




 DataPipeline最新版本支持一个数据源实时或定时分发到多个目的地,解决了资源浪费和管理不便的问题。扩展了Hive使用场景,允许自定义分区字段并支持Hive作为数据源进行定时分发。此外,新推出的批量读取模式2.0,让用户在无BINLOG权限的情况下也能进行增量数据同步,通过WHERE条件定制化同步策略,降低了配置成本。
DataPipeline最新版本支持一个数据源实时或定时分发到多个目的地,解决了资源浪费和管理不便的问题。扩展了Hive使用场景,允许自定义分区字段并支持Hive作为数据源进行定时分发。此外,新推出的批量读取模式2.0,让用户在无BINLOG权限的情况下也能进行增量数据同步,通过WHERE条件定制化同步策略,降低了配置成本。

为能更好地服务用户,DataPipeline最新版本支持:
-
一个数据源数据同时分发(实时或定时)到多个目的地;
-
提升Hive的使用场景:
写入Hive目的地时,支持选择任意目标表字段作为分区字段;
可将Hive作为数据源定时分发到多个目的地。
-
定时同步关系型数据库数据时,可自定义读取策略来满足各个表的同步增量需求。
本篇将首先介绍一下一对多数据分发及批量读取模式2.0的功能,后续功能会在官微陆续发布。
推出「一对多数据分发」的背景
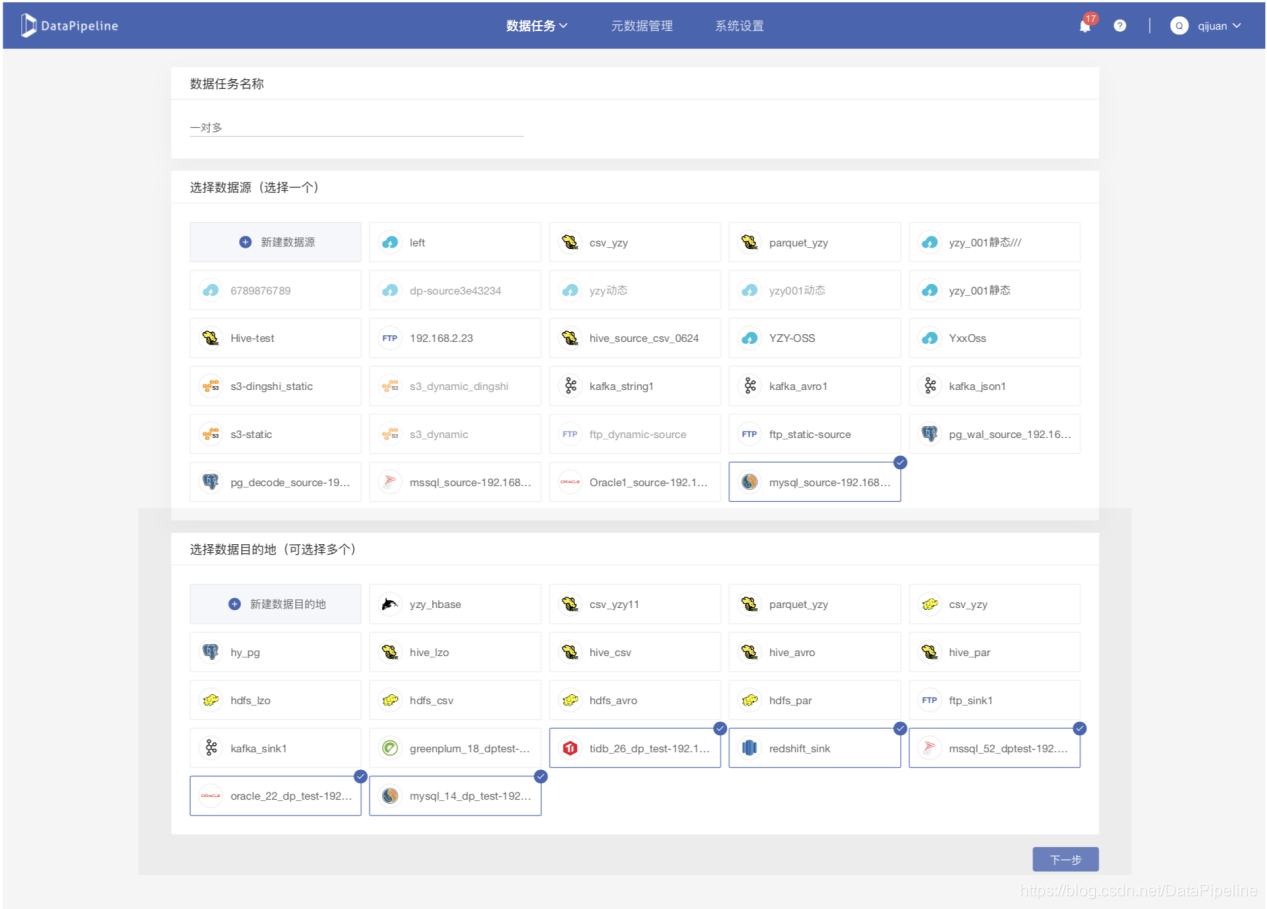
在历史版本中,DataPipeline每个任务只允许有一个数据源和目的地,从数据源读取的数据只允许写入到一张目标表。这会导致无法完美地支持客户的两个需求场景:
需求场景一:
客户从一个API数据源或者从KafkaTopic获取JSON数据后,通过高级清洗解析写入到目的地多个表或者多个数据库中,但历史版本无法同时写入到多个目的地,只能创建多个任务。这会导致数据源端会重复获取同一批数据(而且无法完全保证数据一致性),浪费资源,并且无法统一管理。
需求场景二:
客户希望创建一个数据任务,并从一个关系型数据库表实时(或定时)分发到多个数据目的地。在历史版本中,用户需要创建多个任务来解决,但创建多个任务执行该需求时会重复读取数据源同一张表的数据,比较浪费资源。客户更希望只读取一次便可直接解析为多个表,完成该需求场景。
新功能解决的问题:
-
用户在一个数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









