







hadoop安装手册
步骤一 虚拟机的安装
首先下载最新版本的Linux的iso文件,可以在http://www.linuxdown.net/下载
我选择的是CentOS7.1版本。
然后下载VMWare workstation,VMWare的安装因为比较简单在这里就略过,我这里选择的是##VMwareworkstation_full_12.2.0.1269版本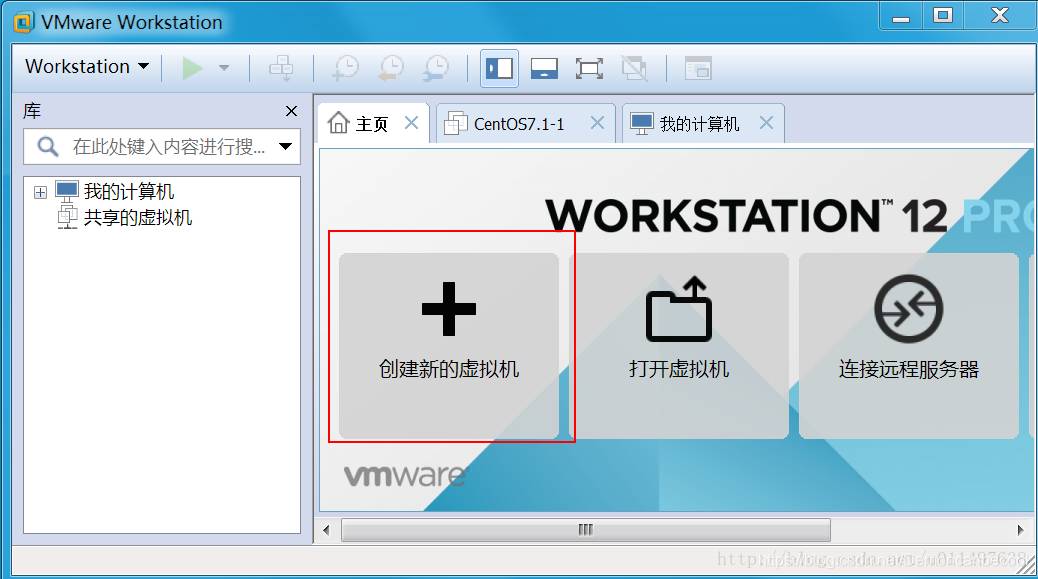

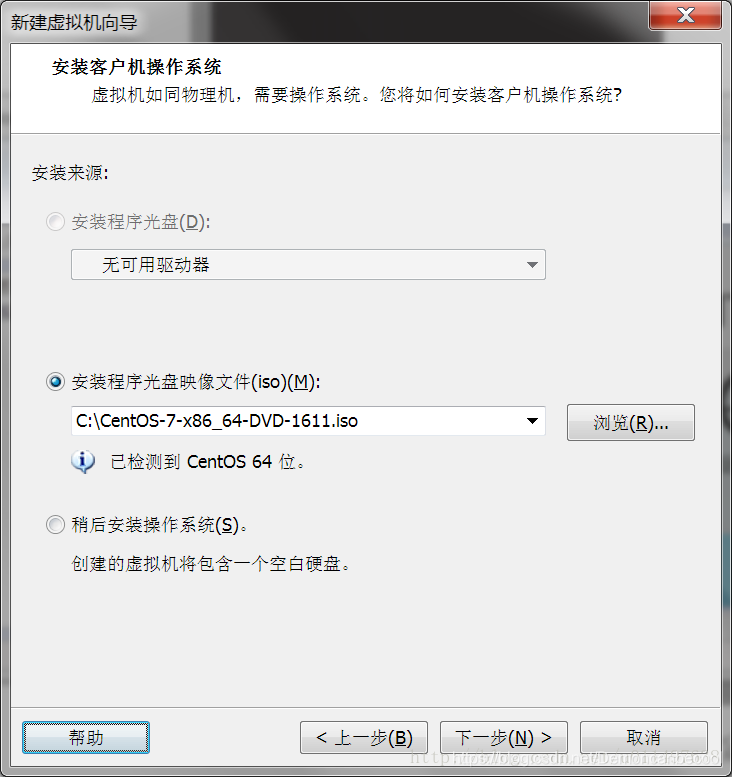
安装完成后系统会要求一些密钥 下面是我分享的可用的一些密钥
5A02H-AU243-TZJ49-GTC7K-3C61N
5A02H-AU243-TZJ49-GTC7K-3C61N
VY1DU-2VXDH-08DVQ-PXZQZ-P2KV8
VF58R-28D9P-0882Z-5GX7G-NPUTF
YG7XR-4GYEJ-4894Y-VFMNZ-YA296
VF5XA-FNDDJ-085GZ-4NXZ9-N20E6
UC5MR-8NE16-H81WY-R7QGV-QG2D8
二、Hadoop基础环境的配置
1前置操作:使我创建的用户获得管理权限
step1:切换到管理员用户
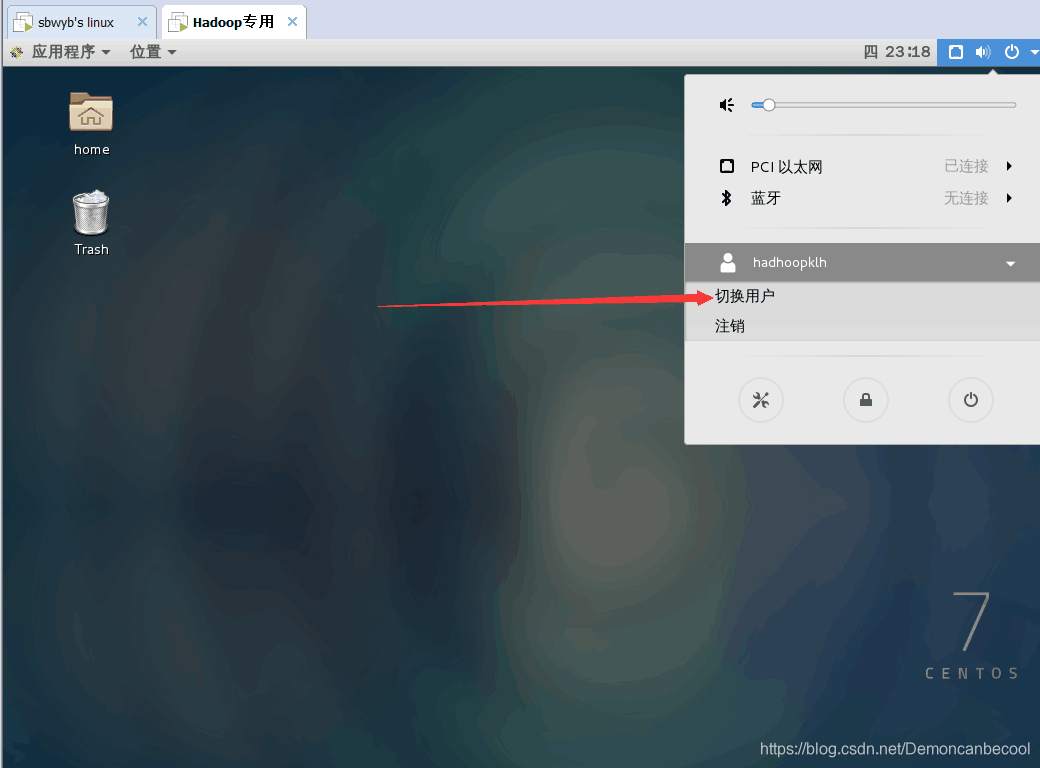
由于我们安装的是LinuxGUI界面,因此我们可以直接手动在GUI界面用户登录界面切换至root用户


(root用户的密码在安装虚拟机时由自己设置)
进入root后

打开终端
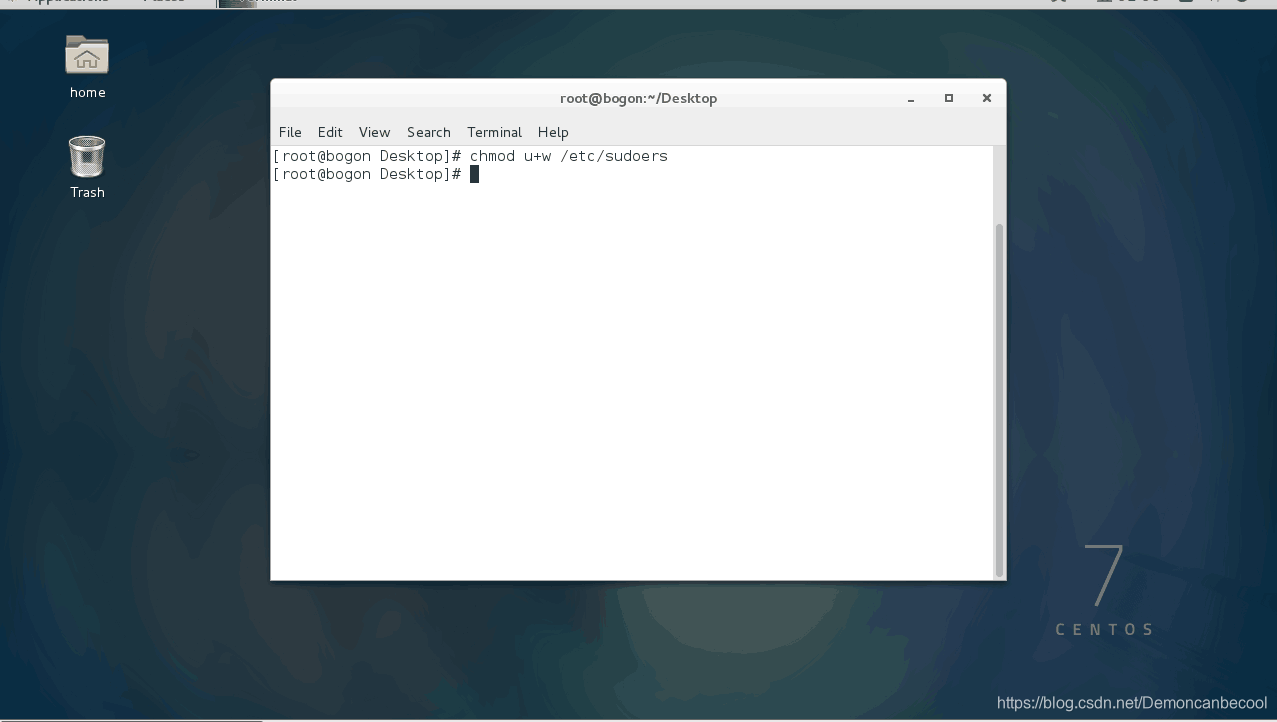
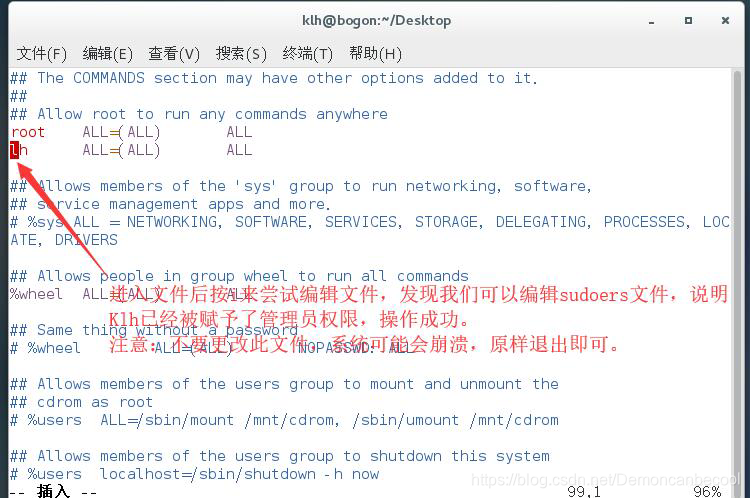
输入chomd u+w /etc/sudoers 此代码是将系统文件sudoers可读 以进行后面的操作
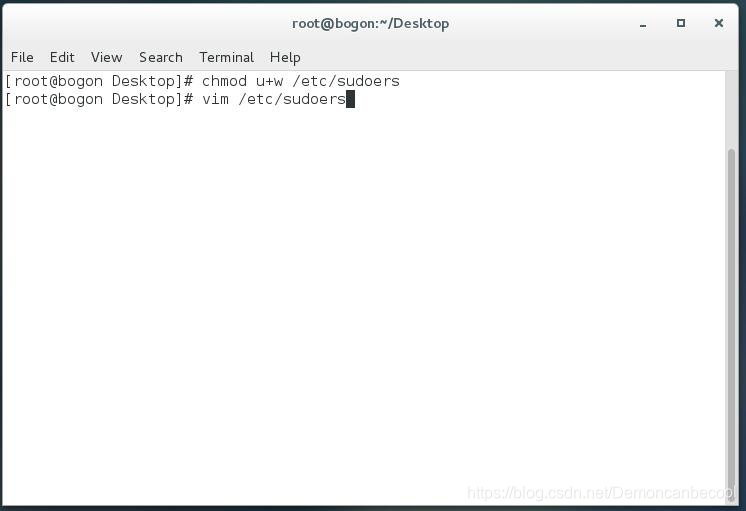
用vim/etc/sudoers 打开sudoers文件 或者用图形界面打开(操作简单,不进行详细说明)
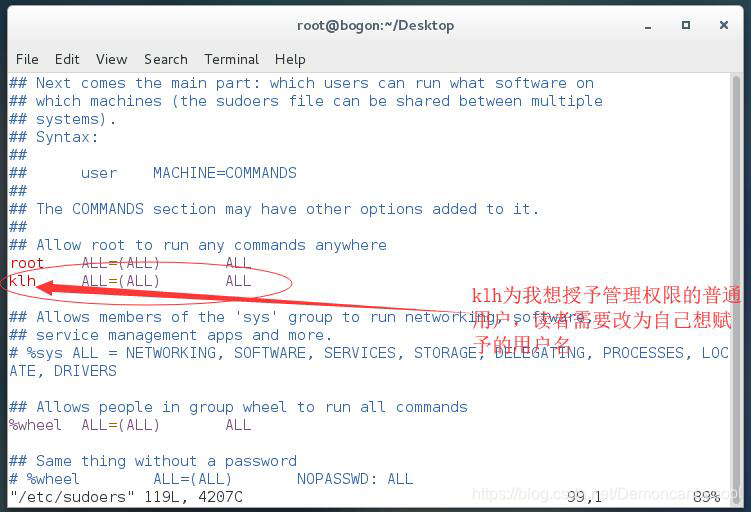
