《大数据应用与实践》练习题
选择题
1.下列关于Spark特性的说法,正确的是( )。
A. Spark 仅支持 Java 语言开发 B. Scala可以自动推测类型
C. Spark 支持延迟计算 D. Spark 不支持内存计算
2.下面关于 Scala 特性说法正确的是( )。
A. Scala 不支持模式匹配 B. Scala 是纯面向对象语言
C. Scala 支持隐式转换 D. Scala 不能与 Java 互操作
3.下列 Scala 方法中,哪个方法可以正确获取列表的前 n 个元素( )。
A. take (n) B. head (n) C. first (n) D. front (n)
4.下列选项中,哪个端口不是 Hadoop 自带的服务端口( )。
A. 50070 B. 8088 C. 9000 D. 4040
5.以下哪个是 HBase 的数据模型特性( )?
A. 行式存储 B. 强事务一致性 C. 列族 D. 二级索引
3.下列哪个组件属于 Flink 的流处理核心( )?
A. JobManager B. Namenode C. ResourceManager D. HMaster
6.Hive 中用于存储元数据的数据库是( )。
A. MySQL B. HBase C. MongoDB D. Cassandra
7.下面哪个是 DataFrame 的特点( )。
A. 不可分区 B. 无结构信息
C. 支持 SQL 查询 D. 不可序列化
8.关于 Spark SQL,下面哪个是错误的( )
A. 支持多种数据源 B. 只能处理结构化数据
C. 提供 DataFrame 和 Dataset API D. 可与 Hive 集成
9.下列选项中,哪个属于行动算子操作( )。
A. map () B. filter ()
C. reduce () D. flatMap ()
10.以下哪个操作会触发 Spark 的宽依赖(Wide Dependency)( )?
A. map() B. filter() C. groupByKey() D. union()
11.YARN 中负责单个节点资源管理的组件是( )。
A. ApplicationMaster B. NodeManager C. ResourceManager D. JobTracker
12.Flink 的时间类型中,基于数据生成时间的是( )。
A. 处理时间(Processing Time) B. 事件时间(Event Time)
C. 摄入时间(Ingestion Time) D. 系统时间(System Time)
13.Spark 应用程序的入口点是( )。
A. SparkContext B. SQLContext
C. HiveContext D. SparkSession
14.下面哪个不是 Spark SQL 支持的数据源( )。
A. Parquet B. JSON
C. CSV D. NoSQL 数据库
15.Spark 的内存管理模型中,Storage 内存主要用于( )。
A. 存储 RDD 缓存数据 B. 执行 Shuffle 操作
C. 存储任务执行时的临时数据 D. 存储广播变量
16.下列关于 HDFS 副本机制的说法,错误的是( )。
A. 默认副本数为 3 B. 副本分布在不同机架(Rack)
C. 副本由 DataNode 自动管理 D. 副本数不可自定义
17. Spark SQL 中用于处理结构化数据的核心抽象是( )。
A. RDD B. DataFrame C. DStream D. Dataset[Row]
18.以下哪个工具用于 Hadoop 集群的配置管理( )?
