




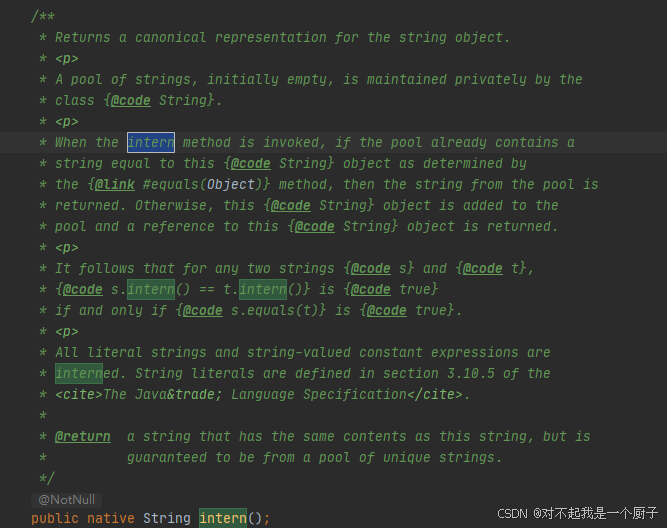
试想如果当堆内缓存中存在大量重复的String字符串时(有限个),我们首先想到的是能不能把String缓存到一个Map中,当map中存在时就使用Map中的String,Map中不存在时就new一个String放进去,这正是String.intern()所实现的功能
当然如果你使用的是Long,Interger类型的主播id,可以自己实现String.intern()的功能,因为主播id是稀疏的而不是稠密的,所以无法利用Long,Interger类型自身的cache
以直播场景为例,在直播推荐系统中,主播id是主播的唯一标识,最初是一个32位整型,在公司大多数其它Java业务场景中都是使用Interger来表示,后来由于主播id分配完了,又统一升级到到64位整型,但在推荐业务场景中我们一直都是使用String来表示,美其名曰灵活,你变由你变,你怎么变我都不用变
在推荐服务内部会缓存很多i2i的相似词表,结构为Map<String,List<String>>,key为主播id,value的List中存放的是与key相似的主播id列表(用途就是比如你看过主播a,就会把与主播a相似的其它主播推荐给你),虽然只有3万量级的主播,但这样一个Map,往往会有1000多万个主播id,其中绝大部分是重复的主播id
比如:
aid1->aid2,aid3,aid4,aid5
aid2->aid4,aid5,aid6,aid10
aid3->aid1,aid2,aid9,aid10
当然这个结构是简化过的,一般每个aid还会有个Float类型的分数,用与在线召回时排序截断
如果我们有多个这种i2i相似词表,那么缓存中将会存在大几千万重复主播id,此时如果我们用String.intern()来优化,最终缓存中的主播id,将会由千万级下降到万级,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1951
1951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