如图所示 找到第98行代码root ALL=(ALL) ALL 复制在下一行,然后将root改为我们想要赋予管理权限的普通用户名称,然后esc+:+wq保存退出
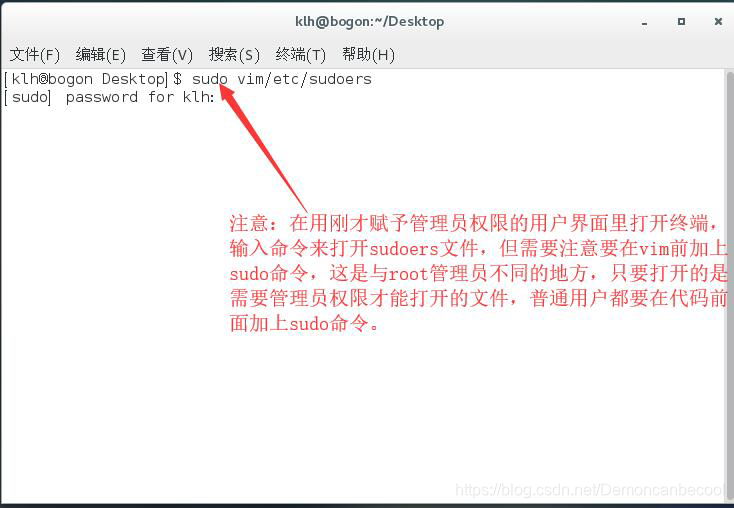
保存完毕后我们退出root用户,登录刚才赋予权限的用户,然后打开终端,输入以下代码
2基础网络环境的配置
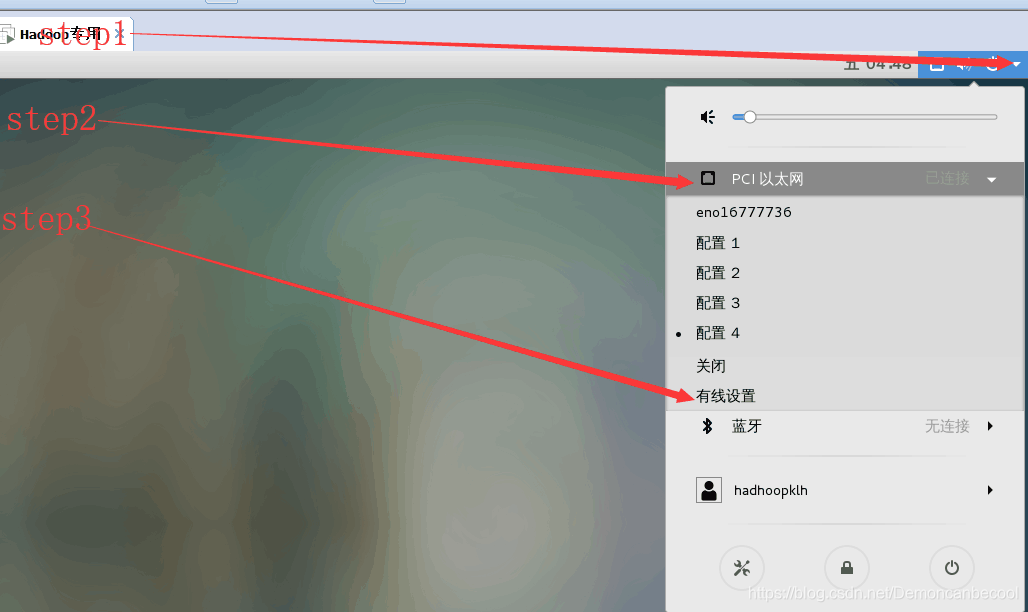
根据以上步骤打开网络设置
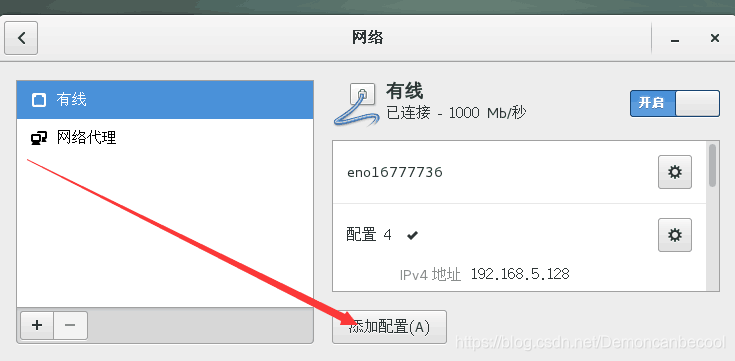
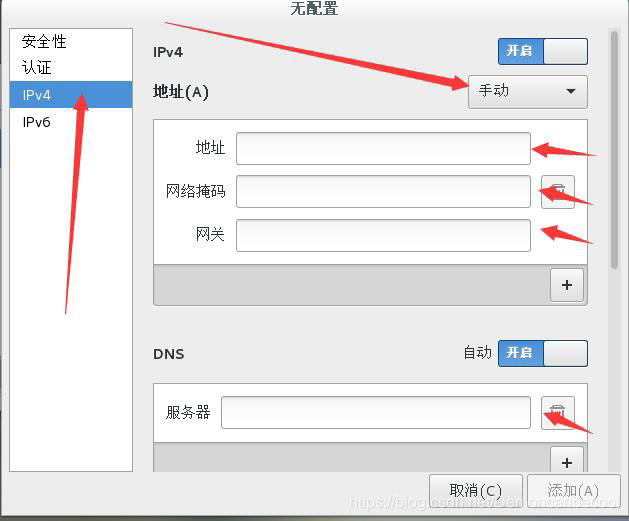 网络地址 网络掩码 网关需要点击虚拟机菜单栏的编辑选项中的虚拟网络编辑器,打开Nat设置,操作如下:
网络地址 网络掩码 网关需要点击虚拟机菜单栏的编辑选项中的虚拟网络编辑器,打开Nat设置,操作如下:
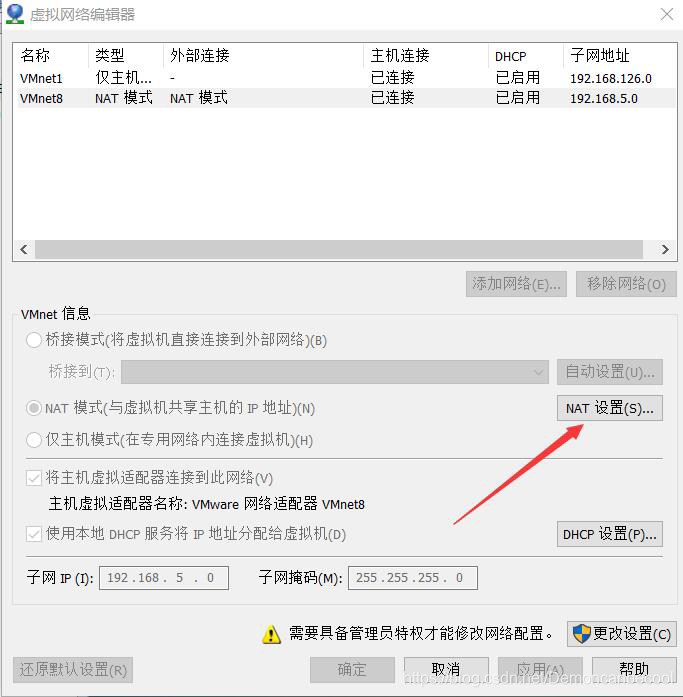
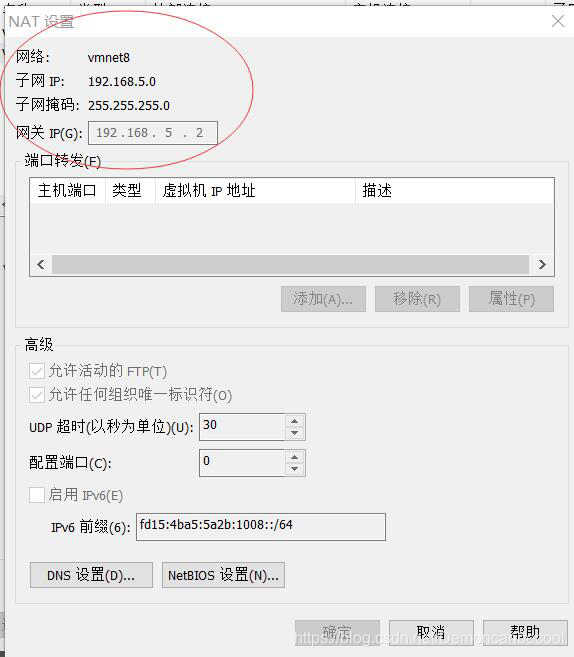 ## 注意:子网IP最后一位不能为0,255,1,2.需要从3~254之间选择
## 注意:子网IP最后一位不能为0,255,1,2.需要从3~254之间选择
子网掩码不变,网关IP不变。DNS可以为8.8.8.8 去某度搜各地的即可。
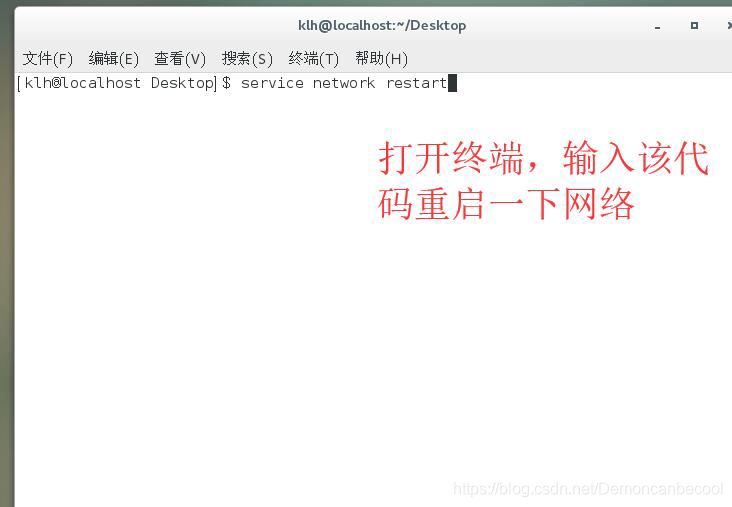
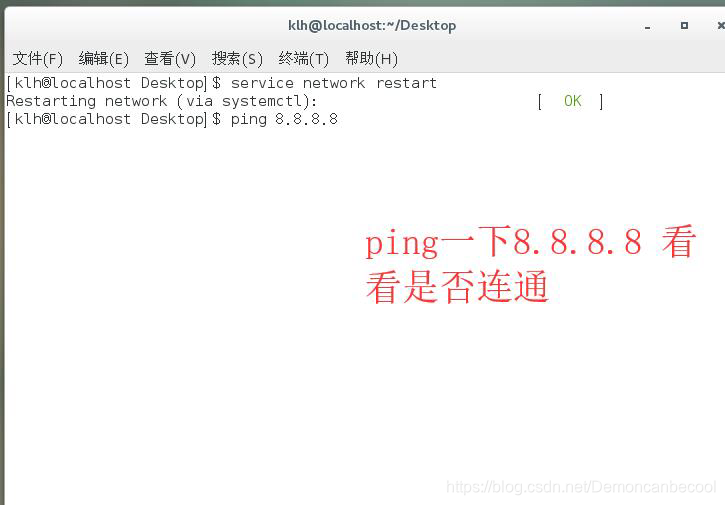

3(配置网络地址与主机名的对应关系)
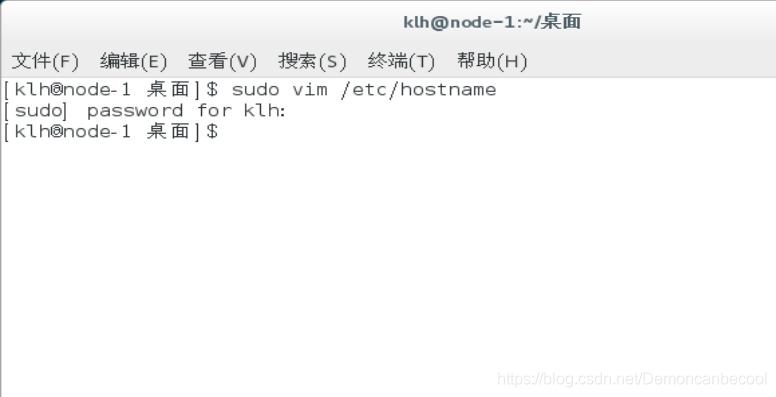
首先在终端里输入
Sudo vim /etc/hostname
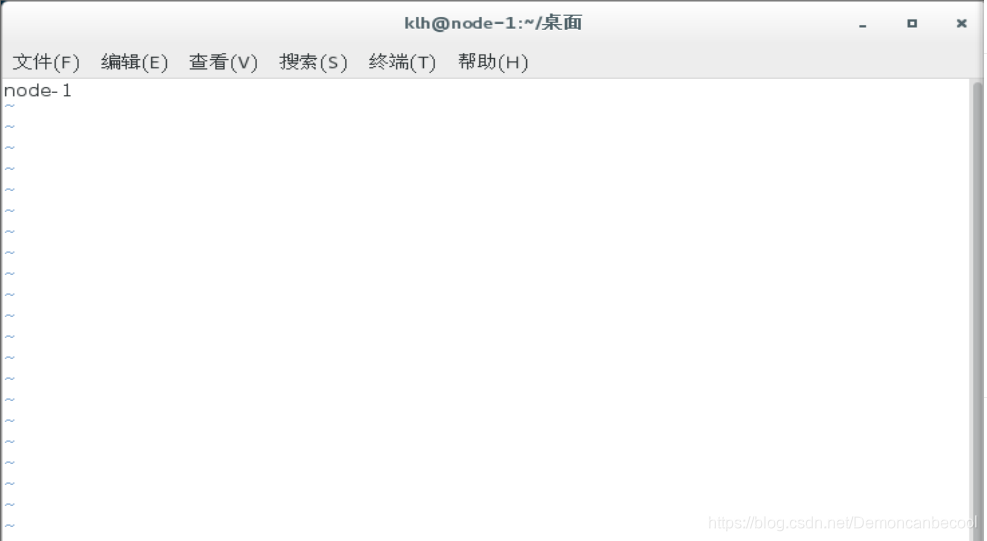
将此文件内容全部删除,更改为你的当前操作主机的主机名
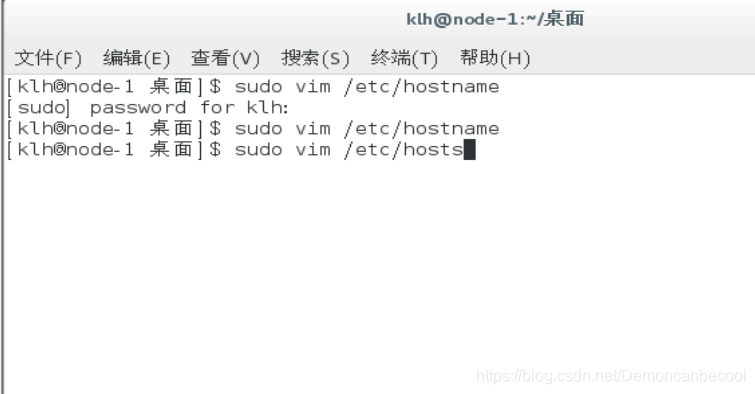
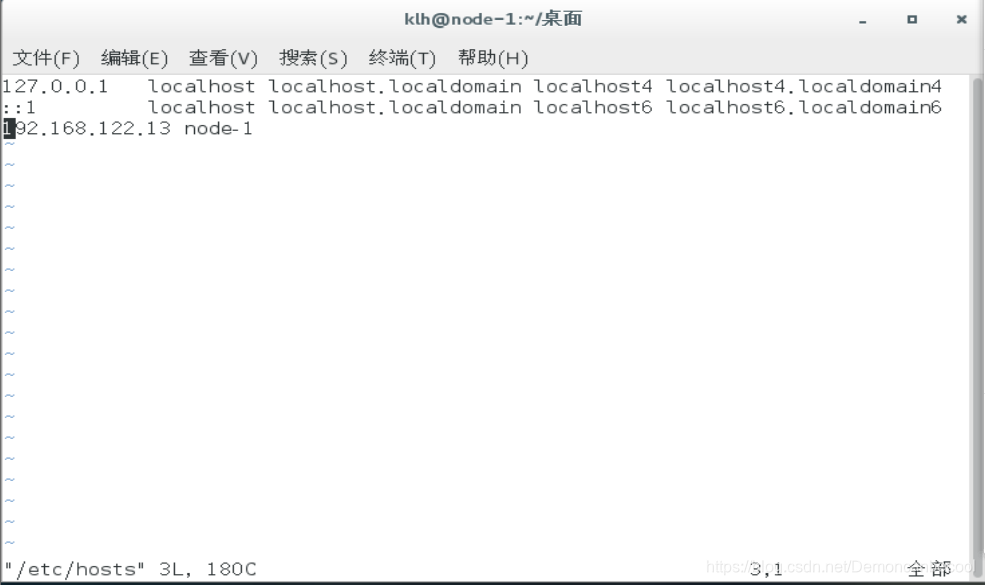
Sudo vim /etc/hosts
在最后新建一行,添加以下内容
IP地址1 主机名1
IP地址2 主机名2
IP地址3 主机名3
如图所示:
