







【Ceph学习笔记】简介,集群部署与集群扩容
分布式存储
集中式存储
所谓集中式系统就是指由一台或多台主计算机组成中心节点,数据集中存储于这个中心节点中,并且整个系统的所有业务单元都集中
部署在这个中心节点上,系统所有的功能均由其集中处理。也就是说,集中式系统中,每个终端或客户端仅仅负责 数据的录入和
输出,而数据的存储与控制处理完全交由主机来完成。
集中式系统最大的特点就是部署结构简单,由于集中式系统往往基于底层性能卓越的大型主机,因此无需考虑如何对服务进行多个节
点的部署,也就不用考虑多个节点之间的分布式协作问题。
分布式存储
分布式系统如何定义?这里引用一下Distributed Systems Concepts and Design(Third Edition)中的一句话:“A distributed system is one in which components located at networked computers communicate and coordinate their actions only by passing messages”。从这句话里面
我们可以看到几个重点:
- 组件分布在网络计算机上
- 组件之间仅仅通过消息传递来通信并协调行动
严格讲,同一个分布式系统中的计算机在空间部署上是可以随意分布的,这些计算机可能被放在不同的机柜上,也可能在不同的机房中
甚至分布在不同的城市。无论如何,一个标准的分布式系统在没有任何特定业务逻辑约束的情况下,都会有以下几个特征:
1)、分布性
分布式系统中的多台计算机都会在空间上随意分布,同时,及其的分布情况也会随时变动
2)、对等性
分布式系统中的计算机没有主/从之分,既没有控制整个系统的主机,也没有被控制的从机,组成分布式系统的所有节点都是对等的。副
本(Replica)是分布式系统最常见的概念之一,指的是分布式系统对数据和服务提供的一种冗余方式。在 常见的分布式系统中,为了对
外提高可用的服务,我们往往会对数据和服务进行副本处理。数据副本是指在不同的节点上持久化同一份数据,当某一个节点上存储的
数据丢失时,可以从副本上读取到该数据,这是解决分布式系统数据丢失问题最为有效的手段。另一类副本是服务副本,指多个节点提
供同样的服务,每个节点都有 能力接收来自外部的请求并进行相应的处理
3)、并发性
在一个计算机网络中,程序运行过程中的并发性操作是非常常见的行为,例如同一个分布式系统的多个节点,可能会并发地操作一些共享
的资源,诸如数据库或分布式存储等,如何准确并高效地协调分布式并发操作也成为了分布式系统架构与设计中最大的挑战之一
4)、缺乏全局时钟
一个典型的分布式系统是由一系列空间上随意分布的多个进程组成的,具有明显的分布性,这些进程之间通过交换消息来进行相互通信。
因此,在分布式系统中,很难定义两个事件究竟谁先谁后,原因就是因为分布式系统缺乏一个全局的时钟控制序列
5)、故障总是会发生
组成分布式系统的所有计算机,都有可能发生任何形式的故障。
一个被大量工程实践过的黄金定理是:任何在设计阶段考虑到的异常情况一定会在系统实际运行中发生,并且,在系统实际运行中还会遇到很多在设计时未考虑到的异常故障。所以,除非需求指标允许,在系统设计时不能放过任何异常情况
6)、处理单点故障
在整个分布式系统中,如果某个角色或者功能只有某台单机在支撑,那么这个节点称为单点,其发生的故障称为单点故障,也就是通常说的
SPoF(Single Point of Failure),避免单点故障的关键就是把这个功能从单机实现变为集群实现,当然,这种变化一般会比较困难,否则就
不会有单点问题了。如果不能把单点变为集群实现,那么一般还有两种选择:
(1)给这个单点做好备份,能够在出现问题时进行恢复,并且尽量做到自动恢复
(2)降低单点故障的影响范围
以下来自百度:
分布式存储是一种数据存储技术,通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,
数据分散的存储在企业的各个角落.
分布式系统的意义
从单机单用户到单机多用户,再到现在的网络时代,应用系统发生了很多的变化。而分布式系统依然是目前很热门的讨论话题,那么,分布
式系统给我们带来了什么,或者说是为什么要有分布式系统呢?从三方面考虑:
-
升级单机处理能力的性价比越来越低
摩尔定律:当价格不变时,每隔18个月,集成电路上可容纳的晶体管数目会增加一倍,性能也将提升一倍。这个定律告诉我们,随着时间
的推移,单位成本的支出所能购买的计算机能力在提升。不过,如果我们把时间固定下来 ,也就是固定在某个具体时间点来购买单颗不同
型号的处理器,那么所购买的处理器性能越高,所要付出的成本就越高,性价比就越低。那么,也就是说在一个确定的时间点,通过更换
硬件做垂直扩展的方式来提升性能会越来越不划算 -
单机处理能力存在瓶颈
某个固定时间点,单颗处理器有自己的性能瓶颈,也就说即使愿意花更多的钱去买计算能力也买不到了 -
出于稳定性和可用性的考虑
如果采用单击系统,那么在这台机器正常的时候一切OK,一旦出问题,那么系统就完全不能用了。当然,可以考虑做容灾备份等方案,而
这些方案就会让系统演变为分布式系统了,传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
Ceph简介
ceph官方文档 http://docs.ceph.org.cn/
ceph中文开源社区 http://ceph.org.cn/
- 概述
Ceph是可靠的、可扩展的、统一的、开源分布式的存储系统。
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。
在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像
的后端存储。
不管你是想为云平台提供Ceph 对象存储和/或 Ceph 块设备,还是想部署一个 Ceph 文件系统或者把 Ceph 作为他用,所有 Ceph 存储
集群的部署都始于部署一个个 Ceph 节点、网络和 Ceph 存储集群。
Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。运行Ceph文件系统客户端时,则必须要有元数据服务器( MDS )。

Ceph可提供以下三种功能:
• 对象存储RADOSGW(Reliable、Autonomic、Distributed、Object Storage Gateway)
• 块存储RBD(Rados Block Device)
• 文件系统存储Ceph FS(Ceph Filesystem)
-
Ceph 优点
• 统一存储 - 虽然ceph底层是一个分布式文件系统,但由于在上层开发了支持对象和块的接口。所以在开源存储软件中,能够一统江湖。
• 高扩展性 - 扩容方便、容量大。能够管理上千台服务器、EB级的容量。
• 可靠性强 - 支持多份强一致性副本。副本能够垮主机、机架、机房、数据中心存放, 安全可靠。
存储节点可以自管理、自动修复。无单点故障,容错性强。
• 性能高 - 因为是多个副本,因此在读写操作时候能够做到高度并行化。理论上,节点越多,整个集群的IOPS和吞吐量越高。
ceph客户端读写数据直接与存储设备(osd) 交互。 -
Ceph应用场景
Ceph可以提供对象存储、块设备存储和文件系统服务,其对象存储可以对接网盘(owncloud)应用业务等;
其块设备存储可以对接(IaaS),当前主流的IaaS运平台软件,如:OpenStack、CloudStack、Zstack、Eucalyptus等以及kvm等。 -
Ceph的核心组件
Ceph的核心组件包括Ceph OSD、Ceph Monitor和Ceph MDS。
Ceph OSD
OSD的英文全称是Object Storage Device,它的主要功能是存储数据、复制数据、平衡数据、恢复数据等,与其它OSD间进行心跳
检查等, 并将一些变化情况上报给Ceph Monitor。一般情况下一块硬盘对应一个OSD,由OSD来对硬盘存储进行管理,当然一个
分区也可以成为一个OSD。
Ceph OSD的架构实现由物理磁盘驱动器、Linux文件系统和Ceph OSD服务组成,对于Ceph OSD Deamon而言,Linux文件系统显
的支持了 ,其拓展性,一般Linux文件系统有好几种,比如有BTRFS、XFS、Ext4等,BTRFS虽然有很多优点特性,但现在还没达到
生产环境所需的稳定性,一般比较推荐使用XFS。
当 Ceph 存储集群设定为有2个副本时,至少需要2个OSD守护进程,集群才能达到 active+clean 状态(Ceph 默认有3个副本,但你可以调整副本数)
Ceph Monitor
由该英文名字我们可以知道它是一个监视器,负责监视Ceph集群,维护Ceph集群的健康状态,同时维护着Ceph集群中的各种Map
图,比如OSD Map、Monitor Map、PG Map和CRUSH Map,这些Map统称为Cluster Map,Cluster Map是RADOS的关键数据结构,管
理集群中的所有成员、关系、属性等信息以及数据的分发,比如当用户需要存储数据到Ceph集群时,OSD需要先通过Monitor获取
最新的Map图,然后根据Map图和object id等计算出数据最终存储的位置。
Ceph MDS
全称是Ceph MetaData Server,主要保存的文件系统服务的元数据,但对象存储和块存储设备是不需要使用该服务的。
Ceph 元数据服务器( MDS )为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。
元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令。
块存储
什么是块设备?
