




 DataKit是一款开源的一体化数据采集平台,支持多种环境下的统一数据采集,包括Metrics、Logs、Traces等,具备强大的扩展性和配置管理能力。
DataKit是一款开源的一体化数据采集平台,支持多种环境下的统一数据采集,包括Metrics、Logs、Traces等,具备强大的扩展性和配置管理能力。
前言
随着云、云原生的发展,越来越多的客户意识到了“数据”的重要性,纷纷掀起了一波数据累积浪潮。
现今,国内外都有大量的数据采集器,但大多数采集能力单一,比如 Telegraf 仅支持指标,Filebeat只服务日志,OpenTelemetry 的 Collector对非云原生的组件并不友好,需要大量安装 Exporter插件。为了实现系统的可观测性,需要使用多个采集器,造成资源浪费。
Datakit 是目前唯一的真正一体化实现各种环境(传统环境,云/云原生)统一数据采集平台,一个进程或 Daemonset Pod就可以实现全方位的数据采集,配置体验良好,开源且可扩展性强。本文将全面介绍 Datakit 相关功能。
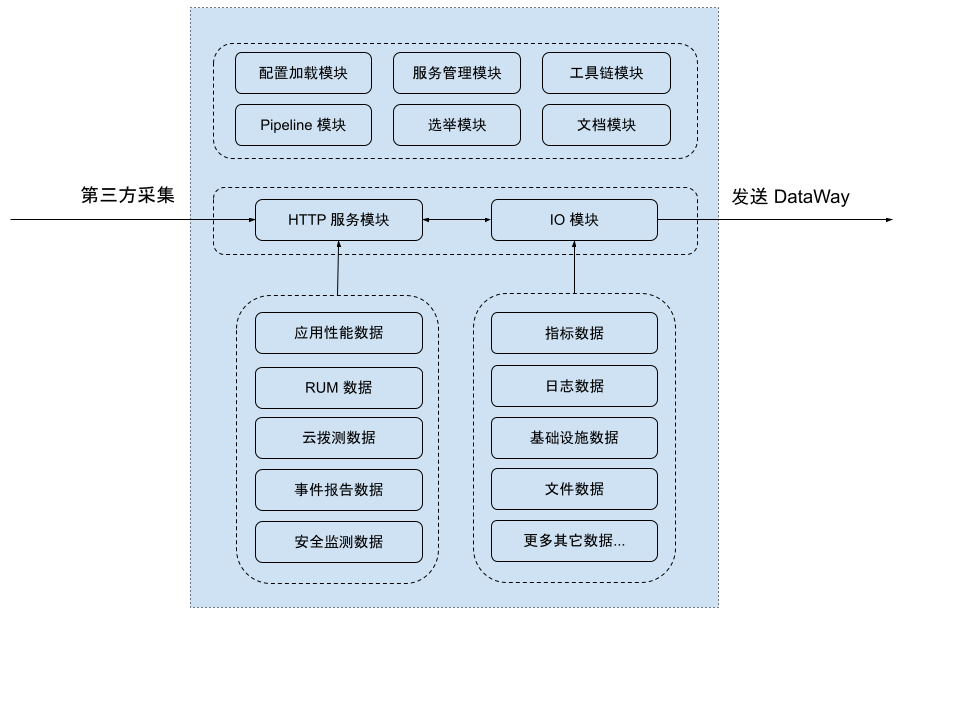
(DataKit 内部架构)
多维度可观测性数据采集
Datakit 支持从各种基础设施、技术栈中采集 Metrics、Logs、Traces 等数据,并对这些数据进行结构化处理。
1、实时基础设施对象
DataKit 支持从主机,容器,k8s,进程,云产品,所有基础设施对象实时状态一网打尽。例如:
- Datakit hostobject 用于收集主机基本信息,如硬件型号、基础资源消耗等。
- 进程采集器可以对系统中各种运行的进程进行实施监控, 获取、分析进程运行时各项指标,包括内存使用率、占用CPU时间、进程当前状态、进程监听的端口等,并根据进程运行时的各项指标信息,用户可以在观测云中配置相关告警,使用户了解进程的状态,在进程发生故障时,可以及时对发生故障的进程进行维护。
2、指标
相比 Telegraf 只能采集时序数据,DataKit 涵盖更为全面的数据采集类型,有海量的技术栈的指标收集能力,采集器的配置更简单,数据质量更好。
3、日志
日志数据对于整体的可观测性,其提供了足够灵活、多变的的信息组合方式,正因如此,相比指标和 Tracing,日志的采集、处理方式方案更多,以适应不同环境、架构以及技术栈的采集场景。
从磁盘文件获取日志
这是最原始的日志处理方式,不管是对开发者而言,还是传统的日志收集方案而言,日志最开始一般都是直接写到磁盘文件的,写到磁盘文件的日志有如下几个特点:
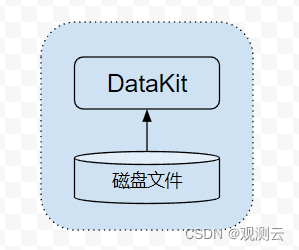
- 序列式写入:一般的日志框架,都能保证磁盘文件中的日志,保持时间的序列性
- 自动切片:由于磁盘日志文件都是物理递增的,为避免日志将磁盘打爆,一般日志框架都会自动做切割,或者通过一些外部常驻脚本来实现日志切割
基于以上特征,DataKit 只需要要持续盯住这些文件的变更即可(即采集最新的更新),一旦有日志写入,则 DataKit 就能采集到,而且其部署也很简单,只需要在日志采集器的 conf 中填写要采集的文件路径(或通配路径)即可。
通过调用环境 API 获取日志
这种采集方式目前主要针对容器环境中的 stdout 日志,这种日志要求运行在容器(或 Kubernetes Pod)中的应用将日志输出到 stdout,然后通过 Docker 的日志接口,将对应 stdout 上的日志同步到 DataKit。
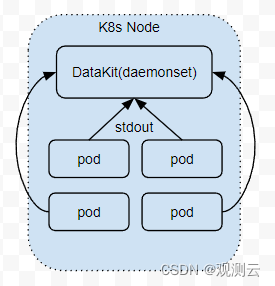
远程推送日志给 DataKit
对远程日志推送而言,其主要是
- 开发者直接将应用日志推送到 DataKit 指定的服务上,比如 Java 的 log4j 以及 Python 原生的 SocketHandler
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









