






 本文聚焦Pytorch网络性能问题,分析了loss波动、不降等情况。介绍了添加BN模块、残差连接、正则化、Dropout等优化方法,对比了tf和torch的一维卷积。还从数据与标签、模型等方面探讨不收敛原因,并给出训练效果不佳时如选择交叉熵、使用Mini - batch等解决办法。
本文聚焦Pytorch网络性能问题,分析了loss波动、不降等情况。介绍了添加BN模块、残差连接、正则化、Dropout等优化方法,对比了tf和torch的一维卷积。还从数据与标签、模型等方面探讨不收敛原因,并给出训练效果不佳时如选择交叉熵、使用Mini - batch等解决办法。
1. 网络性能
看网络的性能,主要是看Loss,偶尔看看评价指标
1.1 loss 波动很大,不是一直朝着减小的方向进行loss上下横跳
一是可能learning_rate对于当前模型来说,取的太大了,模型输出在不同的凹面间进行横跳。
二是输入数据分布不均匀,处于不同的量纲下,特异性太强,导致模型较难拟合。这时候可以检查下数据输入,加一些Normalization的操作.
三是原数据样本少,特异性强(一条样本就是一个类型),模型学不会,这种是需要人工去检查一下数据的,看下数据的样本数量以及分布情况,是不是可以拟合的。
1.2 loss 不降 或 短暂下降后就不变了出现这种现象:
第一个要检查的就是是不是learning_rate太小了(跟上面情况相反了),模型找到一个局部最优点就不优化了。
其次,**可以加一些正则化操作,dropout,或加一些扰动、对抗训练等。因为可能是训练的数据比较简单、分布一致,或是模型参数复杂,出现了过拟合的情况,导致loss不降了。**
另外,还要再检查一下,模型的网络代码,**比如错误的使用的激活函数,如ReLU等, 激活函数Relu将输出全部映射到0-1间,而当做回归任务时,这样的0-1输出是没办法覆盖整个答案空间的,这样也是会导致loss降不动**。
以上只是针对loss,去看网络不收敛的情况下的一些可能原因。但实际中,出现不收敛或模型没学好的其他情形,应该是需要结合更多指标来辅助判断的,如综合看你的loss下降情况以及验证集的指标Precision,Recall,F1等情况了。
1. 若是loss还能降,指标还在升,那说明欠拟合,还没收敛,应该继续train,增大epoch。
2. 若是loss还能再降,指标也在降,说明过拟合了,那就得采用提前终止(减少epoch)或采用weight_decay等防过拟合措施。
3. 若是设置epoch=16,到第8个epoch,loss也不降了,指标也不动了,说明8个epoch就够了,剩下的白算了。
以上说的也都是预设的一些理想情况,现实中往往没有这么明确,就如第三种情况,它可能只是到了局部最优点,并没有最优,你可能换个大点的batch_size或lr,模型就调了个方向继续下坡,指标又能往上走点,这就有点玄学了,这样的情况就不再讨论了。
2. 添加BN模块
bathnormalization就是批标准化,批指的是mini-batch,标准化也就是0均值1方差,
看似这个东西比较简单,但是威力却是很强,有下面几个优点(来自2015年原文《BatchNormalization:Accelerating Deep Network Train by Reducing Internal Covariate Shift》,这篇论文堪称这一年深度学习界最重要的一篇论文):
-可以用更大学习率,加速模型收敛
-可以不用精心设计权重初始化
-可以不用Dropout或者较小的Dropout
-可以不用L2或者较小的weight decay
-可以不用局部响应标准化(Alexnet中用到过)
BN模块应该添加 激活层前面
在模型实例化后,我们需要对BN层进行初始化。PyTorch中的BN层是通过nn.BatchNorm1d或nn.BatchNorm2d类来实现的。
bn = nn.BatchNorm1d(20) #
对于1D输入数据,使用nn.BatchNorm1d;对于2D输入数据,使用nn.BatchNorm2d
在模型的前向传播过程中,我们需要将BN层应用到适当的位置。以全连接层为例,我们需要在全连接层的输出之后调用BN层。
class MLP(nn.Module):
def __init__(self, neural_num, layers=100):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.bns = nn.ModuleList([nn.BatchNorm1d(neural_num) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear), bn in zip(enumerate(self.linears), self.bns):
x = linear(x)
# x = bn(x)
x = torch.relu(x)
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
print("layers:{}, std:{}".format(i, x.std().item()))
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
# method 1
# nn.init.normal_(m.weight.data, std=1) # normal: mean=0, std=1
# method 2 kaiming
# 由于网络里面用到了relu,所以这里使用Kaiming初始化方法
nn.init.kaiming_normal_(m.weight.data)
neural_nums = 256
layer_nums = 100
batch_size = 16
net = MLP(neural_nums, layer_nums)
# net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
2.1 BN的分类
-nn.BatchNorm1d
-nn.BatchNorm2d
-nn.BatcNorm3d
上面三个BatchNorm方法都继承_BatchNorm这个基类,初始化参数如下:

(1)num_features表示一个样本的特征数量,这是最重要的一个参数。
(2)eps表示分母修正项,
(3)momentum表示指数加权平均估计当前mean/var.