块设备是i/o设备中的一类,是将信息存储在固定大小的块中,每个块都有自己的地址,还可以在设备的任意位置读取一定长度的数据。
看不懂?那就暂且认为块设备就是硬盘或虚拟硬盘吧。
查看下Linux环境中的设备:
[root@ceph ~] ls /dev/
/dev/sda /dev/sda1 /dev/sda2 /dev/sdb /dev/sdb1 /dev/hda
/dev/rbd1 /dev/rbd2 …
上面的/dev/sda、/dev/sdb和/dev/hda都是块设备文件,这些文件是怎么出现的呢?
当给计算机连接块设备(硬盘)后,系统检测的有新的块设备,该类型块设备的驱动程序就在/dev/下创建个对应的块设备设备文件
用户可以通过设备文件使用该块设备
它们怎么有的叫 sda?有的叫 sdb?有的叫 hda?
以sd开头的块设备文件对应的是SATA接口的硬盘,而以hd开头的块设备文件对应的是IDE接口的硬盘。
那SATA接口的硬盘跟IDE接口的硬盘有啥区别?
你只需要知道,IDE接口硬盘已经很少见到了,逐渐被淘汰中,而SATA接口的硬盘是目前的主流。
而sda和sdb的区别呢?
当系统检测到多个SATA硬盘时,会根据检测到的顺序对硬盘设备进行字母顺序的命名。
PS:系统按检测顺序命名硬盘会导致了盘符漂移的问题。
怎么还有的叫 rbd1 和 rbd2 呢?
被你发现了,rbd就是我们压轴主角了。rbd就是由Ceph集群提供出来的块设备。
可以这样理解,sda和hda都是通过数据线连接到了真实的硬盘,而rbd是通过网络连接到了Ceph集群中的一块存储区域,往rbd设备文件写入数据,最终会被存储到Ceph集群的这块区域中。
针对多种多样的使用场景,衍生出了很多的文件系统。有的文件系统能够提供更好的读性能,有的文件系统能提供更好的写性能。
我们平时常用的文件系统如xfs、ext4是读写性能等各方面比较均衡的通用文件系统。
然而,很多应用往往并不需要这种均衡,而需要突出某一方面的性能,如小文件的存储性能。
此时,xfs、ext4等通用文件系统如果不能满足应用的需求,应用往往会在裸设备上实现自己的数据组织和管理方式。
简单的说,就是应用为了强化某种存储特性而实现自己定制的数据组织和管理方式,而不使用通用的文件系统。
Ceph块设备接口怎么使用?
在Ceph集群中创建块设备:
rbd create -s 1G myrbd # 保证/etc/ceph目录下有Ceph集群的配置文件ceph.conf和ceph.client.admin.keyring
在用户机上挂载该Ceph块设备,可以理解为往用户机上插入硬盘:
rbdmap myrbd # 输出: /dev/rbd1
将Ceph块设备格式化成文件系统并挂载:
mkfs.xfs /dev/rbd1
mkdir -p /mnt/ceph_rbd
mount /dev/rbd1 /mnt/ceph_rbd
通过/mnt/ceph_rbd读写数据,都是在读写Ceph集群中该块设备对应的存储区域
总结一下,块设备可理解成一块硬盘,用户可以将其格式化成特定的文件系统,由文件系统来组织管理存储空间,从而为用户提供丰富而友好的数据操作支持。
文件系统存储
还记得上面说的块设备上的文件系统吗,用户可以在块设备上创建xfs文件系统,也可以创建ext4等其他文件系统。
Ceph集群实现了自己的文件系统来组织管理集群的存储空间,用户可以直接将Ceph集群的文件系统挂载到用户机上使用。
下图为ceph三种存储的对比:
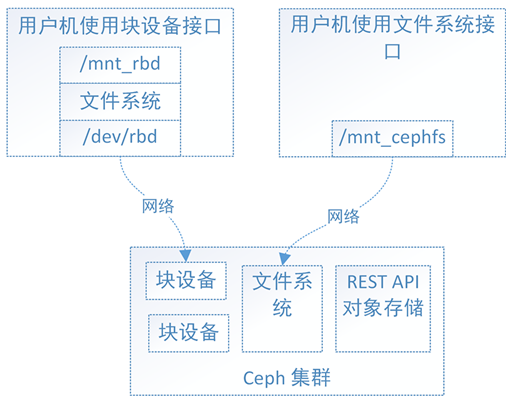
Ceph有了块设备接口,在块设备上完全可以构建一个文件系统,那么Ceph为什么还需要文件系统接口呢?
主要是因为应用场景的不同,Ceph的块设备具有优异的读写性能,但不能多处挂载同时读写,目前主要用在OpenStack上作为虚拟磁盘
Ceph的文件系统接口读写性能较块设备接口差,但具有优异的共享性。
PS:想了解更多?快去查查SAN和NAS。
为什么Ceph的块设备接口不具有共享性,而Ceph的文件系统接口具有呢?
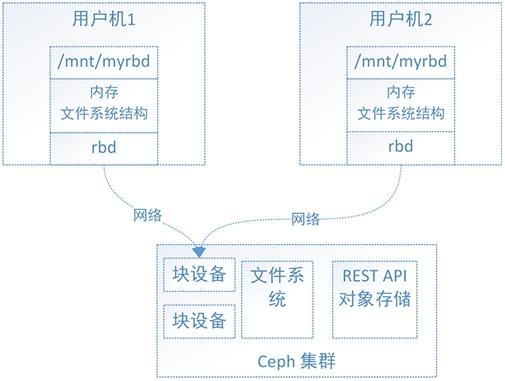
对于Ceph的块设备接口,如下图, 文件系统的结构状态是维护在各用户机内存中的
假设Ceph块设备同时挂载到了用户机1和用户机2,当在用户机1上写入数据后,更新了用户机1的内存中文件系统状态,最终数据存储到了Ceph集群中
但此时用户机2内存中的文件系统并不能得知底层Ceph集群数据已经变化而维持数据结构不变,因此用户无法从用户机2上读取用户机1上新写入的数据。
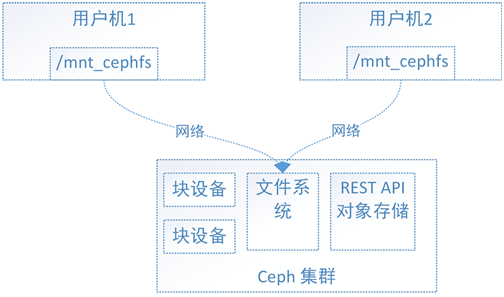
对于Ceph的文件系统接口,如下图,文件系统的结构状态是维护在远端Ceph集群中的
Ceph文件系统同时挂载到了用户机1和用户机2,当往用户机1的挂载点写入数据后,远端Ceph集群中的文件系统状态结构随之更新
当从用户机2的挂载点访问数据时会去远端Ceph集群取数据,由于远端Ceph集群已更新,所有用户机2能够获取最新的数据。
Ceph的文件系统接口使用方式?
将Ceph的文件系统挂载到用户机目录
mkdir -p /mnt/ceph_fuse
ceph-fuse /mnt/ceph_fuse
大功告成,在/mnt/ceph_fuse下读写数据,都是读写远程Ceph集群
总结一下,Ceph的文件系统接口弥补了Ceph的块设备接口在共享性方面的不足,Ceph的文件系统接口符合POSIX标准,用户可以像使用本地存储目录一样使用Ceph的文件系统的挂载目录。还是不懂?这样理解吧,无需修改你的程序,就可以将程序的底层存储换成空间无限并可多处共享读写的Ceph集群文件系统。
对象存储
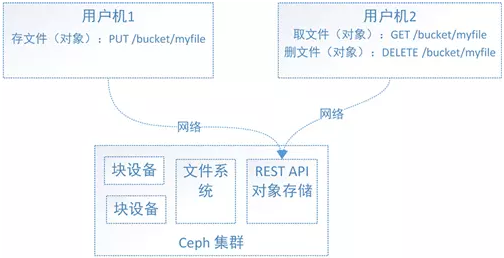
首先,通过下图来看下对象存储接口是怎么用的
简单了说,使用方式就是通过http协议上传下载删除对象(文件即对象)。
老问题来了,有了块设备接口存储和文件系统接口存储,为什么还整个对象存储呢?
往简单了说,Ceph的块设备存储具有优异的存储性能但不具有共享性,而Ceph的文件系统具有共享性然而性能较块设备存储差
为什么不权衡一下存储性能和共享性,整个具有共享性而存储性能好于文件系统存储的存储呢? 对象存储就这样出现了。
对象存储为什么性能会比文件系统好?