 4.1.1.3关闭防火墙
4.1.1.3关闭防火墙
查看防火墙状态
Systemctl status firewalld.service
关闭防火墙
Systemctl strop firewalld.service
查看服务开启启动项列表
Systemctl list-unit-files
设置防火墙开机不自动启动
Systemctl disable firewalld.service
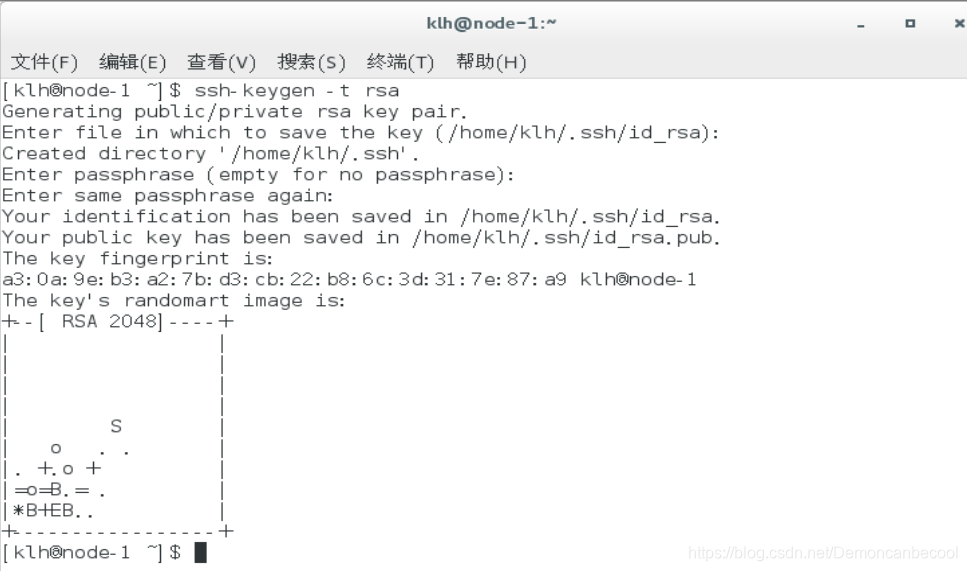
三、免密登陆首先生成公私钥
首先输入Ssh-keygen -t rsa创建公钥
打开用户目录下的.ssh目录
(1)cd
cd .ssh

(2)将公钥文件拷贝成authorized_keys
(3)验证Ssh 本节点主机名,若无需输入密码可直接登录则设置成功

四、jdk安装
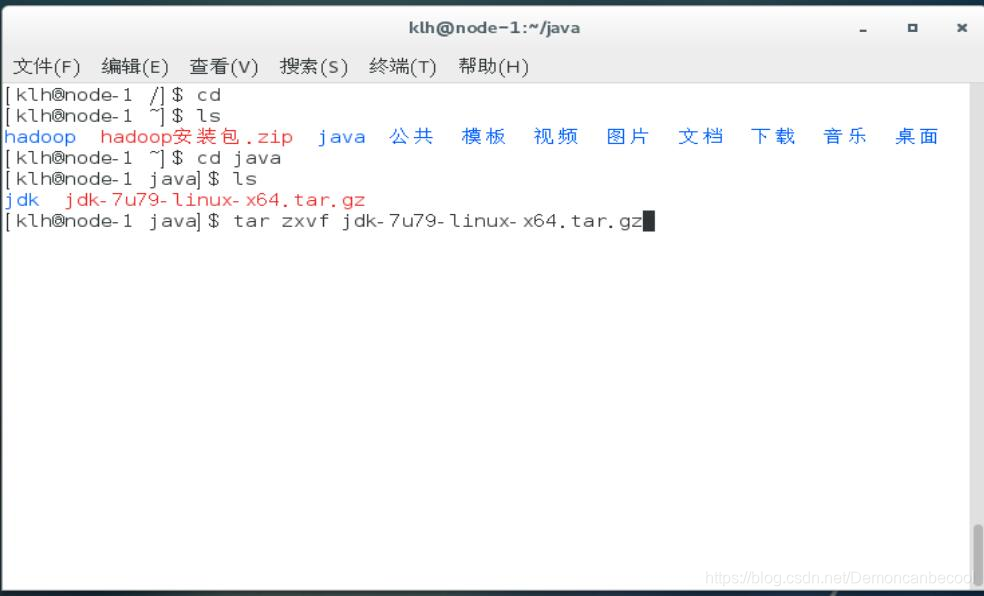
复制jdk文件(.tar.gz格式)到用户目录下
在此目录下新建java目录,将安装包移动到该目录下解压
Tar zxvf 压缩包名
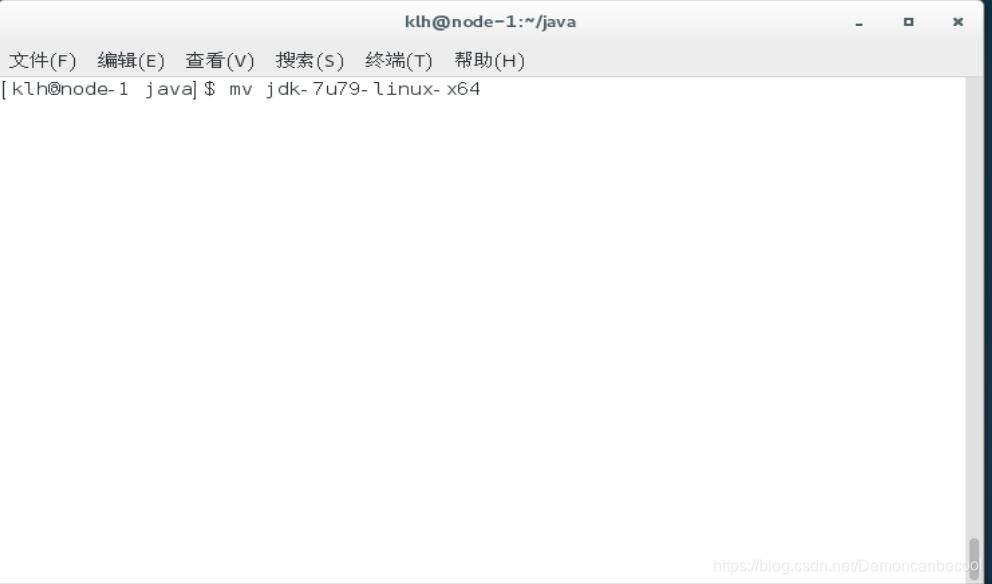
解压后为了方便后期操作,将解压后目录名重命名为jdk(使用mv改名)
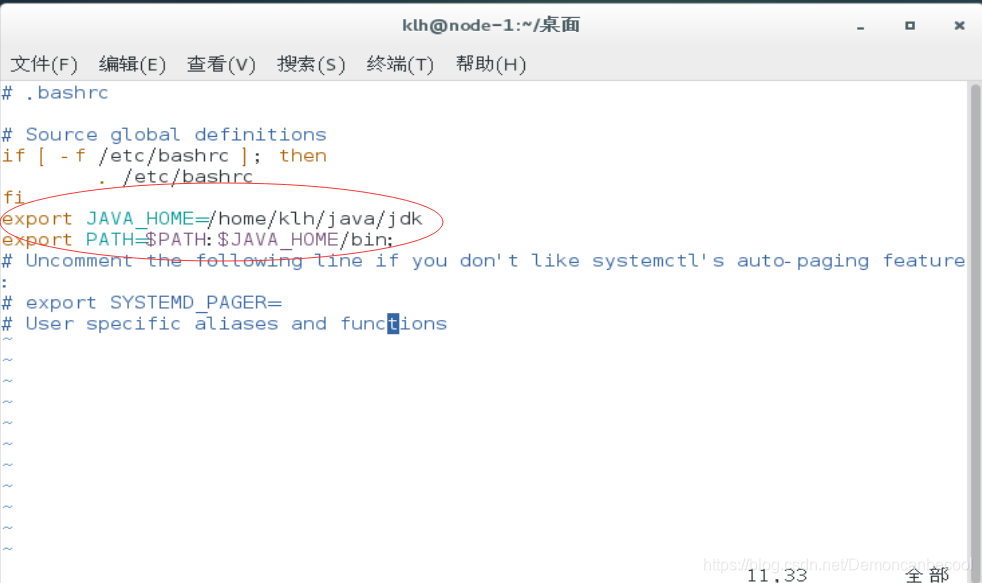
打开并编辑用户目录下的.\bashrc文件
Vim ~/.bashrc
在正文的后面添加以下内容
Export JAVA_HOME=/home/ryan/java/jdk
Export PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin
保存退出
让该文件立即生效
Source ~/.bashrc
卸载已有jdk(可选)
查询已安装包名中包含jdk的
Rpm -qa |grep jdk
卸载方法
Rpm -e 包名 --nodeps(忽略依赖关系)
使用java -version命令验证
如果显示版本号与安装版本号相同,则证明安装成功了

五、hadoop的安装
首先将hadoop安装包复制到用户目录下,新建hadoop目录。将安装包移动到该目录下解压。
将解压完成后的目录(hadoop-2.6.2)改名为hadoop(为了方便)
