




概述
演变自prometheus
云原生计算基金会(CNCF)接纳了OpenMetrics项目,一个用于暴露度量的开源规范,进入了CNCF沙箱。沙箱是早期和不断发展的云原生项目的基地。
OpenMetrics汇集了Prometheus的成熟度和采用率,Google在处理极端规模的统计数据方面的背景,以及各种项目、供应商和最终用户的经验和需求,旨在从分层监控方式转变为使用户能够大规模传输度量。
这个开源项目专注于创建中立的度量暴露格式,为用户当前和未来的需求提供完善的数据模型,并将其嵌入到标准中,该标准是被广泛采用的普罗米修斯暴露格式的演变。虽然,目前有许多监控解决方案可供使用,但许多监控解决方案并未专注于度量,而是基于专有、难以实施和分层数据模型的旧技术。
“OpenMetrics的主要优势,在于为众多行业领先的实施和新采用者开辟了云原生度量监控的事实模型。普罗米修斯改变了世界监测的方式,OpenMetrics旨在利用这个有机发展的生态系统,将其转化为有意识的、全行业共识的基础,从而缩小与InfluxData、Sysdig、Weave Cortex和OpenCensus等其它监测解决方案的差距。毋庸置疑,Prometheus将是最前沿在其服务器和所有客户端库中实现OpenMetrics。”SpaceNet的技术架构师,Prometheus团队成员,OpenMetrics的创始人Richard Hartmann说。“CNCF一直致力于将云原生社区聚集在一起。我们期待与该社区合作,进一步实现云原生监控,并继续构建我们的用户和上游贡献者社区。”
OpenMetrics贡献者包括AppOptics、Cortex、Datadog、Google、InfluxData、OpenCensus、Prometheus、Sysdig和Uber等。
指标的重要性
可观测性的三驾马车分别为:指标、trace 、日志
他们分别所处的监控层级:
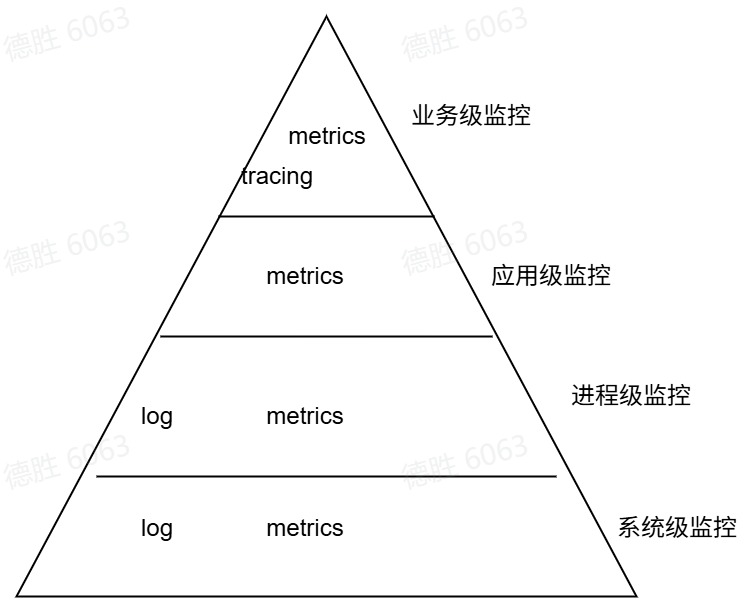
- Metrics的特点是时序的,可聚合(Aggregatable)通俗地讲,Metrics是随着时间的推移产生的一些与监控相关的可聚合的重要指标(如Counter计数器、gague测量值、Historgram直方图等)。
- Logging是一种离散日志(或称事件),分为有结构的日志和无结构的日志两种。
- Tracing是业务请求调用链记录。
指标的意义
一般在业务开发中,通过查日志的方式就能定位到系统存在问题,通过Tracing模式可以查到链路上出现问题的环节。但是合理的指标设置、完美的监控大屏配置、超前的监控告警往往能让开发者在业务方发现问题之前就已经发现问题。所谓上工治未病,指标贯穿系统级到业务级监控,合理的指标监控就是掌握了系统的脉搏,能防患于未然,在问题发生之前定位问题。
问题的排查
