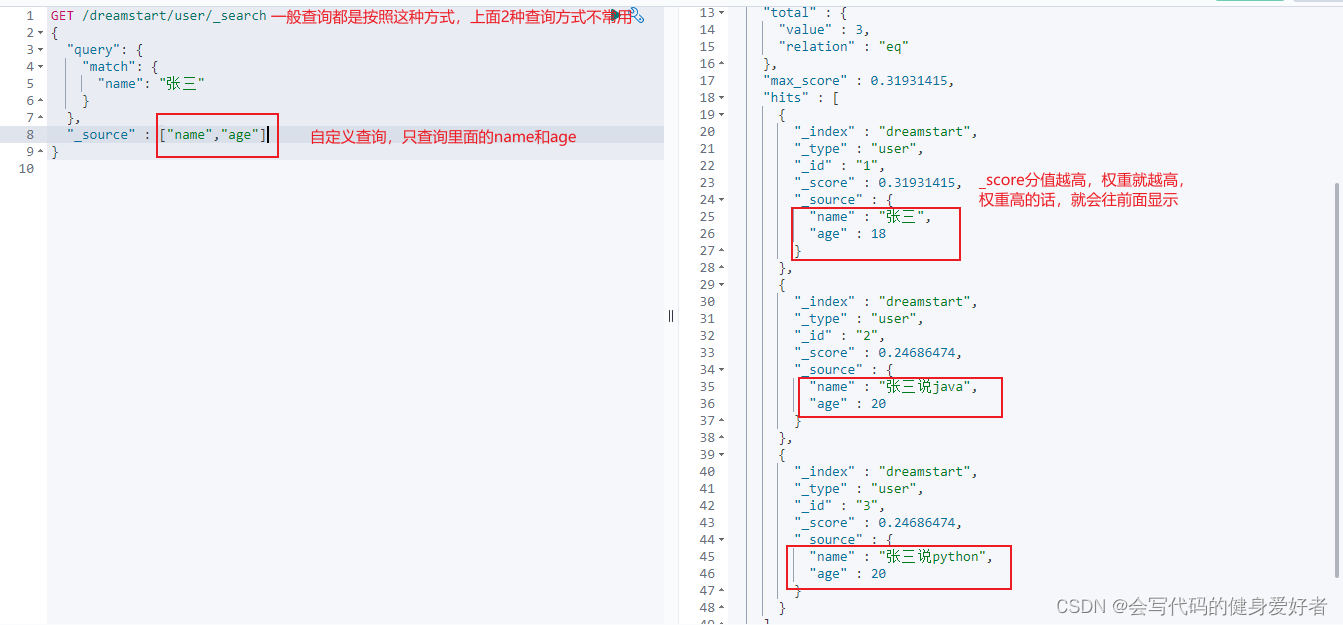
6.正常查询的方式
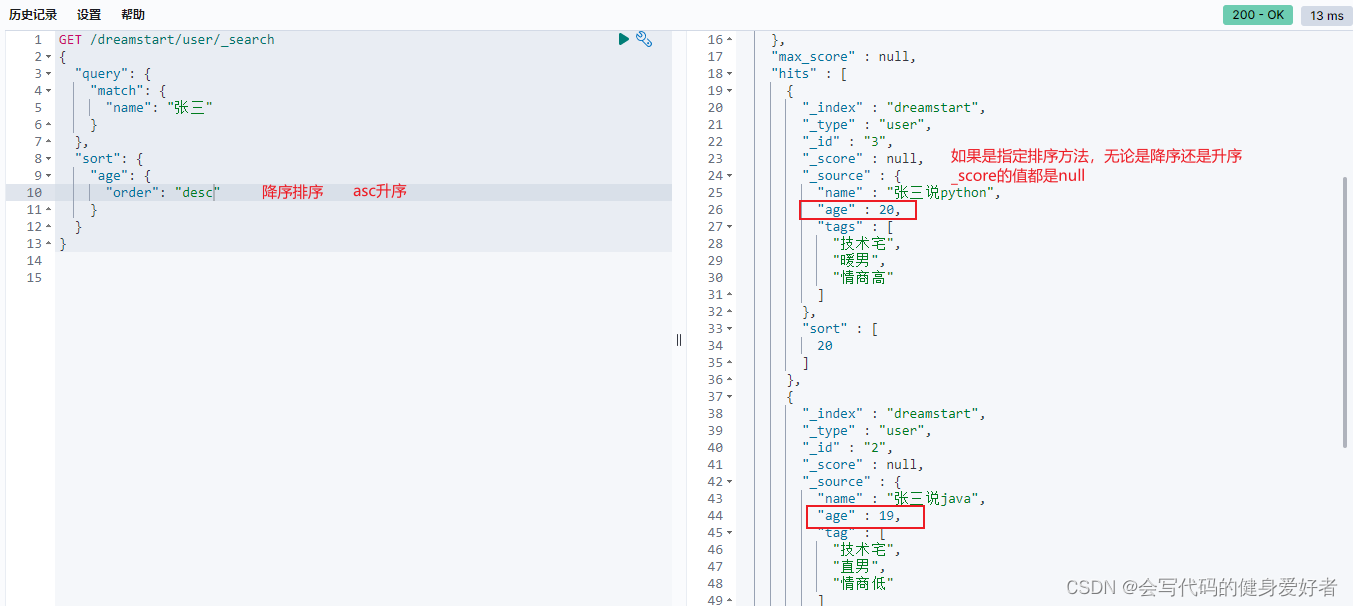
7.根据字段升序或者降序查询
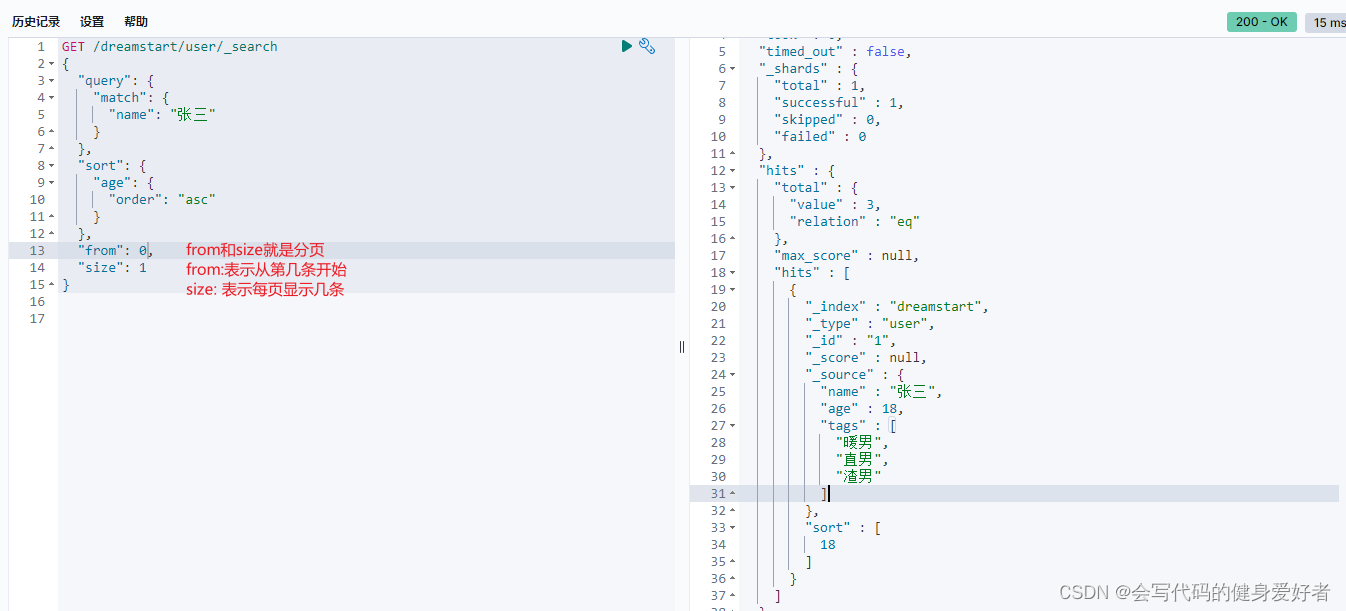
8.分页
9.布尔值查询
关于match和term