原因是多方面的,主要原因是对象存储组织数据的方式相对简单,只有bucket和对象两个层次(对象存储在bucket中),对对象的操作也相对简单。
而文件系统存储具有复杂的数据组织方式,目录和文件层次可具有无限深度,对目录和文件的操作也复杂的多,因此文件系统存储在维护文件系统的结构数据时会更加繁杂,从而导致文件系统的存储性能偏低。
存储空间(Bucket)所谓的桶
存储空间是用于存储对象(Object)的容器,所有的对象都必须隶属于某个存储空间。
您可以设置和修改存储空间属性用来控制地域、访问权限、生命周期等,这些属性设置直接作用于该存储空间内所有对象
可以通过灵活创建不同的存储空间来完成不同的管理功能。
同一个存储空间的内部是扁平的,没有文件系统的目录等概念,所有的对象都直接隶属于其对应的存储空间。
每个用户可以拥有多个存储空间
存储空间的名称在 OSS 范围内必须是全局唯一的,一旦创建之后无法修改名称。
存储空间内部的对象数目没有限制。
存储空间的命名规范如下:
只能包括小写字母、数字和短横线(-)。
必须以小写字母或者数字开头和结尾。
长度必须在3-63字节之间
Ceph的对象存储接口怎么用呢?
Ceph的对象接口符合亚马逊S3接口标准和OpenStack的Swift接口标准,可以自行学习这两种接口。
总结一下
文件系统存储具有复杂的数据组织结构,能够提供给用户更加丰富的数据操作接口,而对象存储精简了数据组织结构,提供给用户有限的数据操作接口,以换取更好的存储性能。对象接口提供了REST API,非常适用于作为web应用的存储。
块设备速度快,对存储的数据没有进行组织管理,用户数据读写不方便(以块设备位置offset + 数据的length来记录数据位置,读写数据)。
在块设备上构建了文件系统后,文件系统帮助块设备组织管理数据,数据存储对用户更加友好(以文件名来读写数据)。
Ceph文件系统接口解决了“Ceph块设备+本地文件系统”不支持多客户端共享读写的问题,但由于文件系统结构的复杂性导致了存储性能较Ceph块设备差。
对象存储接口是一种折中,保证一定的存储性能,同时支持多客户端共享读写
ceph在开源社区还是比较热门的,但是更多的是应用于云计算的后端存储。
所以大多数在生产环境中使用ceph的公司都会有专门的团队对ceph进行二次开发,ceph的运维难度也比较大。
但是经过合理的优化之后,ceph的性能和稳定性都是值得期待的。
服务端 RADOS (Reliable, Autonomic Distributed Object Store) 集群主要由两种节点组成:
• 一种是为数众多的、负责完成数据存储和维护功能的OSD(Object Storage Device)
• 另一种则是若干个负责完成系统状态检测和维护的monitor。
Monitor
Monitor 集群提供了整个存储系统的节点信息等全局的配置信息,通过 Paxos 算法保持数据的一致性。
OSD
OSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程
Pool, PG(placement group)
- Pool - 存储池, 存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略
支持两种类型:副本(replicated)和 纠删码( Erasure Code) - PG - 归置组, 是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略;
相同PG内的对象都会放到相同的硬盘上; PG是 ceph的核心概念, 服务端数据均衡和恢复的最小粒度就是PG
下面这张图形象的描绘了它们之间的关系:
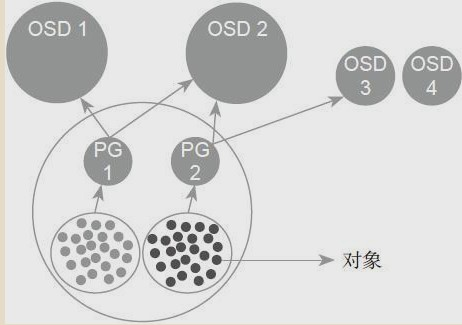
• 一个Pool里有很多PG,
• 一个PG里包含一堆对象;一个对象只能属于一个PG;
• PG有主从之分,一个PG分布在不同的OSD上
无论使用哪种存储方式(对象、块、挂载),存储的数据都会被切分成对象(Objects)。Objects size大小可以由管理员调整,通常为2M或4M。
每个对象都会有一个唯一的OID,由ino与ono生成,虽然这些名词看上去很复杂,其实相当简单:
ino即是文件的File ID,用于在全局唯一标示每一个文件,而ono则是分片的编号。
比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。
Oid的好处是可以唯一标示每个不同的对象,并且存储了对象与文件的从属关系。
由于ceph的所有数据都虚拟成了整齐划一的对象,所以在读写时效率都会比较高。
但是对象并不会直接存储进OSD中,因为对象的size很小,在一个大规模的集群中可能有几百到几千万个对象。
这么多对象光是遍历寻址,速度都是很缓慢的。
如果将对象直接通过某种固定映射的哈希算法映射到osd上,当这个osd损坏时,对象无法自动迁移至其他osd上面(因为映射函数不允许)。
为了解决这些问题,ceph引入了归置组的概念,即PG。
PG是一个逻辑概念,我们linux系统中可以直接看到对象,但是无法直接看到PG。
每个对象都会固定映射进一个PG中,所以当我们要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG就可以了,无需遍历所有对象。
而且在数据迁移时,也是以PG作为基本单位进行迁移,ceph不会直接操作对象。
对象时如何映射进PG的?
还记得OID么?首先使用静态hash函数对OID做hash取出特征码,用特征码与PG的数量取模,得到的序号则是PGID。
由于这种设计方式,PG的数量多寡直接决定了数据分布的均匀性,所以合理设置的PG数量可以很好的提升CEPH集群的性能并使数据均匀分布。
PG会根据管理员设置的副本数量进行复制,然后通过crush算法存储到不同的OSD节点上(其实是把PG中的所有对象存储到节点上),第一个osd节点即为主节点,其余均为从节点。
Ceph部署
Ceph集群部署
准备五台机器
monitor 192.168.23.237
osd1 192.168.23.233
osd2 192.168.23.234
osd3 192.168.23.235
client 192.168.23.236
1. 在node节点上准备osd
把3个osd挂载到sdb上
继续挂在并设置开机启动
2. 在管理节点上配置对其他节点免密登录
在monitor端配置
[root@monitor ~]# ssh-copy-id osd1;ssh-copy-id osd2;ssh-copy-id osd3
3. 在管理节点上安装ceph部署工具ceph-deploy
[root@monitor ~]# vim /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
enabled=1
gpgcheck=0
type=rpm-md
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
enabled=1
gpgcheck=0
type=rpm-md
priority=1
[Ceph-source]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS/
enabled=1
gpgcheck=0
type=rpm-md
priority=1
[Ceph-aarch64]
name=Ceph aarch64 packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/aarch64/
enabled=1
gpgcheck=0
type=rpm-md
[root@monitor ~]# scp /etc/yum.repos.d/ceph.repo node1:/etc/yum.repos.d/
[root@monitor ~]# scp /etc/yum.repos.d/ceph.repo node2:/etc/yum.repos.d/
[root@monitor ~]# scp /etc/yum.repos.d/ceph.repo node3:/etc/yum.repos.d/
3.2. 创建monitor服务(仅管理节点)
[root@monitor ~]# yum install -y ceph-deploy
[root@monitor ~]# mkdir /etc/ceph
[root@monitor ~]# cd /etc/ceph/