进行问题排查时,如果没有指标的监控,研发人员往往是通过查日志解决问题的。但是如果需要查询分布式集群上几十台到几百台机器的日志,不借助一些日志软件,而是使用命令行集中查询,那将是一件非常麻烦的事情。而在当下这个云原生和微服务架构盛行的时代,监控系统百花齐放,往往会基于Metrics的监控大屏进行查询从而定位问题。比如Prometheus就支持非常强大的Metrics查询—PromQL语句查询。Metrics查询是基于时间序列的数据库设计得到的,其可以直接定位到过去的任意时间点,可以对系统层、进程层、应用层、业务层乃至端上的所有监控指标进行查询。如果Metrics无法定位问题或者需要更多信息,Tracing监控手段可以提供协助,帮助定位该问题发生在微服务链路的哪个环节。最后,可以再根据日志找到最根本的问题。通过Metrics→Tracing→Logging的顺序分析问题,比直接去查日志更高效,很多问题都可以在日志之前的环节直接被定位并解决。
开放格式的好处
- 可用性:开放标准可供所有人读取和 实施。
- 使最终用户的选择最大化
- 无歧视(供应商中立):开放标准以及 管理开放标准的组织不会偏爱 其中的某个实施者。
- 没有刻意的秘密:标准不得隐瞒 针对可互操作实施所必需的任何详细信息。
- 大部分数据格式是专有的,或者很难实施, 亦或是两种情况都有
- Prometheus 已成为云原生 指标监测的实际标准
- 公开数据的易用性使得 兼容指标端点出现激增
- Prometheus 的公开格式虽然是基于大量操作 经验,但一直是在少数人之中设计的
- 其他一些项目和供应商在采用 “竞争性”产品中的某些功能时极为受挫
从接入到存储的高可扩展高可移植性
prometheus云原生事实标准 - 跟着大哥有肉吃
OpenMetrics汇集了Prometheus的成熟度和采用率,
时序化数据库 - 天然支持时序指标
指标的开放标准 openMetrics
OpenMetrics的主要优势,在于为众多行业领先的实施和新采用者开辟了云原生度量监控的事实模型
100%的兼容性
广泛的来源支持和存储支持
OpenMetrics将普罗米修斯公开格式演变为标准。OpenMetrics致力创建一个适合大规模传输指标的开放标准,同时支持文本表示和Protocol Buffers。OpenMetrics是一种协议规范。openMetrics具有极强的信息兼容性,在单一数据格式和表格式中可以兼容任何类型的指标数据。
先看看我们项目中的metrics长什么样子
指标是一种特定类型的遥测数据。他们代表一组数据的当前状态的快照。 他们与日志或事件是截然不同的,指标侧重于记录或描述个别事件。OpenMetrics主要是一种指标格式,独立于任何其他的传输格式。
指标和时间序列
指标将所有系统状态表示为以下几类:数值、计数、当前值 、枚举值、bool值
与单一事件发生在特定时间不同,指标倾向于在时间维度上聚合数据,这样会减少系统资源消耗,但是会丢失一些信息;在监控系统中为了性能通常会做一些合理的取舍。
时间序列是信息随时间的变化的记录。指标中的时间序列格式全部按照标准使用数值表示。
数据模型
数据类型
Values 指标值
指标值必须为 floating 或者 integers. 注意:有的指标接受者可能只支持floating .必须支持非实数值 NaN、+Inf 和 -Inf。 NaN 不能被视为缺失值,但它可以用于表示除以零。布尔值必须用数值表示且遵循: 1true, 0false.