上述操作同给jdk解压改名,在此不再次说明。
将hadoop根目录下的bin目录和sbin目录路径加入到PATH中
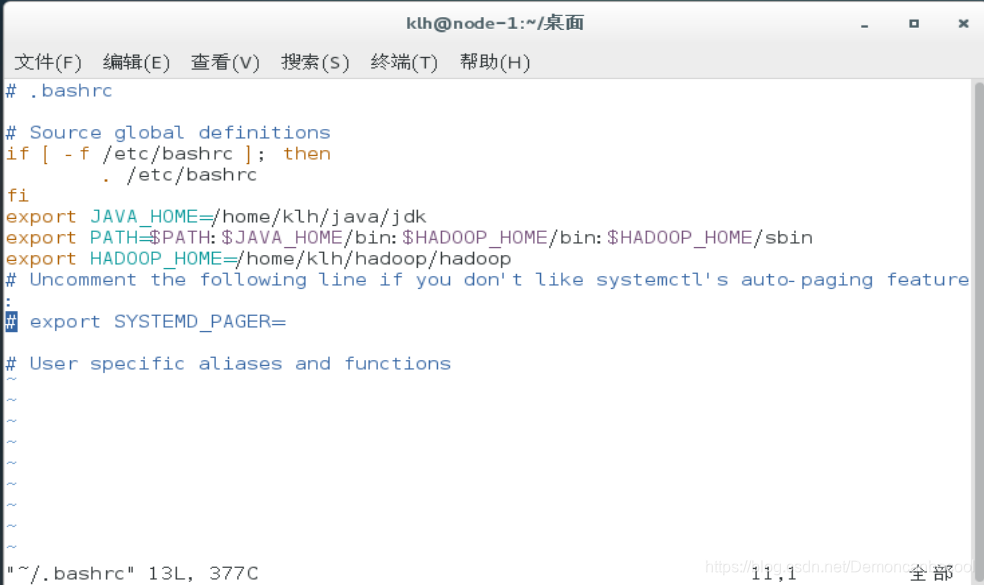
更改~/.bashrc文件如下
export JAVA_HOME=/home/ryan/java/jdk
export HADOOP_HOME=/home/ryan/hadoop/hadoop
export PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin:
H
A
D
O
O
P
H
O
M
E
/
b
i
n
:
HADOOP_HOME/bin:
HADOOPHOME/bin:HADOOP_HOME/sbin
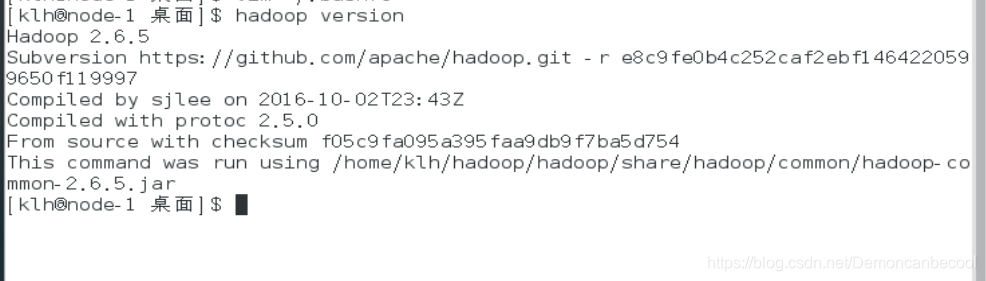
改完后,执行source命令令其立即生效
使用hadoop version验证是否成功
六、hadoop的配置
3.1在$HADOOP_HOME/etc/hadoop/目录下
需要配置以下文件
Hadoop-env.sh
export JAVA_HOME=/home/klh/java/jdk
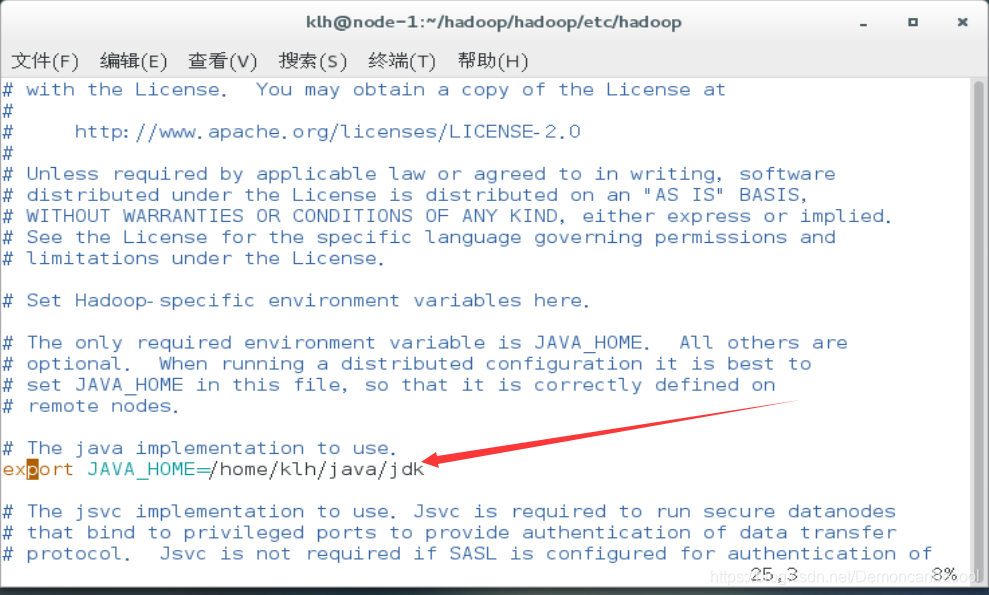
Yarn-env.sh
export JAVA_HOME=/home/klh/java/jdk
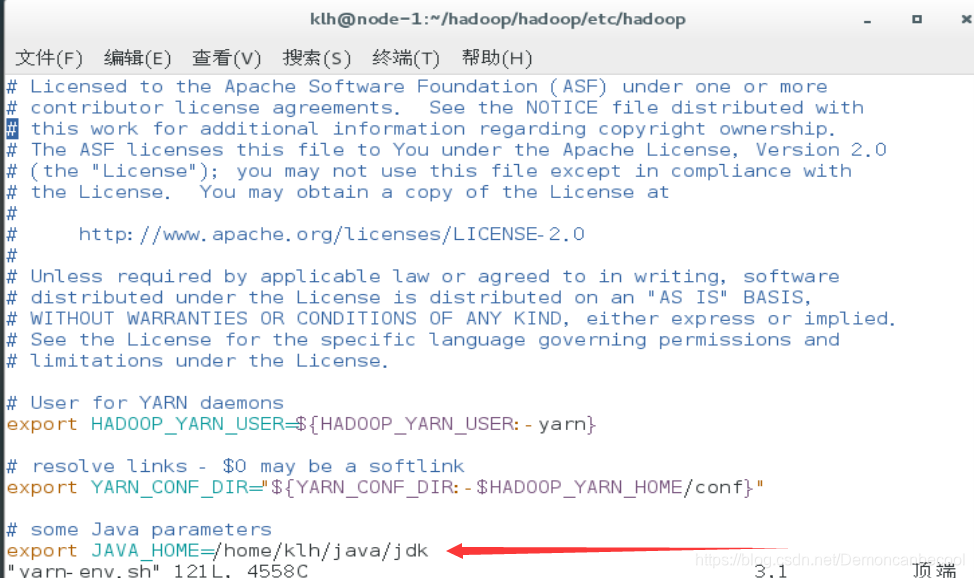
Core-site.xml
在configuration标签中添加以下变量和值
fs.defaultFS
hdfs://node-1:9000
hadoop.tmp.dir
/home/ryan/hadoop/hadoop/tmp
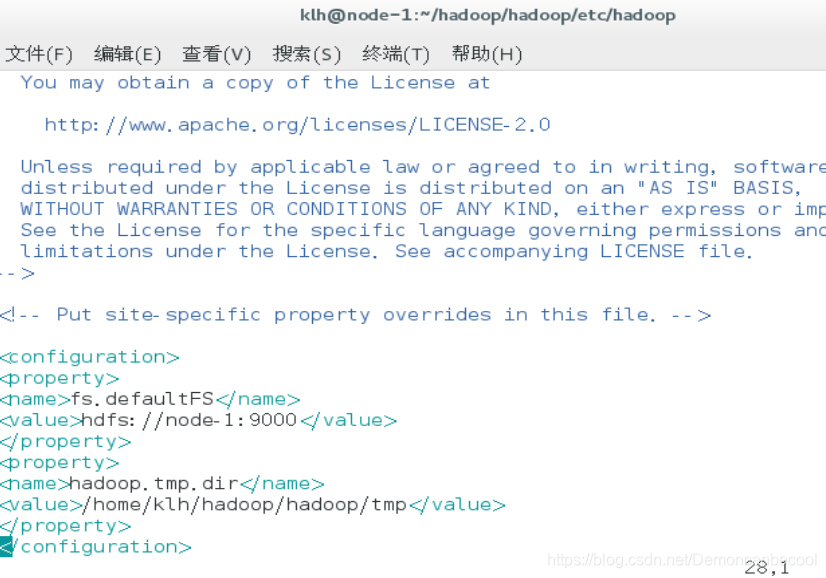
Hdfs-site.xml
(如果不设置该参数,则默认值为3)
dfs.replication
2
(如果不设置该参数,则默认值为
h
a
d
o
o
p
.
t
m
p
.
d
i
r
/
d
f
s
/
n
a
m
e
)
<
n
a
m
e
>
d
f
s
.
n
a
m
e
n
o
d
e
.
n
a
m
e
.