(4)affline表示是否需要affline transform,
(5)track_running_stats表示是训练状态还是测试状态,这个也是非常关键的,因为我们发现momentum那里有个均值和方差,如果是训练状态,那么就需要重新估计mean和方差,而如果是训练状态,那么久需要重新估计mean和方差,而如果是测试状态,就用训练时候统计的均值和方差。
2.2.1 nn.BatchNorm1d->input = B *特征数 *1d特征
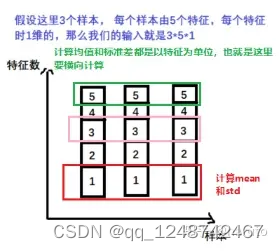
batch_size = 3 # 3个样本
num_features = 5 # 5个特征
momentum = 0.3 # 这个计算后面均值,方差的时候用到
features_shape = (1) # 我们特征的维度是1
feature_map = torch.ones(features_shape)
# 1D 一个特征
feature_maps = torch.stack([feature_map*(i+1) for i in range(num_features)], dim=0)
# 2D 一列数据
feature_maps_bs = torch.stack([feature_maps for i in range(batch_size)], dim=0)
# 3D 上面那3列数据
print("input data:\n{} shape is {}".format(feature_maps_bs, feature_maps_bs.shape))
bn = nn.BatchNorm1d(num_features=num_features, momentum=momentum) # BN1d在这里定义
running_mean, running_var = 0, 1 # 这个得初始化,毕竟我们这是第一次迭代
for i in range(2):
outputs = bn(feature_maps_bs)
print("\niteration:{}, running mean: {} ".format(i, bn.running_mean))
print("iteration:{}, running var:{} ".format(i, bn.running_var))
mean_t, var_t = 2, 0
running_mean = (1 - momentum) * running_mean + momentum * mean_t
# 采用滑动平均方式计算均值和方差
running_var = (1 - momentum) * running_var + momentum * var_t
print("iteration:{}, 第二个特征的running mean: {} ".format(i, running_mean))
print("iteration:{}, 第二个特征的running var:{}".format(i, running_var))
2.1.2 -nn.BatchNorm2d-> input=B特征数2d特征
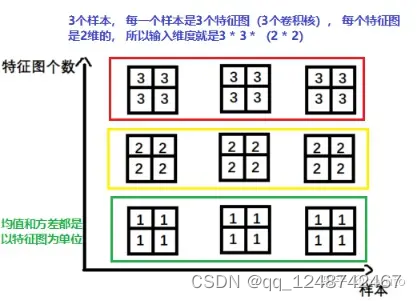
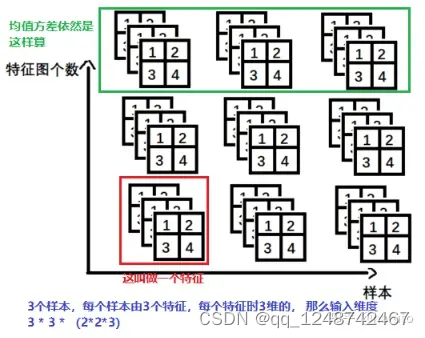
2.1.3 -nn.BatchNorm3d->input=B * 特征数 *3d特征
2.2 BN方法的分类
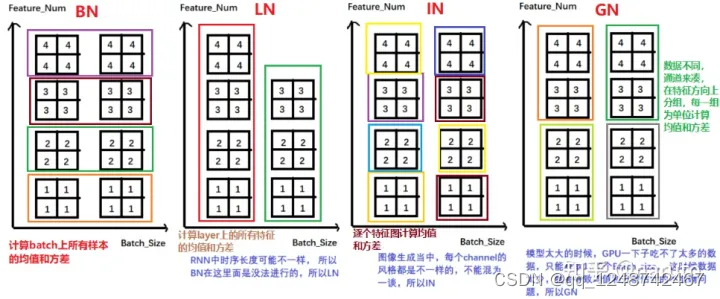
我们常见得Normalization方法其实有四种,分别是
(1)BatchNormalization是在一个batch上去计算均值和方差,
(2)Layer Normalization是以层为单位去计算均值和方差,
(3)Instance Normalization主要是再图像生成方法中使用得一个方法,
(4)Group Normalization是按组为单位计算均值和方差。
BN与LN得区别:
-LN中同层神经元输入拥有相同得均值和方差,不同得输入样本有不同得均值和方差
-BN中则针对不同神经元输入计算均值和方差,同一个batch中得输入拥有相同得均值和方差。
还要注意,再LN中不再有running_mean和running_var,并且gamma和beta为逐元素得。下面我们看看pytorch得LN:
nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
这里得normalized_shape表示该层特征形状,这个依然是最重要得。eps表示分母修正项,elementwise_affine表示是否需要affine transform.
