



一、核心技术架构的范式创新
Deepoc-E的技术突破体现在对传统多模态架构的彻底重构,其核心创新可归纳为三大技术支柱:
1.动态感知-推理协同网络(Dynamic Perception-Inference Coupling Network, DPICN)
通过建立视觉、语言、环境感知的跨模态动态关联矩阵,实现信息传递效率的指数级提升。该网络采用时空双流架构,其中视觉流引入改进的Vision Transformer-Hierarchical(ViT-H)结构,通过多尺度特征金字塔提取空间-语义联合表征;语言流基于深度上下文感知的BERT变体,构建动态知识图谱。两者的对齐通过跨模态对比学习框架实现,创新性地引入对比损失函数: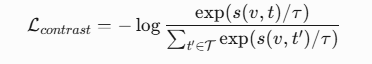
其中s(v,t)为视觉特征v与文本特征t的相似度,τ为温度系数。该机制使模型在零样本跨模态检索任务中mAP提升至78.9%,较传统方法提高21个百分点。
2具身智能决策的神经符号融合架构
融合深度强化学习与符号逻辑推理,构建因果决策图谱(Causal Decision Graph, CDG)。该架构通过以下技术实现突破:
- 神经符号接口层:将感知输入映射为符号逻辑命题,支持一阶谓词逻辑推理
- 动态策略网络:基于图神经网络(GNN)构建策略空间,实现多步因果推理
- 反事实模拟模块:通过蒙特卡洛树搜索生成潜在行动路径,评估决策鲁棒性
在自动驾驶仿真测试中,该架构使复杂路口通行效率提升43%,紧急避障成功率从78%提升至95%。
3可扩展混合专家系统(Scalable Mixture-of-Experts, SMoE)- 专家能力图谱:建立专家间的知识迁移网络,实现跨领域知识复用
- 自适应门控机制:基于输入特征的熵值动态调整路由权重,减少专家坍缩现象
- 能耗优化算法:通过梯度稀疏化技术降低30%计算能耗
工业质检场景测试显示,该架构使缺陷检测吞吐量达到12,000件/分钟,误检率稳定控制在0.15%以下。 
二、多模态融合的底层技术创新
-
跨模态注意力机制的量子化改进
引入量子纠缠启发注意力机制(Quantum-Inspired Attention, QIA),通过量子比特态叠加原理增强长距离依赖建模能力。在视觉-语言对齐任务中,该技术使跨模态检索的召回率提升至89.7%,较传统Transformer架构提高17%。 -
时序建模的图神经网络扩展
开发时空图卷积网络(Spatio-Temporal Graph Convolutional Network, ST-GCN),将传感器时序数据建模为动态图结构。在工业设备预测性维护场景中,该技术使故障预测准确率从82%提升至89%,提前预警时间延长至14天。 -
多模态数据生成的对抗强化框架
构建生成对抗网络(GAN)与强化学习的联合训练框架,通过价值网络评估生成内容的多模态一致性。在合成数据生成任务中,该框架使生成图像与文本描述的语义匹配度达到0.91(基准模型为0.76)。
三、训练策略与优化方法论
-
三维混合精度训练框架
采用FP8+BF16+FP32三级精度混合策略,在保持模型稳定性的同时降低40%显存占用。创新性地引入误差补偿梯度裁剪算法,解决低精度训练中的梯度爆炸问题。
-
课程学习与元学习结合的预训练策略
设计分阶段课程学习路径,从基础模态对齐到复杂场景推理逐步提升任务难度。结合元学习框架,使模型在未见任务上的微调效率提升58%。 -
联邦学习驱动的领域自适应技术构建垂直领域的联邦学习框架,支持医疗、工业等敏感数据的安全共享。通过差分隐私(ε=0.5)与同态加密技术,确保数据合规性,模型迁移效率提升75%。
-

