




 该博客探讨了BERT服务的使用,包括句子编码、池化策略的选择,以及如何处理分词问题。文章指出,池化层的选择会影响句子表示的质量,而BERT的子词分词可能导致OOV问题。对于句子相似度计算,作者建议关注排名而非绝对的余弦相似度。此外,还讨论了如何使用自定义的微调BERT模型。
该博客探讨了BERT服务的使用,包括句子编码、池化策略的选择,以及如何处理分词问题。文章指出,池化层的选择会影响句子表示的质量,而BERT的子词分词可能导致OOV问题。对于句子相似度计算,作者建议关注排名而非绝对的余弦相似度。此外,还讨论了如何使用自定义的微调BERT模型。
bert-as-service github:
https://github.com/hanxiao/bert-as-service#q-the-cosine-similarity-of-two-sentence-vectors-is-unreasonably-high-eg-always–08-whats-wrong
BERT interview questions:
https://mp.weixin.qq.com/s/E60wUHkHo-Gj3wb9Denuag
bert-as-service uses BERT as a sentence encoder and hosts it as a service via ZeroMQ, allowing you to map sentences into fixed-length representations in just two lines of code.
1. Pooling
1)pooling是干什么用的?
pooling is required to get a fixed representation of a sentence. In the default strategy REDUCE_MEAN, I take the second-to-last hidden layer of all of the tokens in the sentence and do average pooling.


