






 本文分享了使用Go语言进行爬虫开发的初次尝试,详细记录了从思路分析到代码实现的过程,包括抓包分析、图片链接提取及下载,并对代码进行了总结反思。
本文分享了使用Go语言进行爬虫开发的初次尝试,详细记录了从思路分析到代码实现的过程,包括抓包分析、图片链接提取及下载,并对代码进行了总结反思。
写在前面: 我是「虐猫人薛定谔i」,一个不满足于现状,有梦想,有追求的00后
\quad
本博客主要记录和分享自己毕生所学的知识,欢迎关注,第一时间获取更新。
\quad
不忘初心,方得始终。
\quad❤❤❤❤❤❤❤❤❤❤

思路分析
第一次尝试用Go语言来写爬虫,由于自己刚开始学习Go语言,很多东西还没有搞懂,所以……
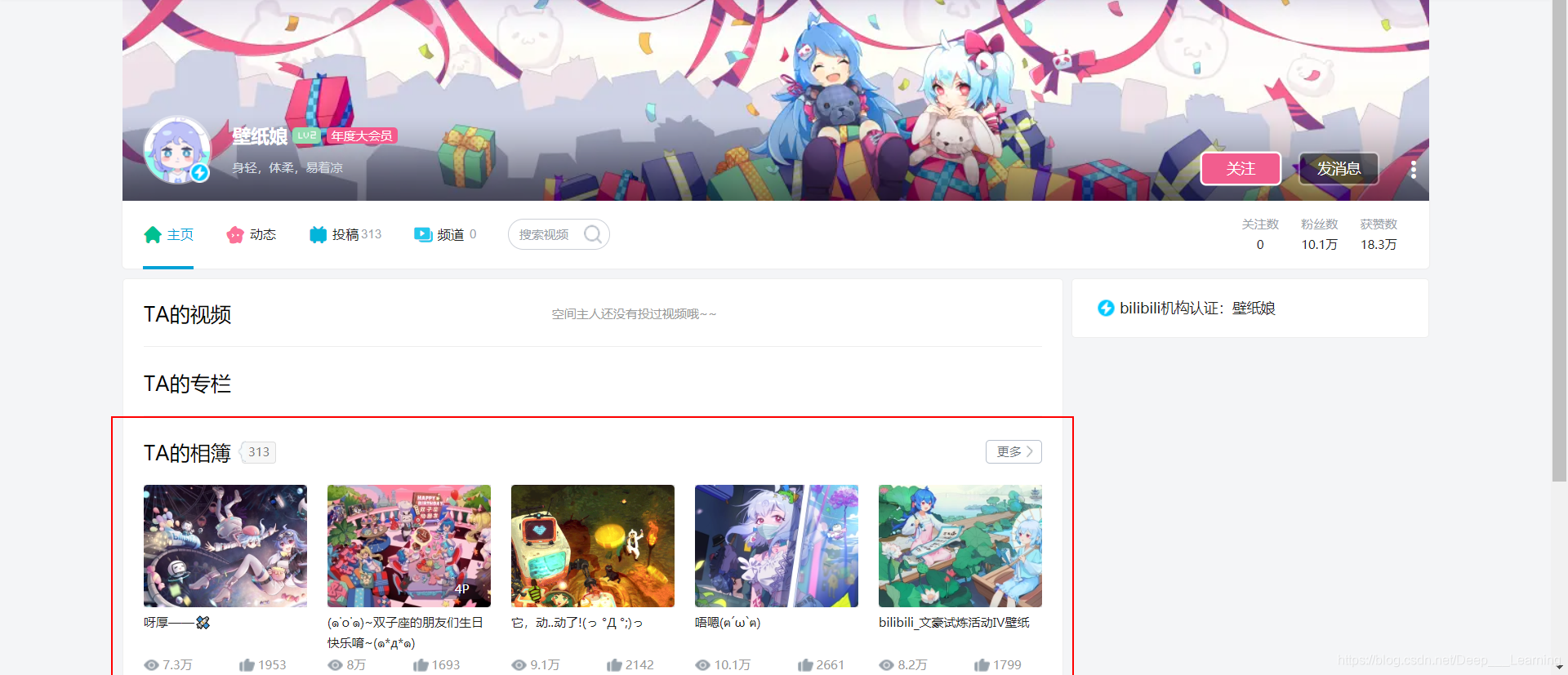
抓包分析一下
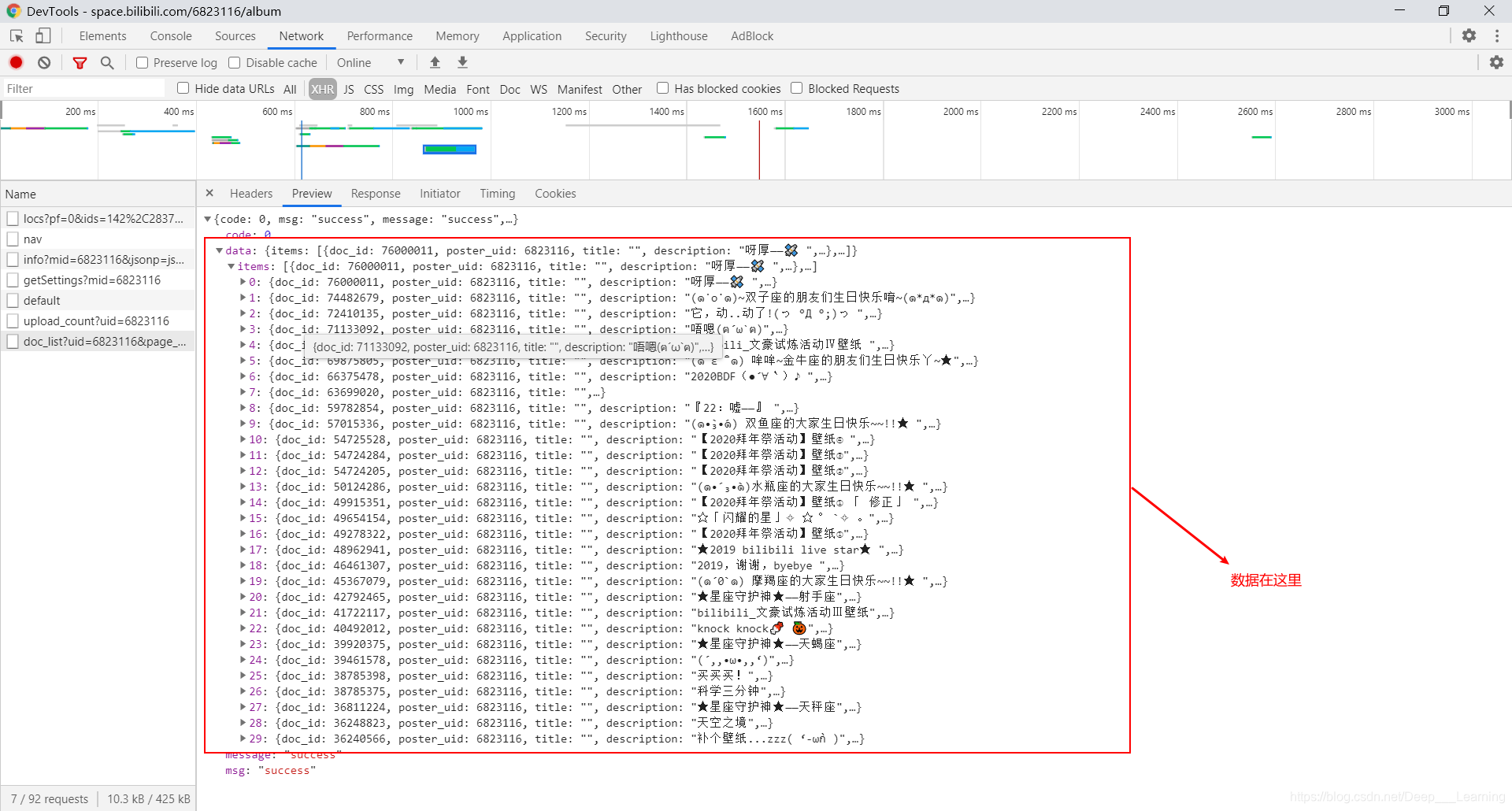
提取图片链接时,我用的是正则表达式,其实是可以用json解析的
本来打算用并发提高速度的,奈何自己太菜,不会啊……

代码
package main
import (
"fmt"
"bufio"
"io"
"io/ioutil"
"net/http"
"os"