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.bn = nn.BatchNorm1d(20)
self.fc2 = nn.Linear(20, 30)
self.fc3 = nn.Linear(30, 2)
def forward(self, x):
x = self.fc1(x)
x = self.bn(x)
x = self.fc2(x)
x = self.fc3(x)
return x
3. 添加残差连接
最主要的是需要注意输入参数的维度是否一致
import torch
import torch.nn as nn
class ResidualBlock(nn.Module):
def __init__(self, input_size, hidden_size):
super(ResidualBlock, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, input_size)
self.relu = nn.ReLU()
def forward(self, x):
residual = x
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out += residual
out = self.relu(out)
return out
-----------------------------------
©著作权归作者所有:来自51CTO博客作者mob649e8166c3a5的原创作品,请联系作者获取转载授权,否则将追究法律责任
pytorch 全链接层设置残差模块
https://blog.51cto.com/u_16175510/6892589
4. 一维卷积(tf和torch)
a. tf.keras.layers.Conv1D
该函数的必要参数有两个,filters(即 out_channels)和 kernel_size。对于 X = (1, 8, 128),如下代码可以得到 Y = (1, 6, 64):
import tensorflow as tf
X = tf.random.normal((1, 8, 128))
X.shape
# TensorShape([1, 8, 128])
conv = tf.keras.layers.Conv1D(64, 3, padding='valid')
Y = conv(X)
Y.shape
# TensorShape([1, 6, 64])
keras 为了让整个 api 更加用户友好,隐藏了两个关键参数。第一个是 data_format,在默认值 “channels_last”下,X 的维度顺序为 [batch_size, seq_length, input_channels],更符合NLP任务的直观理解。如果修改为“channels_first”,X 需要满足 [batch_size, input_channels, seq_length]。第二个是 input_channels,在函数内部自动获得:
input_channel = self._get_input_channel(input_shape)
如果 X 和 data_format 不匹配,就得不到正确的 in_channels。这里就是和 Pytorch 显著差异的地方。
b. torch.nn.Conv1d
该函数的必要参数有三个,in_channels, out_channels 和 kernel_size。被 keras 隐藏的 in_channels 被直接暴露,并且也不支持 data_format 的设置,X 的维度顺序必须是 [batch_size, input_channels, seq_length]。因此,对于通常的使用习惯,必须要先对输入做一次维度转换,再对输出做一次。对于 X = (1, 8, 128),如下代码可以得到 Y = (1, 6, 64):
import torch
X = torch.randn(1, 8, 128)
X.shape
# torch.Size([1, 8, 128])
Xt = X.transpose(1,2)
Xt.shape
# torch.Size([1, 128, 8])
conv = torch.nn.Conv1d(128, 64, 3)
Yt = conv(Xt)
Yt.shape
# torch.Size([1, 64, 6])
Y = Yt.transpose(Yt)
Y.shape
# torch.Size([1, 6, 64])
5. 添加正则化
注意:一般情况下 weight_decay = lr/10
