




-
-
TBCNN – 基于树的卷积神经网络
TBCNN: A Tree-Based Convolutional Neural Network for Programming Language Processing
-
一种用于编程语言处理的基于树的卷积神经网络
-
Abstract:
- 由于当前还没有将深度神经网络应用于编程语言处理, 提出TBCNN模型来对基于ASTs的编程语言进行建模, 提取丰富的信息
- 在模型中首先通过基于ASTs的编码准则来预训练获得program vector, 然后通过树型卷积来捕捉树的一些有用特征, 并且引入了三路池化(3-way pooling)和连续二叉树(continous binary tree)来处理不同形状大小的ASTs
- 通过与基准方法对比, 这个方法可以更好更快地完成程序分类任务, 同时预训练出来的program vector也能提高训练的速度
-
Introduction:
- 编程语言和自然语言的区别: 程序包含丰富而明确的结构信息, 编程语言中的源代码往往遵循固定僵化的语法结构, 而且通过复杂的控制流和数据流, 批次之间的代码块之间可能存在依赖关系
-
- 提出“编码准则”学习ast中每个节点的向量表示,作为预训练阶段;
- 提出了基于树的卷积方法提取程序的局部结构特征;
- 引入“连续二叉树”和“三路池化”的概念,使模型适用于不同结构和大小的树;
整体模型
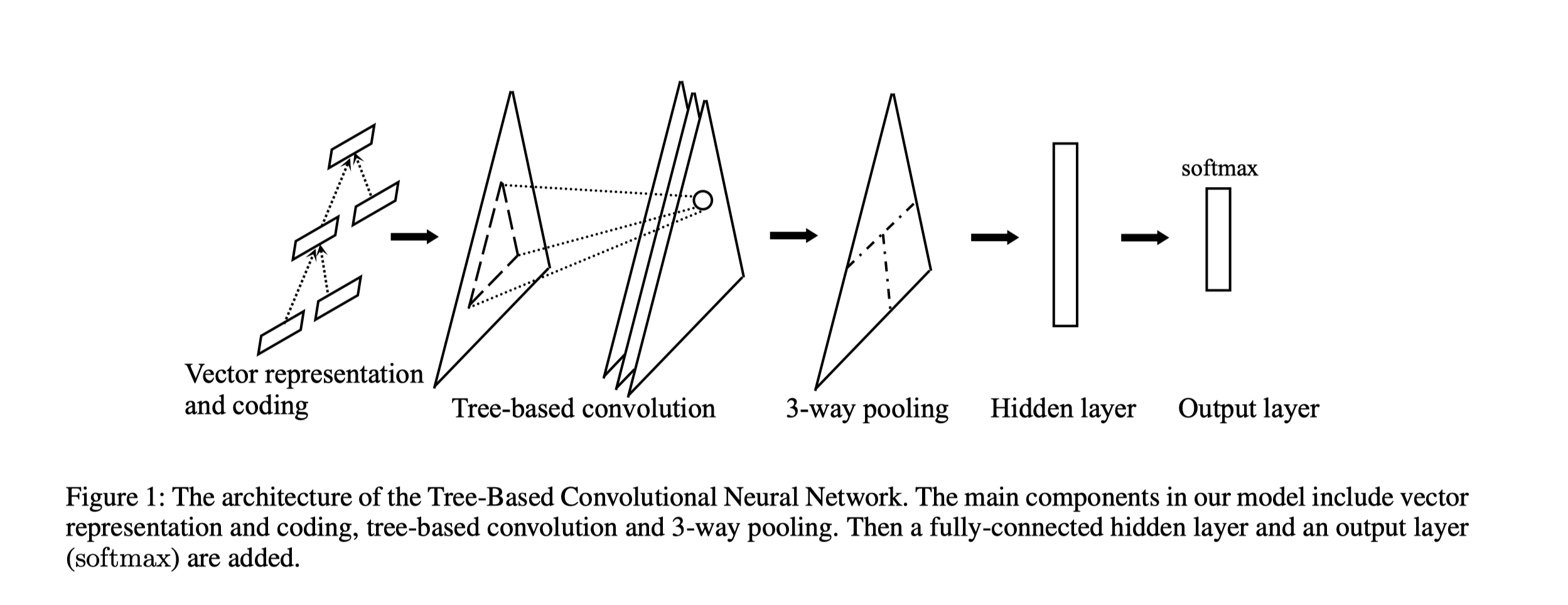
-
Pretraining
-
对于一个节点 p p p 和它的所有孩子 c 1 , c 2 , . . . , c i c_1, c_2,...,c_i c1,c2,...,ci ,用一下式子来表示 p p p 的coded vector
v e c ( p ) ≈ t a n h ( ∑ i l i W c o d e , i v e c ( c i ) + b c o d e ) vec(p)\approx tanh(\sum_il_iW_{code,i}vec(c_i)+b_{code}) vec(p)≈tanh(∑iliWcode,ivec(ci)+bcode)
-
定义 v e c ( p ) vec(p) vec(p) 和 p p p 的 coded vector 的距离的平方
d = ∣ ∣ v e c ( p ) − t a n h ( ∑ i l i W c o d e , i v e c ( c i ) + b c o d e ) ∣ ∣ 2 2 d=\left|\left|vec(p)-tanh(\sum_il_iW_{code,i}vec(c_i)+b_{code}) \right|\right|_2^2 d=∣∣vec(p)−tanh(∑iliWcode,ivec(ci)+bcode)∣∣22