[root@monitor ceph]# ceph-deploy new monitor
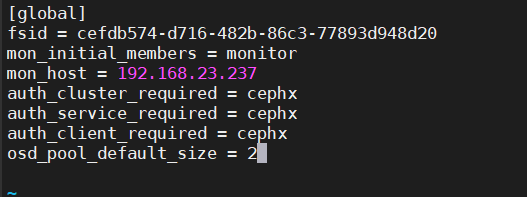
[root@monitor ceph]# vim ceph.conf
4. 查看配置文件
osd_pool_default_size = 2 # 配置文件的默认副本数从3改成2,这样只有两个osd也能达到active+clean状态
5. 在所有节点安装ceph(在管理节点操作)
yum -y install ceph
6. 配置初始 monitor(s)、并收集所有密钥(仅管理节点)
[root@monitor ceph]# ceph-deploy mon create-initial
[root@monitor ceph]# ls
ceph.bootstrap-mds.keyring ceph.bootstrap-rgw.keyring ceph-deploy-ceph.log
ceph.bootstrap-mgr.keyring ceph.client.admin.keyring ceph.mon.keyring
ceph.bootstrap-osd.keyring ceph.conf rbdmap
7. 激活第1步中的OSD
7.1 准备OSD(管理节点操作
[root@monitor ceph]# ceph-deploy osd prepare osd1:/mnt/osd osd2:/mnt/osd osd3:/mnt/osd
7.2 修改OSD属主属组(所有OSD节点)
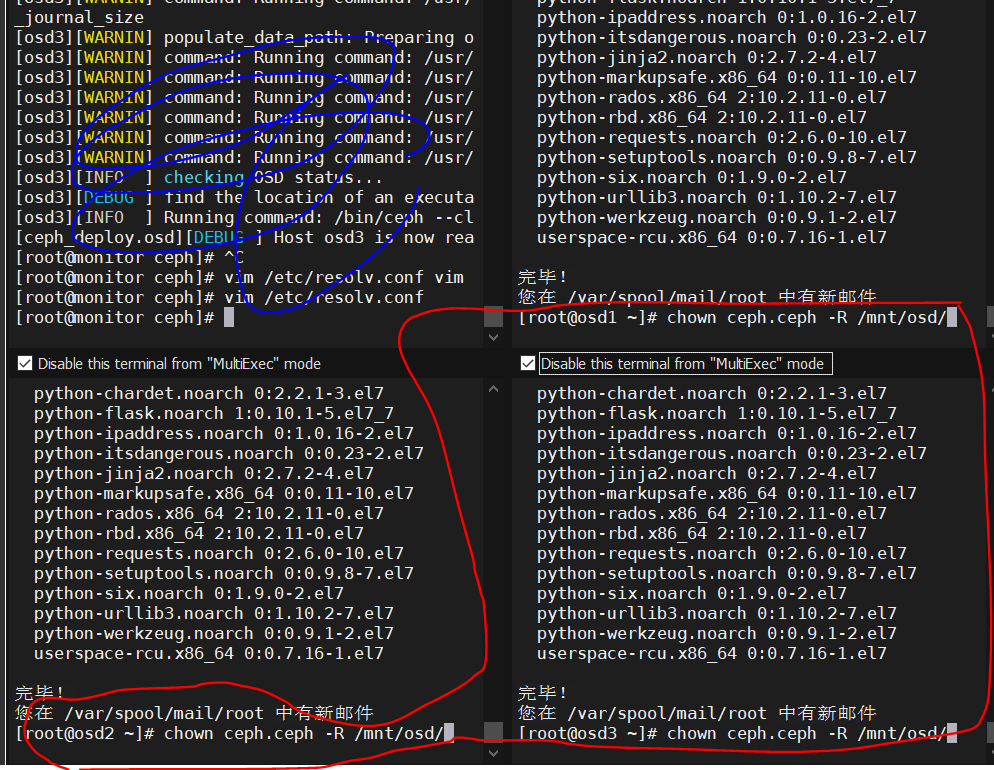
7.3 激活OSD(管理节点操作)
[root@monitor ceph]# ceph-deploy osd activate osd1:/mnt/osd osd2:/mnt/osd osd3:/mnt/osd
[root@monitor ceph]# ceph-deploy osd list osd{1..3}
8.统一配置
用 ceph-deploy 把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点
这样每次执行 Ceph 命令行时就无需指定 monitor 地址和 ceph.client.admin.keyring 了
[root@monitor ceph]# ceph-deploy admin osd1 osd2 osd3 #admin是命令
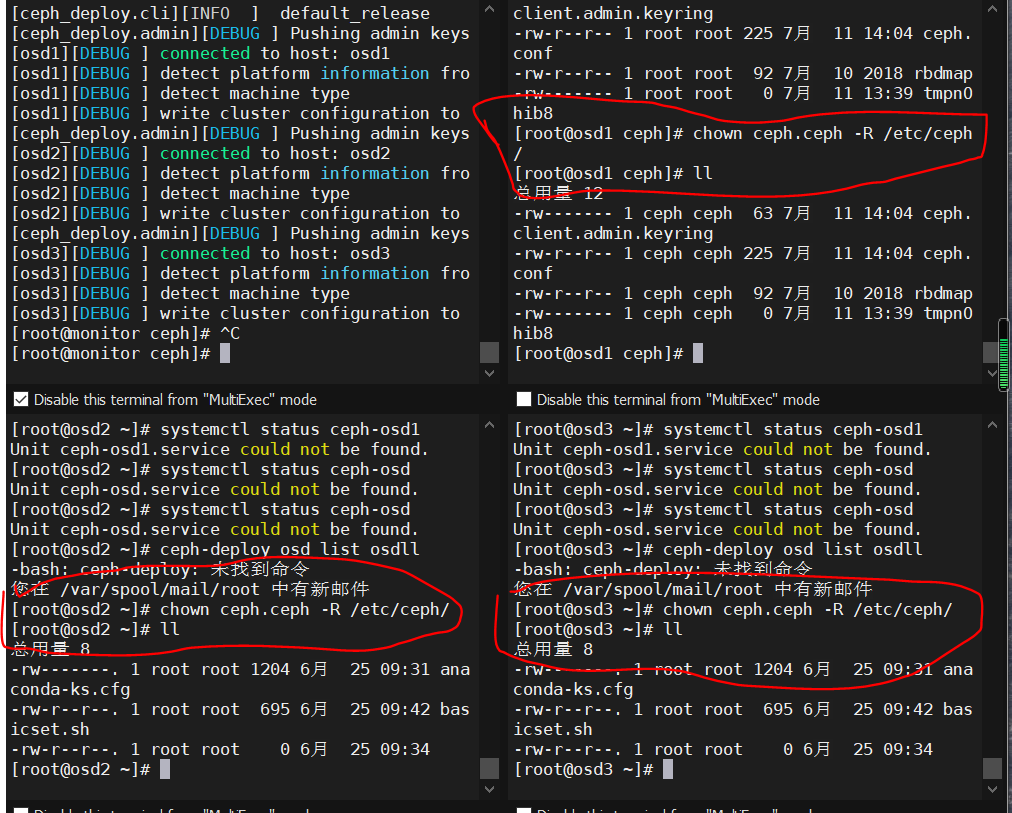
检查集群的健康状况
[root@monitor ceph]# ceph health
HEALTH_OK
Ceph块设备
Ceph 块设备靠无限伸缩性提供了高性能,如向内核模块、或向 abbr:KVM (kernel virtual machines) (如 Qemu 、 OpenStack 和 CloudStack 等云计算系统通过 libvirt 和 Qemu 可与 Ceph 块设备集成)。你可以用同一个集群同时运行 Ceph RADOS 网关、 Ceph FS 文件系统、和 Ceph 块设备。
要使用 Ceph 块设备,你必须有一个在运行的 Ceph 集群
要使用 Ceph 块设备命令,你必须有对应集群的访问权限
- 在管理节点上将 配置文件和密钥环拷贝到client
[root@monitor ceph]# scp /etc/yum.repos.d/ceph.repo 192.168.23.236:/etc/yum.repos.d
[root@monitor ceph]# yum -y install ceph
[root@monitor ceph]# ceph-deploy admin 192.168.23.236
- 修改密钥文件的权限
[root@client ceph]# chown -R ceph.ceph /etc/ceph
[root@client ceph]# chmod +r ceph.client.admin.keyring
使用块存储
在 client 节点上操作
- 创建存储池
语法: ceph osd pool create {pool-name} {pg-num}
参数说明:
pool-name : 存储池名称,必须唯一。
pg-num : 存储池拥有的归置组总数。
下面是pg-num几个常用的值:
• 少于 5 个 OSD 时可把 pg_num 设置为 128
• OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512
• OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096
• OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
• 自己计算 pg_num 取值时可借助 pgcalc 工具. 随着OSD数量的增加,正确的 pg_num 取值变得更加重要,
因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难事件导致数据丢失的概率)。
- 创建块设备映像 {pool-name}/{image-name}
# 指定 features: layering,否则 map 可能出错
# 也可以将 rbd_default_features = 1 添加到 /etc/ceph/ceph.conf 的 [global]
# 如果创建映像时不指定存储池,它将使用默认的 rbd 存储池
[root@monitor ceph]# ceph osd pool create mypool 128
pool 'mypool' created
[root@monitor ceph]# rbd create --size 1024 mypool/myimage --image-feature layering
[root@monitor ceph]# rbd create --size 2048 mypool/web --image-feature layering
[root@monitor ceph]# rbd ls mypool
myimage
web
- 映射块设备 {pool-name}/{image-name}
[root@client ceph]# rbd map mypool/myimage --id admin # 注:rbd0 说明这是映射的第一个块设备
/dev/rbd0
[root@client ceph]# ls /dev/rbd
rbd/ rbd0
[root@client ceph]# ls /dev/rbd0 -l
brw-rw---- 1 root disk 252, 0 7月 11 17:12 /dev/rbd0
[root@client ceph]# rbd showmapped
id pool image snap device
0 mypool myimage - /dev/rbd0
[root@client ceph]# ll /dev/rbd/mypool/
总用量 0
lrwxrwxrwx 1 root root 10 7月 11 17:12 myimage -> ../../rbd0
- 使用块设备 /dev/rbd/{pool-name}/{image-name} 创建文件系统
[root@client ceph]# mkfs.xfs /dev/rbd0
- 挂载
[root@client ceph]# mkdir /mnt/rdb0
[root@client ceph]# mount /dev/rbd0 /mnt/rbd0
[root@client ceph]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.7M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 17G 1.8G 16G 11% /
/dev/sda1 1014M 137M 878M 14% /boot
tmpfs 98M 0 98M 0% /run/user/0
/dev/rbd0 1014M 33M 982M 4% /mnt/rbd0
在线扩容
块设备扩容
文件系统级别在线扩容
[root@client rdb0]# rbd resize --size 2048 mypool/myimage # 调整块设备大小为2G
Resizing image: 100% complete...done.