"regexp"
"strconv"
"strings"
)
var id int
func saveData(str string) {
imgPath := "D:\\Code\\Go\\goStudy\\result\\album\\"
imgName := strconv.Itoa(id) + ".jpg"
resp, err := http.Get(str)
if err != nil {
fmt.Println(err)
return
}
defer resp.Body.Close()
reader := bufio.NewReaderSize(resp.Body, 32 * 1024)
imgFile, err := os.Create(imgPath + imgName)
if err != nil {
panic(err)
}
writer := bufio.NewWriter(imgFile)
io.Copy(writer, reader)
fmt.Println(id, ".jpg is ok!")
id ++
}
func parseData(url string) {
response, err := http.NewRequest("GET", url, nil)
if err != nil {
fmt.Println(err)
return
}
response.Header.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36")
client := http.Client{}
resp, err := client.Do(response)
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println(err)
return
}
data := string(body)
reg, err := regexp.Compile("\"img_src\":\".*?\"")
if err != nil {
fmt.Println(err)
return
}
result := reg.FindAllStringSubmatch(data, -1)
for _, val := range result {
str := strings.Replace(val[0], "img_src", "", -1)
str = strings.Replace(str, "\"", "", -1)[1:]
saveData(str)
}
}
func main() {
url := "https://api.vc.bilibili.com/link_draw/v1/doc/doc_list?uid=6823116&page_num="
id = 0
for i := 0; i < 11; i++ {
pageURL := url + strconv.Itoa(i)
parseData(pageURL)
}
}
结果
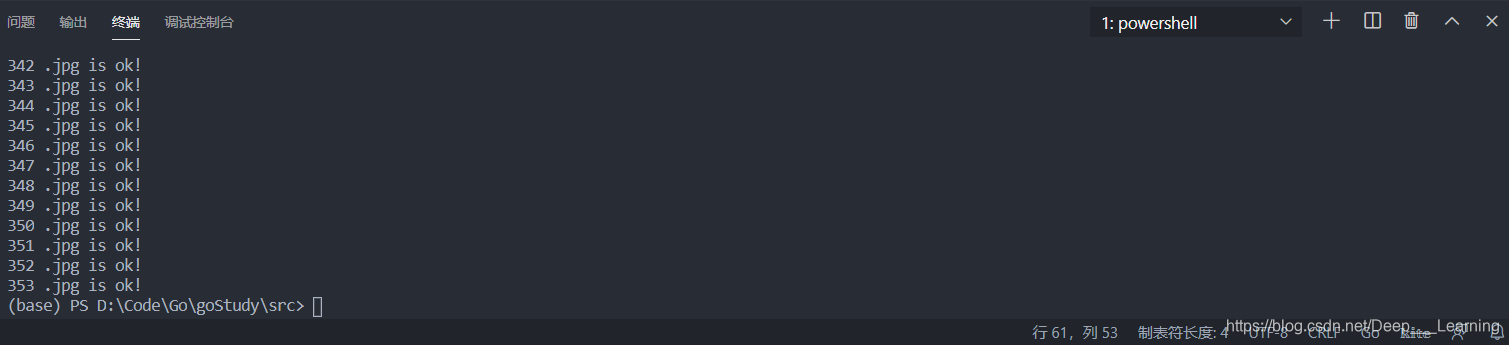
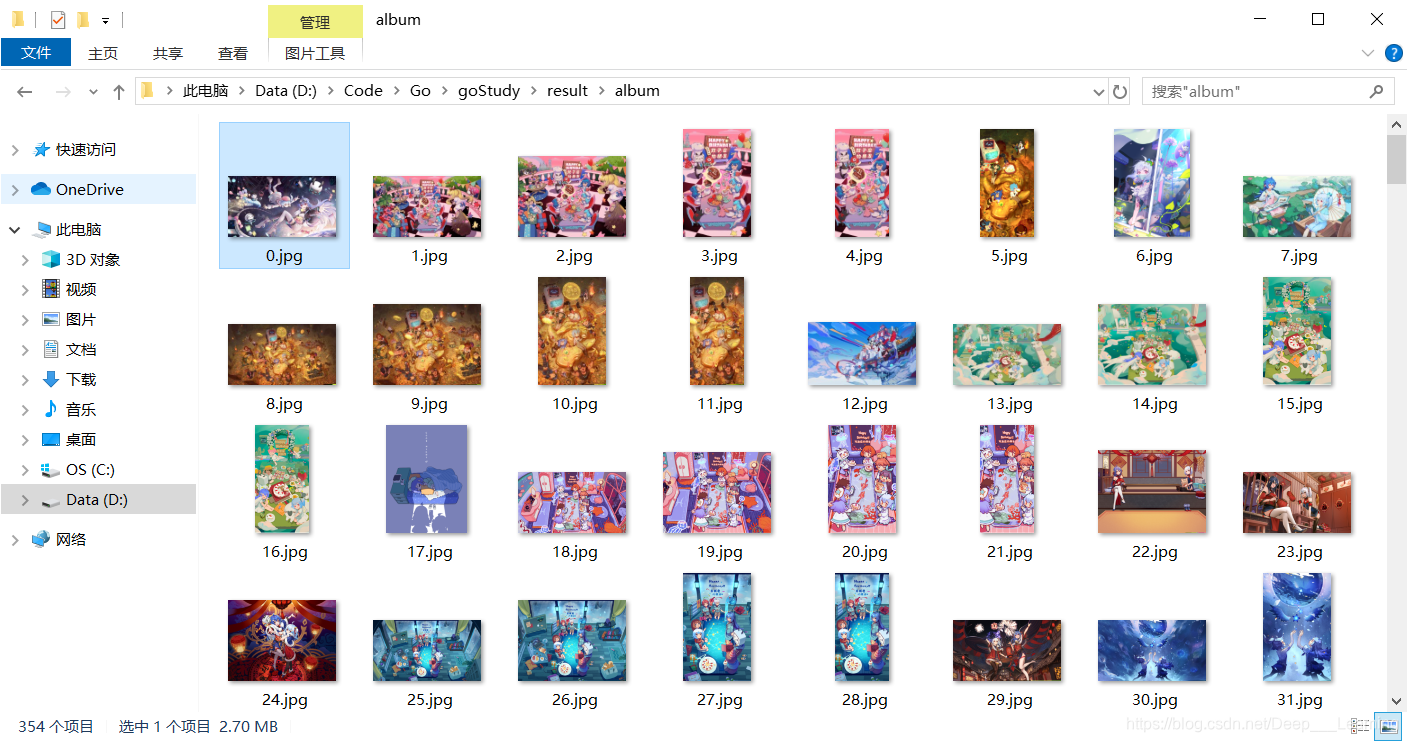
总结
个人感觉写爬虫还是用Python方便,可能是自己Python用的比较顺手的缘故吧!

蒟蒻写博客不易,加之本人水平有限,写作仓促,错误和不足之处在所难免,谨请读者和各位大佬们批评指正。
如需转载,请署名作者并附上原文链接,蒟蒻非常感激
名称:虐猫人薛定谔i
博客地址:https://blog.youkuaiyun.com/Deep___Learning

















 1233
1233




 到【灌水乐园】发言
到【灌水乐园】发言







