







 本文介绍如何使用Python的Scrapy框架抓取豆瓣电影数据,包括电影名称、图片、评分等信息,用于个人网站的电影板块建设。文章详细展示了代码实现过程,包括环境配置、XPath语法使用技巧及常见错误解决。
本文介绍如何使用Python的Scrapy框架抓取豆瓣电影数据,包括电影名称、图片、评分等信息,用于个人网站的电影板块建设。文章详细展示了代码实现过程,包括环境配置、XPath语法使用技巧及常见错误解决。
网站ICP备案已经完成,是时候搞一波个人网站了,先搞个电影板块,就算没看过,看看影评跟别人扯的时候也好装作自己不是周末宅的样子
环境:python3.7;scrapy1.5
工具:Chrome;Pycharm
1.在项目路径使用命令行执行
scrapy startproject projectName项目结构如下
具体可参考Scrapy官方文档
2.在Pycharm中打开该项目
配置环境为在系统中安装的python.exe,而不是某个项目中的python环境
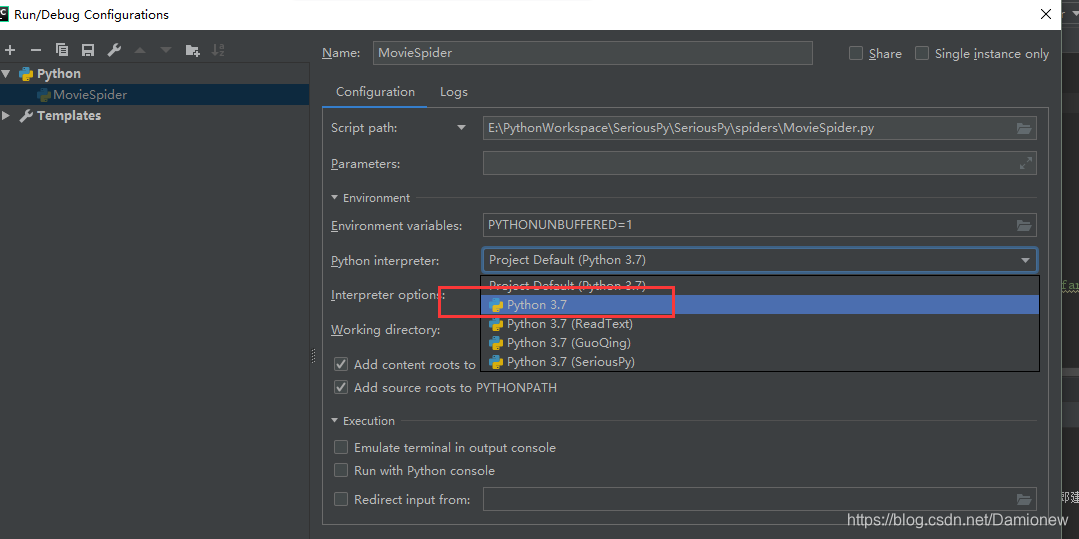
3.在创建xxxSpider.py文件
'''
为个人网站项目爬取电影数据
'''
from scrapy.spiders import Spider
from scrapy import cmdline
import pymysql
class MovieSpider(Spider):
name = "movie"
allowed_domains = ["movie.douban.com"]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
start_urls = [
"https://movie.douban.com/chart"
]
def parse(self,response):
# 提取response中所有class为indent下所有class为item的tr
for sel in response.xpath('//div[@class="indent"]//tr[@class="item"]'):
# 提取当前sel(即tr[i])下所有class为nbg的a标签的title,替换掉空格和换行,中括号
movie_name = (str(sel.xpath('.//a[@class=""][1]/text()[1]').extract())+\
str(sel.xpath('.//a[@class=""][1]/span/text()').extract()))\
.replace("\\n","").replace(" ","").replace("[","").replace("]","")
# 获取class为nbg的a标签的图片链接
movie_image = str(sel.xpath('.//a[@class="nbg"]/img/@src').extract()).replace("[", "").replace("]", "")
# 获取文字上的链接,可跳转到详细内容页面,从而获取影评
movie_url = str(sel.xpath('.//a[@class="nbg"]/@href').extract()).replace("[", "").replace("]", "")
