



目 录
摘 要
随着城市化进程加快,地铁在城市交通中占据重要地位。传统地铁客流数据管理依赖人工统计分析,效率低下且易出错,难以满足实时精准需求。为解决此问题,本系统采用前端 Vue 和 Echarts,后端 Python 及 Flask 框架,结合 MySQL 数据库构建。系统具备管理员和普通用户功能。管理员可登录查看个人信息、管理用户、查看地铁客流数据及预测分析,包括高峰期时间段、客流量多的站点及人流量趋势预测图。普通用户可注册登录,查看个人信息、地铁客流数据及预测分析。系统通过可视化技术展示地铁客流数据,为地铁运营管理和乘客出行提供科学依据,提升地铁运营效率和乘客出行体验。
关键词:地铁客流分析、数据可视化、预测系统、Flask
Abstract
With the acceleration of urbanization, subways play an important role in urban transportation. Traditional subway passenger flow data management relies on manual statistical analysis, which is inefficient and prone to errors, making it difficult to meet real-time and accurate needs. To solve this problem, this system adopts front-end Vue and Echarts, back-end Python and Flask framework, combined with MySQL database construction. The system has both administrator and regular user functions. Administrators can log in to view personal information, manage users, view subway passenger flow data and forecast analysis, including peak hours, stations with high passenger flow, and predicted pedestrian flow trends. Ordinary users can register and log in to view personal information, subway passenger flow data, and forecast analysis. The system displays subway passenger flow data through visualization technology, providing scientific basis for subway operation management and passenger travel, improving subway operation efficiency and passenger travel experience.
Key Words:subway passenger flow analysis, data visualization, prediction system Flask
第一章 引言
地铁作为城市公共交通的重要组成部分,其发展历程与城市化进程紧密相连。自地铁首次投入运营以来,其运输能力和服务范围不断扩大,成为城市居民日常出行的重要选择。在早期,地铁运营主要依赖人工管理,工作人员通过手工记录和统计客流数据,以评估运营状况和制定调度计划。然而,这种方式效率低下,数据准确性难以保证,难以满足日益增长的地铁运营需求。随着计算机技术的飞速发展,地铁运营逐渐引入信息化管理系统,数据记录和分析的效率得到显著提升。然而,传统系统仍存在局限性,无法实时预测客流变化,难以有效应对突发情况,导致运营决策滞后,乘客出行体验受到影响。
地铁客流数据分析与预测系统应运而生,其意义在于为地铁运营提供精准的客流预测和科学的决策支持。该系统能够实时收集和分析地铁客流数据,通过先进的数据分析方法,预测未来客流趋势,帮助运营管理人员提前制定运营策略,优化列车调度,合理安排人员,提高运营效率和服务质量。系统为乘客提供出行参考,帮助其合理规划出行时间,避免高峰拥堵,提升出行体验。系统通过对客流数据的深度分析,为城市规划和地铁线路优化提供数据支持,助力城市交通可持续发展。