term是精确查询,用的就是倒排索引进行一个精确查询,查询效率高
match则是用的分词器解析,会先分析文档,然后根据分析的文档进行查询
must:相当于mysql的and ,where name ="张三" and age = 18;
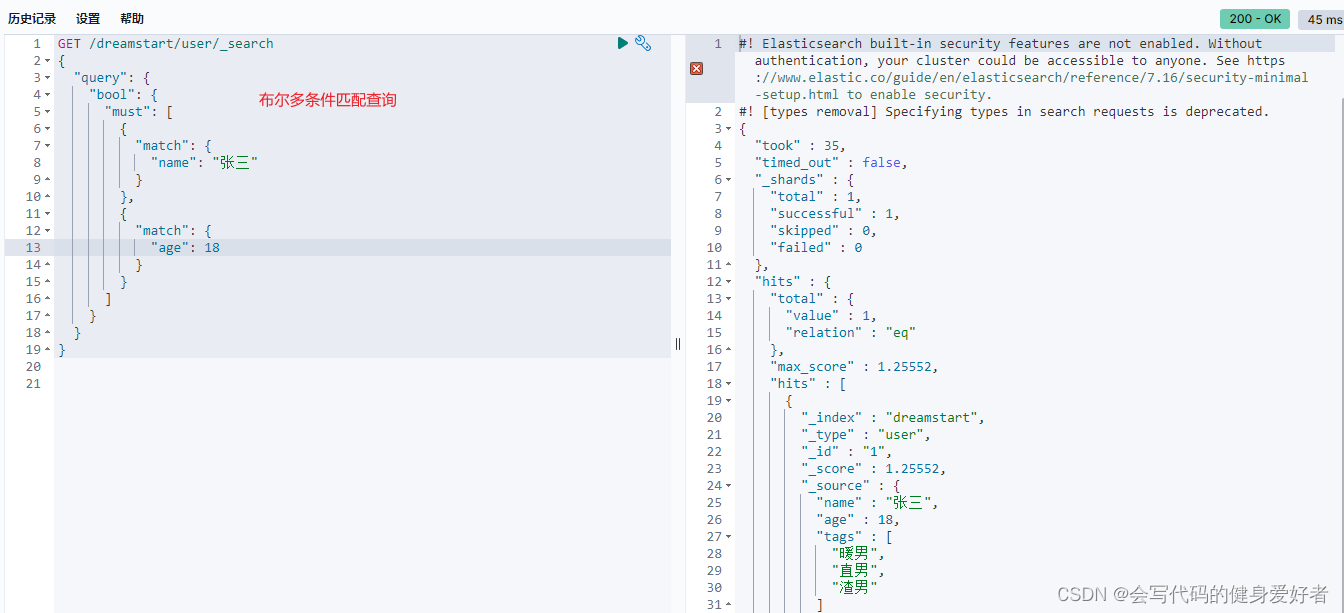