A. ZooKeeper B. Oozie C. Ambari D. Hive
19.下面关于Scala特性说法错误的是( )。
A. Java和Scala不可以混编 B. Scala可以自动推测类型
C. Scala有模式匹配 D. Scala是以面向函数编程
20.下列Scala方法中,哪个方法可以正确计算数组arr的长度( )。
A. Count B. take C. tail D. length
21.下列选项中,哪个不是Spark生态系统中的组件( )。
A. Spark Streaming B. Mllib C. Graphx D. Spark R
22.下列选项中,哪个端口不是Spark自带的服务端口( )。
A. 8080 B. 4040 C. 8090 D. 18080
23.Spark是Hadoop生态下哪个组件的替代方案( )
A. Hadoop B.Yarn C.Hdfs D.MapReduce
24.下列选项中,哪个不属于转换算子操作( )。
A. filter() B. map() C. collect() D. reduceByKey()
25.下列选项中,能使RDD产生宽依赖的是( )。
A. groupByKey() B. filter() C. flatMap() D. map()
26.Rdd持久化机制中,默认的存储级别是( )。
A. MEMORY_ONLY B. MEMORY_ONLY_SER
C. MEMORY_AND_DISK D. MEMORY_AND_DISK_SER
27.下面哪个不是Spark的部署方式( )。
A. Spark on YARN B. Spark on Mesos
C. Spark on Hadoop D. Standalone
28. Spark的阶段划分的依据是产生( )。
A.宽依赖 B.窄依赖
C.Task D.Application
填空题
1.Spark 的两种共享变量是广播变量和______________。
2.RDD 的转换操作具有______________特性,即它们不会立即执行。
3.Spark 生态系统包含 Spark Core、Spark SQL、________、MLlib、GraphX
以及独立调度组件。
4.Spark 提交作业时,使用本地模式并分配 4 个 CPU 核心的master参数值
是________。
5.Spark 提交作业时,连接到 YARN 集群的master参数值是________。
6.Hadoop 集群中负责资源调度的组件是________。
7.Spark 的调度模式分为 FIFO 和______________。
8.Spark Streaming 的______________机制用于保证数据处理的精确一次语义。
9.Spark RDD 的缓存级别默认是________。
10.Spark SQL 中,______________是 Spark 2.0 引入的统一入口点。
11.Spark Streaming中对DStream的转换操作会转变成对 的 转换操作。
判断题
1.Spark 的 DStream 是基于 RDD 的流式计算抽象。( )
2.Spark 的累加器(Accumulator)支持跨任务修改。( )
3.HDFS 不适合存储大量小文件。( )
4.Hadoop的MapReduce作业中,通过磁盘进行数据Shuffle。( )
5.Spark 的 RDD 是不可变的分布式数据集( )
6.Spark Streaming 是批处理框架,不支持实时处理( )
7.DataFrame 是带有 schema 信息的 RDD( )
8.Spark 的 shuffle 操作一定会导致数据的磁盘落盘( )
9.HBase 的行键(Row Key)可不按字典序排序。( )
10.Hive 的分区表可以提高查询效率。( )
11.YARN 的 ResourceManager 负责全局资源调度。( )
12.Spark 的广播变量可以在每个 Executor 上缓存一份( )
13.Spark SQL 的 DataFrame API 只支持 SQL 查询,不支持函数式操作( )
14.Spark 的 checkpoint 操作会将 RDD 保存到 HDFS 等可靠存储中( )
15.Spark SQL 不支持直接操作 Hive 表。( )
16.HBase 的列族在表创建后不可修改。( )
17.Spark 任务的 Executor 可以运行多个 Task。( )
18.Spark 的 Executor 是运行在 Worker 节点上的进程( )
19.Spark 的 DStream 转换操作是懒执行的( )
20.Spark 的内存管理模型中,Execution 内存和 Storage 内存可以动态调整( )
简述题
1.简述Spark中RDD的容错机制(Lineage)的工作原理。
2.对比Spark中reduceByKey和groupByKey的性能差异,并说明原因。
3.简述 Spark 的宽窄依赖及其对调度的影响。
4.比较 Spark 的 DataFrame 和 Dataset 的异同。
5.简述Kafka生产者(Producer)和消费者(Consumer)的主要功能及关键特性?
6.简述 Spark 的 Shuffle 过程及其优化策略。
7.SparkSQL中DataFrame和Dataset的主要区别是什么?各适用于什么场景?
8.简述HDFS中NameNode和DataNode的分工协作机制。
9.列举Spark的三种主要部署模式,并说明每种模式的适用场景。
10.如何理解 Spark 的弹性分布式数据集(RDD)?
11.简述 Spark 的资源调度流程。
12.解释 Spark 的容错机制。
13.Spark和Hadoop有什么区别?