weight decay的大小一般根据具体情况而定,通常在.0001到.001之间。
它的作用是在训练神经网络时对权重进行正则化,防止讨拟合
(1)如果weight decay设置得太小,可能无法有效地防止过拟合,
(2)如果设置得太大,可能会导致欠拟合。因此,需要根据实际情况进行调整
在优化器的位置上设置L2正则化(weight_decay=0.0001)
# 定义模型
model = Net()
#定义代价函数
CrossEntropy_loss = nn.CrossEntropyLoss()
#定义优化器,设置L2正则化(weight_decay=0.0001)
LR=0.5
optimizer = optim.SGD(model.parameters(),lr=LR,weight_decay=0.001)
————————————————
版权声明:本文为优快云博主「留小星」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jerry_liufeng/article/details/109608811
6. Dropout
(1)dropout加得时候注意放置得位置
(2)由于dropout操作,模型训练和测试是不一样得,
上面我们说了,训练得时候采用dropout而测试得时候不用dropout,那么我们在迭代得时候,就得告诉网络目前是什么状态,如果要测试,就得先用.eval()函数告诉网络一下子,训练得时候就用.train()函数告诉网络一下子。
class MLP(nn.Module):
def __init__(self, neural_num, d_prob=0.5):
super(MLP, self).__init__()
self.linears = nn.Sequential(
nn.Linear(1, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
# 注意这里用上了Dropout, 我们看到这个Dropout是接在第二个Linear之前,Dropout通常放在需要Dropout网络的前一层
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
# 通常输出层的Dropout是不加的,这里由于数据太简单了才加上
nn.Linear(neural_num, 1),
)
def forward(self, x):
return self.linears(x)
7. 超级重要
在面对模型不收敛的时候,首先要保证训练的次数够多。在训练过程中,loss并不是一直在下降,准确率一直在提升的,会有一些震荡存在。只要总体趋势是在收敛就行。若训练次数够多(一般上千次,上万次,或者几十个epoch)没收敛,再考虑采取措施解决。
7.1、数据与标签方面
(1) 没有对数据进行预处理。数据分类标注是否准确?数据是否干净?
(2)没有对数据进行归一化。
由于不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。此外,大部分神经网络流程都假设输入输出是在0附近的分布,从权值初始化到激活函数、从训练到训练网络的优化算法。将数据减去均值并除去方差
(3)样本的信息量太大导致网络不足以fit住整个样本空间。
样本少只可能带来过拟合的问题,你看下你的training set上的loss收敛了吗?如果只是validate set上不收敛那就说明overfitting了,这时候就要考虑各种anti-overfit的trick了,比如dropout,SGD,增大minibatch的数量,减少fc层的节点数量,momentum,finetune等。
(4)标签的设置是否正确。
7.2 模型方面
1. 网络设定不合理。
如果做很复杂的分类任务,却只用了很浅的网络,可能会导致训练难以收敛。应当选择合适的网络,或者尝试加深当前网络。总体来说,网络不是越深越好,开始可以搭建一个3~8层的网络,当这个网络实现的不错时,你可以考虑实验更深的网络来提升精确度。从小网络开始训练意味着更快,并且可以设置不同参数观察对网络的影响而不是简单的堆叠更多层。
2. Learning rate不合适。
如果太大,会造成不收敛,如果太小,会造成收敛速度非常慢。
在自己训练新网络时,可以从0.1开始尝试,如果loss不下降的意思,那就降低,除以10,用0.01尝试,一般来说0.01会收敛,不行的话就用0.001. 学习率设置过大,很容易震荡。不过刚刚开始不建议把学习率设置过小,尤其是在训练的开始阶段。在开始阶段我们不能把学习率设置的太低否则loss不会收敛。
从0.1,0.08,0.06,0.05 …逐渐减小直到正常为止。