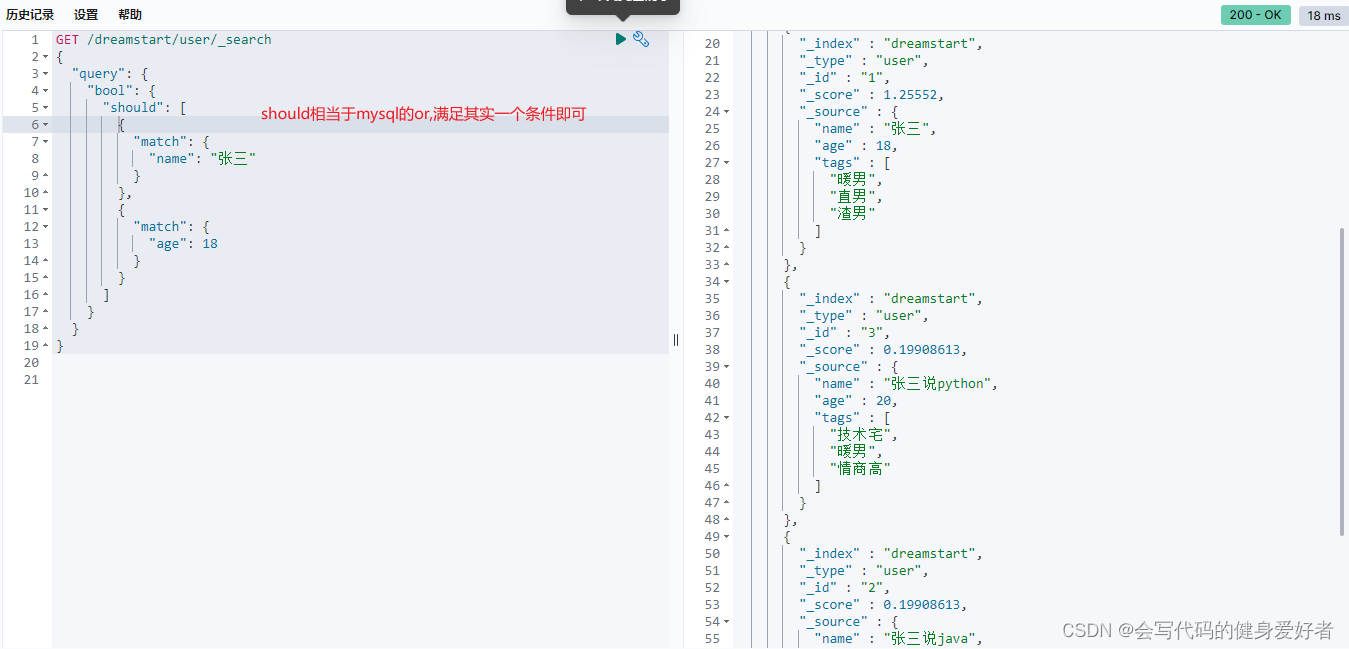
should:相当于mysql的or,where name ="张三" or age = 18;
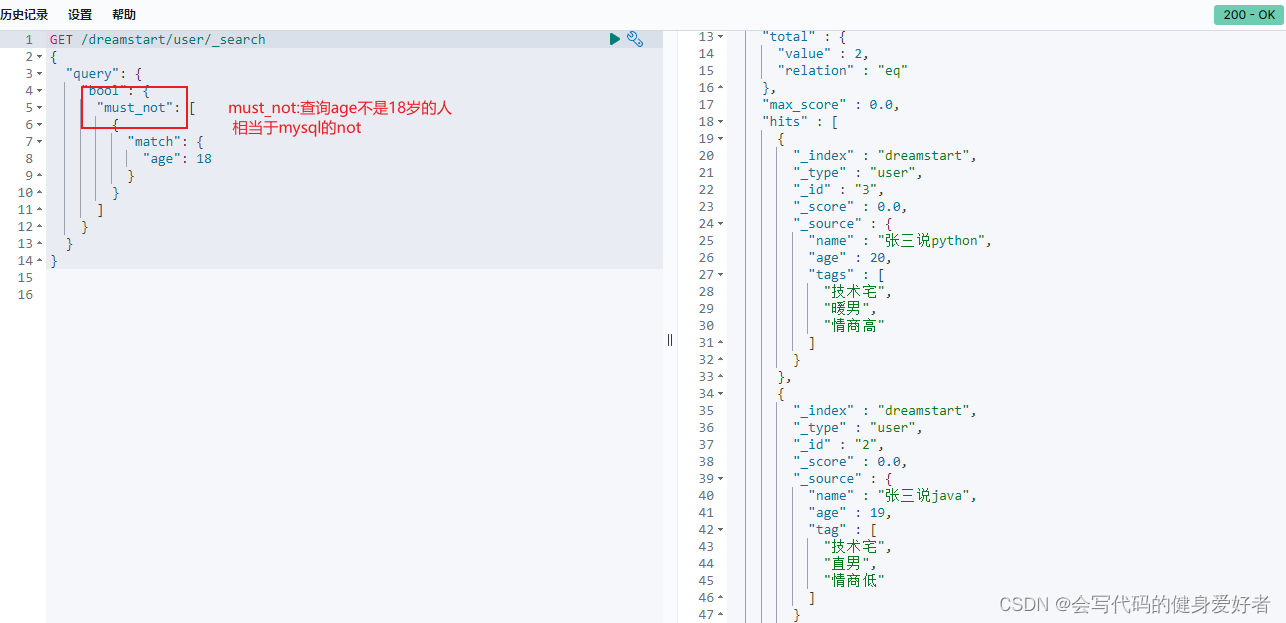
must_not: 相当于mysql的not
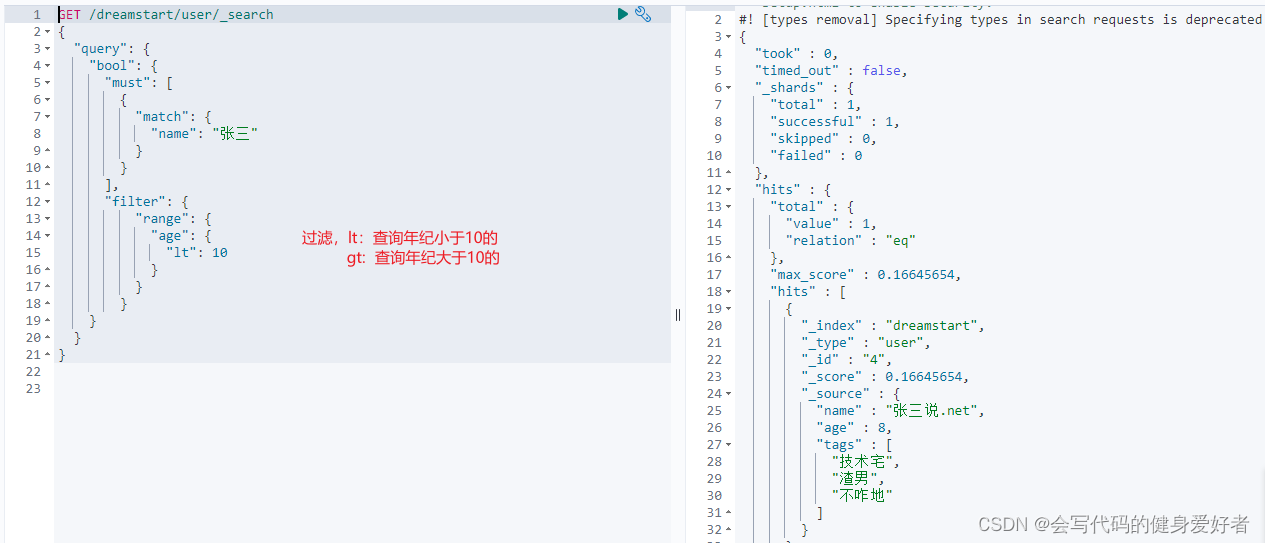
