



基于上一篇文章文献阅读:LEARNING FAST AND SLOW FORONLINE TIME SERIES FORECASTING-优快云博客过后,这里去根据论文中的代码仓库进行了一个实验。尊重原创代码:GitHub - DMIRLAB-Group/LSTD
问题
这里发现给的配置文件不是很全面,基于全部的深度学习环境安装过后,我的实验环境是RTX 5060ti 16g。基于论文中的计算KL散度会爆显存,该放到学校的算力资源上a800 80g显存的情况下依然会爆显存。这里只能多用一张a800,或者调低batchsize到原来的一半。
依赖文件
numpy == 1.23.5
pandas == 1.5.3
einops==0.4.0
tqdm==4.64.1
wandb
numexpr
scikit-learn
参考
d={
'Traffic':{
1: ' --method LSTD --root_path ./data/ --data Traffic --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 1 '
' --depth 10 --hidden_dim 512 --hidden_layers 1 --tau 0.7 --batch_size 16 --learning_rate 0.003 --mode time',
24: ' --method LSTD --root_path ./data/ --data Traffic --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0 '
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 24 '
' --depth 9 --hidden_dim 512 --hidden_layers 2 --tau 0.75 --batch_size 8 --learning_rate 0.003 --mode time',
48: ' --method LSTD --root_path ./data/ --data Traffic --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0 '
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 48 '
' --depth 10 --hidden_dim 512 --hidden_layers 2 --tau 0.7 --batch_size 4 --learning_rate 0.003 --mode time'
},
'Exchange':{
1: ' --method LSTD --root_path ./data/ --data Exchange --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 1 '
' --depth 10 --hidden_dim 448 --hidden_layers 1 --tau 0.7 --batch_size 4 --learning_rate 0.003 --mode time',
24: ' --method LSTD --root_path ./data/ --data Exchange --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 24 '
' --depth 10 --hidden_dim 512 --hidden_layers 1 --tau 0.75 --batch_size 8 --learning_rate 0.003 --mode time',
48: ' --method LSTD --root_path ./data/ --data Exchange --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.0001 --zc_kl_weight 0.0001 --pred_len 48 '
' --depth 9 --hidden_dim 448 --hidden_layers 1 --tau 0.75 --batch_size 8 --learning_rate 0.003 --mode time'
},
'WTH': {
1: ' --method LSTD --root_path ./data/ --data WTH --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 1 '
' --depth 9 --hidden_dim 512 --hidden_layers 1 --tau 0.75 --batch_size 8 --learning_rate 0.003 --mode time',
24: ' --method LSTD --root_path ./data/ --data WTH --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 24 '
' --depth 9 --hidden_dim 256 --hidden_layers 1 --tau 0.7 --batch_size 4 --learning_rate 0.002 --mode var',
48: '--method LSTD --root_path ./data/ --data WTH --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
'--des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
'--L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 48 '
' --depth 9 --hidden_dim 256 --hidden_layers 1 --tau 0.7 --batch_size 4 --learning_rate 0.001 --mode var'
},
'ECL': {
1: ' --method LSTD --root_path ./data/ --data ECL --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 1 '
' --depth 9 --hidden_dim 512 --hidden_layers 1 --tau 0.75 --batch_size 16 --learning_rate 0.002 --mode time',
24: ' --method LSTD --root_path ./data/ --data ECL --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 24 '
' --depth 9 --hidden_dim 512 --hidden_layers 1 --tau 0.75 --batch_size 8 --learning_rate 0.002 --mode var',
48: ' --method LSTD --root_path ./data/ --data ECL --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 48 '
' --depth 9 --hidden_dim 512 --hidden_layers 1 --tau 0.75 --batch_size 8 --learning_rate 0.002 --mode var'
},
'ETTh2': {
1: ' --method LSTD --root_path ./data/ --data ETTh2 --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 1 '
' --depth 9 --hidden_dim 512 --hidden_layers 1 --tau 0.75 --batch_size 4 --learning_rate 0.003 --mode time',
24: ' --method LSTD --root_path ./data/ --data ETTh2 --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 24 '
' --depth 9 --hidden_dim 512 --hidden_layers 1 --tau 0.75 --batch_size 4 --learning_rate 0.003 --mode var',
48: ' --method LSTD --root_path ./data/ --data ETTh2 --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 48 '
' --depth 9 --hidden_dim 256 --hidden_layers 2 --tau 0.7 --batch_size 32 --learning_rate 0.003 --mode var'
},
'ETTm1': {
1: ' --method LSTD --root_path ./data/ --data ETTm1 --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 1 '
' --depth 9 --hidden_dim 512 --hidden_layers 1 --tau 0.75 --batch_size 8 --learning_rate 0.003 --mode time',
24: ' --method LSTD --root_path ./data/ --data ETTm1 --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 24 '
' --depth 9 --hidden_dim 256 --hidden_layers 1 --tau 0.7 --batch_size 4 --learning_rate 0.003 --mode var',
48: ' --method LSTD --root_path ./data/ --data ETTm1 --n_inner 1 --test_bsz 1 --features M --seq_len 60 --label_len 0 '
' --des "Exp" --itr 1 --train_epochs 6 --online_learning "full" --L1_weight 0.001 --dropout 0'
' --L2_weight 0.001 --zd_kl_weight 0.001 --zc_kl_weight 0.001 --pred_len 48 '
' --depth 9 --hidden_dim 256 --hidden_layers 1 --tau 0.7 --batch_size 4 --learning_rate 0.002 --mode var'
},
}提示
如果你的显卡是50系列,cuda版本必须上12.8,python版本必须3.10以上才能行
数据文件放置位置应如图
运行命令
#!/bin/bash
# 1. 定义你要跑的所有数据集名称 (必须和字典里的 Key 完全一致)
# 如果只想跑其中几个,可以在这里删减
datasets=("Exchange" "WTH" "ECL" "ETTh2" "ETTm1")
# 2. 定义你要跑的长度
lengths=(1 24 48)
# 3. 定义种子
seed=42
# ================= 核心循环逻辑 =================
for data in "${datasets[@]}"; do
for len in "${lengths[@]}"; do
echo "----------------------------------------------------------------"
echo "正在启动任务: Dataset = $data | Length = $len | Seed = $seed"
echo "当前时间: $(date)"
echo "----------------------------------------------------------------"
# 执行 Python 命令
python run_LSTD.py -seed $seed -dataset $data -len $len
# 检查是否报错 (如果报错,打印提示,但继续跑下一个)
if [ $? -ne 0 ]; then
echo ">>> 警告: $data ($len) 运行失败或被中断!"