Timestamps 时间戳
时间戳必须是以秒为单位的 Unix 时间戳。 可以使用负时间戳。
字符串 Strings
字符串必须仅由有效的 UTF-8 字符组成,并且长度可以为零。 必须支持 NULL (ASCII 0x0)
Lable 标签
标签是由字符串组成的键值对。
以下划线开头的标签名称是保留的,除非本标准规定,否则不得使用。 标签名称必须遵循 ABNF 部分中的限制。
LabelSet 标签集
一个标签集必须由标签组成并且可以为空。 标签名称在标签集中必须是唯一的。
MetricPoint 指标点
每个 MetricPoint 由一组值组成,具体取决于 MetricFamily 类型。
Exemplars 示例
示例是对 MetricSet 之外的数据的引用。 一个常见的用例是程序跟踪的 ID。
示例必须由一个标签集和一个值组成,并且可以有一个时间戳。 它们可能与 MetricPoints 的 LabelSet 和时间戳不同。
示例标签集的标签名称和值的组合长度不得超过 128 个 UTF-8 字符。 示例的文本呈现中的其他字符(例如“,=”)不包括在此限制中,以实现简单性以及文本和原型格式之间的一致性。
接收者可以丢弃示例
Metric 指标
指标由MetricFamily 中的唯一LabelSet 定义。 Metrics 必须包含一个或多个 MetricPoints 的列表。 对于给定 MetricFamily 的指标 如果指标名相同那么他们的标签集也应该相同。
MetricFamily 指标族
一个 MetricFamily 可以有零个或多个指标。 MetricFamily 必须具有名称、HELP、TYPE 和 UNIT 元数据。 MetricFamily 中的每个 Metric 都必须有一个唯一的 LabelSet。
Name
MetricFamily 名称是一个字符串,并且在 MetricSet 中必须是唯一的。 名称应该遵循蛇形命名法。指标名称必须遵 循 ABNF 部分中的限制。
MetricFamily 名称中的冒号被保留以表示 MetricFamily 是通用监控系统的计算或聚合的结果。
以下划线开头的 MetricFamily 名称是保留的,除非本标准指定,否则不得使用。
Suffixes
后缀名不得与指标名存在潜在冲突。比如有两个指标"foo" "foo_created", 如果后缀名为"_created", 那么可能导致名称混乱
不同指标类型的常规后缀:
- Counter: '_total', '_created'
- Summary: '_count', '_sum', '_created', '' (empty)
- Histogram: '_count', '_sum', '_bucket', '_created'
- GaugeHistogram: '_gcount', '_gsum', '_bucket'
- Info: '_info'
- Gauge: '' (empty)
- StateSet: '' (empty)
- Unknown: '' (empty)
Type
类型指定 MetricFamily 类型。 有效值为“unknown”、“gauge”、“counter”、“stateset”、“info”、“histogram”、“gaugehistogram”和“summary”。
Unit
单位
Help
help是一个字符串,应该是非空的。 它提供一个简要描述,并且应该足够短以用作工具提示。
MetricSet 指标集
指标集是openMetrics最外层的对象,它必须由 MetricFamilies 组成,并且可以为空。每个 MetricFamily 名称必须是唯一的。 同一个MetricSet 中的不同Metric不应该有重复的label。
MetricSet 中不需要特定的 MetricFamilies 排序。
指标类型
Gauge
Gauge是当前的测量值,例如当前使用的内存字节数或队列中的项目数,gauge非常适合需要使用绝对值的场景。
Metric 中类型为 Gauge 的 MetricPoint 必须具有单个值。gauge可能会随着时间的推移而增加、减少或保持不变。 即使它们只朝一个方向前进,它们也可能仍然是gauge而不是counter。 日志文件的大小通常只会增加,资源可能会减少,而队列大小的限制可能是恒定的。gauge可以用于编码枚举,其中枚举具有许多状态并随时间变化,这是最有效但是用户友好性比较差。
Counter
计数器测量离散事件。 常见示例是收到的 HTTP 请求数、花费的 CPU 秒数或发送的字节数。 对于计数器而言,适合度量某些随时间增加快慢的场景使用。
类型为 Counter 的 Metric 中的 MetricPoint 必须具有一个称Total的值。 总量是一个非空值,并且必须从 0 开始随时间单调递增。Metric 中类型为 Counter 的 MetricPoint 应该有一个名为 Created 的 Timestamp 值。 这可以帮助摄取者区分新的指标和之前没有看到的长期运行的指标。Metric 计数器的 Total 中的 MetricPoint 可以重置为 0。如果存在,相应的 Created 时间也必须设置为重置的时间戳。Metric 的计数器的 Total 中的 MetricPoint 可能有一个示例。