filter: 可以使用filter进行数据过滤
gte>= lte<=
10:多条件模糊查询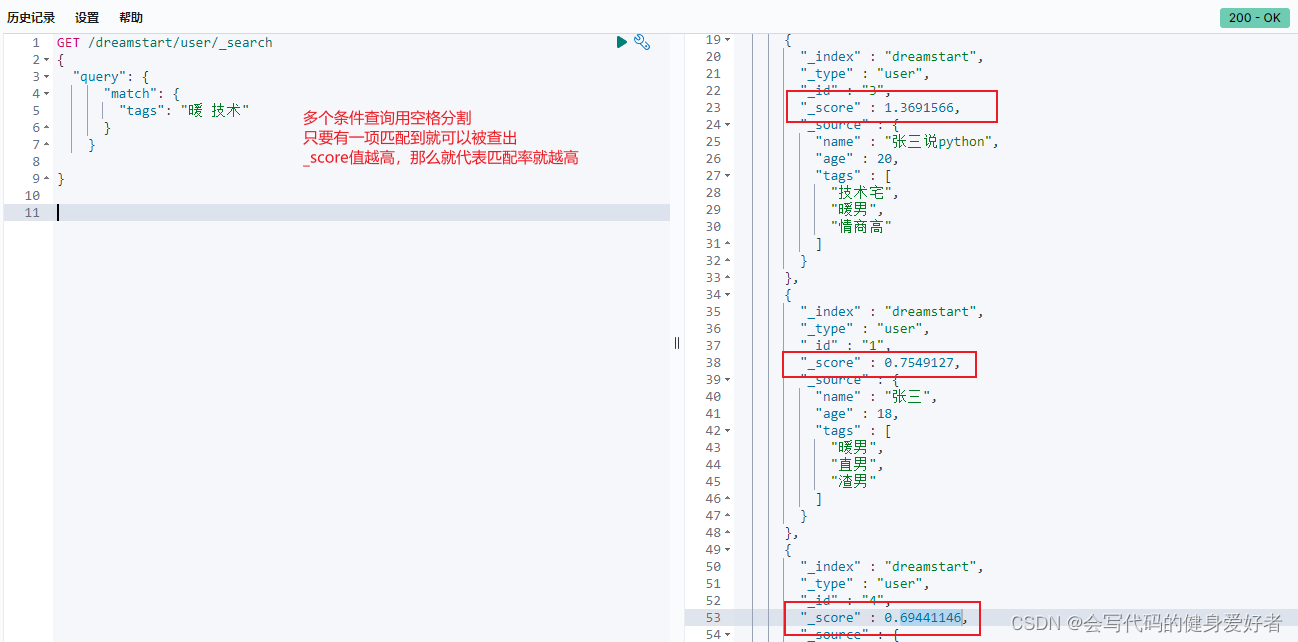
keyword字段不会被分词器解析
如果2个name字段分别是:"张三","张三1"
那么如果name不是keyword字段那么查询name="张三",2条数据都会被查询出来
