







 本文介绍了B树和B+树的概念与特性,分析了B+树为何成为MySQL索引结构的选择,以及B+树在大数据量场景下减少I/O读写的优点。还探讨了联合索引在B+树上的分布方式,并解释了InnoDB为何未采用红黑树的原因。
本文介绍了B树和B+树的概念与特性,分析了B+树为何成为MySQL索引结构的选择,以及B+树在大数据量场景下减少I/O读写的优点。还探讨了联合索引在B+树上的分布方式,并解释了InnoDB为何未采用红黑树的原因。
目录
总结
二叉平衡树:利用折半查找思想,减少了查找次数。查找性能主要取决于树的高度。同时无法避免范围匹配的“回旋索引”问题
B树一个节点可以存多个数据,减少了树的高度,降低了查找次数。但仍然无法解决回旋索引的问题。
B+树中的数据顺序存储在叶子节点上,并用指针相连。避免了回旋索引的问题
前言
关于索引的基本概念可参考这篇博客https://blog.youkuaiyun.com/Delicious_Life/article/details/105466368
我们知道MySQL的索引结构使用了B+树,想必读者很想知道为什么百度B+树会搜出来个B树,B树和B+树到底有什么异同?要清楚这些内容,首先我们要了解平衡二叉树
注意:二叉排序树和B树在范围查询时都无法避免回旋查询,只有B+树可以。
平衡二叉树
程序运行时需要从本地磁盘加载到内存中。每次从磁盘加载到内存都可以看做是一次I/O操作,而这种I/O操作是很耗费时间和性能的。因此MySQL在设计索引时考量的重点是哪种数据结构查找快并且I/O读写次数尽可能少。
答案是树,一个典型的查找树就是平衡二叉树!
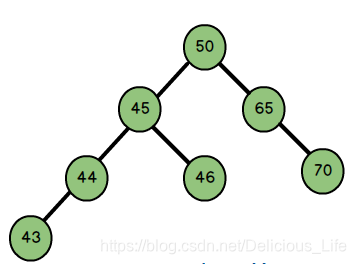
平衡二叉树有两个特点:首先必须是“二叉的排序树”;其次每个节点的左子树和右子树高度差最多为1
这种数据结构相比扫描所有数据,平均效率提高了1/2。
B树
上面使用的二叉平衡树的确大大减少了查找次数,但生活中“秒”级别的查找是不够的,让用户等20-30s很可能用户会“裂开”。要想提高检索的速度不光要“缩小查找的范围”,还要“减少I/O读写”。
B树这个多叉查找树出现了!所谓”阶“指的是一个节点下面有多少个分叉。
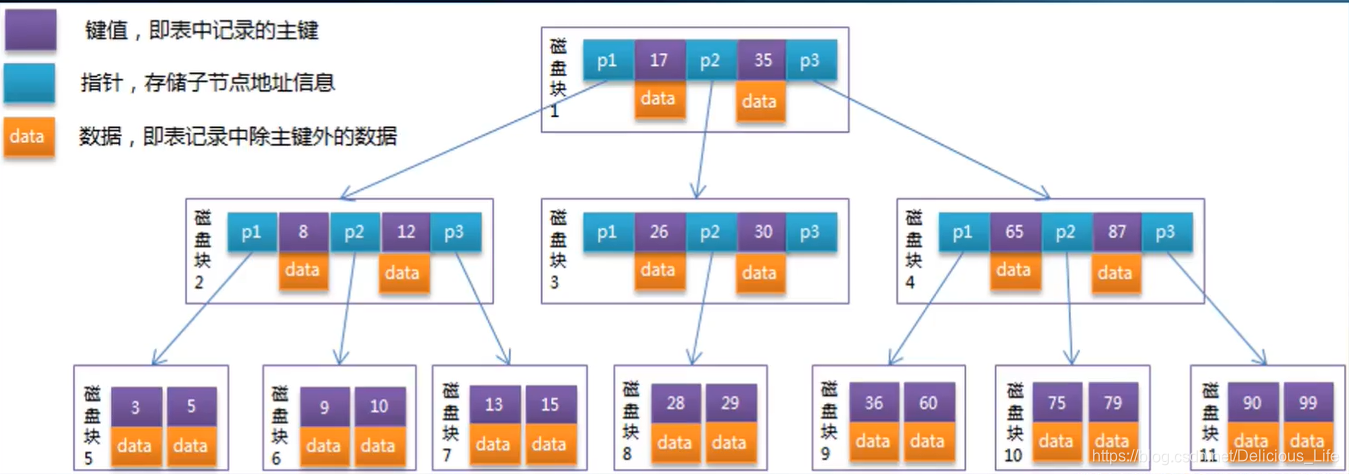
B树有如下特性
1.根节点至少有2个叶子节点
2.每个节点可以包含多个元素,根节点最多可以有“阶数-1”个元素
3..其他节点最少有“阶数/2(向上取整)再减去1”个元素,最多有“阶树/2(向上取整)”个元素
B+树
先来说说B树怎么解决了二叉平衡树的问题。二叉就表示最多只能把I/O读写次数减半,既然二叉解决不了问题,多叉、每个叶子节点可以存多个数据不就好了?这样是不是让I/O读写次数在减半的基础上又减少了呢?