-
同时, 通过将一个随机一个节点( p p p 或者 p p p 的某一个孩子) 换成一个随机的symbol 来完成负采样, 把这个负样本和其coded vector之间的距离计为 d c d_c dc
-
目标: m i n i m i z e W c o d e l , W c o d e r , b c o d e m a x ( d − d c + △ ) minimize_{W^l_{code}, W^r_{code},b_code} max(d-d_c+\triangle) minimizeWcodel,Wcoder,bcodemax(d−dc+△)
-
-
Coding layer
- 对于非叶子结点, p = W c o m b 1 v e c ( p ) + W c o m b 2 t a n h ( ∑ i l i W c o d e , i v e c ( x i ) + b c o d e p =W_{comb1}vec(p)+W_{comb2}tanh(\sum_il_iW_{code,i}vec(x_i)+b_{code} p=Wcomb1vec(p)+Wcomb2tanh(∑iliWcode,ivec(xi)+bcode
-
Tree-based consolution layer
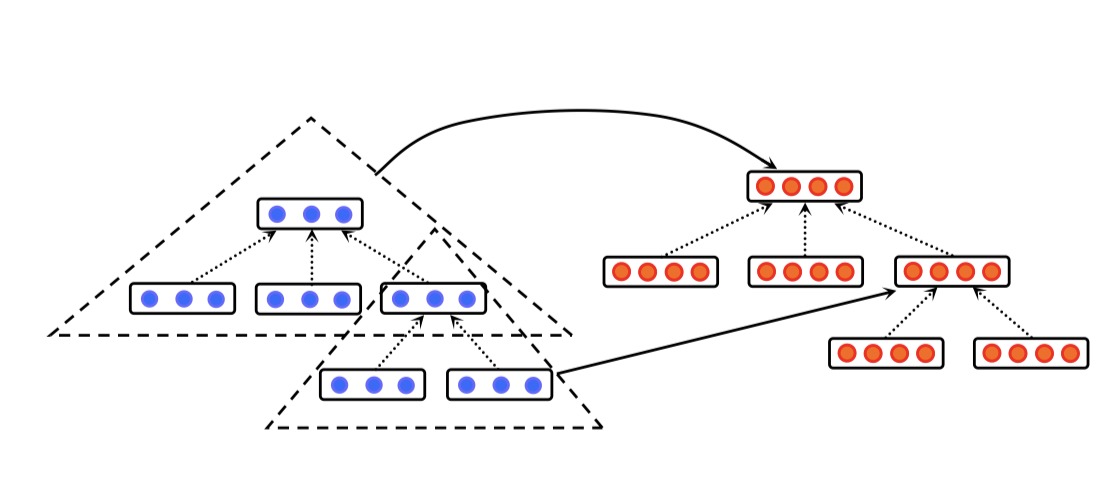
用固定深度的树型卷积核划过整个树结构, 假定对应节点的向量表示是 x 1 , x 2 , . . . x n x_1, x_2, ... x_n x1,x2,...xn, 那么这个卷积层的输出是
y = t a n h ( ∑ n W c o d e , i ∗ x i + b c o d e ) y=tanh(\sum_nW_{code,i}*x_i+b_{code}) y=tanh(∑nWcode,i∗xi+bcode)
而由于孩子节点的数量不固定并且树的形状和大小不固定, 这一步需要同时用zero-paddings和连续二叉树的概念
-
连续二叉树 continuous binary tree
把目标子树看作是一个二叉树(无论原本是什么形状和大小), 使用三个基本的权重矩阵 W c o n v l e f t , W c o n v r i g h t , W c o n v t o p W^{left}_{conv}, W^{right}_{conv}, W^{top}_{conv} Wconvleft,Wconvright,Wconvtop.