[root@client rdb0]# rbd info mypool/myimage
rbd image 'myimage':
size 2048 MB in 512 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.10206b8b4567
format: 2
features: layering
flags:
[root@client rdb0]# df -h # 我们发现只有镜像变大了,rbd0还是1G
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.7M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 17G 1.8G 16G 11% /
/dev/sda1 1014M 137M 878M 14% /boot
tmpfs 98M 0 98M 0% /run/user/0
/dev/rbd0 1014M 33M 982M 4% /mnt/rbd0
[root@client rdb0]# xfs_growfs /mnt/rbd0
meta-data=/dev/rbd0 isize=512 agcount=8, agsize=32768 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 262144 to 524288
[root@client rdb0]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.7M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 17G 1.8G 16G 11% /
/dev/sda1 1014M 137M 878M 14% /boot
tmpfs 98M 0 98M 0% /run/user/0
/dev/rbd0 2.0G 33M 2.0G 2% /mnt/rbd0
删除块设备
[root@client ~]# umount /mnt/rdb0/
[root@client ~]# rbd unmap /dev/rbd/mypool/myimage # 解除设备映射
[root@client ~]# rbd showmapped # 再次查看,发现/dev/rbd0已经没有了
[root@client ~]# rbd rm mypool/myimage # 删除块设备
Removing image: 100% complete...done.
总结使用块设备的步骤:
1.客户端安装ceph,将密钥环文件传到客户端
2.创建存储池
3.在存储池中创建镜像 -------- 类似于创建一块磁盘
4.rbd映射 -------- 相当于将磁盘插入本机,这一步及后面的步骤一定要在客户端操作
5.格式化
6.挂载
在线扩容:
1.设备级别扩容
2.文件系统级别扩容
Ceph文件系统
部署MDS服务
[root@monitor ceph]# ceph-deploy mds create osd{1..3}
查看状态
[root@monitor ceph]# ceph mds stat
e3:, 3 up:standby
查看集群状态
[root@monitor ceph]# ceph -s
cluster cefdb574-d716-482b-86c3-77893d948d20
health HEALTH_OK
monmap e1: 1 mons at {monitor=192.168.23.237:6789/0}
election epoch 3, quorum 0 monitor
osdmap e18: 3 osds: 3 up, 3 in
flags sortbitwise,require_jewel_osds
pgmap v190: 192 pgs, 2 pools, 14752 kB data, 25 objects
15702 MB used, 14987 MB / 30690 MB avail
192 active+clean
创建ceph文件系统
官方文档: http://docs.ceph.org.cn/cephfs/
一个 Ceph 文件系统需要至少两个 RADOS 存储池,一个用于数据、一个用于元数据。配置这些存储池时需考虑:
• 为元数据存储池设置较高的副本水平,因为此存储池丢失任何数据都会导致整个文件系统失效。
• 为元数据存储池分配低延时存储器(像 SSD ),因为它会直接影响到客户端的操作延时。
创建存储池
[root@monitor ceph]# ceph osd pool create cephfs_data 128
pool 'cephfs_data' created
[root@monitor ceph]# ceph osd pool create cephfs_metadata 128
pool 'cephfs_metadata' created
查看存储池
[root@monitor ceph]# ceph osd lspools
0 rbd,1 mypool,2 cephfs_data,3 cephfs_metadata,
关于存储池: 官方文档: http://docs.ceph.org.cn/rados/operations/pools/
创建前
[root@monitor ceph]# ceph fs ls
No filesystems enabled
创建文件系统
语法: ceph fs new <fs_name> <metadata> <data>
[root@monitor ceph]# ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 3 and data pool 2
查看
[root@monitor ceph]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@monitor ceph]# ceph mds stat
e6: 1/1/1 up {0=osd3=up:active}, 2 up:standby
挂载文件系统
有两种不同挂载方式
A. 内核驱动挂载Ceph文件系统
- 安装ceph
- 创建挂载点
[root@client ceph]# mkdir /mnt/cephfs
[root@client ceph]# yum -y install ceph-fuse
- 创建密钥文件
3.1 在admin节点查看密钥内容
[root@admin ceph]# cat ceph.client.admin.keyring
[client.admin]
key = AQBLR7xdckUIFhAA2G05Hidq5aoSse0nxGNdJQ==
3.2 在client节点创建密钥文件
[root@client ceph]# vim /etc/ceph/admin.secret #复制上面文件中的内容,注意不是全部内容
AQBLR7xdckUIFhAA2G05Hidq5aoSse0nxGNdJQ==
-
挂载
[root@client ceph]# mount.ceph 192.168.10.11:6789:/ /mnt/cephfs/ -o name=admin,secretfile=/etc/ceph/admin.secret
B. 用户空间文件系统(FUSE)
先卸载前面挂载的 -
从admin节点拷贝密钥环(ceph.client.admin.keyring文件)
[root@admin ceph]# scp ceph.client.admin.keyring 192.168.10.15:/etc/ceph/ -
挂载
[root@client rdb0]# ceph-fuse -m 192.168.23.237:6789 /mnt/cephfs/
ceph-fuse[3997]: starting ceph client
2022-07-11 17:47:31.286436 7f55b517af00 -1 init, newargv = 0x55c3679e6780 newargc=11
ceph-fuse[3997]: starting fuse
/
[root@client rdb0]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.7M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 17G 1.8G 16G 11% /
/dev/sda1 1014M 137M 878M 14% /boot
tmpfs 98M 0 98M 0% /run/user/0
/dev/rbd0 2.0G 33M 2.0G 2% /mnt/rbd0
ceph-fuse 30G 16G 15G 52% /mnt/cephfs
卸载: fusermount -u
- 注: 从管理节点而非服务器节点挂载 Ceph FS 文件系统
为了安全, 请将密钥文件设置合适的权限
Ceph对象存储
官方文档: http://docs.ceph.org.cn/rados/operations/pools/
如果你开始部署集群时没有创建存储池, Ceph 会用默认存储池存数据。存储池提供的功能:
• 自恢复力: 你可以设置在不丢数据的前提下允许多少 OSD 失效,对多副本存储池来说,此值是一对象应达到的副本数。典型配置存储一个对象和它的一个副本(即 size = 2 ),但你可以更改副本数;对纠删编码的存储池来说,此值是编码块数(即纠删码配置里的 m=2 )。
• 归置组: 你可以设置一个存储池的归置组数量。典型配置给每个 OSD 分配大约 100 个归置组,这样,不用过多计算资源就能得到较优的均衡。配置了多个存储池时,要考虑到这些存储池和整个集群的归置组数量要合理。
• CRUSH 规则: 当你在存储池里存数据的时候,与此存储池相关联的 CRUSH 规则集可控制 CRUSH 算法,并以此操纵集群内对象及其副本的复制(或纠删码编码的存储池里的数据块)。你可以自定义存储池的 CRUSH 规则。
• 快照: 用 ceph osd pool mksnap 创建快照的时候,实际上创建了某一特定存储池的快照。
• 设置所有者: 你可以设置一个用户 ID 为一个存储池的所有者。
要把数据组织到存储池里,你可以列出、创建、删除存储池,也可以查看每个存储池的利用率
列出存储池
[guo@node1 ceph-cluster]$ rados lspools #默认情况下只有一个rbd存储池
rbd
[guo@node1 ceph-cluster]$ ceph osd lspools
0 rbd,
创建存储池
[guo@node1 ceph-cluster]$ ceph osd pool create data 128
pool 'data' created
[guo@node1 ceph-cluster]$ rados lspools
rbd
data
设置存储池配额
存储池配额可设置最大字节数或每存储池最大对象数
语法:
ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}]
例:将data存储池设置只能存储10000个对象
[guo@node1 ceph-cluster]$ ceph osd pool set-quota data max_objects 10000
set-quota max_objects = 10000 for pool data
要取消配额,设置为0
重命名存储池 ceph osd pool rename {current-pool-name} {new-pool-name}
删除存储池 ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]
查看存储池统计信息 rados df
创建存储池快照 ceph osd pool mksnap {pool-name} {snap-name}