d
i
r
<
/
n
a
m
e
>
<
v
a
l
u
e
>
/
h
o
m
e
/
k
l
h
/
h
a
d
o
o
p
/
h
a
d
o
o
p
/
t
m
p
/
d
f
s
/
n
a
m
e
<
/
v
a
l
u
e
>
<
/
p
r
o
p
e
r
t
y
>
<
p
r
o
p
e
r
t
y
>
(
如
果
不
设
置
该
参
数
,
则
默
认
值
为
hadoop.tmp.dir/dfs/name) <name>dfs.namenode.name.dir</name> <value>/home/klh/hadoop/hadoop/tmp/dfs/name </value> </property> <property>(如果不设置该参数,则默认值为
hadoop.tmp.dir/dfs/name)<name>dfs.namenode.name.dir</name><value>/home/klh/hadoop/hadoop/tmp/dfs/name</value></property><property>(如果不设置该参数,则默认值为hadoop.tmp.dir/dfs/data)
dfs.datanode.data.dir
/home/klh/hadoop/hadoop/tmp/dfs/data
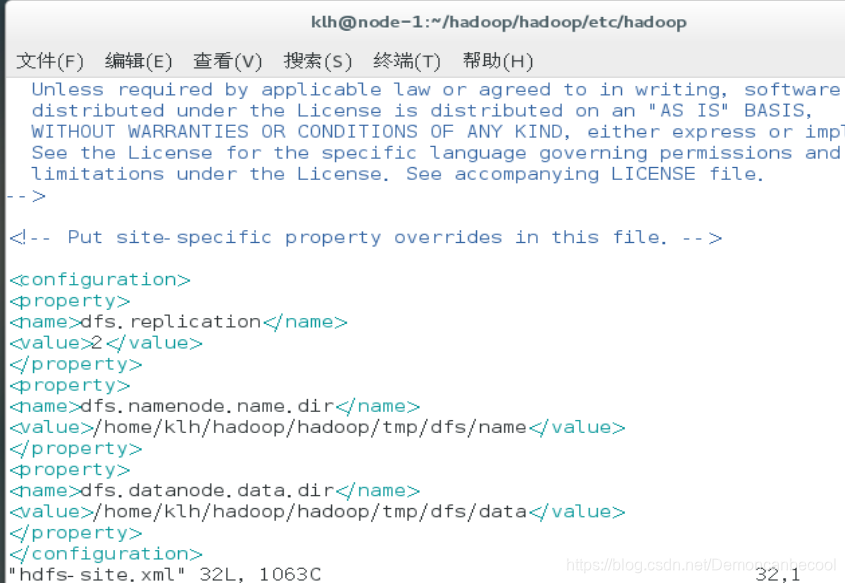