杨烁[1]在2024年对北京市某地铁站环控系统能耗进行分析和预测模拟,采用数据驱动方法,结合历史能耗数据和运营参数,构建预测模型,为地铁站节能提供依据。庞浩、倪海超和郝志升[2]在2024年研究地铁供电系统运行状态预测与维护,利用大数据技术挖掘供电系统数据特征,通过机器学习算法实现状态预测,为供电系统维护提供决策支持。刘小双[3]在2022年对城市夜间光环境演变进行分析和预测,虽然研究对象非地铁客流,但采用时间序列分析方法,为基于时间序列的地铁客流预测提供参考。国内研究集中在地铁系统能耗、供电状态和城市光环境等领域,学者们运用大数据、机器学习和时间序列分析等技术,构建预测模型,为地铁运营和城市环境管理提供数据支持和决策依据。
国内地铁客流数据分析与预测研究逐渐深入,学者们结合实际需求,采用多种技术手段,提升地铁运营效率和服务质量。杨烁的研究为地铁站节能提供数据支持,庞浩等人的研究助力地铁供电系统维护决策,刘小双的研究为时间序列分析在地铁客流预测中的应用提供参考。这些研究推动了地铁客流数据分析与预测技术的发展,为地铁运营和管理提供科学依据,促进地铁系统的智能化和高效化发展。
Yan H 等[4]人在2024年提出一种基于多目标集成策略的碳交易市场价格分析和预测系统,虽然研究对象为碳交易市场,但采用的技术和方法对地铁客流数据分析与预测具有借鉴意义。他们利用多目标优化算法集成多种预测模型,提高预测精度和稳定性。Kim U J 等[5]人在2020年开发一种基于深度学习算法的人工腿步态分析和预测系统,用于实时控制假肢。该研究展示了深度学习在动态系统预测中的应用潜力,为地铁客流预测提供技术思路。Guo Z[6] 在2023年研究基于大数据分析和深度学习的预测系统,虽然未明确指出应用领域,但其研究方法和技术框架对地铁客流预测系统的设计具有参考价值。国外学者在碳交易市场、假肢步态控制和大数据分析等领域开展研究,运用多目标优化、深度学习等技术,构建预测系统,为地铁客流数据分析与预测提供技术借鉴。
国外地铁客流数据分析与预测研究在技术应用和模型构建方面取得进展,学者们结合实际需求,探索新技术在地铁客流预测中的应用。Yan H 等人的研究为多目标优化在预测系统中的应用提供案例,Kim U J 等人的研究展示深度学习在动态预测中的潜力,Guo Z 的研究为大数据分析和深度学习在预测系统中的结合提供参考。这些研究推动地铁客流预测技术的发展,为地铁运营和管理提供科学依据,促进地铁系统的智能化和高效化发展。
本论文共分为七个主要章节,具体结构如下:
1. 绪论:介绍研究背景与意义,回顾国内外研究现状,并概述论文的组织结构。
2. 相关技术介绍:详细介绍与本研究相关的技术,包括Python语言、Django框架等。
3. 需求分析:对系统的功能需求和非功能需求进行分析,明确系统需求,并进行可行性分析,包括技术、操作和经济可行性。
4. 系统设计:涵盖系统架构设计、总体流程设计和功能设计,并进行数据库的概念设计与表设计。
5. 系统实现:具体描述各个功能模块的实现过程,展示系统如何根据需求进行开发。
6. 系统测试:阐述测试的目的、方法和内容,分析测试结果并得出结论,以验证系统的稳定性和功能完整性。
7. 总结:总结研究的主要成果和贡献。
本研究设计并实现一套基于机器学习算法的地铁客流数据分析与预测系统。系统的核心研究内容包括:首先,构建高效的数据采集与预处理模块,以确保地铁客流数据的准确性和完整性;其次,运用多种机器学习算法对历史客流数据进行建模与训练,实现对地铁客流量的精准预测,特别是针对高峰期及特殊时段的客流变化趋势;再次,开发可视化界面,以直观展示客流数据及预测结果,为地铁运营管理人员提供决策支持;最后,通过系统测试与优化,验证系统的可靠性与实用性,确保其能够有效提升地铁运营效率和乘客出行体验。
第二章 相关技术介绍
Python 是一种广泛应用的高级编程语言,其简洁的语法和强大的库支持在数据科学、人工智能、Web 开发等多个领域取得了显著的成功[7]。在本系统中,Python 作为后端开发语言,承担了数据处理与分析的主要工作。其丰富的库和工具集使其成为数据密集型应用的首选语言,在处理大数据和机器学习任务时表现出色。Python 支持多种编程范式,包括面向对象编程、函数式编程和过程式编程,这种灵活性使得开发人员可以根据需求选择最适合的编码方式。在垃圾处理系统中,Python 通过高效的数据处理能力,实现对垃圾分类数据、产生量、运输状态等信息的快速分析与处理[8]。