删除存储池快照 ceph osd pool rmsnap {pool-name} {snap-name}
调整存储池选项值 ceph osd pool set {pool-name} {key} {value}
获取存储池选项值 ceph osd pool get {pool-name} {key}
设置对象副本数 ceph osd pool set {poolname} size {num-replicas} #{num-replicas} 包括对象本身,默认为2
获取对象副本数 ceph osd dump | grep 'replicated size'
查看对象 rados ls -p poolname
存储对象 rados put <obj-name> <infile> -p poolname
获取对象 rados get <obj-name> <outfile> -p poolname
删除对象 rados rm <obj-name> -p poolname
复制对象 rados cp <obj-name> [target-obj] -p poolname
截断对象 rados truncate <obj-name> length -p poolname 把对象内容保留多少长度
例:
- 在管理端将配置文件和密钥环发送到客户端
[root@admin ~]# cd /etc/ceph/
[root@admin ceph]# ceph-deploy admin client client2
- 在任意节点创建存储池cephobj
[root@client2 ceph]# ceph osd pool create cephobj 128
- 在其中一个客户端存入一个对象到cephobj
[root@client2 ceph]# echo "this file upload by client2" > /tmp/a.txt
[root@client2 ceph]# rados put test-file /tmp/a.txt -p cephobj # 存储对象
- 在另外的客户端获取对象
[root@client ~]# rados ls -p cephobj
test-file
[root@client ~]# rados get test-file /opt/a.txt -p cephobj # 取出对象
[root@client ~]# cat /opt/a.txt
this file upload by client2
集群扩容
添加OSD
实验:为ceph集群添加OSD
一.准备工作
在所有节点上修改解析记录,加入node4
在node4节点上:
配置时间与管理节点admin同步
配置好yum源并安装好ceph软件
挂载好一块磁盘
在管理节点admin上:
把用户公钥传到node4上
二.配置集群加入OSD
在管理节点上操作:
[root@node4 ~]# mkfs.xfs /dev/sdb
[root@node4 ~]# mkdir /mnt/osd4
[root@node4 ~]# mount /dev/sdb /mnt/osd4/
[root@admin ~]# cd /etc/ceph/
[root@admin ceph-cluster]# ceph-deploy osd prepare node4:/mnt/osd4 #准备osd
[root@admin ceph-cluster]# ceph-deploy osd activate node4:/mnt/osd4 #激活osd
一旦你新加了 OSD,Ceph 集群就开始重均衡,把归置组迁移到新 OSD 。可以用下面的 ceph 命令观察此过程:
[root@admin ceph-cluster]# ceph -w
=====================================================================
删除OSD
1.把OSD踢出集群
删除 OSD 前,它通常是 up 且 in 的,要先把它踢出集群,以使 Ceph 启动重新均衡、把数据拷贝到其他 OSD
ceph osd out {osd-num}
例:
[root@admin ceph-cluster]# ceph osd out 2
2.观察数据迁移
一旦把 OSD 踢出( out )集群, Ceph 就会开始重新均衡集群、把归置组迁出将删除的 OSD 。你可以用 ceph 工具观察此过程
ceph -w
你会看到归置组状态从 active+clean 变为 active, some degraded objects 、迁移完成后最终回到 active+clean 状态
3.停止OSD进程
把 OSD 踢出集群后,它可能仍在运行,就是说其状态为 up 且 out 。删除前要先停止 OSD 进程
/etc/init.d/ceph stop osd.{osd-num}
这是el6中的操作方法,7中可kill进程号, 或用systemd结束
结束进程后用ceph osd tree可以看到osd状态已经由up变成了down
4.删除 OSD
此步骤依次把一个 OSD 移出集群 CRUSH 图、删除认证密钥、删除 OSD 图条目、删除 ceph.conf 条目。
如果主机有多个硬盘,每个硬盘对应的 OSD 都得重复此步骤
- ceph osd crush remove {name} #删除 CRUSH 图的对应 OSD 条目,它就不再接收数据了,name可用ceph osd crush tree查看
例:
[root@admin ceph-cluster]# ceph osd crush remove osd.2
2)删除 OSD 认证密钥: ceph auth del osd.{osd-num}
例:
[root@admin ceph-cluster]# ceph auth del osd.2
3)删除 OSD: ceph osd rm {osd-num}
例:
[root@admin ceph-cluster]# ceph osd rm 2
=======================================================
有时候,(通常是只有几台主机的“小”集群,比如小型测试集群)拿出( out )某个 OSD 可能会使 CRUSH 进入临界状态,这时某些 PG 一直卡在 active+remapped 状态.如果遇到了这种情况,你应该把此 OSD 标记为 in :
ceph osd in {osd-num}
等回到最初的状态后,把它的权重设置为 0 ,而不是标记为 out ,用此命令:
ceph osd crush reweight osd.{osd-num} 0
执行后,你可以观察数据迁移过程,应该可以正常结束。把某一 OSD 标记为 out 和权重改为 0 的区别在于,前者,包含此 OSD 的桶、其权重没变;而后一种情况下,桶的权重变了(降低了此 OSD 的权重)。某些情况下, reweight 命令更适合“小”集群。
添加Monitors
实验:为ceph集群添加monitor
Ceph 存储集群需要至少一个 Monitor 才能运行。
为达到高可用,,型的 Ceph 存储集群会运行多个 Monitors,这样在单个 Monitor 失败时不会影响 Ceph 存储集群的可用性。
Ceph 使用 PASOX 算法,此算法要求有多半 monitors(即 1 、 2:3 、 3:4 、 3:5 、 4:6 等 )形成法定人数
下面我们要在node1和node2上添加monitor,以形成monitor的法定人数:
1.修改配置文件:
[root@admin ceph]# vim ceph.conf
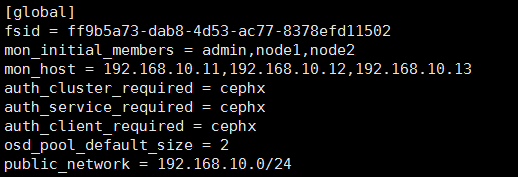
2.新增monitor成员:
[root@admin ceph]# ceph-deploy --overwrite-conf mon add node1
[root@admin ceph]# ceph-deploy --overwrite-conf mon add node2
或 ceph-deploy mon create {host-name [host-name]…}
注: 在一主机上新增监视器时,如果它不是由 ceph-deploy new 命令所定义的,那就必须把 public network 加入 ceph.conf 配置文件
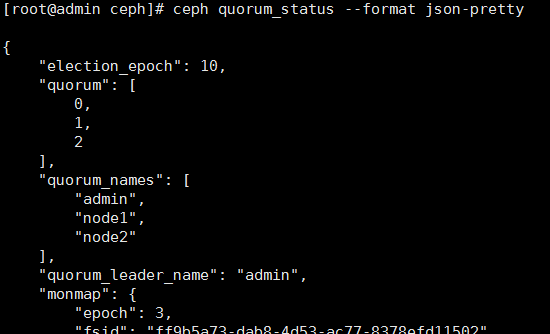
3.添加完成后查看:
[root@admin ceph]# ceph quorum_status --format json-pretty
删除monitor
ceph-deploy mon destroy {host-name [host-name]…}
集群维护常用命令概览
集群维护常用命令概览
1:检查集群健康状况
启动集群后、读写数据前,先检查下集群的健康状态。你可以用下面的命令检查:
ceph health 或者 ceph health detail (输出信息更详细)
要观察集群内正发生的事件,打开一个新终端,然后输入:ceph -w
2:检查集群的使用情况
ceph df 检查集群的数据用量及其在存储池内的分布情况,可以用 df 选项,它和 Linux 上的 df 相似。如下:
输出的 GLOBAL 段展示了数据所占用集群存储空间的概要。
• SIZE: 集群的总容量;
• AVAIL: 集群的可用空间总量;
• RAW USED: 已用存储空间总量;
• % RAW USED: 已用存储空间比率。用此值参照 full ratio 和 near full ratio 来确保不会用尽集群空间
输出的 POOLS 段展示了存储池列表及各存储池的大致使用率。本段没有展示副本、克隆品和快照占用情况。
例如,如果你把 1MB 的数据存储为对象,理论使用率将是 1MB ,但考虑到副本数、克隆数、和快照数,实际使用率可能是 2MB 或更多。
• NAME: 存储池名字;
• ID: 存储池唯一标识符;
• USED: 大概数据量,单位为 KB 、 MB 或 GB ;
• %USED: 各存储池的大概使用率;
• OBJECTS: 各存储池内的大概对象数。
注: POOLS 段内的数字是理论值,它们不包含副本、快照或克隆。
因此,它与 USED 和 %USED 数量之和不会达到 GLOBAL 段中的 RAW USED 和 %RAW USED 数量。
ceph osd df 命令,可以详细列出集群每块磁盘的使用情况,包括大小、权重、使用多少空间、使用率等等
3:检查集群状态
要检查集群的状态,执行下面的命令:
ceph status
输出信息里包含:
• 集群唯一标识符
• 集群健康状况
• 监视器图元版本和监视器法定人数状态
• OSD 版本和 OSD 状态摘要
• 其内存储的数据和对象数量的粗略统计,以及数据总量等。
4:检查MONITOR状态
查看监视器图,执行下面的命令::
ceph mon stat
ceph mon dump
要检查监视器的法定人数状态,执行下面的命令:
ceph quorum_status
5:检查 MDS 状态:
元数据服务器为 Ceph 文件系统提供元数据服务,元数据服务器有两种状态: up | \ down 和 active | inactive ,执行下面的命令查看元数据服务器状态为 up 且 active :
ceph mds stat
要展示元数据集群的详细状态,执行下面的命令:
ceph mds dump
6:集群命令详解
mon 相关
ceph mon stat 查看mon的状态信息
ceph quorum_status 查看mon的选举状态
ceph mon dump 查看mon的映射信息
ceph mon remove cs1 删除一个mon节点
ceph mon getmap -o a.txt 获得一个正在运行的mon map,并保存在a.txt文件中
monmaptool --print a.txt 读取上面获得的map
ceph-mon -i nc3 --inject-monmap a.txt 把上面的mon map注入新加入的节点
