




 复旦大学邱锡鹏教授解析ChatGPT的关键技术,包括情景学习、思维链、自然指令学习,以及大模型的涌现能力。ChatGPT通过大规模预训练获取知识,其对话能力源于产品创新。同时,文章探讨了构建大语言模型的四个维度,并指出ChatGPT的局限性在于不可控性、推理能力和实时交互性。
复旦大学邱锡鹏教授解析ChatGPT的关键技术,包括情景学习、思维链、自然指令学习,以及大模型的涌现能力。ChatGPT通过大规模预训练获取知识,其对话能力源于产品创新。同时,文章探讨了构建大语言模型的四个维度,并指出ChatGPT的局限性在于不可控性、推理能力和实时交互性。
内容来源:ChatGPT 及大模型专题研讨会
分享嘉宾:复旦大教授 邱锡鹏
分享主题:《对话式大型语言模型》
转载自优快云稿件
ChapGPT 自问世以来,便展现出了令世人惊艳的对话能力。仅用两个月时间,ChatGPT 月活跃用户就达一亿,是史上用户增速最快的消费应用。对于学术界、工业界、或是其他相关应用来说都是一个非常大的机会和挑战。事实上,ChatGPT 的成功并不是偶然结果,其背后多有创新之处。本文整理于达观数据参与承办的「ChatGPT 及大模型专题研讨会」上,复旦大学邱锡鹏教授带来的《对话式大型语言模型》主题分享,他从大规模预训练语言模型带来的变化、ChatGPT 的关键技术及其局限性等角度深入地介绍了大规模语言模型的相关知识。

邱锡鹏,复旦大学计算机学院教授,MOSS 系统负责人
为什么是大语言模型?
随着算力的不断提升,语言模型已经从最初基于概率预测的模型发展到基于 Transformer 架构的预训练语言模型,并逐步走向大模型的时代。为什么要突出大语言模型或是在前面加个“Large”?更重要的是它的涌现能力。
当模型规模较小时,模型的性能和参数大致符合比例定律,即模型的性能提升和参数增长基本呈线性关系。然而,当 GPT-3/ChatGPT 这种千亿级别的大规模模型被提出后,人们发现其可以打破比例定律,实现模型能力质的飞跃。这些能力也被称为大模型的“涌现能力”(如理解人类指令等)。
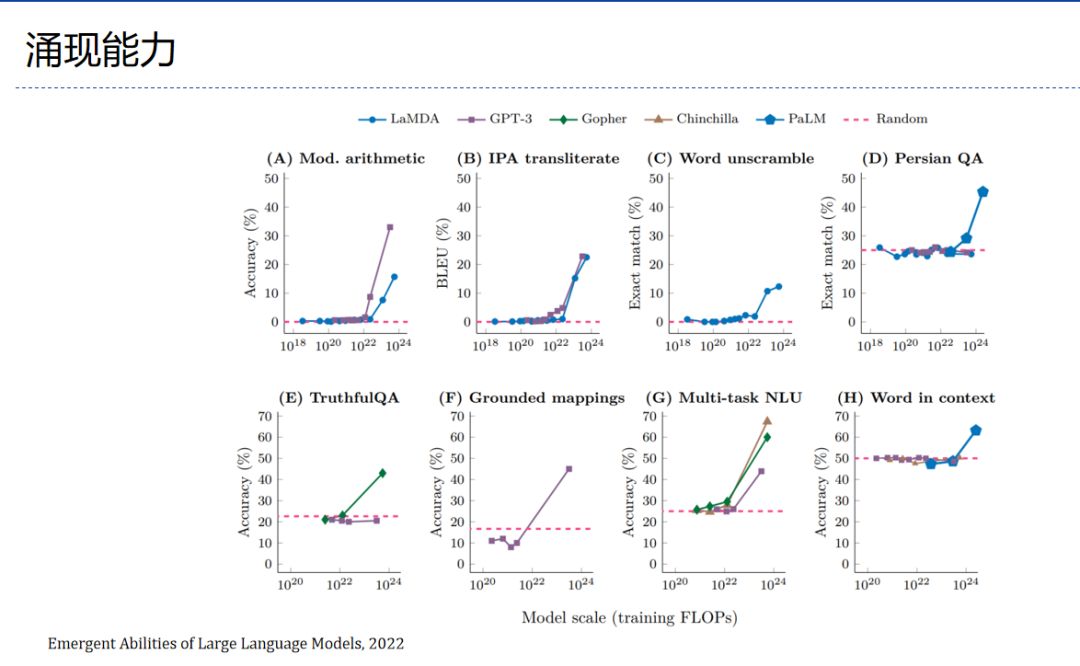
上图是多个 NLP 任务随着模型规模扩大的性能变化曲线,可以看到,前期性能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