# 获取class为pl(英文字母l)的p标签的文字
movie_desc = str(sel.xpath('.//p[@class="pl"]/text()').extract()).replace("[","").replace("]","")
# 获取class为rating_nums的span标签的文字
movie_score = str(sel.xpath('.//span[@class="rating_nums"]/text()').extract()).replace("[","").replace("]","")
# 获取class为pl(英文字母l)的span标签的文字
movie_comments_amount = str(sel.xpath('.//span[@class="pl"]/text()').extract()).replace("(","").replace(")","").replace("[","").replace("]","")
print(movie_name)
print(movie_image)
print(movie_url)
print(movie_desc)
print(movie_score)
print(movie_comments_amount)
"""
当前爬虫内启动入口
"""
cmdline.execute("scrapy crawl movie".split());有了最后一句命令,则可以调用命令行直接右键该项目运行
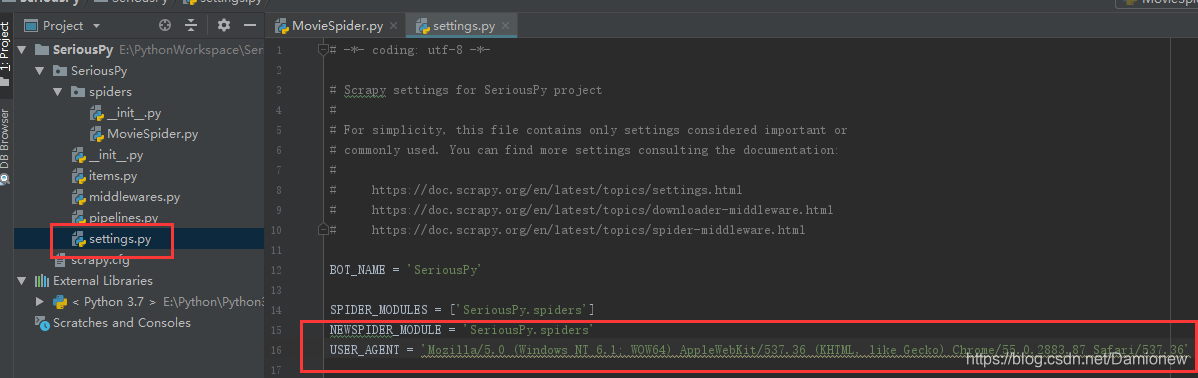
需要在seeting.py中添加User_agent,用以简单的反爬虫措施。chrome内可查看
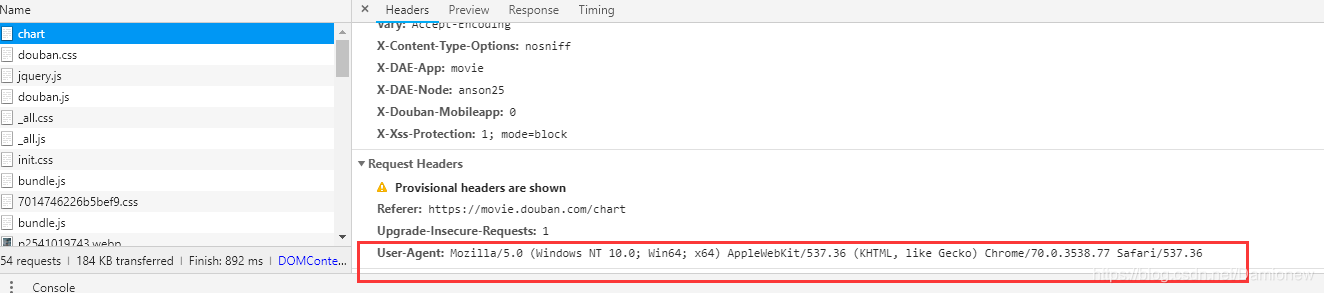
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
否则结果将返回:
2018-12-04 18:04:13 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://movie.douban.com/robots.txt> (referer: None)
2018-12-04 18:04:14 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://movie.douban.com/chart> (referer: None)
2018-12-04 18:04:14 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://movie.douban.com/chart>: HTTP status code is not handled or not allowed
"""
使用三个双引号实现段落的注释
"""
# 使用#实现行的注释
"""
需注意scrapy需要重载parse函数,如下,且def务必不可顶格,必须包含在class内部,否则将报错
Traceback (most recent call last):
File "E:\Python\Python37\lib\site-packages\twisted\internet\defer.py", line 654, in