StateSet
StateSet 表示一系列相关的布尔值,也称为位集。 如果 ENUM 需要编码,这可以通过 StateSet 来完成。StateSet 度量的一个点可能包含多个状态,并且每个状态必须包含一个布尔值。 状态有一个字符串名称。StateSet Metric 的 LabelSet 不得具有与其 MetricFamily 名称相同的标签名称。如果编码为 StateSet,则 ENUM 必须恰好有一个在 MetricPoint 中为真的布尔值。这适用于枚举值随时间变化的情况,并且状态的数量不多。
Info
信息指标用于公开在流程生命周期内不应更改的文本信息。 常见示例是应用程序的版本、修订控制提交和编译器的版本。
Histogram
直方图度量离散事件的分布。常见示例是 HTTP 请求的延迟、函数运行时或 I/O 请求大小。直方图 MetricPoint 必须至少包含一个bucket,并且应该包含 Sum 和 Created 值。每个bucket必须有一个阈值和其值。直方图 MetricPoints 必须至少有一个带有 +Inf 阈值的bucket。bucket必须递增的。
举一个以秒为单位表示请求延迟的指标的示例,其阈值为 1、2、3 和+Inf,bucket的值必须遵循 value_1 <= value_2 <= value_3 <= value_+Inf。如果 10 个请求每个需要 1 秒,则分布在1、2、3 和 +Inf bucket的个数之和必须等于 10。
+Inf 存储bucket计算所有请求。如果存在,总和值必须等于所有测量事件值的总和。 MetricPoint 内的bucket阈值必须是唯一的。
#普通直方图数据
foo_bucket{le=“1”} 9000
foo_bucket{le=“2”} 300
foo_bucket{le=“3”} 150
foo_bucket{le=“4”} 100
foo_bucket{le=“5”} 110
foo_bucket{le=“6”} 130
foo_bucket{le=“7”} 100
foo_bucket{le=“8”} 50
foo_bucket{le=“9”} 40
foo_bucket{le=“10”} 20
foo_bucket{le=“+Inf”} 0
foo_count 1000
foo_sum 13440
foo_created 1520430000.123
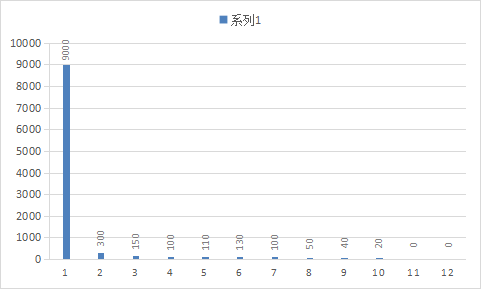
3 + 1 * (50 / 100) = 3.5
#累计直方图数据
foo_bucket{le=“1”} 9000
foo_bucket{le=“2”} 9300
foo_bucket{le=“3”} 9450
foo_bucket{le=“4”} 9550
foo_bucket{le=“5”} 9660
foo_bucket{le=“6”} 9790
foo_bucket{le=“7”} 9890
foo_bucket{le=“8”} 9940
foo_bucket{le=“9”} 9980
foo_bucket{le=“10”} 10000
foo_bucket{le=“+Inf”} 10000
foo_count 1000
foo_sum 13440
foo_created 1520430000.123
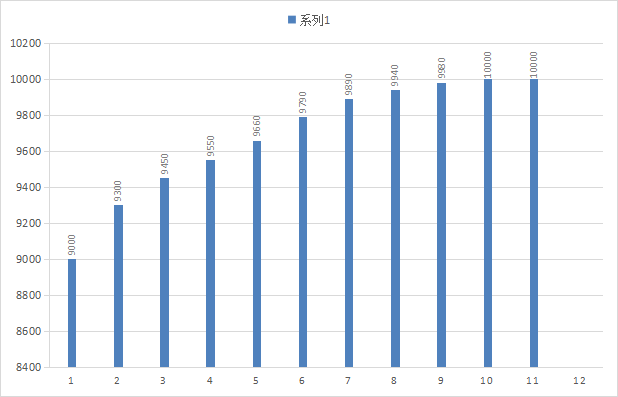
在实际应用中,总有个别指标值与平均值相差较大,这时候去计算平均值,最大值,最小值都不能准确反应出指标所代表的意义,而这种现象被称为长尾问题。为了区分是平均的慢还是长尾的慢,最简单的方式就是查看指标的分布情况,这时就要用到直方图了。
GAUGEHistogram
Summary
统计值度量离散事件的分布,并且可以在直方图过于消耗性能或平均值足够时使用。与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。
#summary值示例:
foo_count 17.0
foo_sum 324789.3
foo_avg
foo_max
foo_min
foo_created 1520430000.123
分位值示例:
foo{quantile=“0.95”} 123.7
foo{quantile=“0.99”} 150.0
foo{quantile=“0.90”}
Unknown
数据传输&格式
协议协商
Protobuf 格式
设计注意事项
主要考虑字符串长度限制
安全考虑
传输过程中的加密
问题
错误 错误率 错误分布 用户该如何暴露
tag维度(变化维度)查询性能 存储性能

















 2462
2462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









