




 本文详细介绍了机器学习任务攻略,包括数据预处理、模型选择与调整、正则化、过拟合处理等关键步骤。同时,讨论了模型训练质量的判断标准,如性能指标、过拟合与欠拟合的识别,并提供了过拟合的修复方法,如数据增强和模型限制。
本文详细介绍了机器学习任务攻略,包括数据预处理、模型选择与调整、正则化、过拟合处理等关键步骤。同时,讨论了模型训练质量的判断标准,如性能指标、过拟合与欠拟合的识别,并提供了过拟合的修复方法,如数据增强和模型限制。
【ML】机器学习任务攻略 4
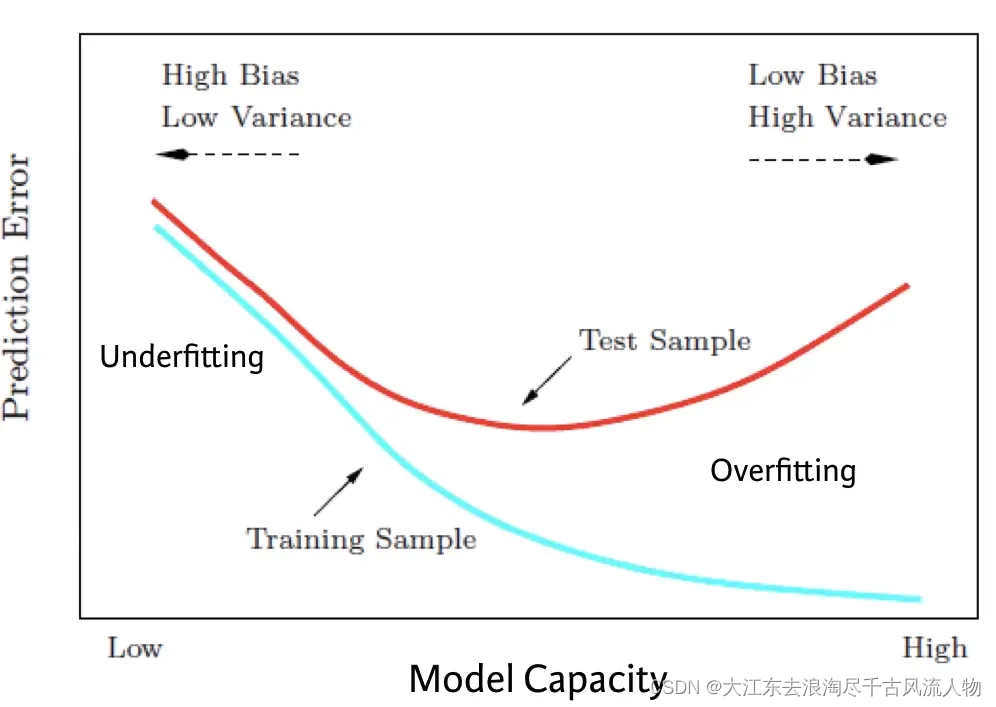
1. 机器学习任务攻略
优化机器学习模型以获得更好的性能是一个涉及多个方面的任务。以下是一些关键的策略和方法,可以帮助提升模型的性能:
1.1 数据预处理
- 数据清洗:移除或填补缺失值,处理异常值。
- 特征工程:选择和构建对模型有用的特征,进行特征选择和降维。
- 数据增强:通过旋转、缩放、裁剪等手段人为增加数据集的多样性,特别是在图像处理中。
- 归一化/标准化:确保所有特征都在相同的尺度上,以避免某些特征在模型中占主导地位。
1.2 模型选择与调整
- 选择模型:根据问题的性质选择合适的模型,如决策树、支持向量机、神经网络等。
- 超参数调整:使用网格搜索、随机搜索或贝叶斯优化等方法来找到最佳的超参数组合。
- 集成学习:使用Bagging、Boosting或Stacking等集成方法来结合多个模型,提高预测性能。
1.3. 交叉验证与评估
- 交叉验证:使用k折交叉验证等方法来评估模型的泛化能力,避免过拟合。
- 性能指标:选择合适的评估指标,如准确率、召回率、F1分数、ROC曲线等,根据问题的具体需求来优化。
1.4. 正则化与避免过拟合
- 正则化:应用L1(Lasso)或L2(Ridge)正则化来减少模型复杂度。
- 早停法:在训练过程中监控验证集的性能,当性能不再提升时停止训练,以避免过拟合。
- Dropout:对于神经网络,使用Dropout技术在训练过程中随机丢弃一些节点,减少过拟合。
1.5. 优化算法与学习率调整
- 优化器选择:选择适合问题的优化算法,如SGD、Adam、RMSprop等。
- 学习率调整:使用学习率衰减策略,或利用学习率预热和循环学习率调整技术。
1.6. 特征选择与降维
- 特征选择:通过统计测试、基于模型的特征重要性评估等方法选择最有影响力的特征。
- 降维技术:应用PCA、t-SNE等降维技术减少数据的维度,提高计算效率。
1.7. 处理类别不平衡
- 重采样:对少数类别进行过采样或对多数类别进行欠采样。
- 修改损失函数:使用类别权重或自定义损失函数来平衡不同类别的重要性。
1.8. 软件和硬件优化
- 并行计算:利用多核CPU或GPU进行并行计算,加速模型训练。
- 模型蒸馏:将大型复杂模型的知识转移到更小、更快的模型中。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4万+
4万+




 到【灌水乐园】发言
到【灌水乐园】发言