程序题
编写函数输出1~100之间所有素数。
使用 Scala 语言按以下要求,编写出程序。
(1) 创建一个名字为 Person 的类,包含私有属性 name(String)和 age(Int)
(2) 提供构造方法初始化这两个属性
(3) 定义一个方法 sayHello,输出 "Hello, my name is [name], I'm [age] years old."
(4) 创建一个 Object 包含 main 方法,实例化 Person 类并调用 sayHello 方法
给定RDD Array(1, 2, 3, 4, 5),使用map和reduce算子计算所有元素的立方和。
创建一个包含元素 "spark", "hadoop", "flume", "date" 的 RDD,过滤出长度大于 5 的元素。
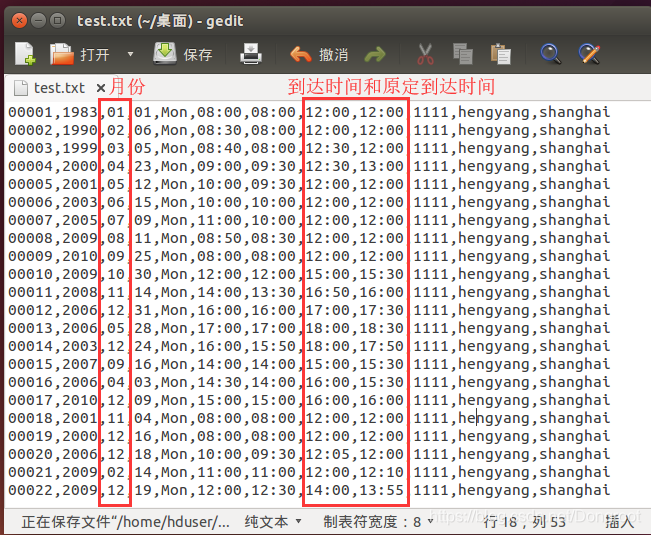
统计文本date.txt中每个单词出现的频率,并输出频率最高的前 3 个单词。
创建一个 RDD 数据为 Array (3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5),计算所有元素的平方和。
现有一份用户访问日志数据 datas/access.log,格式为 "user_id|timestamp|url",要求读取文件创建 RDD,统计每个用户的访问次数。(5 分)
示例数据:
u001|2023-01-01 10:00:00|/home
u002|2023-01-01 10:01:00|/profile
u001|2023-01-01 10:02:00|/cart
答案:
val logRDD = sc.textFile("datas/access.log")【1分】
val userCounts = logRDD
.map(line => line.split("\\|")(0)) // 提取 user_id【1分】
.map(userId => (userId, 1)) // 映射为 (user_id, 1)【1分】
.reduceByKey(_ + _) // 聚合计数【1分】
userCounts.collect().foreach(println)【1分】
现有sales.txt 文件,记录了某商店的销售数据,请使用 Spark 编写程序计算每个类别的总销售额。数据格式为 "product_id,category,price,quantity",(10 分)
示例数据:
P001,electronics,5000,2
P002,clothing,200,5
P003,electronics,3000,1
8.1 //创建 SparkSession
8.2 //读取文件创建 DataFrame
8.3 //计算每个类别的总销售额
8.4 //显示结果
8.5 //关闭 SparkSession
/import org.apache.spark.sql.SparkSession
// 5.1 创建 SparkSession
val spark = SparkSession.builder()
.appName("CategorySales")
.master("local[*]")
.getOrCreate()
// 5.2 读取文件创建 DataFrame
val df = spark.read
.option("header", "false")
.option("delimiter", ",")
.csv("sales.txt")
.toDF("product_id", "category", "price", "quantity")
// 5.3 计算每个类别的总销售额
import spark.implicits._
val resultDF = df
.select($"category", ($"price" * $"quantity").as("total"))
.groupBy("category")
.sum("total")
.withColumnRenamed("sum(total)", "total_sales")
// 5.4 显示结果
resultDF.show()
// 5.5 关闭 SparkSession
spark.stop()
现在有一份服务器日志数据datas/apache.log,要求读取文件创建RDD获取时间是2022年5月17日的请求数据(8分)
部分数据如下:
83.149.9.216--16/05/2022:10:05:03+0000GET /presentations/logstash-monitorama-2013/images/kibana-search.png
83.149.9.216--17/05/2022:10:05:43+0000ET /presentations/logstash-monitorama-2013/images/kibana-dashboard3.png
83.149.9.216--18/05/2022:10:05:47+0000GET /presentations/logstash-monitorama-2013/plugin/highlight/highlight.js
// 创建 SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("test")
val sc = new SparkContext(conf)
// 读取日志文件
val logRDD = sc.textFile("datas/apache.log")