_runCallbacks
current.result = callback(current.result, *args, **kw)
File "E:\Python\Python37\lib\site-packages\scrapy\spiders\__init__.py", line 90, in parse
raise NotImplementedError('{}.parse callback is not
defined'.format(self.__class__.__name__))
且parse函数内需要两个参数:self和response,否则将报错
Traceback (most recent call last):
File "E:\Python\Python37\lib\site-packages\twisted\internet\defer.py", line 654, in
_runCallbacks
current.result = callback(current.result, *args, **kw)
TypeError: parse() takes 1 positional argument but 2 were given
"""
def parse(self,response):
# 在使用xpath语法时,若需遍历,使用for语法
# 定义一个变量sel为通过response.xpath('自定义表达式')提取的所有数据
for sel in response.xpath('//div[@class="indent"]//tr[@class="item"]')
# 可使用pycharm调试来进行测试表达式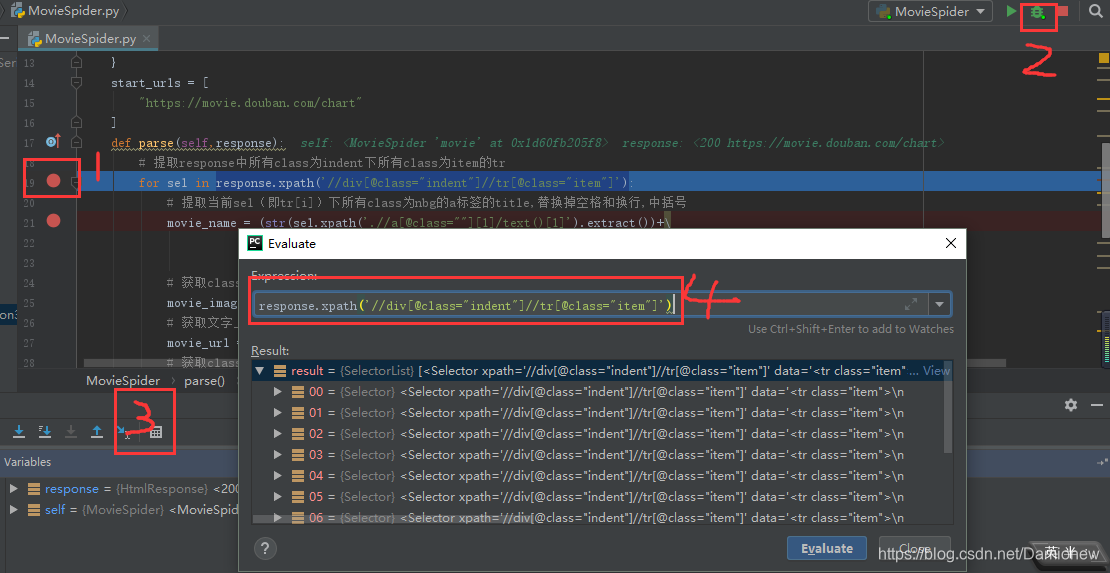
1、打断点;2、开启debug;3、使用Evaluate;4、测试表达式
部分表达式用法
# 在xpath表达式中
# 提取所有div块
sel.xpath('//div')
# 提取id为div1的div块
sel.xpath('//div[@id="div1"]')
# 提取id为div1的div块下id为div2的div块
sel.xpath('//div[@id="div1"//div[@id="div2"]')
# 提取id为div1的div块
sel.xpath('//div[@id="div1"]')
# 提取第1个a标签,注:xpath中从1开始而不是0
sel.xpath('//a[1]')
# 提取a标签下文字
sel.xpath('//a/text()')
# 提取当前内容下的div块
sell1 = sel.xpath('//div[@id="div1"]')
sell2 = sell2.xpath('.//div')
# 使用replace方法时需先将结果转为字符串型
str(sel.xpath('.//span[@class="rating_nums"]/text()').extract()).replace("1","")

















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