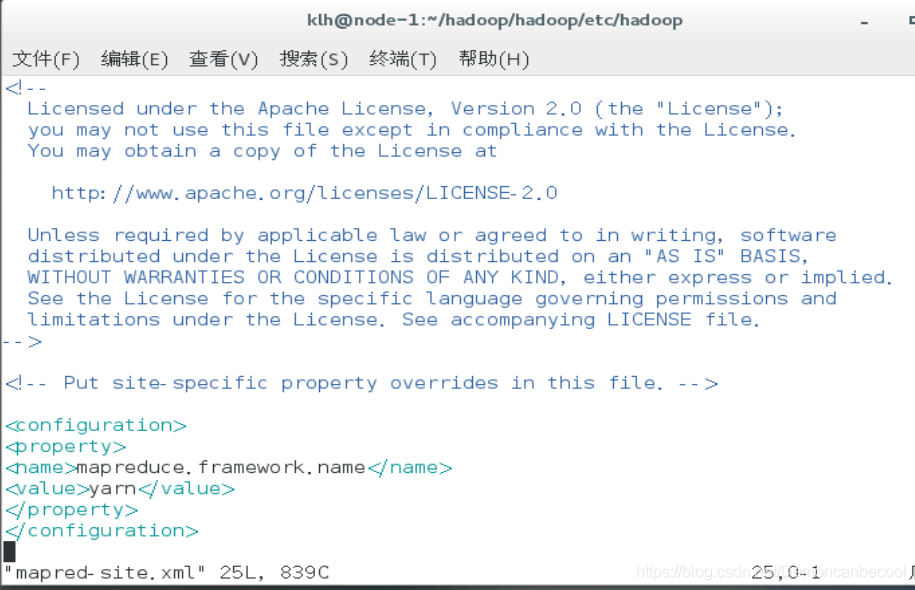
Mapred-site.xml
mapreduce.framework.name
yarn
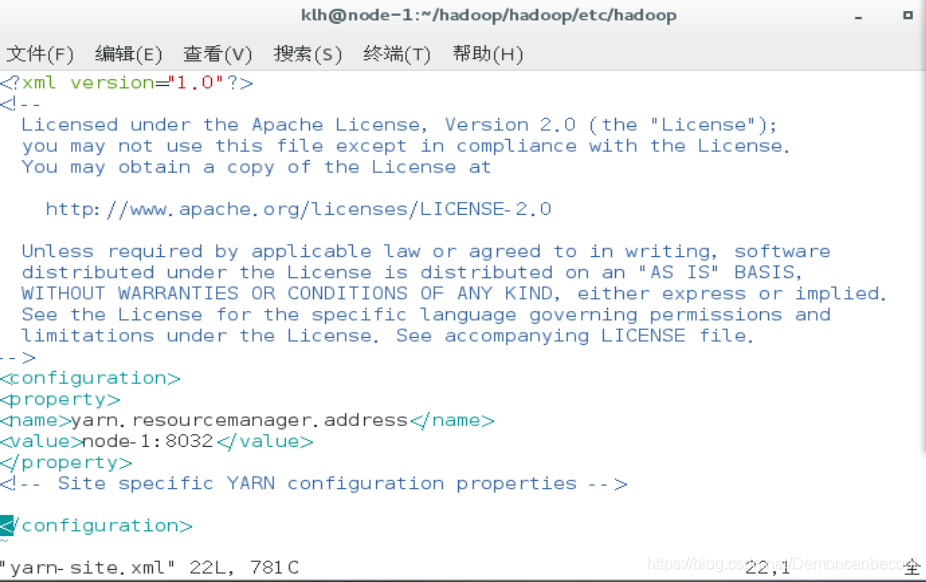
Yarn-site.xml
yarn.resourcemanager.address
rmhostname:8032
Slaves
在此文件中写明所有从节点的节点名,一行一个(如果为伪分布式部署,则默认localhost即可,无需更改)
伪分布式安装:
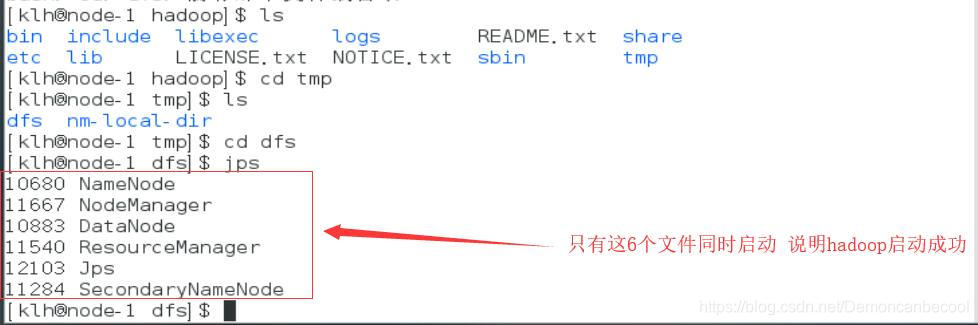
3.2格式化并启动hadoop
格式化代码:
hadoop namenode format
启动代码 :
start-all.sh
3.3根据运行日志定位问题点
 # 伪分布式安装
# 伪分布式安装
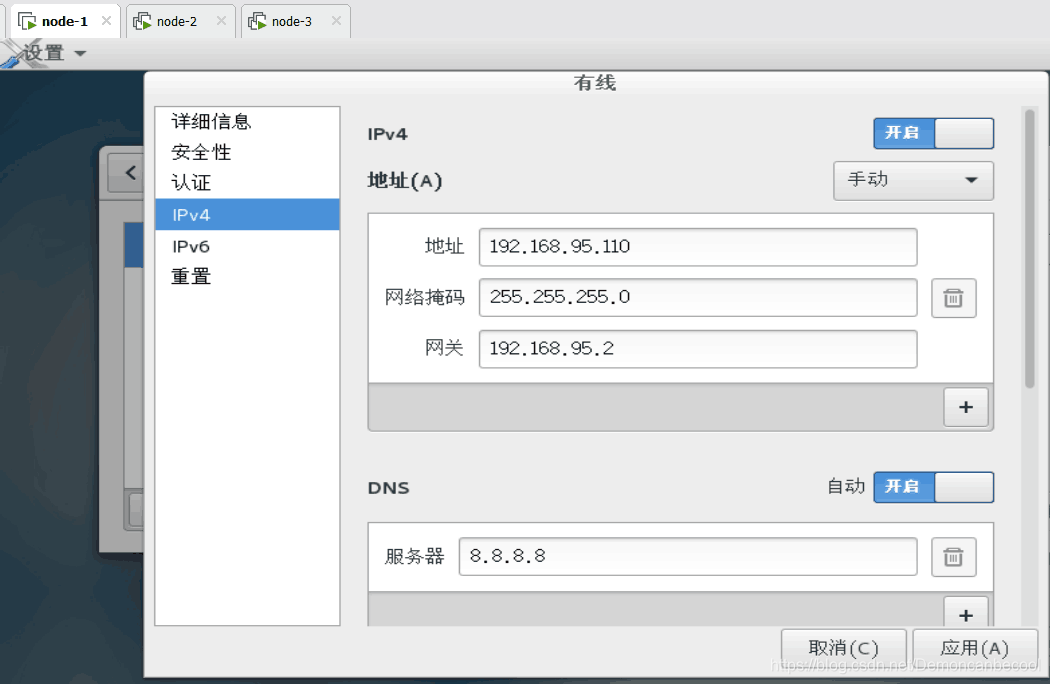
1.克隆两个node-1(主节点)的虚拟机,并分别命名为node-1,node-2
2.进入修改网络设置,为了方便我把node-2,node-3网段最后两位分别写为120,130.
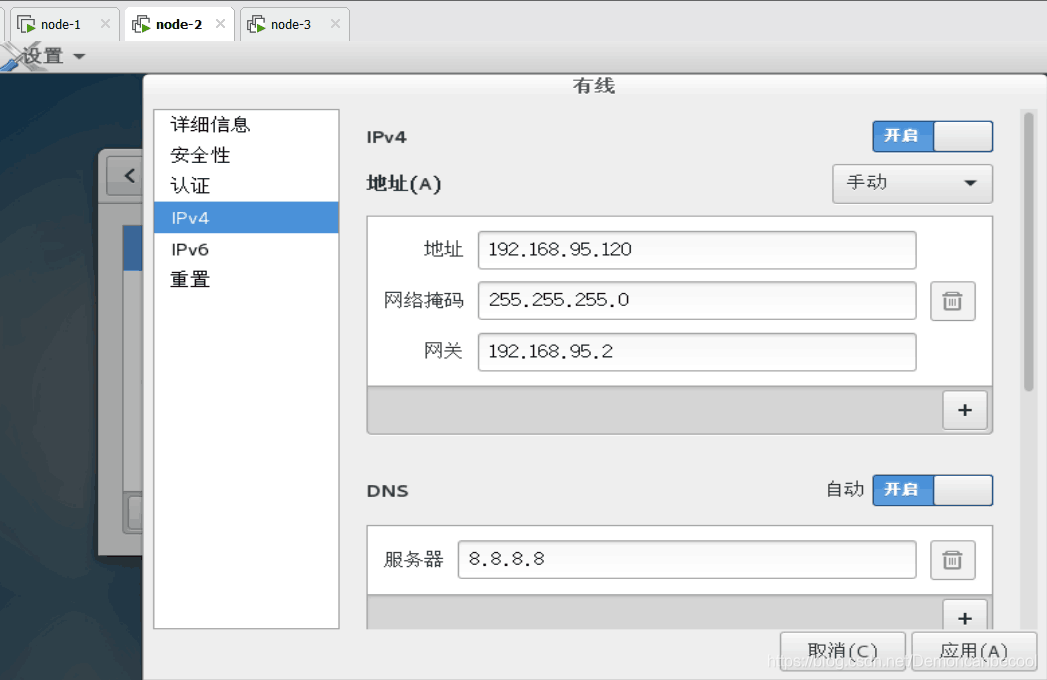
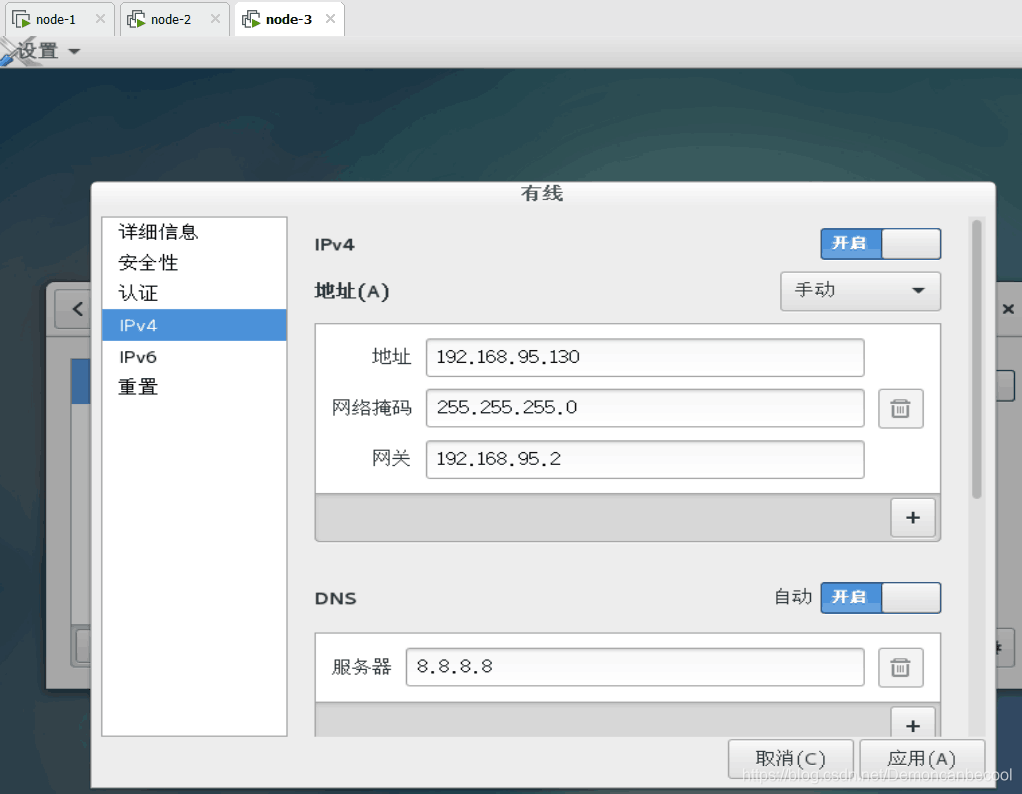 3.进入node-1,2,3的hostname文件作以下更改