Q: So which layer and which pooling strategy is the best?
A: It depends. Keep in mind that different BERT layers capture different information. To see that more clearly, here is a visualization on UCI-News Aggregator Dataset, where I randomly sample 20K news titles; get sentence encodes from different layers and with different pooling strategies, finally reduce it to 2D via PCA (one can of course do t-SNE as well, but that’s not my point). There are only four classes of the data, illustrated in red, blue, yellow and green. To reproduce the result, please run example7.py.
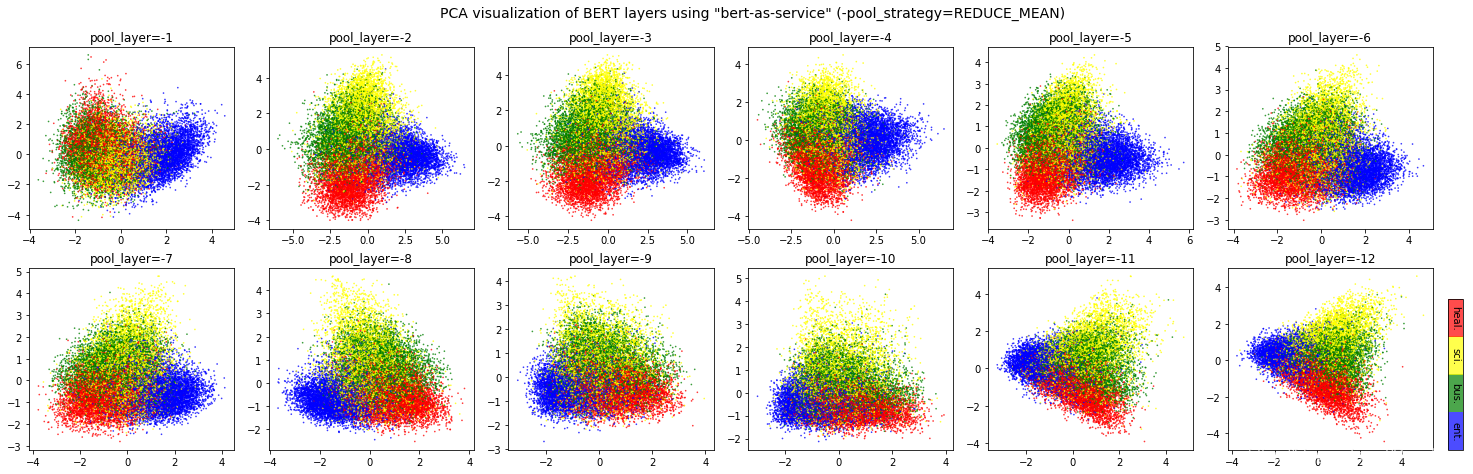
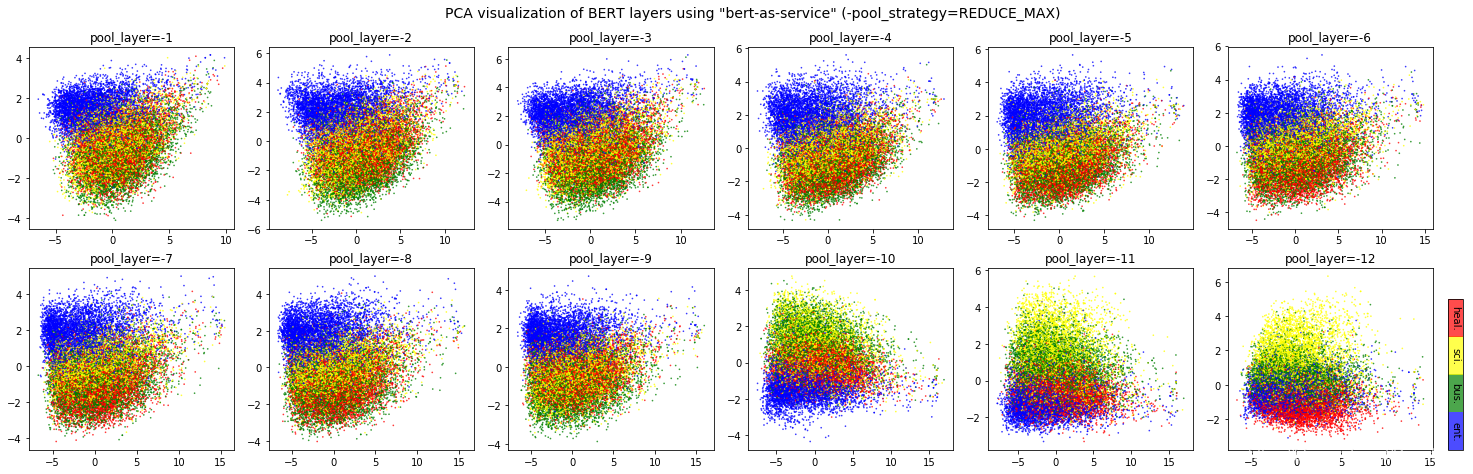
2)如何选择在第几层pool出sentence embedding?
Intuitively, pooling_layer=-1 is close to the training output, so it may be biased to the training targets. If you don’t fine tune the model, then this could lead to a bad representation. pooling_layer=-12 is close to the word embedding, may preserve the very original word information (with no fancy self-attention etc.). On the other hand, you may achieve the very same performance by simply using a word-embedding only. That said, anything in-between [-1, -12] is then a trade-off.
2. Tokenizer
1)subword分词:Why my (English) word is tokenized to ##something?
Because your word is out-of-vocabulary (OOV). The tokenizer from Google uses a greedy longest-match-first algorithm to perform tokenization using the given vocabulary.
For example:
input = “unaffable”
tokenizer_output = [“un”, “##aff”, “##able”]
2)Do I need to do segmentation for Chinese?
No, if you are using the pretrained Chinese BERT released by Google you don’t need word segmentation. As this Chinese BERT is character-based model. It won’t recognize word/phrase even if you intentionally add space in-between. The word embedding is actually the character embedding for Chinese-BERT.
3. sentence similarity
The cosine similarity of two sentence vectors is unreasonably high (e.g. always > 0.8), what’s wrong?
A: A decent representation for a downstream task doesn’t mean that it will be meaningful in terms of cosine distance. Since cosine distance is a linear space where all dimensions are weighted equally. if you want to use cosine distance anyway, then please focus on the rank not the absolute value. Namely, do not use:
if cosine(A, B) > 0.9, then A and B are similar
Please consider the following instead:
if cosine(A, B) > cosine(A, C), then A is more similar to B than C.
The graph below illustrates the pairwise similarity of 3000 Chinese sentences randomly sampled from web (char. length < 25). We compute cosine similarity based on the sentence vectors and Rouge-L based on the raw text. The diagonal (self-correlation) is removed for the sake of clarity. As one can see, there is some positive correlation between these two metrics.
4. finetuned BERT used in bert-as-service
Q: Can I use my own fine-tuned BERT model?
A: Yes. In fact, this is suggested. Make sure you have the following three items in model_dir:
A TensorFlow checkpoint (bert_model.ckpt) containing the pre-trained weights (which is actually 3 files).
A vocab file (vocab.txt) to map WordPiece to word id.
A config file (bert_config.json) which specifies the hyperparameters of the model.

















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









