




回顾:
- 内核模式代码比用户模式代码拥有更多的权限
- 中断改变了调用内核代码的执行流程
- 系统调用允许我们运行内核代码来访问操作系统的服务
本章小结:
-
介绍进程及其实现
-
进程状态和状态转换
-
进程管理的系统调用
进程介绍
定义
进程(process)是程序运行实例的抽象
- 程序(program)是被动的,“位于”磁盘上
- 进程(process)具有与其相关联的控制结构,可能是活动的,并且可能有分配给它的资源(例如I/O设备、内存、处理器)。
管理进程所需的所有信息都由内核存储在进程控制块(process control block, PCB)中。
所有的进程控制块都记录在进程表中。
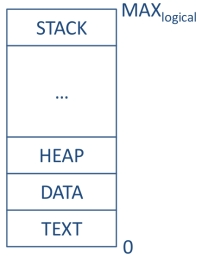
进程的内存映像
一个进程的内存映像包含:
- 程序代码(可以在运行相同代码的多个进程之间共享)
- 数据段、堆栈(stack)和堆(heap)
每个进程都有自己的逻辑地址空间,其中堆栈和堆被放置在相对的两侧,以允许它们增长
进程的生命周期
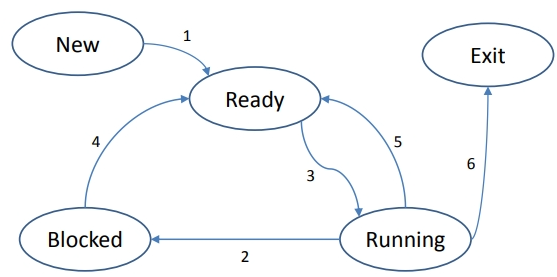
状态
- 刚刚创建了一个新(new)进程。它有一个PCB,正在等待被承认,尽管它可能还没有在内存中。
- 就绪(ready)进程正在等待CPU可用。
- 当前正在运行(running)的进程的指令由CPU执行。
- 阻塞(blocked)的进程无法继续,例如正在等待I/O
- 终止(terminated)的进程不再可执行。数据结构——PCB可暂时保存。
- 中止(suspended)的进程被换出(不作进一步讨论)
转换
状态转换包括:
- New→ready:承认进程并投入执行
- Running → blocked:例如,进程正在等待输入或执行系统调用
- Ready→running:进程调度器(process scheduler, 指在操作系统中负责决定进程执行顺序的组件)选择该进程
- Blocked→ready:事件发生,例如I/O操作已经完成
- Running→ready:进程放弃CPU,例如由于中断(interrupt)或暂停(pause)
- Running→exit:进程已经完成,例如程序结束或遇到异常
中断和系统调用驱动这些转换。
操作系统队列
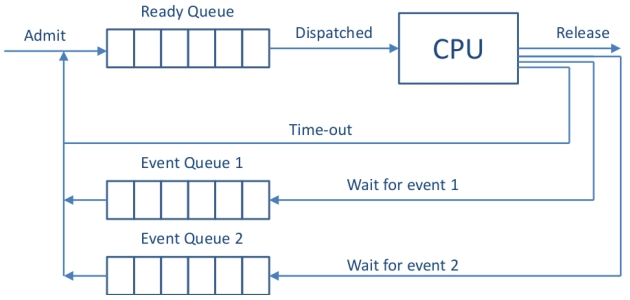
进程的操作系统实现
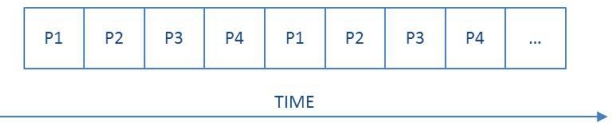
上下文转接:多路编程
现代计算机是多路编程(multi-programming)系统
假设是单处理器系统,各个进程的指令是顺序执行的:
- 多路编程可以追溯到“MULTICS”(多路存取计算机系统(Multiplexed Information and Computing Service))时代
- 多路编程是通过交错执行进程,将CPU时间划分为时间片来实现的
- 通过称为上下文切换(context switching)的过程在进程之间交换控制
- 在时间片的长度和上下文切换时间之间存在一种权衡
- 真正的并行需要硬件支持
当发生上下文切换时,系统保存旧进程的状态并加载新进程的状态(产生开销(overhead))。
- 保存⇒更新进程控制块
- (重新)启动⇒进程控制块读取
较短的时间片段会产生良好的响应时间,但有效利用率较低。例如,假设上下文切换和时间片都使用1ms。那么:
- 100个进程中的最后一个开始运行需要99x (1+1) = 198ms。
- CPU时间的一半(1/(1+1)=0.5)是在做有用的工作。
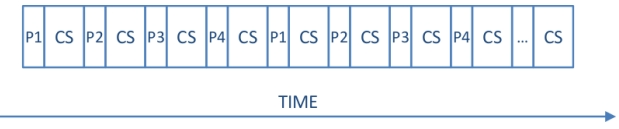
长时间切片会导致较差的响应时间,但会带来更好的有效利用。例如,假设上下文切换时间为1ms,时间片为100ms。那么:
- 100个进程中的最后一个开始运行需要99x (100+1) = 9999ms。
- CPU时间的99%(100/(1+100)=0.99)是在做有用的工作。