3.进入node-1,2,3的hostname文件作以下更改
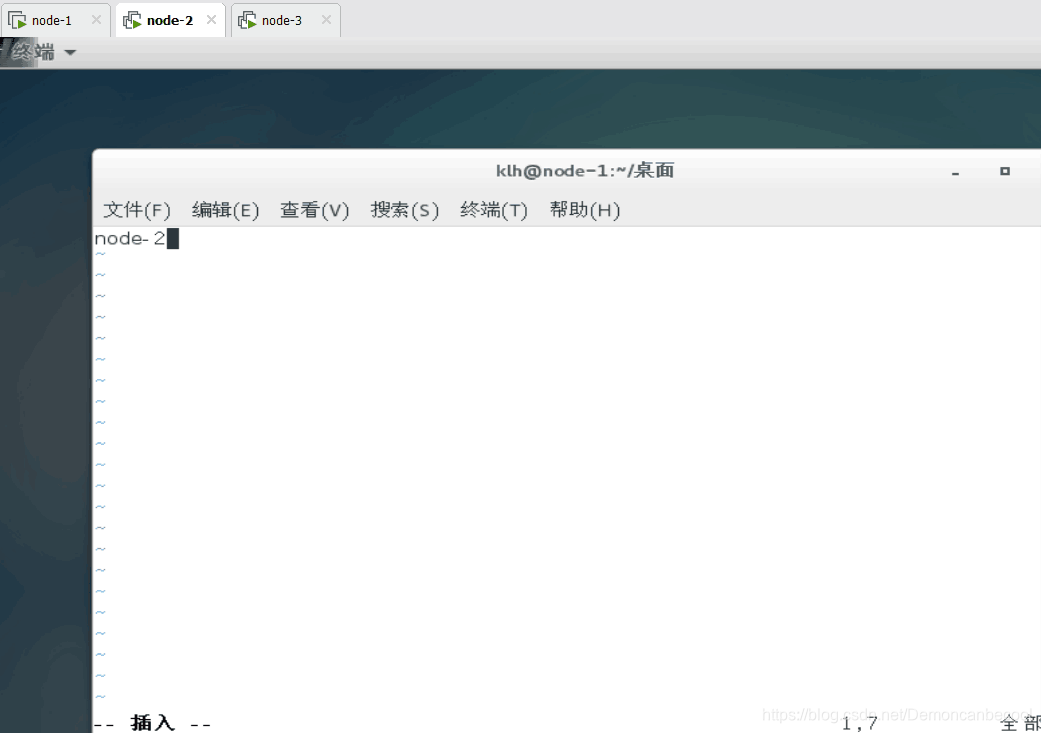
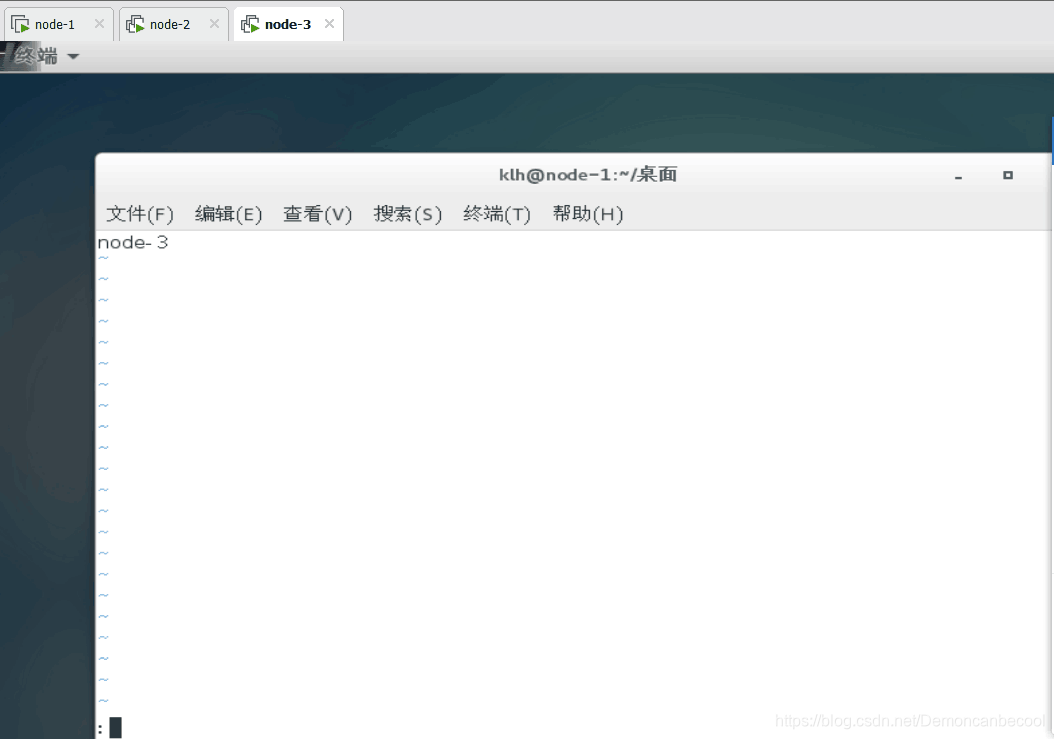
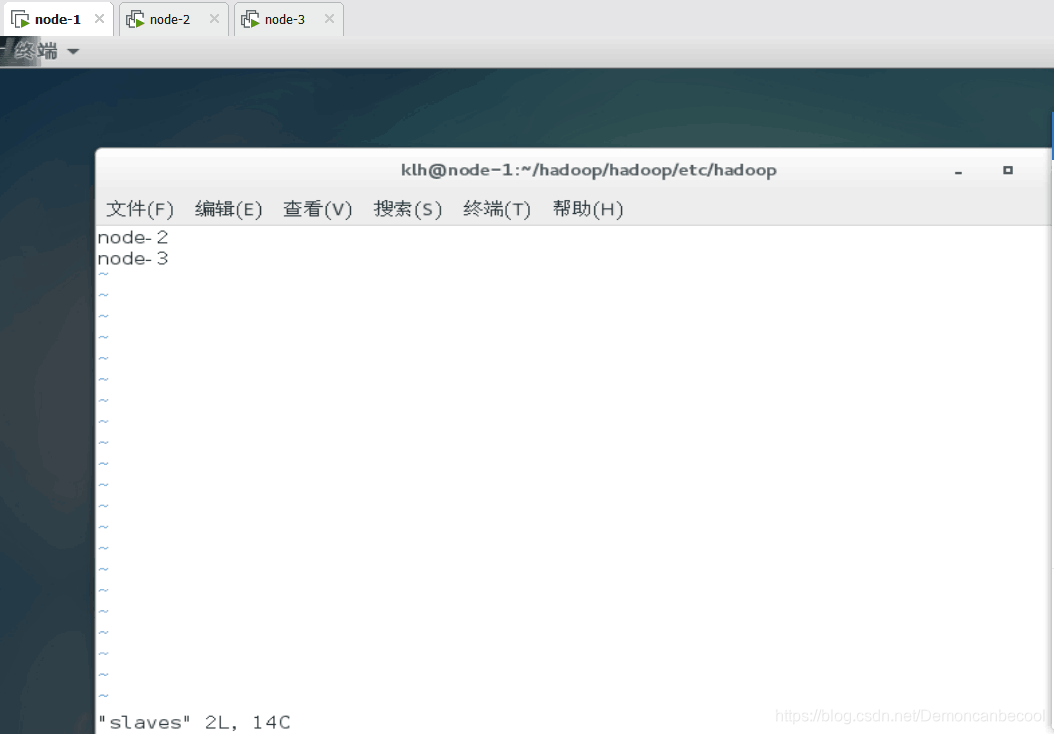 4.再分别进入node-1,2,3进入hosts文件做以下更改
4.再分别进入node-1,2,3进入hosts文件做以下更改
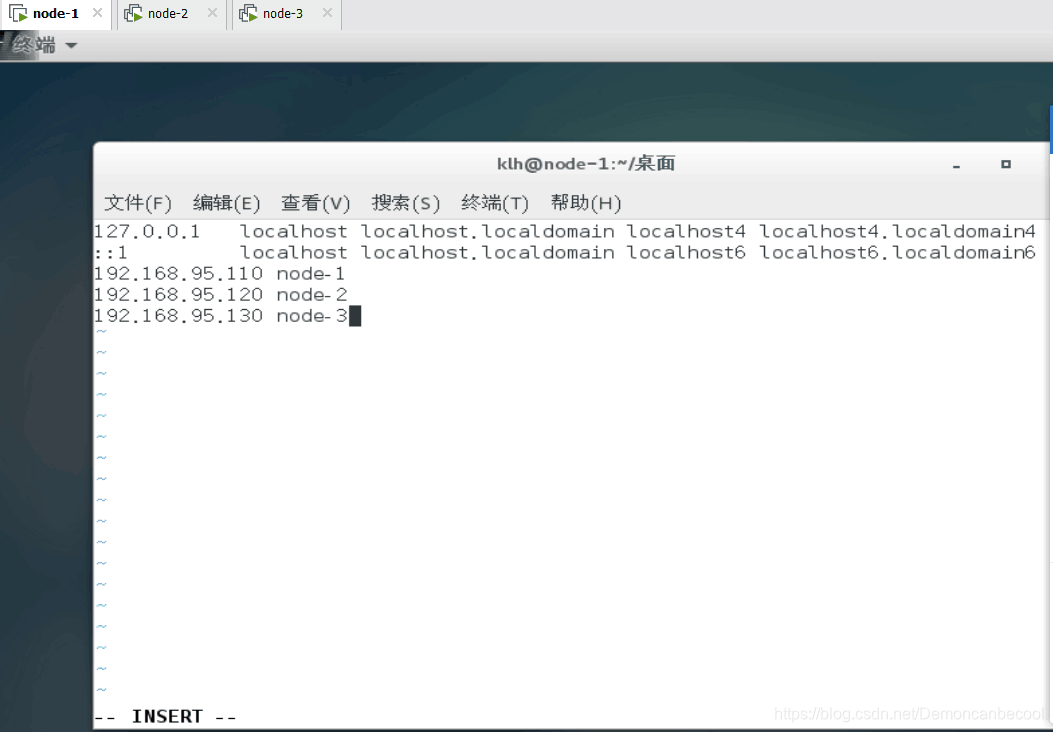
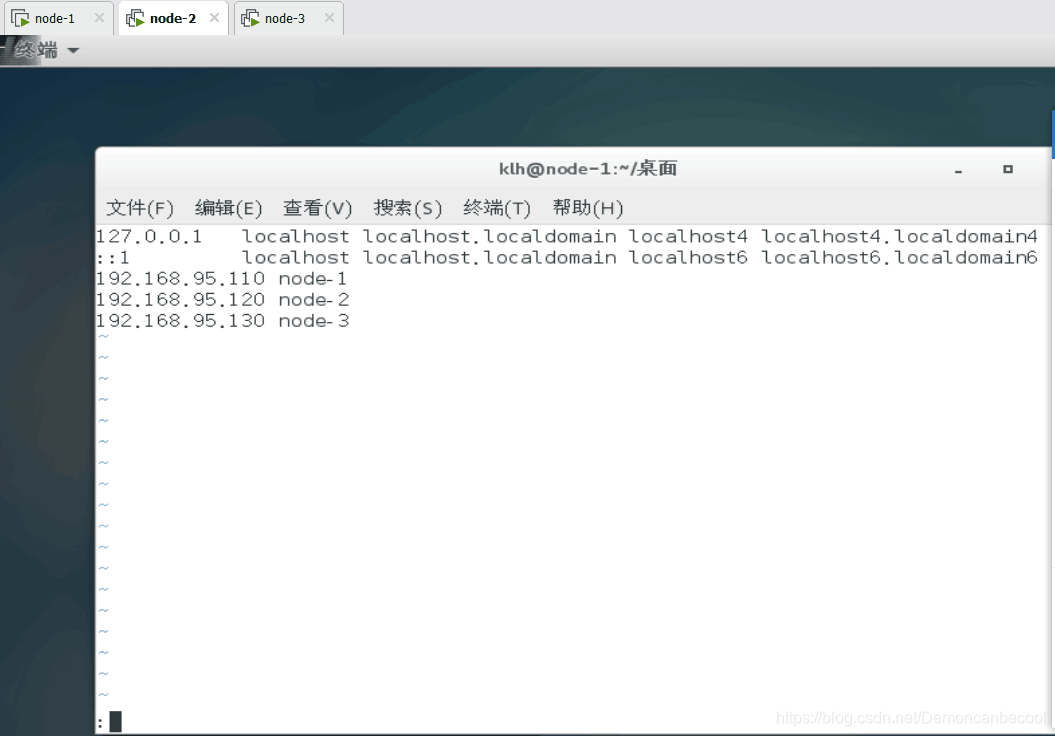
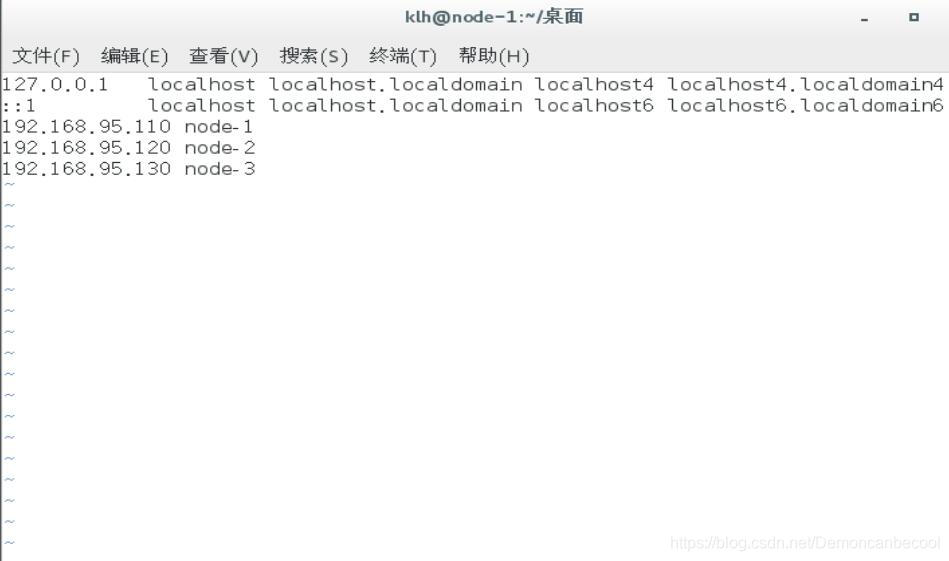 5.生成node-2 node-3的公私钥
5.生成node-2 node-3的公私钥
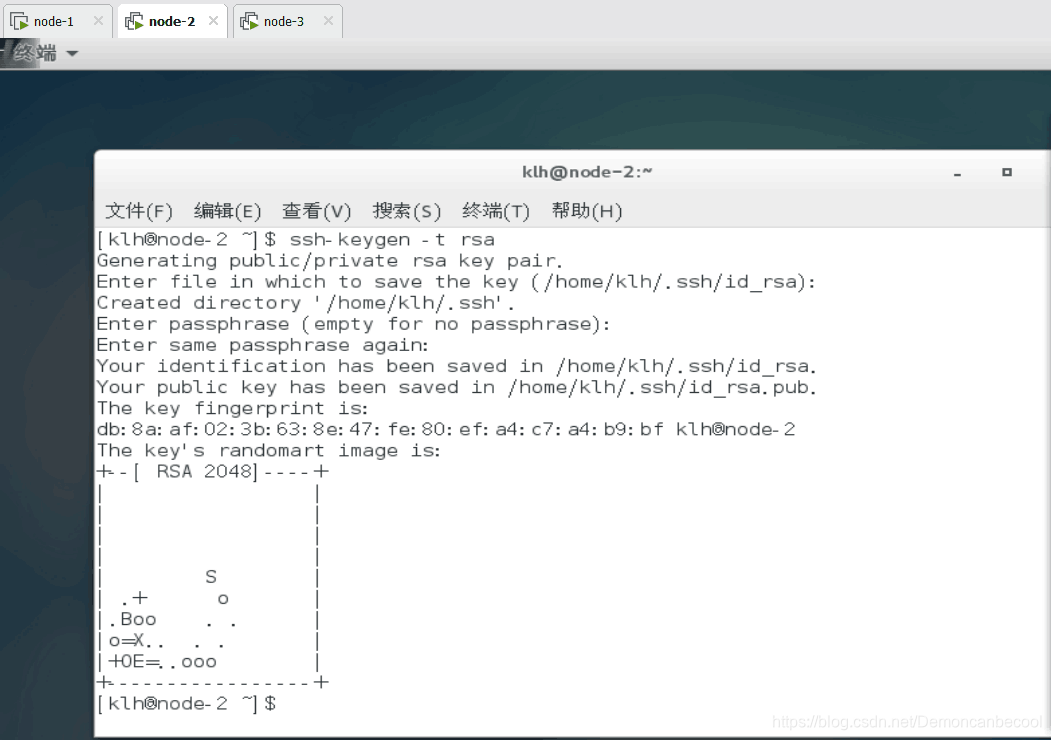

把node-2的公私钥复制到node-1中去
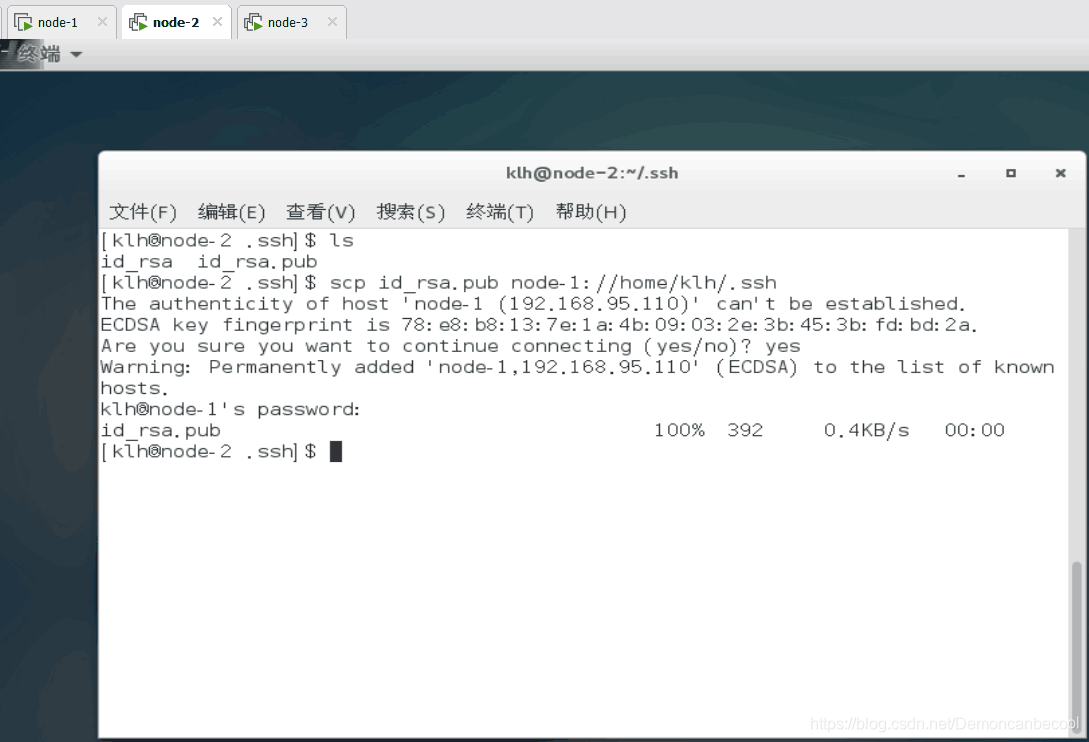
查看是否复制成功
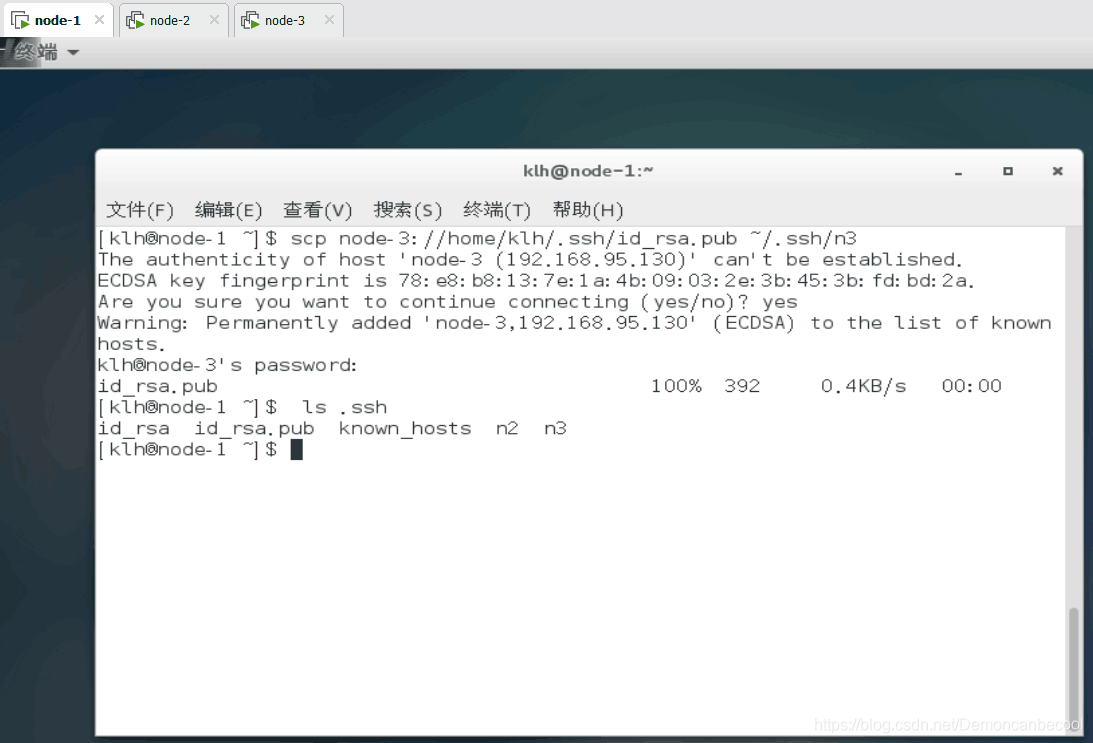
 复制node-3的公私钥到node-1去,并查看是否复制成功。
复制node-3的公私钥到node-1去,并查看是否复制成功。
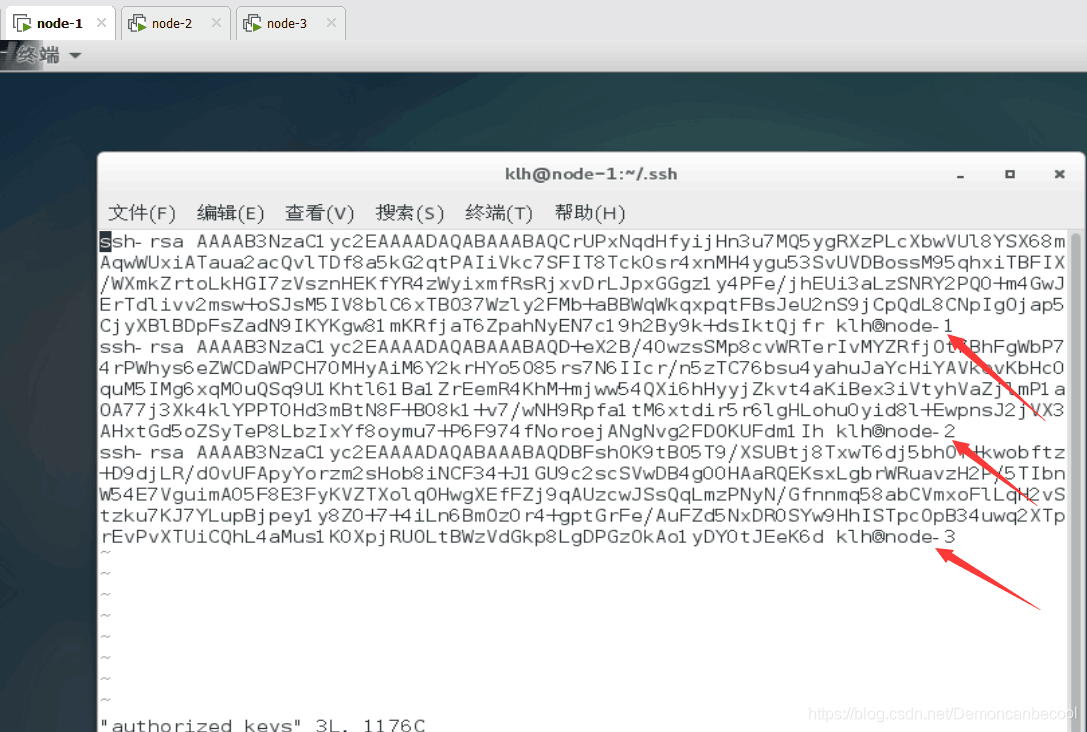