但当数据量非常大的时候,B树的性能还可以提的更高,因此B+树出现了,B+树也正是MySQL所使用的索引结构
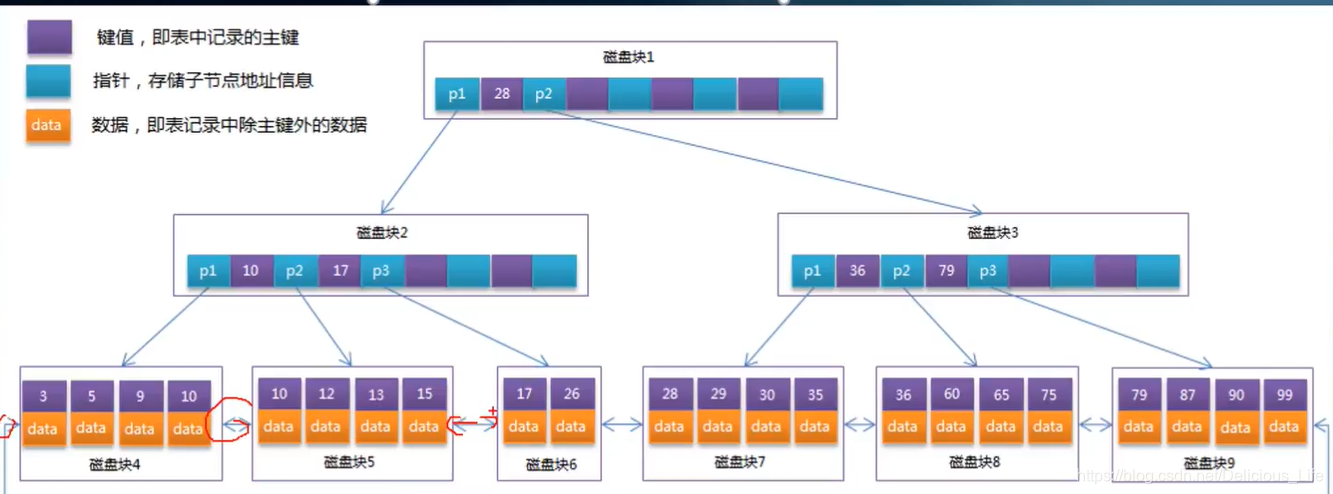
B+树有如下特性
1.B+树的所有非叶子节点只存索引
2.B+树的叶子节点包含所有的索引值,并且指向数据
3.B+树的所有叶子节点相连
总结:可以看到,一方面在数据量小的时候,B+树的I/O次数并不一定比B树少。但是由于B+树把所有数据都放到了一排并增加了指针,实现了顺序查找,因此效率比B树更高。另一方面,非叶子节点只存储索引而不存储数据,因此每个非叶子节点能存储的索引更多了,树的高度也更低了!减少了IO效率
联合索引如何分布在B+树上的
假设现在数据表结构如下。A字段是主键,此时有一个(b,c,d)的联合索引
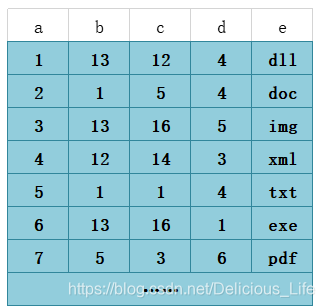
索引排列结构
联合索引的非叶子节点存的是3个键的索引,叶子节点存到是数据
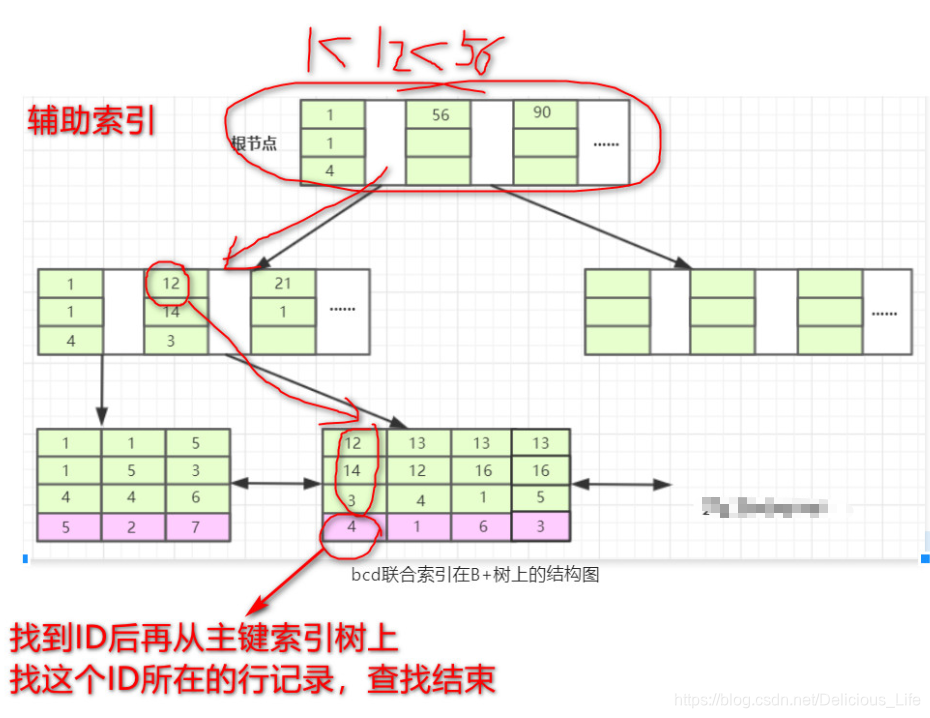
当我们的SQL语言可以应用到索引的时候,比如 select * from T1 where b = 12 and c = 14 and d = 3; 也就是数据库表中a列为4的这条记录。存储引擎首先从根节点(一般常驻内存)开始查找,第一个索引的第一个索引列为1,12大于1,第二个索引的第一个索引列为56,12小于56,于是从这俩索引的中间读到下一个节点的磁盘文件地址,从磁盘上Load这个节点,通常伴随一次磁盘IO,然后在内存里去查找。当Load叶子节点的第二个节点时又是一次磁盘IO,比较第一个元素,b=12,c=14,d=3完全符合,于是找到该索引下的data元素即ID值,再从主键索引树上找到最终数据