有的时候候学习率太低走不出低估,把冲量提高也是一种方法,适当提高mini-batch值,使其波动不大。
learning rate设大了会带来跑飞(loss突然一直很大)的问题。这个是新手最常见的情况——为啥网络跑着跑着看着要收敛了结果突然飞了呢?可能性最大的原因是你用了relu作为激活函数的同时使用了softmax或者带有exp的函数做分类层的loss函数。
当某一次训练传到最后一层的时候,某一节点激活过度(比如100),那么exp(100)=Inf,发生溢出,bp后所有的weight会变成NAN,然后从此之后weight就会一直保持NAN,于是loss就飞起来辣。如果lr设的过大会出现跑飞再也回不来的情况。这时候你停一下随便挑一个层的weights看一看,很有可能都是NAN了。对于这种情况建议用二分法尝试。0.1~0.0001.不同模型不同任务最优的lr都不一样。
3. 隐层神经元数量错误。
在一些情况下使用过多或过少的神经元数量都会使得网络很难训练。
太少的神经元数量没有能力来表达任务,而太多的神经元数量会导致训练缓慢,并且网络很难清除一些噪声。
隐层神经元数量可以从256 到1024中间开始设置,然后可以看看研究人员使用的数字,可以用作参考。
如果他们使用的数字与这个大不相同,那么可以想象一下这其中的原理。在决定使用隐层的单元数量之前,最为关键的是考虑你需要通过这个网络表达信息的实际值的最少数量,然后再慢慢增加这个数字。
如果你做回归任务可以考虑使用的神经元数量为输入或输出变量的2到3倍。
实际上,与其它因素相比,隐藏单元的数量通常对于神经网络的性能影响相当小。并且在很多情况下,增大所需要隐藏单元的数量仅仅是减慢了训练速度。
4. 错误初始化网络参数。
如果没有正确初始化网络权重,那么网络将不能训练。
通常使用的比较多的初始化权重的方法有‘he’,’lecun’,’xavier’
在实际应用中这些方法有非常好的性能而网络偏差通常初始化为0,你可以选择一个最适合你任务的初始化方式。
5. 没有正则化。
正则化典型的就是dropout、加噪声等。即使数据量很大或者你觉得网络不可能出现过拟合,但是对网络进行正则化还是很有必要的。
dropout 通常从设定参数为0.75或0.9开始,根据你认为网络出现过拟合的可能性来调整这个参数。另外,如果你确定这个网络不会出现过拟合,那么可以将参数设定为0.99。正则化不仅仅可以防止过拟合,并且在这个随机过程中,能够加快训练速度以及帮助处理数据中的异常值并防止网络的极端权重配置。对数据扩增也能够实现正则化的效果,最好的避免过拟合的方法就是有大量的训练数据。
6. Batch Size 过大。
Batch size 设置的过大会降低网络的准确度,因为它降低了梯度下降的随机性。另外,在相同情况下batch size 越大那么要达到相同的精确度通常需要训练更多的epoch。
我们可以尝试一些较小的batch size 如 16 ,8 甚至是1。使用较小的batch size 那么一个epoch就可以进行更多次的权值更新。这里有两个好处,第一,可以跳出局部最小点。其二可以表现出更好的泛化性能。
7. 学习率设的不对。
许多深度学习的框架默认开启了gradient clipping ,这个可以处理gradient explosion问题,这个是非常有用的,但是在默认情况下它也很难找到最佳学习率。如果你正确的清理了数据,删除了异常值,以及设定了正确的学习率,那么可以不需要使用gradient clipping,偶尔你也会遇到gradient explosion问题,那么你可以开启gradient clipping。但是,出现这种问题一般情况下表明数据有其它问题,而gradient clipping只是一个临时的解决方案。
8. 最后一层的激活函数用的不对。
在最后一层使用错误的激活函数会导致网络最终不能输出你期望的范围值,
最常见的错误就是最后一层使用Relu函数,其输出无负值。
如果是做回归任务,大多数情况下不需要使用激活函数,除非你知道你所期望的值作为输出。想象一下你的数据值实际代表了什么,以及再归一化之后它们的范围是多少,最有可能的情况是输出没有边界的正数和负数。在这种情况下,最后一层不应该使用激活函数。如果你的输出值只能在某个范围内有意义,如0~1范围内的概率组成。那么最后一层可以使用sigmoid函数。
9. 网络存在坏梯度。
如果你训练了几个epoch误差没有改变,
那可能是你使用了Relu,可以尝试将激活函数换成leaky Relu。因为Relu激活函数对正值的梯度为1,负值的梯度为0。
因此会出现某些网络权值的成本函数的斜率为0,在这种情况下我们说网络是“dead”,因为网络已经不能更新。
如何通过train loss与test loss分析网络当下的状况?