ceph-conf --name mon.nc3 --show-config-value admin_socket 查看mon的amin socket
ceph-conf --name mon.nc1 --show-config-value log_file 查看ceph mon log日志所在的目录
ceph --admin-daemon /var/run/ceph/ceph-mon.nc3.asok config show | less 查看一个集群ceph-mon.nc3参数的配置
mds 相关
ceph mds stat 查看msd状态
ceph mds rm 0 mds.nc1 删除一个mds节点
ceph mds rmfailed <int[0-]> 设置mds状态为失败
ceph mds add_data_pool 新建pool
mds cluster_down 关闭mds集群
mds cluster_up 启动mds集群
ceph mds set max_file_size 1024000000000 设置cephfs文件系统存储方式最大单个文件尺寸
清除 cephfs 文件系统步骤
ceph mds fail 0 强制mds状态为featrue
ceph fs rm leadorfs --yes-i-really-mean-it 删除mds文件系统
ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it 删除fs数据文件夹
ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it 删除元数据文件夹
然后再删除 mds key ,残留文件等
ceph mds rm 0 mds.node242 拆除文件系统前推荐先删除节点,待验证
ceph auth 相关
详见 ceph用户管理
ceph auth list 查看ceph集群中的认证用户及相关的key
为ceph创建一个admin用户并为admin用户创建一个密钥,把密钥保存到/etc/ceph目录下:
ceph auth get-or-create client.admin mds ‘allow’ osd ‘allow *’ mon ‘allow *’ > /etc/ceph/ceph.client.admin.keyring
或
ceph auth get-or-create client.admin mds ‘allow’ osd ‘allow *’ mon ‘allow *’ -o /etc/ceph/ceph.client.admin.keyring
为osd.0创建一个用户并创建一个key
ceph auth get-or-create osd.0 mon ‘allow rwx’ osd ‘allow *’ -o /var/lib/ceph/osd/ceph-0/keyring
为mds.nc3创建一个用户并创建一个key
ceph auth get-or-create mds.nc3 mon ‘allow rwx’ osd ‘allow *’ mds ‘allow *’ -o /var/lib/ceph/mds/ceph-cs1/keyring
导入key信息
ceph auth import /var/lib/ceph/mds/ceph-cs1/keyring
删除集群中的一个认证用户
ceph auth del osd.0
osd 相关
ceph osd tree 查看osd列表
ceph osd perf 查看数据延迟
ceph osd df 详细列出集群每块磁盘的使用情况,包括大小、权重、使用多少空间、使用率等等
ceph osd down 0 down掉osd.0节点
ceph osd rm 0 在集群中删除一个osd硬盘
ceph osd crush rm osd.0 在集群中删除一个osd 硬盘 crush map
ceph osd crush rm cs1 在集群中删除一个osd的host节点
ceph osd getmaxosd 查看最大osd的个数
ceph osd setmaxosd 2048 设置最大的osd的个数(当扩大osd节点的时候必须扩大这个值)
ceph osd crush set {id} {weight} [{loc1} [{loc2} …]] 设置osd crush的权重为1.0
例如:
ceph osd crush set osd.1 0.5 host=node241
ceph osd reweight 3 0.5 设置osd的权重
reweighted osd.3 to 0.5 (8327682)
或者用下面的方式
ceph osd crush reweight osd.1 1.0
ceph osd out osd.3: 把一个osd节点逐出集群
3 1 osd.3 up 0 # osd.3的reweight变为0了就不再分配数据,但是设备还是存活的
ceph osd in osd.3 把逐出的osd加入集群
ceph osd pause 暂停osd (暂停后整个集群不再接收数据)
ceph osd unpause 再次开启osd (开启后再次接收数据)
查看一个集群osd.0参数的配置、输出信息特别详细,集群所有配置生效可以在此参数下确认
ceph --admin-daemon /var/run/ceph/ceph-osd.0.asok config show | less
设置标志 flags ,不允许关闭osd、解决网络不稳定,osd 状态不断切换的问题
ceph osd set nodown
取消设置
ceph osd unset nodown
pool 相关
查看ceph集群中的pool数量
ceph osd lspools 或者 ceph osd pool ls
在ceph集群中创建一个pool
ceph osd pool create rbdtest 100 #这里的100指的是PG组:
查看集群中所有pool的副本尺寸
ceph osd dump | grep ‘replicated size’
查看pool 最大副本数量
ceph osd pool get rbdpool size
size: 3
查看pool 最小副本数量
[root@node241 ~]# ceph osd pool get rbdpool min_size
min_size: 2
设置一个pool的pg数量
ceph osd pool set rbdtest pg_num 100
设置一个pool的pgp数量
ceph osd pool set rbdtest pgp_num 100
修改ceph,数据最小副本数、和副本数
ceph osd pool set $pool_name min_size 1
ceph osd pool set $pool_name size 2
示例:
ceph osd pool set rbdpool min_size 1
ceph osd pool set rbdpool size 2
验证:
ceph osd dump
pool 3 ‘rbdpool’ replicated size 2 min_size 1
设置rbdtest池的最大存储空间为100T(默认是1T)
ceph osd pool set rbdtest target_max_bytes 100000000000000
为一个ceph pool配置配额、达到配额前集群会告警,达到上限后无法再写入数据
ceph osd pool set-quota rbdtest max_objects 10000
在集群中删除一个pool,注意删除poolpool 映射的image 会直接被删除,线上操作要谨慎。
ceph osd pool delete rbdtest rbdtest --yes-i-really-really-mean-it #集群名字需要重复两次
给一个pool创建一个快照
ceph osd pool mksnap rbdtest rbdtest-snap20150924
查看快照信息
rados lssnap -p rbdtest
1 rbdtest-snap20150924 2015.09.24 19:58:55
2 rbdtest-snap2015092401 2015.09.24 20:31:21
2 snaps
删除pool的快照
ceph osd pool rmsnap rbdtest rbdtest-snap20150924
验证,剩余一个snap
rados lssnap -p rbdtest
2 rbdtest-snap2015092401 2015.09.24 20:31:21
1 snaps
rados命令相关
rados 是和Ceph的对象存储集群(RADOS),Ceph的分布式文件系统的一部分进行交互是一种实用工具。
查看ceph集群中有多少个pool (只是查看pool)
rados lspools 同 ceph osd pool ls 输出结果一致
显示整个系统和被池毁掉的使用率统计,包括磁盘使用(字节)和对象计数
rados df
创建一个pool
rados mkpool test
创建一个对象object
rados create test-object -p test
查看对象文件
rados -p test ls
test-object
删除一个对象
rados rm test-object-1 -p test
删除foo池 (和它所有的数据)
rados rmpool test test –yes-i-really-really-mean-it
查看ceph pool中的ceph object (这里的object是以块形式存储的)
rados ls -p test | more
为test pool创建快照
rados -p test mksnap testsnap
created pool test snap testsnap
列出给定池的快照
rados -p test lssnap
1 testsnap 2015.09.24 21:14:34
删除快照
rados -p test rmsnap testsnap
removed pool test snap testsnap
上传一个对象到test pool
rados -p test put myobject blah.txt
使用rados 进行性能测试
测试用例如下:
rados bench 600 write rand -t 100 -b 4K -p datapool
选项解释:
测试时间 :600
支持测试类型:write/read ,加rand就是随机,不加就是顺序
并发数( -t选项):100
pool的名字是:datapool
PG 相关
PG =“放置组”。当集群中的数据,对象映射到编程器,被映射到这些PGS的OSD。
查看pg组的映射信息
ceph pg dump 或者 ceph pg ls
查看一个PG的map
ceph pg map 0.3f
osdmap e88 pg 0.3f (0.3f) -> up [0,2] acting [0,2] #其中的[0,2]代表存储在osd.0、osd.2节点,osd.0代表主副本的存储位置
查看PG状态
ceph pg stat
查询一个pg的详细信息
ceph pg 0.26 query
要洗刷一个pg组,执行命令:
ceph pg scrub {pg-id}
查看pg中stuck的状态
要获取所有卡在某状态的归置组统计信息,执行命令:
ceph pg dump_stuck inactive|unclean|stale --format
ceph pg dump_stuck unclean
ceph pg dump_stuck inactive
ceph pg dump_stuck stale
Inactive (不活跃)归置组不能处理读写,因为它们在等待一个有最新数据的 OSD 复活且进入集群。
Unclean (不干净)归置组含有复制数未达到期望数量的对象,它们应该在恢复中。