为什么InnoDB不用红黑树或B树

红黑树
当我们对一棵平衡二叉搜索树进行插入、删除的时候,很可能会让这棵树变得失衡(最坏可能导致所有祖先结点失衡,但是父结点和非祖先结点都不可能失衡)。
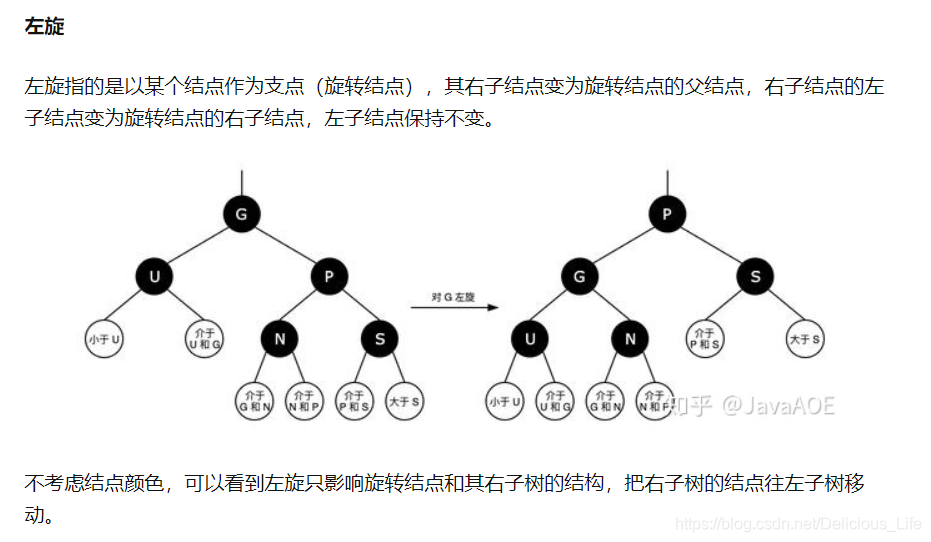
为了达到平衡,需要对树进行旋转。而红黑树能够达到自平衡,靠的也就是左旋、右旋和变色。
旋转操作是局部的。当一侧子树的结点少了,向另一侧“借”一些结点;当一侧子树的结点多了,则“租”一些结点给另一侧。(分左旋、右旋。下图以左旋举例)
由于它的设计,任何不平衡都会在三次旋转之内解决
我们知道HashMap底层用了红黑树,为啥InnoDB不用红黑树呢?
1.B+树可以实现节点的动态调整。对于大数据量,树的高度会降低,B+树更合适。大数据量情况下,无法通过一次把所有数据库中的记录加载到内存,因此IO无法避免。红黑树一个父亲有两个孩子,而B+树可以有多个孩子,树的高度降低意味着减少磁盘IO
2.而HashMap中的红黑树,首先经过了hash分槽,虽然树的高度不能动态调整,但减少了哈希冲突的概率(即减少了链表的长度-进而减少了红黑树的节点数)
总结:HashMap中的数据量无法跟MySQL中的记录行相匹敌。当一次可以把所有数据加载到内存时,当然红黑树更优秀。

















 834
834




 到【灌水乐园】发言
到【灌水乐园】发言