如果是keyword字段,那么查询的时候则只能查询到1条数据,就是name="张三"的这条数据
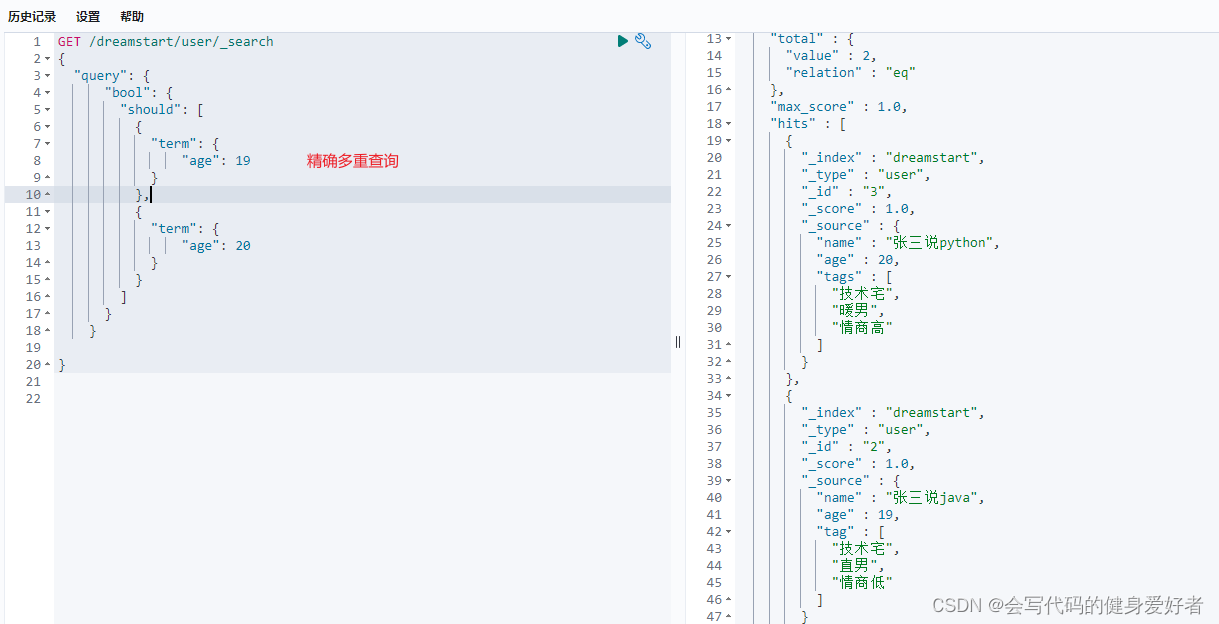
11.精确多重查询
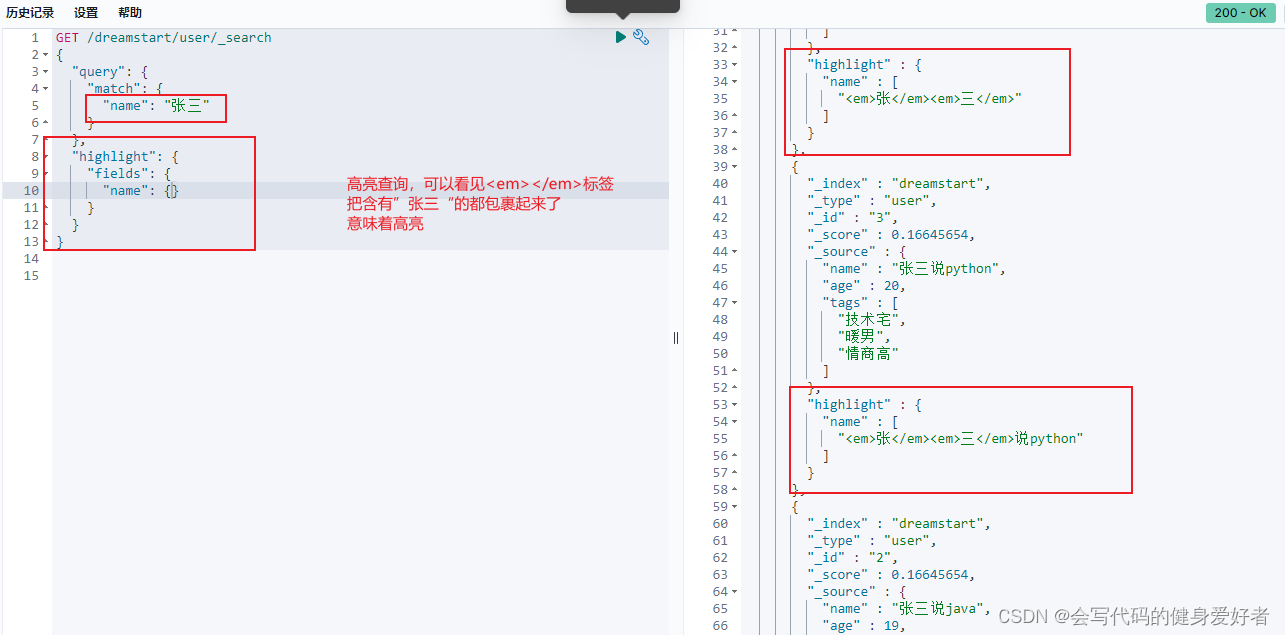
12.高亮查询
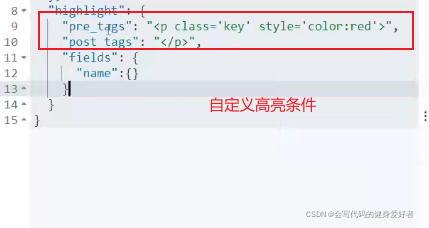
Elasticsearch整合springboot
1.添加依赖
<!--注意和自己下载的Elasticsearch版本对应-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>切记一定要版本对应,不然会报错,那如果看是否对应呢?