else
echo ">>> 成功: $data ($len) 运行完毕。"
fi
echo ""
done
done
echo "所有任务执行结束!"
这里的sh脚本执行直接在linux上起一个名字如 vim run_all.sh
bash 你的脚本.sh就行
实验效果
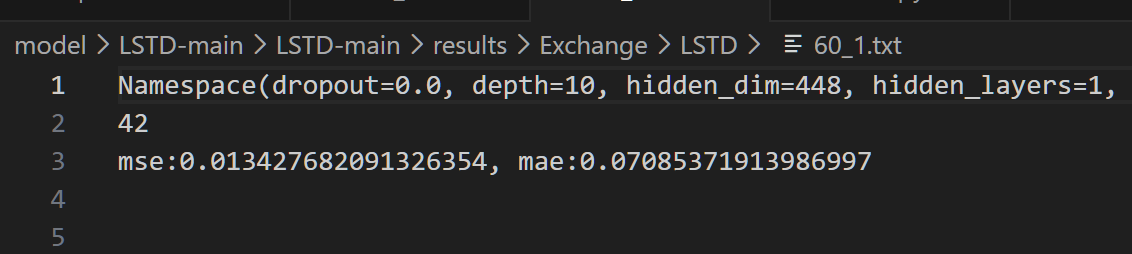
在ECL数据集上
Namespace(dropout=0.0, depth=9, hidden_dim=512, hidden_layers=1, batch_size=4, learning_rate=0.002, tau=0.75, zd_kl_weight=0.001, zc_kl_weight=0.001, L1_weight=0.001, L2_weight=0.001, rec_weight=0.5, mode='var', n_class=4, No_prior=True, is_bn=False, dynamic_dim=128, lags=1, data='ECL', root_path='./data/', data_path='ECL.csv', features='M', target='OT', freq='h', checkpoints='./checkpoints/', seq_len=60, label_len=0, pred_len=24, enc_in=321, dec_in=321, c_out=321, d_model=32, n_heads=8, e_layers=2, d_layers=1, s_layers=[3, 2, 1], d_ff=128, factor=5, padding=0, distil=True, attn='prob', embed='timeF', activation='gelu', output_attention=False, do_predict=False, mix=True, cols=None, num_workers=0, itr=1, train_epochs=6, patience=3, learning_rate_w=0.001, learning_rate_bias=0.001, weight_decay=0.001, des='Exp', loss='mse', lradj='type1', use_amp=False, inverse=False, method='LSTD', fc_dropout=0.05, head_dropout=0.0, patch_len=16, stride=8, padding_patch='end', revin=0, affine=0, subtract_last=0, decomposition=0, kernel_size=25, tcn_output_dim=320, tcn_layer=2, tcn_hidden=160, individual=1, teacher_forcing=False, online_learning='full', opt='adam', test_bsz=1, n_inner=1, channel_cross=False, use_gpu=True, gpu=0, use_multi_gpu=False, devices='0,1,2,3', finetune=False, finetune_model_seed=42, aug=0, lr_test=0.001, version='Wavelets', mode_select='random', modes=64, L=3, base='legendre', cross_activation='tanh', moving_avg=[24], gamma=0.1, m=24, loss_aug=0.5, use_adbfgs=True, period_len=12, mlp_depth=3, mlp_width=256, station_lr=0.0001, sleep_interval=1, sleep_epochs=1, sleep_kl_pre=0, delay_fb=False, online_adjust=0.5, offline_adjust=0.5, online_adjust_var=0.5, var_weight=0.0, alpha_w=0.0001, alpha_d=0.003, test_lr=0.1, seed=42, detail_freq='h')
42
mse:1.7189000650215682, mae:0.2748529085257549
mse误差比论文中的最好效果高了0.3。
往往轻量级别的时间序列数据集,显存16G就吃得消了,且精度达不到文章中的最好效果
确实能跑但是效果确实达不到论文中的水平

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