把node-2 node-3的公私钥合并为authorized_keys
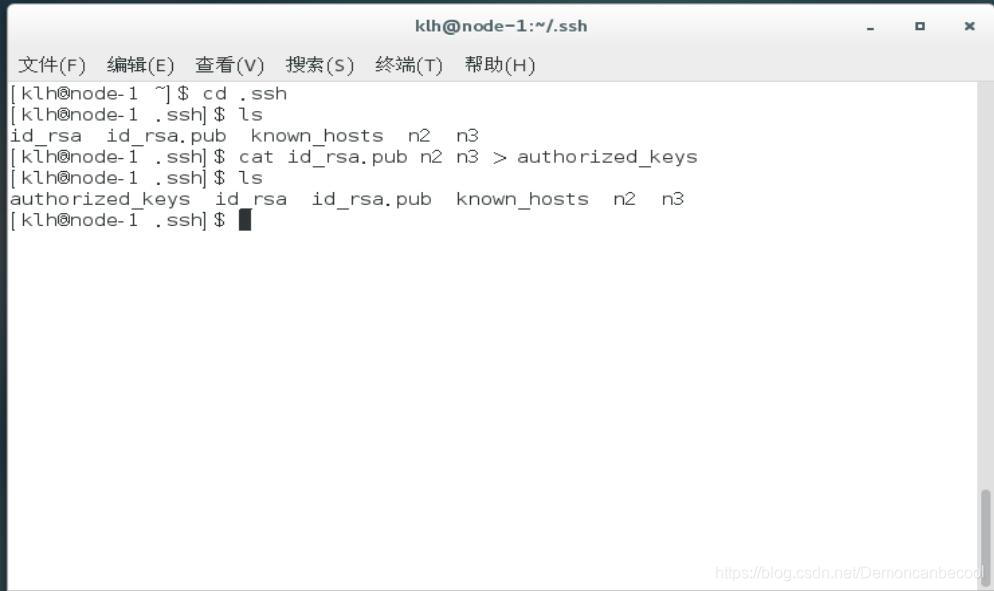
查看是否和并成功 图中箭头所指node-1 node-2 node-3出现了 则成功合并
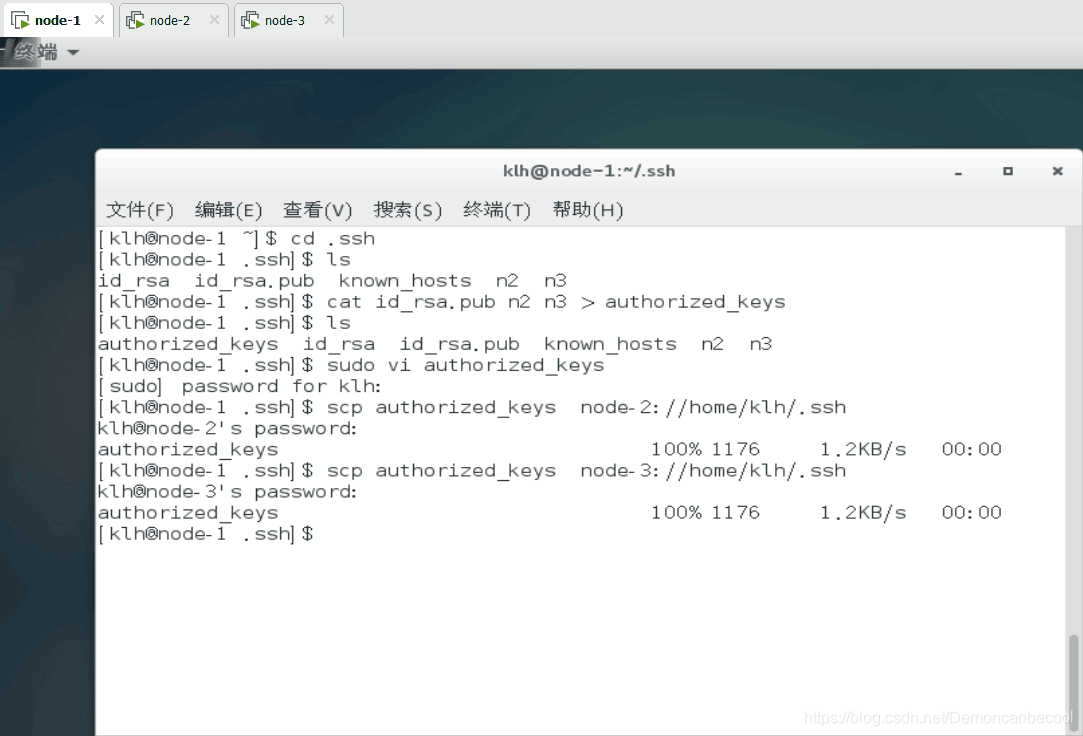
把新生成的authorized_keys 发送给node-2 node-3一人一份 来实现免密登陆
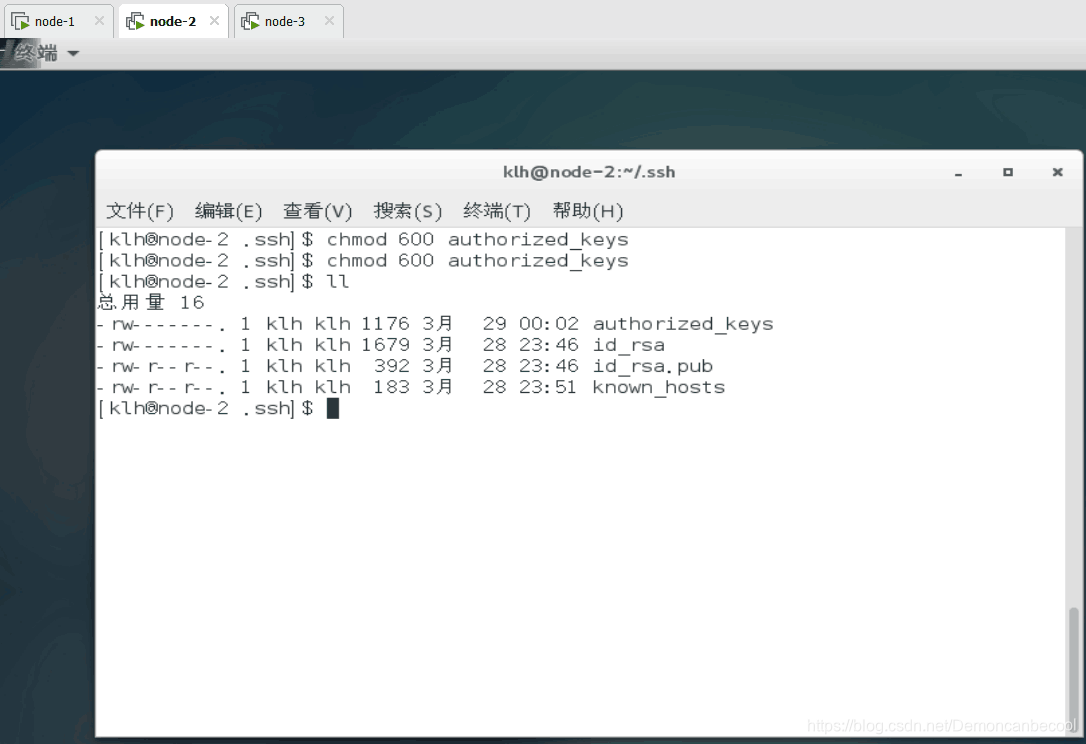
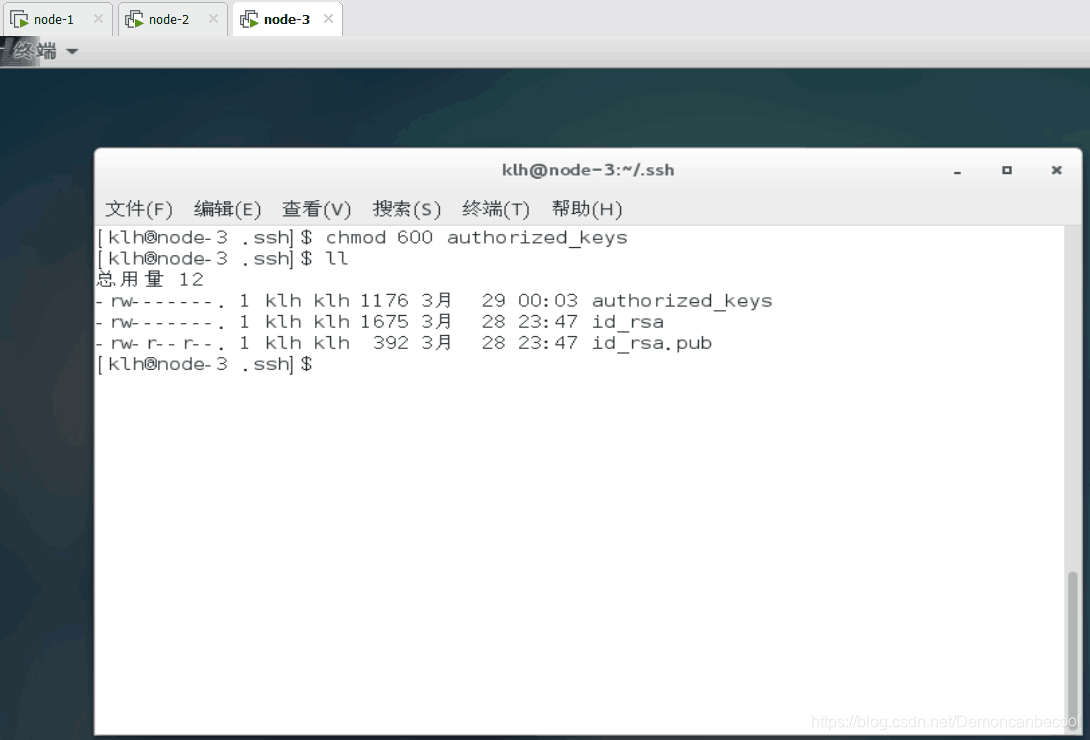
三个用户分别设置修改authorized-keys的权限 -600


三个虚拟机同时打开时主节点会打开以下四个功能
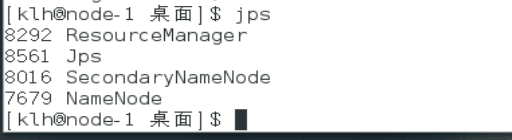
node-2会打开以下三个功能
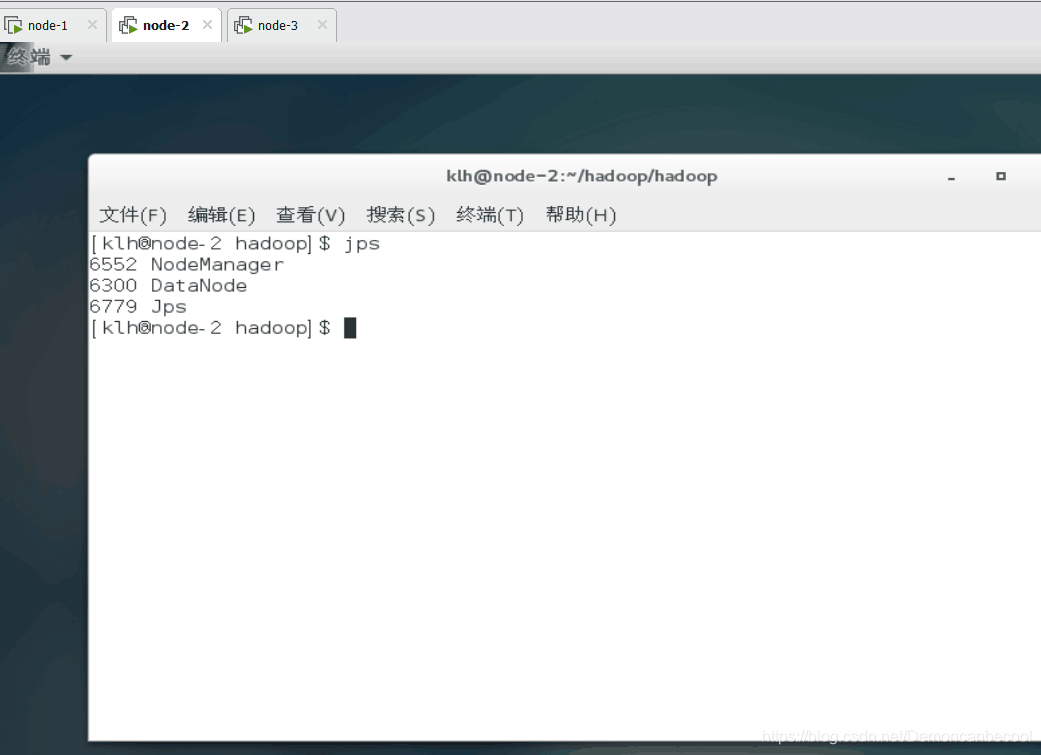 node-3打开以下三个功能 则成功
node-3打开以下三个功能 则成功
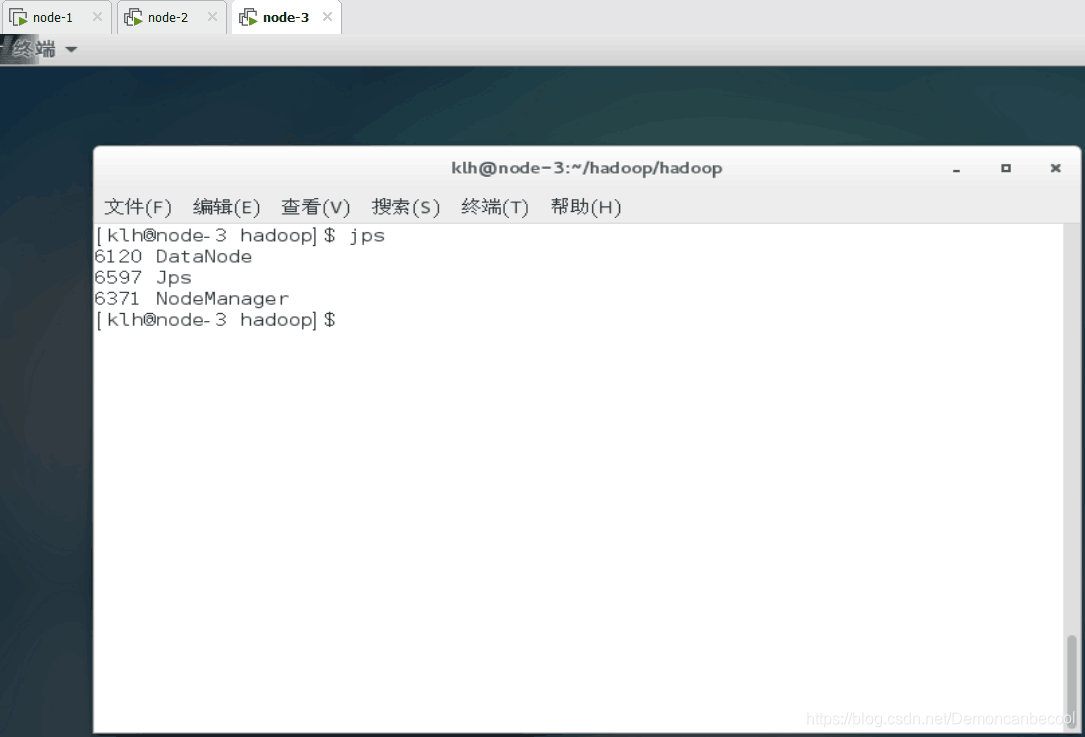

















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









