







一致性哈希算法在分布式系统中应用较多。
1.一般的哈希算法存在的问题
普通的哈希算法会存在一个严重的问题就是,新增节点或者删除节点的时候,原来的key的哈希值会发生变化,k-v要重新在现有的节点之间进行分配,重新分配的过程是会消耗系统的性能的,并且再进行键值重新分配的过程节点的缓存是失效的。
例如,一开始系统中含有3个节点,则每次在对key进行哈希运算后,都是对3进行取余最后得到key所落在的节点。但是当新增一个节点后,每次查询某个key的时候,要计算其哈希然后对4进行取余。显然会导致之前的缓存失效。原因是因为取余的的值变了,原来的会导致缓存失效。要想缓存不失效就得重新分配原来三个服务器中的k-v,对原来的三个服务器的k-v进行哈希计算然后对4取余,这必然会造成大量的性能损耗,数据量越大需要要重新分配的k-v越多,损耗的性能也就越大
2.一致性哈希
一致性哈希算法的目的是在服务器节点数量n变化的时候只需要重定位一小部分的数据,只会在很短的时间内一小部分缓存失效,可以很快的恢复。
一致性哈希将key映射到2^32 空间中,组成一个圆环,圆环的值为 0-2^32-1。
- 一致性哈希算法将整个哈希值空间按顺时针方向组织成一个虚拟的圆环,圆环的值为0-2^32-1
- 接着将各个服务器节点使用hash函数进行哈希,可以选择使用服务器的名称或者Ip地址进行哈希,从而确定每台服务器在哈希环上的位置
- 最后使用算法定位数据访问到相应的服务器,将数据的key进行取哈希,算出key落在圆环的位置,然后沿着顺时针方向寻找,找到的第一个服务器就是该键值要去的服务器。
如下图中key1和key2最后落在服务器A,key3落在服务器B,key4落在服务器C中。
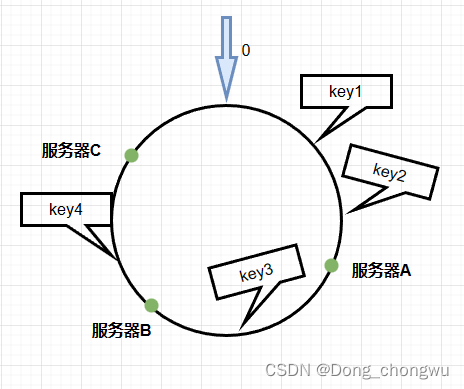
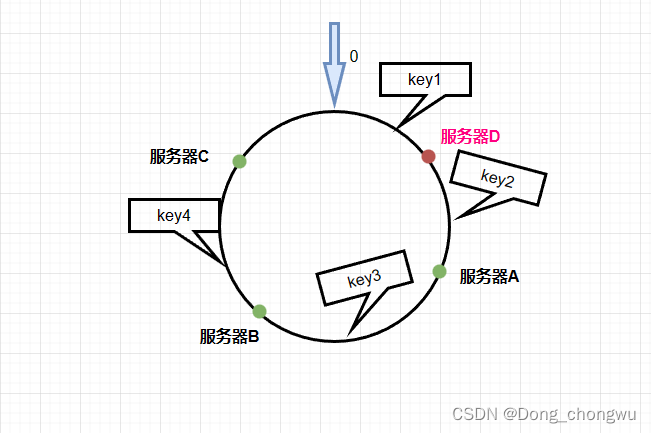
当发生新增节点的时候(删除节点也类似分析)
新增节点D后,将服务器A的数据划分成了两部分,这时只需要重新分配服务器A的一部分k-v,缓存失效的时间短,可以迅速恢复,其余服务器中的数据不用进行重新分配。
3.一致性哈希优点、存在的问题及解决办法
优点:
一致性哈希算法,在新增节点或者删除节点的时候只需要重定位一小部分数据,只有部分的缓存会失效,可以很快的恢复。
存在问题:
当集群中的节点数量较少时,可能会出现节点在哈希空间中分布不平衡的问题,造成hash环倾斜现象,大量的key落在了一个台服务器上。
如下图所示,服务器A所存的数据远高于B和C,主要的原因是因为系统只有三个服务器,三个服务器之间的距离较近,会导致数据在节点中分布不均匀
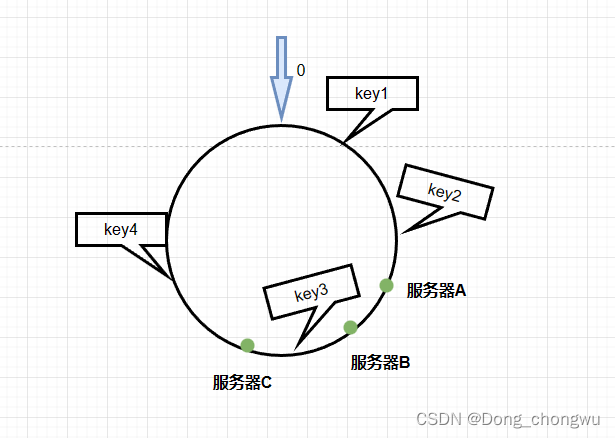
解决办法:
在哈希环中引入虚拟节点,让集群中的节点尽可能多,从而让各个节点均匀的分布在哈希空间中,让虚拟节点映射到实际的服务器节点中,解决hash倾斜问题。
4.Go语言实现一致性哈希算法
1.先设置一致性哈希的数据结构
// 定义哈希函数
type HashFunc func(data []byte) uint32
// 存储服务器节点,可以通过哈希值取到对应的服务器
type Map struct {
hashFunc HashFunc
replicas int
keys []int // sorted
hashMap map[int]string
}