进程控制块包含三种类型的属性:
- 进程标识 Process identification(PID, UID,父PID)
- 进程控制信息 Process control information(进程状态、调度信息等)
- 进程状态信息 Process state information(用户寄存器、程序计数器、堆栈指针、程序状态字、内存管理信息、文件等)
进程控制块是内核数据结构,也就是说,它们是受保护的,只有在内核模式下才能访问!
- 允许用户应用程序直接访问它们可能会损害它们的完整性
- 操作系统通过系统调用(例如设置进程优先级)代表用户管理它们。
切换过程:
- 保存进程状态(程序计数器、寄存器)
- 更新PCB(running -> ready/blocked)
- 将PCB移动到适当的队列(ready/blocked)
- 运行调度程序,选择新进程
- 更新到新PCB中的运行(running)状态
- 更新内存管理单元(MMU)
- 恢复过程
进程实现
表和控制块
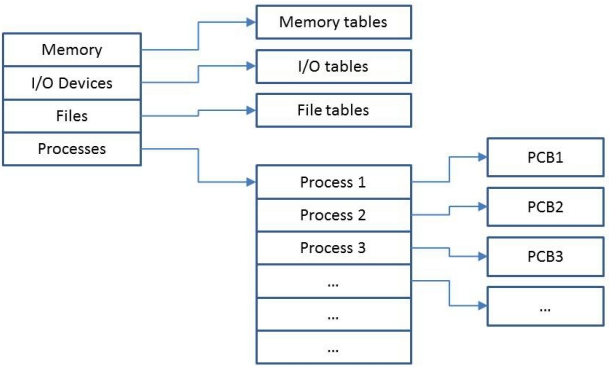
操作系统会将有关“资源”状态的信息存放在表格中:
- 进程表 Process tables(进程控制块)
- 内存表 Memory tables(内存分配、内存保护、虚拟内存)
- 输入/输出表 I/O tables(可用性、状态、传输信息)
- 文件表 File tables(位置、状态)
进程表为每个进程都保存着一个进程控制块,该控制块在进程创建时予以分配。 表由内核进行维护,并且通常会相互关联。
系统调用
进程创建
进程创建(Process Creation)
在计算机操作系统中,进程创建是指创建一个新的进程,以便执行某个程序或任务。
真正的系统调用被“包装”在操作系统库中(例如libc),遵循一个定义良好的接口(例如POSIX, WIN32 API)。
例如,在类unix操作系统上,调用fork来创建进程的副本。在Linux上,用于实现fork的底层系统调用是clone。

Linux下的进程创建:Fork和Exec模式
fork()创建当前进程的完全复制
- 子进程执行的第一条指令是fork调用后的第一条指令
fork()将子进程的进程标识符返回给父进程。
fork()返回0给子进程
常见的模式如下所示:
- 调用fork()来创建当前进程的精确副本。
- 在子进程中,调用“exec”函数之一,用一个新程序替换当前进程。例如execl("/bin/ls", "ls", "-l", 0)将当前进程替换为ls,这是bash等Unix shell中典型的调用模式。
-
父进程调用
fork()创建子进程 -
子进程:
-
打印"Child process"
-
执行
ls -l命令显示当前目录详细列表 -
命令执行完毕后子进程退出
-
-
父进程:
-
等待子进程结束
-
打印子进程的退出状态
-
然后父进程退出
-
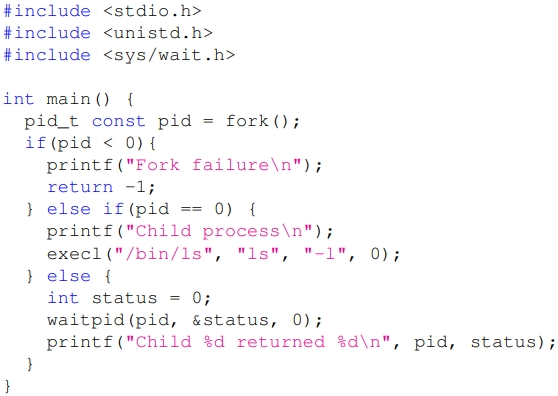
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
pid_t const pid = fork();
#include语句:包含必要的头文件
-
stdio.h:标准输入输出 -
unistd.h:提供fork()和execl()等系统调用 -
sys/wait.h:提供waitpid()函数
main()函数:程序入口
pid_t const pid = fork();:
-
调用
fork()创建新进程 -
返回值:
-
<0:创建失败 -
=0:当前是子进程 -
>0:当前是父进程,返回值为子进程ID
-
错误处理:
if(pid < 0){
printf("Fork failure\n");
return -1;
}
子进程分支:
else if(pid == 0) {
printf("Child process\n");
execl("/bin/ls", "ls", "-l", 0);
}
-
打印"Child process"
-
使用
execl()执行/bin/ls程序,参数为ls -l -
execl()成功后不会返回,原进程映像被替换
父进程分支:
else {
int status = 0;
waitpid(pid, &status, 0);
printf("Child %d returned %d\n", pid, status);
}
-
使用
waitpid()等待指定子进程结束 -
打印子进程ID和退出状态
进程终止
进程终止(Process Termination)
指计算机操作系统中一个运行中的程序或应用程序实例结束运行的过程。
通过exit和abort的系统调用可以用来显式地通知OS进程已经终止
- 必须取消资源分配
- 输出必须刷新
- 可能需要执行流程管理
一个系统调用来终止其他进程:
- UNIX/Linux: kill()
- Windows: TerminateProcess()

















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