// 筛选日期为 17/05/2022 的记录
val filteredRDD = logRDD.filter { line =>
val datePattern = """\s17/05/2022:""".r // 匹配日期模式
datePattern.findFirstIn(line).isDefined
}
// 输出筛选结果
filteredRDD.foreach(println)
// 关闭 SparkContext
sc.stop()
现有Kafka 的主题test-topic,持续发送英文句子(每行一个句子)。使用 Spark Streaming 实时统计每个单词的出现次数,每5秒输出一次结果。请写出核心代码。(8分)
// 创建 SparkConf 和 StreamingContext
val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5)) // 批处理间隔5秒
// 创建 DStream
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("test-topic"), kafkaParams)
)
// 核心处理逻辑
val lines = stream.map(_.value())
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(w => (w, 1)).reduceByKey(_ + _)
// 输出结果
wordCounts.print()
// 启动流计算
ssc.start()
ssc.awaitTermination()
有50W个京东店铺,每个顾客访客访问任何一个店铺的任何一个商品时都会产生一条访问日志,访问日志存储的表名为Visit,访客的用户id为user_id,被访问的店铺名称shop,数据如下:(10分)
user_id
shop
u1
a
u2
b
u1
b
u1
a
u3
c
u4
b
请使用spark sql语句统计:
6.1每个店铺的UV(访客数)(4分)
6.2每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数(6分)
6.1// 创建DataFrame
val visitDF = data.toDF("user_id", "shop")
// 注册为临时表
visitDF.createOrReplaceTempView("Visit")
val uvResult = spark.sql(
"""SELECT
shop,
COUNT(DISTINCT user_id) AS uv
FROM Visit
GROUP BY shop
ORDER BY uv DESC"""
)
6.2val top3Result = spark.sql(
"""WITH ranked_visits AS (
SELECT
shop,
user_id,
COUNT(*) AS visit_count,
ROW_NUMBER() OVER (
PARTITION BY shop
ORDER BY COUNT(*) DESC
) AS rank
FROM Visit
GROUP BY shop, user_id
)
SELECT
shop,
user_id,
visit_count
FROM ranked_visits
WHERE rank <= 3
ORDER BY shop, rank"""
)
现有某电商平台的用户评分数据 ratings.csv,格式为 "user_id,movie_id,rating,timestamp",请使用 Spark SQL 查询出评分最高的前 10 部电影(需考虑评分人数不少于 10 人)。(15 分)
示例数据:
1,101,5,1612345678
2,101,4,1612345679
3,102,3,1612345680
...
请给出关键 SQL 查询语句。
import org.apache.spark.sql.SparkSession
object MovieRatingAnalysis {
def main(args: Array[String]): Unit = {
// 创建 SparkSession
val spark = SparkSession.builder()
.appName("TopMoviesByRating")
.master("local[*]")
.getOrCreate()
// 读取数据
val ratingsDF = spark.read
.option("header", "false")
.option("inferSchema", "true")
.csv("ratings.csv")
.toDF("user_id", "movie_id", "rating", "timestamp")
// 注册临时视图
ratingsDF.createOrReplaceTempView("ratings")
// 执行 SQL 查询
val topMoviesDF = spark.sql(
"""
SELECT
movie_id,
AVG(rating) AS avg_rating,
COUNT(*) AS num_ratings
FROM ratings
回答问题






 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 25
25





 到【灌水乐园】发言
到【灌水乐园】发言