Stale (不新鲜)归置组处于未知状态:存储它们的 OSD 有段时间没向监视器报告了(由 mon_osd_report_timeout 配置)。
可用格式有 plain (默认)和 json 。阀值定义的是,归置组被认为卡住前等待的最小时间(默认 300 秒)
显示一个集群中的所有的pg统计
ceph pg dump --format plain
恢复一个丢失的pg
如果集群丢了一个或多个对象,而且必须放弃搜索这些数据,你就要把未找到的对象标记为丢失( lost )。
如果所有可能的位置都查询过了,而仍找不到这些对象,你也许得放弃它们了。这可能是罕见的失败组合导致的,集群在写入完成前,未能得知写入是否已执行。
当前只支持 revert 选项,它使得回滚到对象的前一个版本(如果它是新对象)或完全忽略它。要把 unfound 对象标记为 lost ,执行命令:
ceph pg {pg-id} mark_unfound_lost revert|delete
查看某个PG内分布的数据状态,具体状态可以使用选项过滤输出
ceph pg ls {} {active|clean|down|replay|splitting|scrubbing|scrubq|degraded|inconsistent|peering|repair|recovering|backfill_wait|incomplete|stale|remapped|deep_scrub|backfill|
backfill_toofull|recovery_wait|undersized [active|clean|down|replay|splitting|scrubbing|scrubq|degraded|inconsistent|peering|repair|recovering|backfill_wait|incomplete|stale|remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|undersized…]} : list pg with specific pool, osd, state
实例如下:
pg号 过滤输出的状态
ceph pg ls 1 clean
查询osd 包含pg 的信息,过滤输出pg的状态信息
pg ls-by-osd <osdname (id|osd.id)> list pg on osd [osd]
{} {active|clean|down|replay|splitting|scrubbing|scrubq|degraded|
inconsistent|peering|repair|recovering| backfill_wait|incomplete|stale|remapped|deep_scrub|backfill|backfill_toofull|recovery_wait|undersized[active|clean|down|replay|splitting|
scrubbing|scrubq|degraded|inconsistent| peering|repair|recovering|backfill_ wait|incomplete|stale|remapped|deep_scrub|backfill|backfill_toofull|recovery_wait|undersized…]}
实例如下:
ceph pg ls-by-osd osd.5
查询pool包含pg 的信息,过滤输出pg的状态信息
ceph pg ls-by-pool poolname 选项
ceph pg ls-by-pool {active|clean| down|replay|splitting|scrubbing|scrubq| degraded|inconsistent|peering|repair| recovering|backfill_wait|incomplete| stale|remapped|deep_scrub|backfill|
backfill_toofull|recovery_wait| undersized [active|clean|down|replay| splitting|scrubbing|scrubq|degraded| inconsistent|peering|repair|recovering| backfill_wait|incomplete|stale| remapped|deep_scrub|backfill|backfill_
实例如下:
ceph pg ls-by-pool test
查询某个osd状态为 primary pg ,可以根据需要过滤状态
pg ls-by-primary <osdname (id|osd.id)> {} {active|clean|down|replay|splitting|scrubbing|scrubq|degraded|inconsistent|peering|repair|recovering|backfill_wait|incomplete|stale|remapped|deep_scrub|backfill|
backfill_toofull|recovery_wait|undersized [active|clean|down|replay|splitting|scrubbing|scrubq|degraded|inconsistent|peering|repair|recovering|backfill_wait|incomplete|stale|remapped|deep_scrub|backfill|
backfill_toofull|recovery_wait|undersized…]} : list pg with primary = [osd]
实例如下:
osd号 过滤输出的状态
ceph pg ls-by-primary osd.3 clean
rbd命令相关
在test池中创建一个命名为kjh的10000M的镜像
rbd create -p test --size 10000 kjh
查看ceph中一个pool里的所有镜像
rbd ls test
kjh
查看新建的镜像的信息
rbd -p test info kjh
查看ceph pool中一个镜像的信息
rbd info -p test --image kjh
rbd image ‘kjh’:
size 1000 MB in 250 objects
order 22 (4096 kB objects)
block_name_prefix: rb.0.92bd.74b0dc51
format: 1
删除一个镜像
rbd rm -p test kjh
调整一个镜像的尺寸
rbd resize -p test --size 20000 kjh
rbd -p test info kjh #调整后的镜像大小
rbd image ‘kjh’:
size 2000 MB in 500 objects
order 22 (4096 kB objects)
block_name_prefix: rb.0.92c1.74b0dc51
format: 1
rbd pool 快照功能测试
新建个pool叫’ptmindpool’同时在下面创建一个’kjhimage’
ceph osd pool create ptmindpool 256 256
pool ‘ptmindpool’ created
创建镜像
rbd create kjhimage --size 1024 --pool ptmindpool
查看镜像
rbd --pool ptmindpool ls
kjhimage
创建snap,快照名字叫’snapkjhimage’
rbd snap create ptmindpool/kjhimage@snapkjhimage
查看kjhimage的snap
rbd snap ls ptmindpool/kjhimage
SNAPID NAME SIZE
2 snapkjhimage 1024 MB
回滚快照,
rbd snap rollback ptmindpool/kjhimage@snapkjhimage
删除snap 删除snap报(rbd: snapshot ‘snapshot-xxxx’ is protected from removal.)写保护 ,使用 rbd snap unprotect volumes/snapshot-xxx’ 解锁,然后再删除
rbd snap rm ptmindpool/kjhimage@snapkjhimage
删除kjhimage的全部snapshot
rbd snap purge ptmindpool/kjhimage
把ceph pool中的一个镜像导出
导出镜像
rbd export -p ptmindpool --image kjhimage /tmp/kjhimage.img
Exporting image: 100% complete…done.
验证查看导出文件
l /tmp/kjhimage.img
-rw-r–r-- 1 root root 1073741824 Sep 24 23:15 /tmp/kjhimage.img
把一个镜像导入ceph中
rbd import /tmp/kjhimage.img -p ptmindpool --image importmyimage1
Importing image: 100% complete…done
验证查看导入镜像文件
rbd -pptmindpool ls
importmyimage1
常见问题
-
安装ceph慢
解决方法: 直接在每个节点上配置yum源并手动安装ceph -
重启ceph无法正常运行
查看OSD磁盘是否正常挂载. 注意将OSD设置自动挂载 -
重新启动ceph后集群警告PG过多
通过检查发现, PG确实超过了300
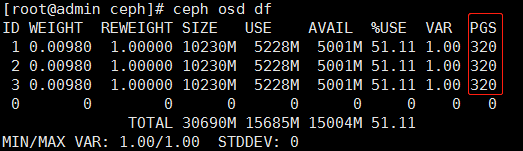
这300是怎么来的呢?通过查阅官方资料发现这个300是由参数mon_pg_warn_max_per_osd设定的,其默认值为300.

解决方法:
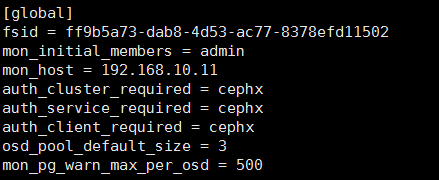
1). 修改ceph.conf文件,将mon_pg_warn_max_per_osd重新设置一个值
[root@admin ceph]# vim ceph.conf
2). 将修改push到集群中其他节点
[root@admin ceph]# ceph-deploy --overwrite-conf config push node{1…3}
3). 重启ceph-mon服务
[root@admin ceph]# systemctl restart ceph-mon@admin
4). 再次查看

- 清理机器上的ceph相关配置:
卸载所有ceph程序:ceph-deploy uninstall [{ceph-node}]
删除ceph相关的安装包:ceph-deploy purge {ceph-node} [{ceph-data}]
删除ceph相关的配置:ceph-deploy purgedata {ceph-node} [{ceph-data}]
删除key:ceph-deploy forgetkeys
卸载ceph-deploy管理:yum -y remove ceph-deploy
ceph-deploy purge ceph-admin ceph-node{1…3}
ceph-deploy purgedata ceph-admin ceph-node{1…3}
ceph-deploy forgetkeys
rm -rf /etc/ceph/*
rm -rf /var/lib/ceph/*
rm -rf /mnt/osdN/*
Reference
- ceph 分布式存储 by 梦里花落知多少

















 3696
3696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









