




 本文介绍了Python的正则表达式库re,包括匹配原则、常用方法如match、search、findall,以及正则表达式的特殊字符和操作符。讨论了贪婪性和分组,并提到了模式匹配的选项如re.IGNORECASE、re.MULTILINE等。
本文介绍了Python的正则表达式库re,包括匹配原则、常用方法如match、search、findall,以及正则表达式的特殊字符和操作符。讨论了贪婪性和分组,并提到了模式匹配的选项如re.IGNORECASE、re.MULTILINE等。
正则表达式(regular expression):精确匹配或者模糊匹配
所有的语言使用的正则大同小异
正则的用处:
1、爬虫
2、分析日志
正则的匹配原则:从第一个字符逐一尝试匹配,返回最长的匹配内容(正则的贪婪性,尽可能多的匹配)
正则的匹配方法:
1、match(一个匹配结果):表示从字符串的第一个字符开始匹配,如果从第一个字符就不能匹配上,则匹配失败,返回None
2、search(一个匹配结果):表示从字符串任意位置匹配1次即可,遍历完整个字符串仍匹配不到的,则匹配失败,返回None
3、findall(多个匹配结果):表示匹配所有正则表达式匹配的内容,返回列表
4、group:将所有正则表达式匹配的内容显示出来
正则的扫描顺序:从第一个字符开始向后扫描
re.match(r"1",“1b”) 匹配对象,匹配到后,就不再向后匹配了
re.match(r"1",“0b”) None,第一个就没匹配上,就不再向后匹配了
re.search(r"1",“ab1d”) 匹配对象,就不再向后匹配了
re.search(r"1",“abcd”) None,把所有的字符串内容扫描一遍
re.search(r"\d+",“ab113d”) 匹配对象113,就不再向后匹配了
\d:匹配数字
\D:匹配非数字
\w:匹配数字和字母(大小写均包含)
\W:匹配非数字和字母
\s:匹配空白(" " \t \r \n)
\S:匹配非空白
\b:匹配边界
.:匹配除回车外的任意字符
+:匹配一个或多个
*:匹配0个或多个
?:匹配0次或1次,非贪婪,表示抑制正则表达式的贪婪性
正则表达式的贪婪性,尽量多匹配。
{a,b}:表示匹配a个到b个
[a-zA-Z]:[]中是或的关系,这里表示匹配一个字母
r是元字符,正则表达式前面加上r,表示正则表达式中的内容不转义
使用正则表达式需导入re包
#字符串类型才可模式匹配,也就是下面例子中"1abc"这个位置的内容必须为字符串格式
import re
print(re.match(r"1","1abc")) #r"1"是正则表达式,"1abc"是匹配的目标字符串
print(re.match(r"1","1abc").group())

分组:()小括号中的内容表示分组的内容
group()等价于group(0),表示返回匹配到的整个字符串,group(1)表示返回匹配到的第一个分组
print(re.search(r"a(\d+)c","a11232c").group())
print(re.search(r"a(\d+)c","a11232c").group(1))

?单独使用,表示匹配0次或1次,从字符串的第一个字符开始匹配,如果匹配不到则返回空,匹配得到则返回第一个匹配的内容
print(re.search(r'\d?','a3bf 2g').group())
print(re.search(r'\w?','a3bf 2g').group())