在垃圾处理系统中,Python 主要用于实现数据清洗、分析、图像识别、预测等功能。系统通过使用 Pandas 和 NumPy 等数据处理库,进行大规模垃圾数据的清洗、整理和分析。对于机器学习相关任务,Python 提供了 Scikit-learn 和 TensorFlow 等强大的库,能够对垃圾分类的图像识别任务进行训练和优化。这些库不仅加速了开发过程,还提供了强大的功能,支持多种模型的训练和评估,使得系统能够自动进行垃圾分类,提升垃圾分类的精度和效率。Python 的灵活性和丰富的生态系统使其成为数据处理、分析和机器学习的理想选择,对于提升智能垃圾处理系统的智能化和精准度具有重要作用[9]。
ECharts 是一个开源的 JavaScript 图表库,用于数据可视化,能够创建各种交互性强的图表和可视化组件。其支持多种常见的图表类型,包括折线图、柱状图、饼图、散点图、热力图,且具有良好的可扩展性和灵活性,能够通过简单的配置生成丰富的图形展示。在本系统中,ECharts 被用于前端的数据可视化部分,帮助用户直观了解垃圾分类、回收情况以及垃圾产生量的分布[10]。
ECharts 提供了丰富的可视化组件和交互功能,能够使得垃圾处理系统中的数据展示更加直观和易于理解[11]。通过使用 ECharts,系统能够将垃圾量、分类比例、回收率等数据以柱状图、饼图、漏斗图等形式展示,方便用户进行快速决策。ECharts 的数据绑定功能使得图表能够与后端数据进行实时更新,确保图表展示内容的及时性和准确性。垃圾分类和资源回收领域,ECharts 的强大可视化功能能够助城市管理者更加高效地掌握垃圾处理的情况,制定更加精准的垃圾分类和处理策略[12]。
Vue框架作为一种流行的JavaScript前端框架,具有许多优点,Vue的设计理念注重简洁性和可读性,其API设计简单直观,易于上手[13]。新手开发者可以很快地掌握Vue的基本概念和用法,降低了学习成本。Vue采用组件化的开发方式,将页面拆分成独立的组件,每个组件负责自己的功能和样式[14]。这种模块化的开发方式使得代码更易于维护和重用,同时也提高了团队协作的效率。Vue提供了响应式的数据绑定机制,当数据发生变化时,页面会自动更新,无需手动操作DOM[15]。
Flask 是一种用 Python 编写的轻量级 Web 应用框架。它能够用于构建 Web 应用程序,通过提供一系列工具和功能,帮助开发者快速搭建 Web 服务[16]。Flask 允许开发者定义路由,将 URL 映射到对应的处理函数,从而实现对不同请求的响应。它支持模板渲染,可以使用 Jinja2 模板引擎将动态数据与静态模板结合,生成 HTML 页面。Flask 提供请求和响应对象,用于处理 HTTP 请求和生成 HTTP 响应,包括获取请求参数、设置响应头等操作[17]。Flask 支持扩展机制,可以通过安装扩展来增加额外的功能,数据库操作、表单处理、用户认证等。开发者可以利用 Flask 构建 RESTful API,通过定义路由和视图函数,实现数据的接收和返回,满足不同客户端的请求。Flask 的灵活性使得它能够适应从小型项目到大型应用的开发需求,开发者可以根据具体需求选择合适的组件和扩展来构建应用[18]。
MySQL 是一种关系型数据库管理系统,用于存储和管理数据。它能够创建数据库,数据库是数据的集合,用于组织和存储相关的数据。在数据库中,可以创建表,表是由行和列组成的结构,用于存储具体的数据记录。MySQL 支持定义数据类型,如整数、字符串、日期等,以确保数据的正确性和一致性。它提供 SQL 语言,用于执行数据的增、删、改、查操作,通过编写 SQL 语句,可以实现对表中数据的插入、删除、更新和查询。MySQL 支持事务处理,事务是一组操作的集合,这些操作要么全部成功,要么全部失败,从而保证数据的完整性。它还提供索引功能,索引是一种数据结构,用于提高数据查询的效率,通过在表的列上创建索引,可以快速定位到所需的数据记录。MySQL 支持用户权限管理,可以创建不同的用户账号,并为每个用户分配不同的权限,如读取、插入、更新、删除等权限,从而保证数据库的安全性。MySQL 支持数据备份和恢复,可以通过备份操作将数据库的数据保存到文件中,当需要时可以通过恢复操作将数据还原到数据库中,确保数据的安全性和可靠性。