train loss 不断下降,test loss不断下降,说明网络仍在学习;
train loss 不断下降,test loss趋于不变,说明网络过拟合;
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
10. 网络性能低下
只有30%左右的准确率,那么可以怎么办呢?
10.1 训练效果不好
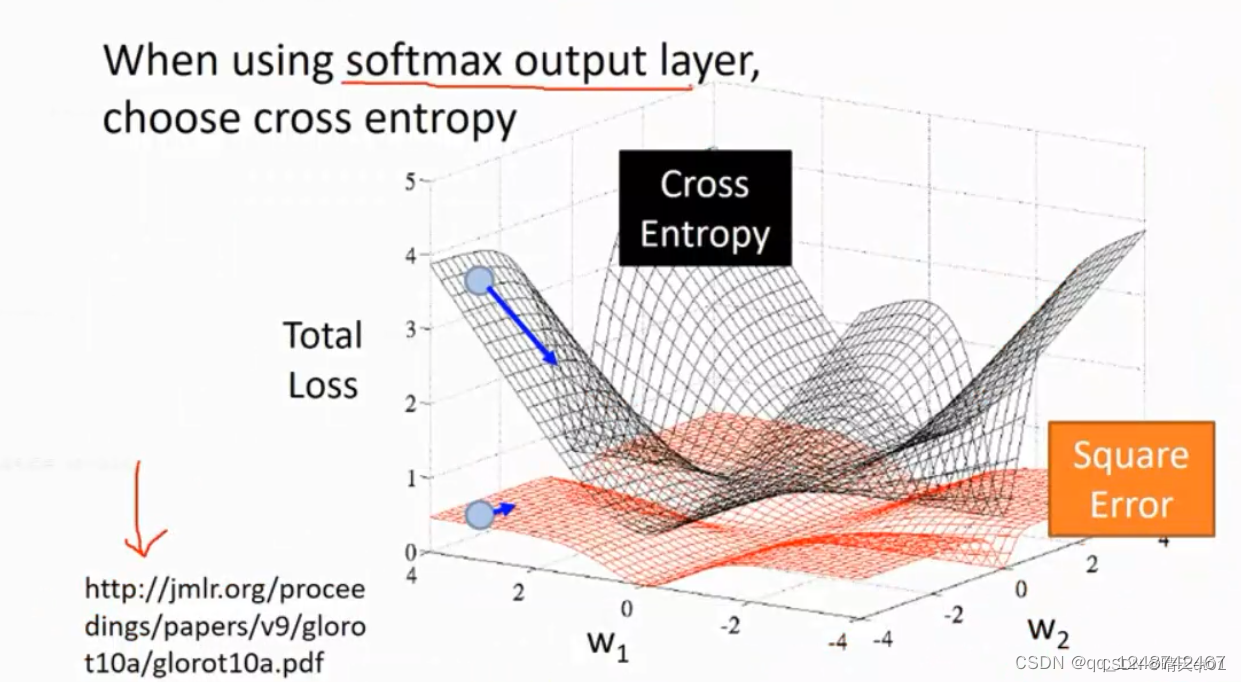
(1)softmax的输出选择交叉熵cross-entroy(见图1)
在softmax layer 的前提条件下,我们发现cross entropy的斜率要比 square error 误差值的斜率要大的多,如果求微分,系统可以马上知道我误差下降的方向是那边。如果我们看图中的蓝色点,如果是square,它的误差是平的,往左往右它是无法判断的。就会导致不调整权重值。或者只是微微调整,那如果没有达到最小的误差值,就会导致效果差了,cross entropy做梯度下降法的时候它的下降速度很快,而且能明确下降的方向
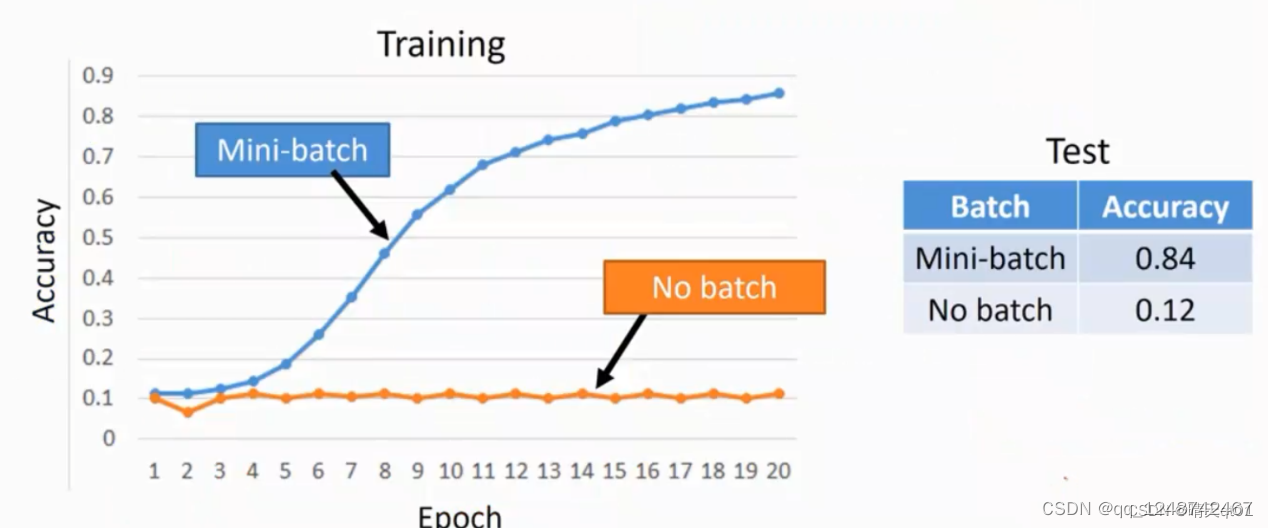
(2)Mini-batch
假设现在有2000个数据,mini-batch设为100 它就会设定为20个批次
如果我们不设置mini-batch的话,没进来一笔数据,我们就要调整一次权重数据,这样会导致跑的时间很久,100万个数据就要调整100万次。会导致最后的结果与你输入资料的顺序有关,先输入的资料先调整,后输入的模型后调整,导致模型的稳定性不高。
Mini-batch就是先输入100笔数据,然后100笔数据一起调整。
这样run的数据比较快,因为是100笔数据一起看,数据前后影响会降低。
比如现在100个数据进来,我们就可以吧这100个数据都求loss值,然后把这些loss值求和,然后一次性去调整我们的参数。然后再放进来100个数据,然后再进行调整我们的参数权重。我们就重复20次,然后再进行重复训练
你可能怀疑这个是不是有效果
用准确率的可视化图看,就可以发现,它的效果很好,模型相对稳定。
当训练数据准确率不高的时候,也可以考虑用批次的问题。
参考5吧,感觉很厉害呢
Refernce
1、Pytorch搭建残差网络
2、扒源码:TensorFlow与Pytorch在一维卷积上的差异
3、 训练不收敛
4、 正则化大于标准化总结
5、学习效果不好


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