.匹配任意一个字符,除了回车
print(re.match(r'a.c','abc'))
print(re.match(r'a.c','a*c'))
print(re.match(r'a.c','a\nc'))
print(re.match(r'a.c','a c'))
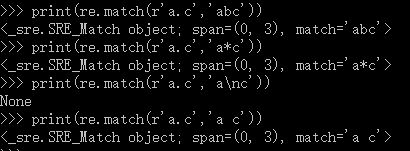
[]中的内容为或的关系,匹配一个字符
print(re.match(r'[abc]','a'))
print(re.match(r'[abc]','b'))
print(re.match(r'[abc]','d'))
print(re.match(r'[abc]','ab'))
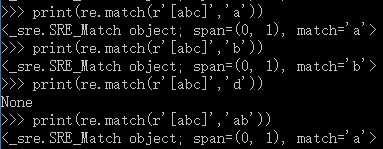
+匹配一个或多个,*匹配0个或多个
print(re.search(r'[abc]+','1abc2'))
print(re.search(r'[abc]*','1abc2'))
print(re.search(r'[abc]+','abc12'))
print(re.search(r'[abc]*','abc12'))
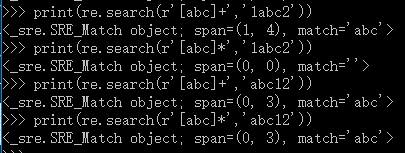
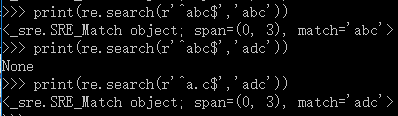
search + ‘^’,表示以xxx开头
search + ‘$’,表示以xxx结尾
print(re.search(r'^abc','111abc'))
print(re.search(r'^abc','abc111'))
print(re.search(r'a.c$','1111adc'))
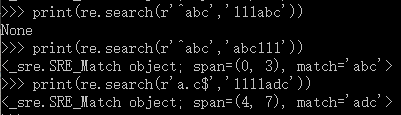
以a开头,以c结尾
print(re.search(r'^abc$','abc'))
print(re.search(r'^abc$','adc'))
print(re.search(r'^a.c$','adc'))
\A匹配开头,\Z匹配结尾,与 ^ 和 $ 一样
print(re.match(r'\Aabc\Z','abc'))
print(re.match(r'\Aabc\Z','abc2'))

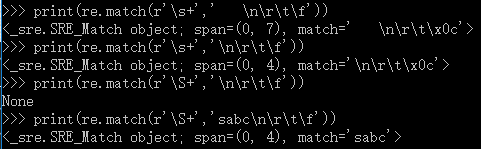
\s 匹配空白,\S 匹配非空白
print(re.match(r'\s+',' \n\r\t\f'))
print(re.match(r'\s+','\n\r\t\f'))
print(re.match(r'\S+','\n\r\t\f'))
print(re.match(r'\S+','sabc\n\r\t\f'))
\b匹配边界
print(re.search(r'\babc\b','abc2'))
print(re.search(r'\babc\b','abc'))
print(re.search(r'\babc\b','1 abc'))
print(re.search(r'\babc\b','aabc '))
print(re.search(r'\babc\b','1 abc '))

|或
print(re.match(r'ab|cd','ab123'))
print(re.match(r'ab|cd','cd123'))

findall用法
匹配一句话中的单词,不要标点
s = "I have a cat!"
print(re.findall(r"\w+",s))
s = "I have 5 cats!"
print(re.findall(r"[a-zA-Z]+",s))
print(re.findall(r"\w+",s))