第三章 需求分析
用户功能包括登录注册、查看个人信息、查看地铁数据和预测分析。用户可进行账号注册与登录操作,登录后查看个人ID、姓名、联系电话、邮箱及头像信息。用户能够查看地铁客流数据,包括出行高峰期时间段和客流量最多的站点。用户可查看客流量随时间变化的趋势预测图。功能用例图如图3-1所示。
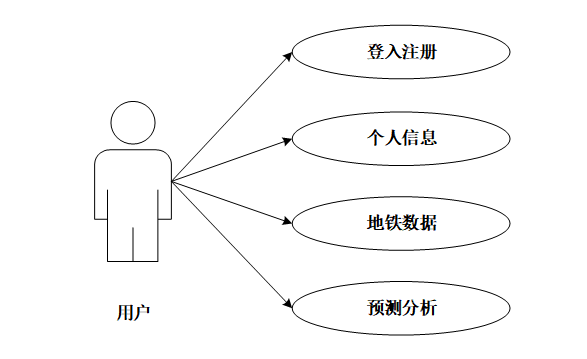
图3-1 用户功能用例图
管管理员功能包括用户管理、地铁数据管理和预测分析管理。管理员可查看系统其他用户的个人信息,管理用户账号。管理员能够查看地铁客流数据,包括出行高峰期时间段和客流量最多的站点,并进行数据管理操作。管理员还可查看客流量随时间变化的趋势预测图,并对预测分析进行管理。可进行功能用例图如图3-2所示。
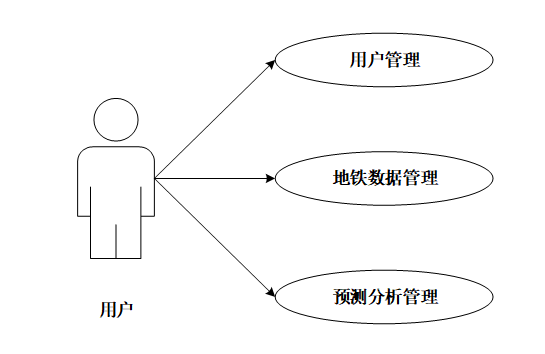
图3-2管理员功能用例图
1. 可用性
系统应具备高可用性,用户在任何时间都能顺畅访问。系统的正常运行时间应达到99.9%以上,用户不会因系统故障而影响操作体验。用户界面设计应简洁明了,降低操作复杂性。
2. 可靠性
系统需要具备高可靠性,在故障发生时能够快速恢复。数据应定期备份,在意外情况下不丢失。系统应具备故障检测机制,自动识别并处理潜在问题。
3. 安全性
系统应实现严格的安全控制,保护用户数据的隐私和完整性。用户信息应加密存储,传输过程中的数据也需采用加密协议,防止数据泄露。系统应具备权限管理功能,不同用户只能访问相应的数据和功能。
4. 可扩展性
系统设计应具备良好的可扩展性,模块化设计使得新功能可以方便地集成,系统能够支持更高的用户负载而无需重构基础架构。
5. 性能
系统的响应时间应控制在合理范围内,通常不超过2秒。
地铁客流数据分析与预测系统的技术可行性基于当前成熟的技术体系。在技术层面,Python 语言搭配 Flask 框架能够高效构建 Web 后端服务,处理复杂的业务逻辑与数据交互。Flask 提供灵活的路由机制和扩展性,可满足系统对不同功能模块的开发需求。前端采用 Vue 框架结合 Echarts 库,能够实现数据的动态可视化展示,为用户提供直观的交互体验。MySQL 数据库作为数据存储核心,具备强大的数据管理能力,支持高并发读写操作,能够存储海量的地铁客流数据并保证数据的完整性和一致性。机器学习算法为客流预测提供理论基础,通过历史数据训练模型,可实现对客流量的精准预测。这些技术的成熟度和稳定性为系统的开发与运行提供了坚实保障。
在操作层面,系统设计注重用户友好性和易用性。管理员通过登录系统,可便捷管理用户信息、查看客流数据及预测结果,操作流程简洁明了。普通用户注册登录后,能够快速获取地铁客流信息,辅助出行决策。系统界面采用直观的可视化设计,以图表形式展示数据,降低用户理解成本。从运维角度看,系统基于开源技术栈构建,社区资源丰富,便于后期维护与升级。系统采用模块化设计,各功能模块相对独立,便于单独维护和优化,降低了运维难度。整体而言,系统的操作流程和运维管理均具备较高的可行性。
经济层面,系统开发与运营成本可控。开发阶段主要投入为人力成本和软硬件购置费用。技术栈基于开源框架,降低了软件采购成本。硬件需求主要为服务器和存储设备,可根据实际需求灵活配置。运营阶段,系统维护成本相对较低,开源社区支持可减少技术支持费用。从收益角度看,系统可帮助地铁运营企业优化运营调度,降低运营成本,提升运营效率,间接带来经济效益。系统可为城市交通规划提供数据支持,减少因规划不合理导致的资源浪费,具有显著的社会经济效益。综合考虑成本与收益,系统在经济上具有较高的可行性。
社会层面,地铁客流数据分析与预测系统对城市交通管理和社会运行具有积极意义。系统通过优化地铁运营调度,可缓解高峰时段拥堵,提升乘客出行体验,减少社会资源浪费。精准的客流预测有助于城市规划部门合理规划地铁线路和站点布局,促进城市可持续发展。从环境保护角度看,系统优化运营调度可降低地铁能耗,减少碳排放,符合绿色出行理念。系统为乘客提供出行建议,引导合理出行,有助于缓解城市交通压力,提升城市整体运行效率。因此,系统在社会层面具有较高的可行性和推广价值。
第四章 随机森林算法设计