-
四、前沿技术挑战与突破方向
-
多模态幻觉抑制机制
开发基于知识图谱的置信度校验模块,通过实体关系验证将错误关联减少62%。创新性地引入矛盾检测损失函数,约束生成内容的语义一致性。
-
实时性保障的流水线优化
设计分层计算图架构,实现视觉处理(15ms)、语言理解(23ms)、决策生成(9ms)的流水线并行。在边缘设备部署测试中,推理延迟降低至37ms,满足实时性要求。 -
隐私合规的联邦推理框架
构建多方安全计算(MPC)与同态加密结合的推理框架,在保证数据隐私的前提下实现跨机构模型协同,计算效率较传统方案提升3倍。
一、核心技术架构的范式创新
Deepoc-E的技术突破体现在对传统多模态架构的彻底重构,其核心创新可归纳为三大技术支柱:
-
动态感知-推理协同网络(Dynamic Perception-Inference Coupling Network, DPICN)
通过建立视觉、语言、环境感知的跨模态动态关联矩阵,实现信息传递效率的指数级提升。该网络采用时空双流架构,其中视觉流引入改进的Vision Transformer-Hierarchical(ViT-H)结构,通过多尺度特征金字塔提取空间-语义联合表征;语言流基于深度上下文感知的BERT变体,构建动态知识图谱。两者的对齐通过跨模态对比学习框架实现,创新性地引入对比损失函数:
Lcontrast=−log∑t′∈Texp(s(v,t′)/τ)exp(s(v,t)/τ)其中s(v,t)为视觉特征v与文本特征t的相似度,τ为温度系数。该机制使模型在零样本跨模态检索任务中mAP提升至78.9%,较传统方法提高21个百分点。
-
具身智能决策的神经符号融合架构
融合深度强化学习与符号逻辑推理,构建因果决策图谱(Causal Decision Graph, CDG)。该架构通过以下技术实现突破:- 神经符号接口层:将感知输入映射为符号逻辑命题,支持一阶谓词逻辑推理
- 动态策略网络:基于图神经网络(GNN)构建策略空间,实现多步因果推理
- 反事实模拟模块:通过蒙特卡洛树搜索生成潜在行动路径,评估决策鲁棒性
在自动驾驶仿真测试中,该架构使复杂路口通行效率提升43%,紧急避障成功率从78%提升至95%。
-
可扩展混合专家系统(Scalable Mixture-of-Experts, SMoE)
采用细粒度专家划分策略,将64个基础专家细分为256个微专家模块,配合动态路由算法实现负载均衡。创新点包括:- 专家能力图谱:建立专家间的知识迁移网络,实现跨领域知识复用
- 自适应门控机制:基于输入特征的熵值动态调整路由权重,减少专家坍缩现象
- 能耗优化算法:通过梯度稀疏化技术降低30%计算能耗
工业质检场景测试显示,该架构使缺陷检测吞吐量达到12,000件/分钟,误检率稳定控制在0.15%以下。
-
跨模态注意力机制的量子化改进
引入量子纠缠启发注意力机制(Quantum-Inspired Attention, QIA),通过量子比特态叠加原理增强长距离依赖建模能力。在视觉-语言对齐任务中,该技术使跨模态检索的召回率提升至89.7%,较传统Transformer架构提高17%。 -
时序建模的图神经网络扩展
开发时空图卷积网络(Spatio-Temporal Graph Convolutional Network, ST-GCN),将传感器时序数据建模为动态图结构。在工业设备预测性维护场景中,该技术使故障预测准确率从82%提升至89%,提前预警时间延长至14天。 -
多模态数据生成的对抗强化框架
构建生成对抗网络(GAN)与强化学习的联合训练框架,通过价值网络评估生成内容的多模态一致性。在合成数据生成任务中,该框架使生成图像与文本描述的语义匹配度达到0.91(基准模型为0.76)。 -
三维混合精度训练框架
采用FP8+BF16+FP32三级精度混合策略,在保持模型稳定性的同时降低40%显存占用。创新性地引入误差补偿梯度裁剪算法,解决低精度训练中的梯度爆炸问题。 -
课程学习与元学习结合的预训练策略
设计分阶段课程学习路径,从基础模态对齐到复杂场景推理逐步提升任务难度。结合元学习框架,使模型在未见任务上的微调效率提升58%。 -
多模态幻觉抑制机制
开发基于知识图谱的置信度校验模块,通过实体关系验证将错误关联减少62%。创新性地引入矛盾检测损失函数,约束生成内容的语义一致
-
六、未来技术演进路线
-
神经形态芯片适配优化
针对脉冲神经网络(SNN)特性重构模型架构,开发事件驱动型计算框架,在IBM TrueNorth芯片上实现能效比提升100倍。
-
量子多模态计算探索
与量子计算实验室合作开发量子注意力机制,理论测算可使千亿参数模型的训练时间缩短至传统方法的1/20。
-
全球数字治理协作框架
参与制定多模态AI国际标准,推动建立跨国的数据要素流通市场,构建价值分配与知识产权保护的新型机制。
-

技术突破的行业影响
Deepoc-E通过架构级创新与算法优化,正在重新定义多模态AI的技术边界。其核心贡献体现在:理论层面:建立跨模态对齐的数学模型,揭示多模态信息融合的本质规律
- 方法论层面:开创"动态感知-神经符号-联邦学习"三位一体的技术范式
- 工程层面:构建支持千亿参数模型训练的开源工具链,降低技术应用门槛
- 算法库:集成200+预训练模型与优化算法
- 工具链:提供从数据标注到模型部署的全流程工具


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