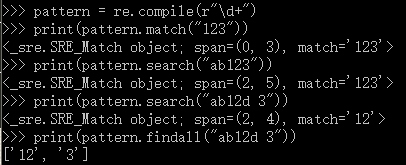
每次匹配都要手动再写一次正则表达式,如果一个正则表达式使用比较频繁,可以把它编译成一个模式,这样每次使用就不用重复写正则表达式,编译compile,可以复用
pattern = re.compile(r"\d+")
print(pattern.match("123"))
print(pattern.search("ab123"))
print(pattern.search("ab12d 3"))
print(pattern.findall("ab12d 3"))
re.I 全写(re.IGNORECASE),表示使匹配时,忽略大小写 2
re.M 全写(re.MULTILINE),多行匹配,影响 ^ 和 $的行为 8
re.S 全写(re.DOTALL),使点(.)匹配包括换行在内的所有字符 16
re.X 全写(re.VERBOSE),该标志通过给予你更灵活的格式以便你将正
则表达式写得更易于理解。详细模式。这个模式下正则表达式可
以是多行,忽略空白字符,并可以加入注释。 64
加上模式(或者模式对应的数字),可以使正则表达式更加灵活
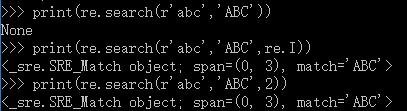
print(re.search(r'abc','ABC'))
print(re.search(r'abc','ABC',re.I))
print(re.search(r'abc','ABC',2))
re.M 以多行模式匹配
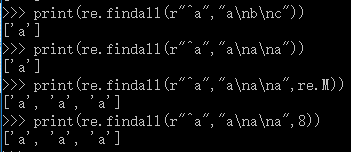
print(re.findall(r"^a","a\nb\nc"))
print(re.findall(r"^a","a\na\na"))
print(re.findall(r"^a","a\na\na",re.M))
print(re.findall(r"^a","a\na\na",8))
re.DOTALL /re.S 点匹配任意字符
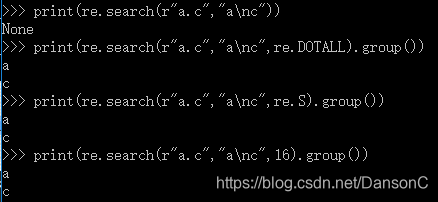
print(re.search(r"a.c","a\nc"))
print(re.search(r"a.c","a\nc",re.DOTALL).group())
print(re.search(r"a.c","a\nc",re.S).group())
print(re.search(r"a.c","a\nc",16).group())
re.X加注释
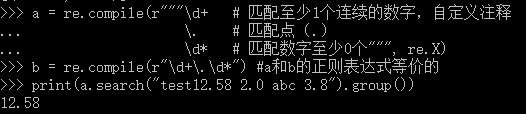
a = re.compile(r"""\d+ # 匹配至少1个连续的数字,自定义注释
\. # 匹配点(.)
\d* # 匹配数字至少0个""", re.X)
b = re.compile(r"\d+\.\d*") #a和b的正则表达式等价的
print(a.search("test12.58 2.0 abc 3.8").group())
多个模式
print(re.findall(r"^a","a\na\nA",re.M|re.I))
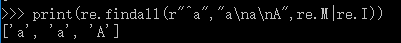
有多少个分组,用处不大
p = re.compile(r'(\w+) (\w+) (?P<sign>.*)',re.S)
print(p.groups)
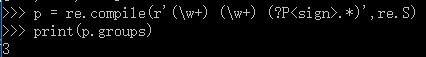
命名分组,命名为sign,相当于一个变量名,按sign取值
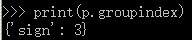
p = re.compile(r'(\w+) (\w+) (?P<sign>.*)',re.S)
print(p.match("a b c").group("sign"))

命名分组放在第几个
print(p.groupindex)
指定范围匹配
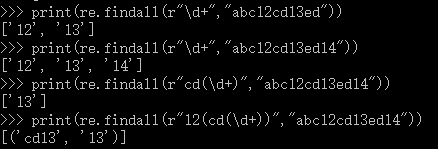
print(re.findall(r"\d+","abc12cd13ed"))
print(re.findall(r"\d+","abc12cd13ed14"))
print(re.findall(r"cd(\d+)","abc12cd13ed14"))
print(re.findall(r"12(cd(\d+))","abc12cd13ed14"))
正则切割字符串
split切割,sub替换
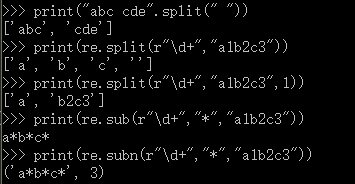
print("abc cde".split(" "))
print(re.split(r"\d+","a1b2c3"))
print(re.split(r"\d+","a1b2c3",1))
print(re.sub(r"\d+","*","a1b2c3"))
print(re.subn(r"\d+","*","a1b2c3")) #subn 返回替换后的字符串和替换的次数组成的元组

















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