先去idea右侧的maven里面去看
然后看下载的版本是多少?如果版本一致最好,如果不是在pom文件指定下版本号即可
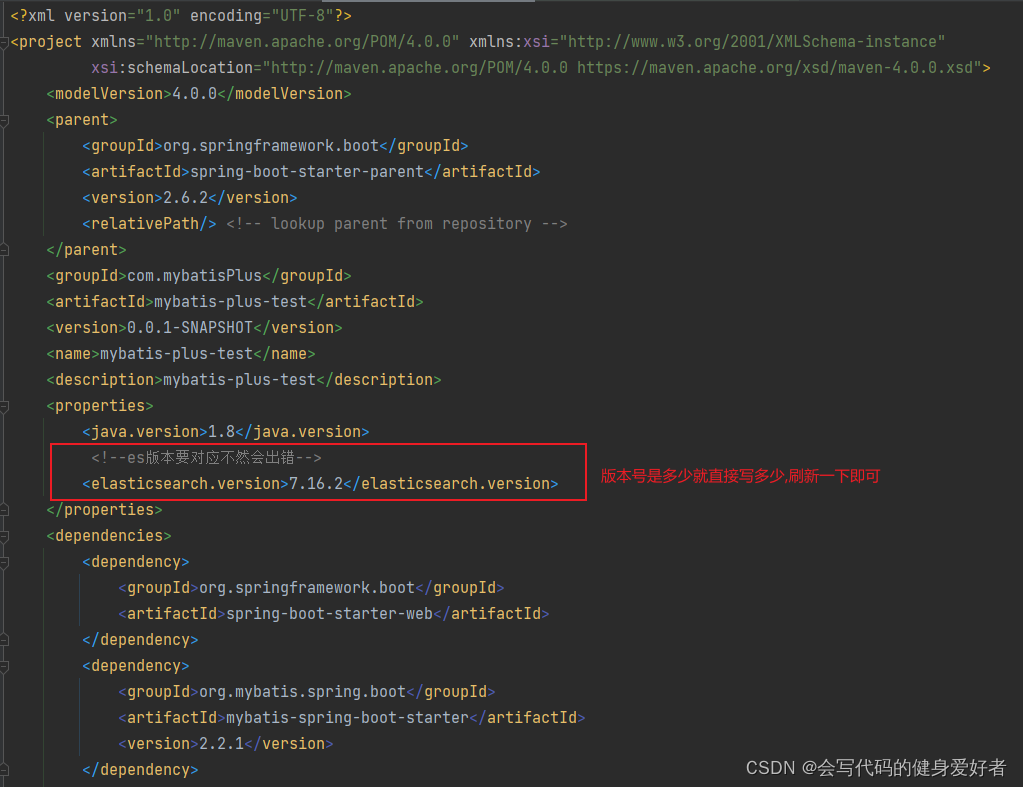
<properties>
<java.version>1.8</java.version>
<!--es版本要对应不然会出错-->
<elasticsearch.version>7.16.2</elasticsearch.version>
</properties>2.写个config类
设置并在项目启动时连接你的elasticsearch
@Configuration
public class ElasticsearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
return restHighLevelClient;
}
}3.常用API:创建索引库
写的时候记得将上面的config类注入进去,下面所有的client都是这个config
@Autowired private RestHighLevelClient client;
//创建索引库
@Test
void contextLoads() throws IOException {
//创建索引请求
CreateIndexRequest request = new CreateIndexRequest("dreamstart2");
//客户端执行请求
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}4.判断这个索引库是否存在
//判断这个索引库是否存在
@Test
void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("dreamstart1");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}5.删除索引库
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("dreamstart1");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
//delete.isAcknowledged() 是否删除成功ture/false
System.out.println(delete.isAcknowledged());
}6.创建文档
@Test
void testAddDocument() throws IOException {
//创建一个user对象
User user = new User("李四",18,"南京市","1999.12.31");
//创建一个请求
IndexRequest request = new IndexRequest("dreamstart1");
//规则 相当于PUT /dreamstart1/_doc/1
request.id("1");
request.timeout();
//将user对象放到索引库(dreamstart1)中
request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,获取响应结果
IndexResponse index = client.index(request, RequestOptions.DEFAULT);
System.out.println(index.toString());
System.out.println(index.status());
}7.判断文档是否存在
@Test
void testExistDocument() throws IOException {
GetRequest request = new GetRequest("dreamstart1","1");
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}8.获取文档类型
@Test
void testGetDocument() throws IOException {
GetRequest request = new GetRequest("dreamstart2","1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
Map<String, Object> source = response.getSource();
//打印文档内容
System.out.println(response.getSourceAsString());
System.out.println(source);
}9.更新文档内容
@Test
void testUpdateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("dreamstart1","1");
updateRequest.timeout();
User user = new User("李四说java",22,"徐州市","1999.12.31");
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse update = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(update);
}10.删除文档记录
@Test
void testDeleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("dreamstart1","1");
DeleteResponse delete = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(delete.status());
}11.批量插入数据
//批量插入数据
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout();
//去数据库查询user表
List<User> users = userMapper.selectList(null);
//将user表里面的数据全部放到es里面
for (User user : users) {
//设置具体索引库
bulkRequest.add(new IndexRequest("dreamstart2")
//设置id
.id(String.valueOf(user.getId()))
//文档内容,user表里面的内容
.source(JSON.toJSONString(user),XContentType.JSON));
}
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
//是否失败,返回false代表成功
System.out.println(bulk.hasFailures());
}12.查询搜索
查询条件可以使用QueryBuilders工具类进行快速匹配查询 QueryBuilders.termsQuery(name指的是字段名,values指的是查询条件):精确查询 QueryBuilders.matchQuery():模糊查询 QueryBuilders.matchAllQuery():匹配所有问题:termsQuery精确查询的时候可能会出现查询不到的情况,就比如我想查询”userName=张三说java“的数据,在我的索引库里面明明有这条数据,但是就是查询不到?