// New creates a new Map
func New(replicas int, fn HashFunc) *Map {
m := &Map{
replicas: replicas, // 每个物理节点会产生 replicas 个虚拟节点
hashFunc: fn,
hashMap: make(map[int]string), // 虚拟节点 hash 值到物理节点地址的映射
}
if m.hashFunc == nil {
m.hashFunc = crc32.ChecksumIEEE
}
return m
}
2.加入服务器节点
// AddNode add the given nodes into consistent hash circle
func (m *Map) AddNode(keys ...string) {
for _, key := range keys {
if key == "" {
continue
}
for i := 0; i < m.replicas; i++ {
// 使用 i + key 作为一个虚拟节点,计算虚拟节点的 hash 值
hash := int(m.hashFunc([]byte(strconv.Itoa(i) + key)))
// 将虚拟节点添加到环上
m.keys = append(m.keys, hash)
// 注册虚拟节点到物理节点的映射
m.hashMap[hash] = key
}
}
sort.Ints(m.keys)
}
3.获取key对应的服务器节点
// PickNode gets the closest item in the hash to the provided key.
func (m *Map) PickNode(key string) string {
if m.IsEmpty() {
return ""
}
// 支持根据 key 的 hashtag 来确定分布
partitionKey := getPartitionKey(key)
hash := int(m.hashFunc([]byte(partitionKey)))
// Binary search for appropriate replica.
idx := sort.Search(len(m.keys), func(i int) bool { return m.keys[i] >= hash })
// 若 key 的 hash 值大于最后一个虚拟节点的 hash 值,则 sort.Search 找不到目标
// 这种情况下选择第一个虚拟节点
if idx == len(m.keys) {
idx = 0
}
return m.hashMap[m.keys[idx]]
}
5.Redis采用的分布式集群策略
redis的集群模式不是使用一致性哈希算法,而是使用的是固定的哈希槽,一共有16384个哈希槽,每个节点负责一定的哈希槽,可以进行平均分配也可以进行手动分配。所有节点负责的哈希槽加起来必须等于16384个,不能存在空余的槽。
根据key值,按照CRC16算法计算一个哈希值,再用这个哈希值对16384进行取模,可以得到0-16383范围内的数,每一个数对应一个哈希槽,可以通过哈希槽找到相应的节点。

















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