对于子树中的某一个节点 x i x_i xi, 其权重矩阵 W c o n v W_{conv} Wconv 是这三个基本权重矩阵的线性组合
-
-
Three-way pooling
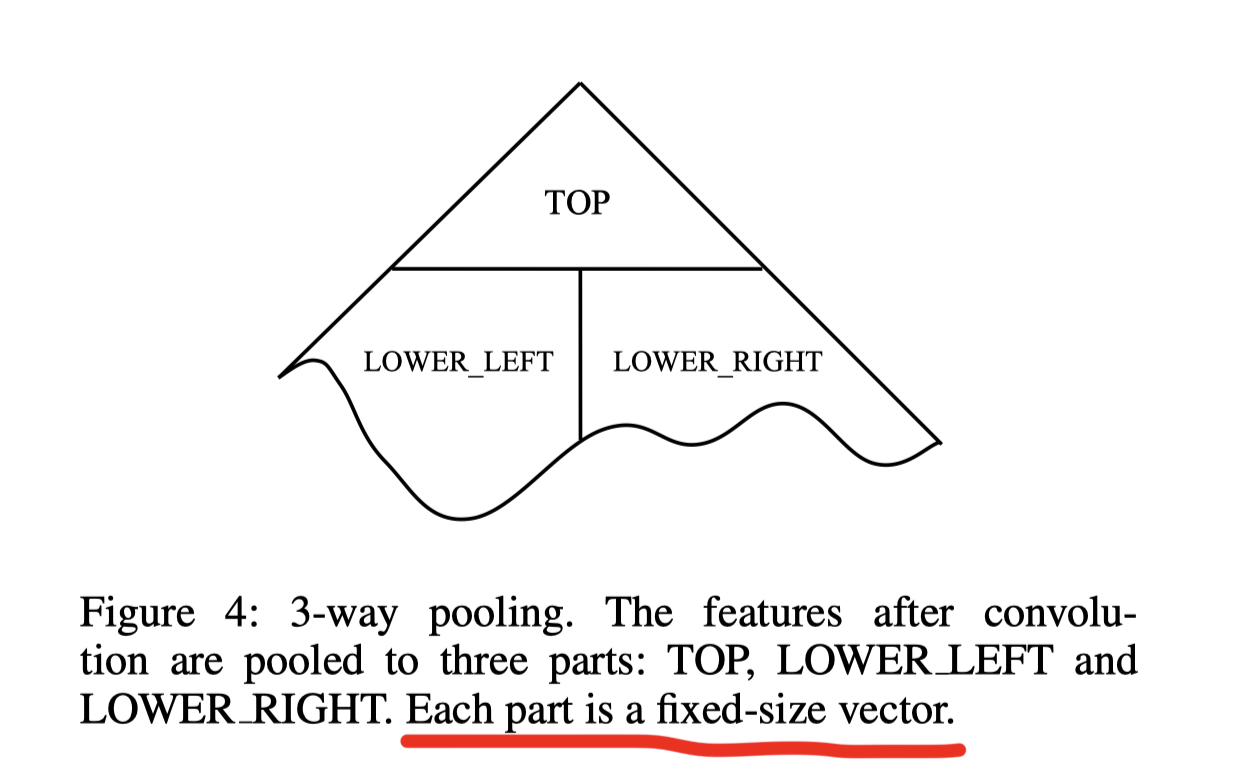
卷积层之后会得到一个形状和大小不变的新树, 因此不能直接接到hidden layer和output layer
用三路池化讲特征池化成三个部分
-
SGDM 优化器算法
- 向后传播算法
-
Hiden layer and output layer — softmax
归一化 s o f t m a x i = e i ∑ j e j softmax_i =\frac{e^i}{\sum_je^j} softmaxi=∑jejei
- 实验和实验结果
- 向量表示成功地捕获了AST节点的有意义特征
- 神经编程语言处理, 对程序进行分类是有效可行的
-
-
TBCNN
最新推荐文章于 2024-08-24 07:23:54 发布

















 2348
2348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