原因:大概率是因为es里面的ik分词器(这个不是es自带的需要自己去下载加上),他把要搜索的张三说java给分词了,但是termQuery又是精确查询,所以查询不到
解决:只需要将要查询的字段后面写上 .keyword就好,keyword代表不分词
//查询搜索
@Test
void testSearchRequest() throws IOException {
//构建搜索查询,具体查询哪个索引库
SearchRequest searchRequest = new SearchRequest("dreamstart2");
//构建查询
SearchSourceBuilder builder = new SearchSourceBuilder();
//查询字段高亮显示
builder.highlighter();
//查询条件可以使用QueryBuilders工具类进行快速匹配查询
// QueryBuilders.termsQuery(name指的是字段名,values指的是查询条件):精确查询
// QueryBuilders.matchQuery():模糊查询
// QueryBuilders.matchAllQuery():匹配所有
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("userName.keyword", "张三说java");
builder.query(termsQueryBuilder);
//分页可以设置不设置也有默认值
builder.from();
builder.size();
//设置查询时间,不要超过60s
builder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(builder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
//拿数据都在search.getHits() 里面
SearchHits hits = search.getHits();
for (SearchHit hit : hits.getHits()) {
//用户数据都在这个hit.getSourceAsMap()里面
System.out.println(hit.getSourceAsMap());
}
System.out.println(JSON.toJSONString(hits));
}13.排序查询和过滤查询
排序查询 builder.sort()
过滤查询 builder.fetchSource()
//排序查询 builder.sort()
//过滤查询 builder.fetchSource()
@Test
void testSearchRequest1() throws IOException {
SearchRequest searchRequest = new SearchRequest();
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchAllQuery());
//根据age字段,倒叙排序
builder.sort("age", SortOrder.DESC);
//包含,排除
// include数组就代表是查询出来的结果字段
String [] include = {"id","age","userName"};
// exclude数组代表除了这个字段不差,其他字段全部查出来
String [] exclude = {};
builder.fetchSource(include,exclude);
builder.from(0);
builder.size(5);
searchRequest.source(builder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsString());
}14.范围查询
gte:大于等于 lte:小于等于
gt:大于 lt:小于
@Test
void testRangeSearchRequest() throws IOException {
SearchRequest searchRequest = new SearchRequest();
//设置查询的索引库,如果不设置会从整个es索引库中搜索
searchRequest.indices("dreamstart2");
SearchSourceBuilder builder = new SearchSourceBuilder();
//根据age这个字段进行范围查询,查询出 大于等于20岁 并且 小于等于25岁 的数据
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("age");
//gte:大于等于 lte:小于等于
//gt:大于 lt:小于
rangeQueryBuilder.gt(20);
rangeQueryBuilder.lt(25);
builder.query(rangeQueryBuilder);
searchRequest.source(builder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsString());
}
}15.高亮查询
//高亮查询
@Test
void testFuzzySearchRequest() throws IOException {
SearchRequest searchRequest = new SearchRequest();
//设置查询的索引库,如果不设置会从整个es索引库中搜索
searchRequest.indices("dreamstart2");
SearchSourceBuilder builder = new SearchSourceBuilder();
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("userName.keyword", "张三说java");
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("userName");
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
builder.highlighter(highlightBuilder);
builder.query(termsQueryBuilder);
searchRequest.source(builder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
//查询执行时间
System.out.println(search.getTook());
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsString());
}
}16.组合查询
@Test
void testFuzzySearchRequest1() throws IOException {
SearchRequest searchRequest = new SearchRequest("dreamstart2");
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//must:必须满足age="20"并且userName=“张三说.net”的数据
//mustNot:反之,必须不满足age=20的数据 boolQueryBuilder.mustNot(QueryBuilders.matchQuery("age","20"));
boolQueryBuilder.must(QueryBuilders.matchQuery("age","20"));
boolQueryBuilder.must(QueryBuilders.matchQuery("userName","张三说.net"));
//should:要那么满足age="20",要么就满足userName=“张三说java”,数据满足二者其中一个就行
boolQueryBuilder.should(QueryBuilders.matchQuery("age",20));
boolQueryBuilder.should(QueryBuilders.matchQuery("userName.keyword","张三说java"));
builder.query(boolQueryBuilder);
searchRequest.source(builder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsString());
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