在随机森林算法设计中,首先需要从数据库中获取用户的行为数据,包括点击、评论、收藏和点赞等行为的统计信息。通过 SQL 查询语句,从 MySQL 数据库中提取相关数据,并将其整合到一个数据表中。数据表中的每一行代表一个用户对某个资源的行为记录,列包括用户ID、资源ID以及各种行为的计数。随后,对数据进行预处理,将字符串类型的字段转换为整数类型,以便算法能够处理。通过数据集的划分,将数据分为训练集和测试集,用于模型的训练和验证。
随机森林算法由多个决策树组成,每个决策树在训练过程中使用随机抽样的数据和特征子集。在构建决策树时,首先选择最佳的分割点,通过计算基尼指数来评估每个特征的分割效果。基尼指数越低,表示该特征的分割效果越好。通过递归的方式,不断分割数据,直到达到设定的最大深度或节点的样本数小于最小值。在每个节点的分割过程中,随机选择一部分特征进行评估,增加了模型的随机性和泛化能力。最终,通过多个决策树的预测结果进行投票,得到最终的预测结果。
为了评估随机森林模型的性能,采用交叉验证的方法。将数据集划分为若干个子集,每个子集轮流作为测试集,其余数据作为训练集。通过计算模型在每个测试集上的准确率,得到模型的平均准确率。在实验中,通过调整决策树的数量、最大深度、最小样本数等参数,优化模型的性能。实验结果显示,随着决策树数量的增加,模型的准确率逐渐提高,但计算成本也相应增加。通过合理选择参数,可以在准确率和计算效率之间取得平衡。
在随机森林算法完成预测后,根据用户的ID和预测结果,生成推荐列表。如果用户ID存在于预测结果中,则根据用户的相似性推荐与其行为相似的其他用户所关注的资源;如果用户ID不存在,则随机推荐一些资源。最终,将推荐结果整理为 JSON 格式,便于前端展示和使用。
在本项目中,使用 Flask 框架构建 Web 应用。首先,创建 Flask 应用实例并配置数据库连接信息。通过 SQLAlchemy 扩展实现对 MySQL 数据库的操作,数据库连接配置为 mysql+pymysql://root:root@127.0.0.1:3306/project_db。设置应用的密钥和文件上传目录,用于后续的安全验证和文件存储。手动注册了 .js 和 .css 文件的 MIME 类型,确保静态资源能够正确解析。
定义了 connect_db 函数,用于建立数据库连接。在每次请求之前,通过 before_request 钩子函数将数据库连接对象存储到 Flask 的全局对象 g 中,供后续请求处理使用。在请求结束后,通过 after_request 钩子函数释放数据库连接,确保资源的合理使用。
为了实现路由的动态加载和模块化管理,项目采用自定义的路由加载机制。首先,通过 os.walk 遍历视图模块目录(views),获取所有 Python 文件的路径。然后,利用 importlib 动态加载每个模块,并根据模块中的配置信息动态注册路由。每个视图模块包含一个类,类中定义了对应的 HTTP 方法和路由路径。通过反射机制,动态获取模块类的实例,并根据类中的方法动态生成路由规则。
在路由加载过程中,根据模块类的配置信息,动态生成路由规则并注册到 Flask 应用中。支持 GET 和 POST 方法的路由注册,同时支持普通页面路由和 API 路由。通过自定义的 router 函数,将请求方法和对应的视图函数封装为路由处理器,确保请求能够正确分发到对应的处理逻辑。通过 append_urlpatterns 函数,统一管理路由规则的添加,简化路由注册流程。
在请求处理流程中,引入了中间件机制。通过 middleware_check_permissions 函数,在请求到达视图函数之前进行权限验证,确保只有合法用户能够访问特定资源。为了支持跨域请求,通过 before_request 钩子函数对 OPTIONS 请求进行预处理,返回允许跨域的响应头,包括允许的请求方法、请求头字段等信息,从而解决跨域问题。
在项目入口处,通过 app.run 方法启动 Flask 应用。设置 debug=True,以便在开发过程中实时调试代码,自动重启服务并提供调试信息。通过动态加载路由和模块化设计,项目能够灵活扩展功能模块,同时保持代码的清晰性和可维护性。
在进行数据库设计时,概念设计帮助明确系统的整体结构和需求。在这一阶段,需要确定实体、属性以及它们之间的关系,为后续的数据库表设计奠定基础。接下来,将深入探讨数据库表设计的具体细节,实现更高效的数据存储和管理。
概念设计是数据库设计的第一步,其主要目标是对系统的数据需求进行全面的理解和抽象。在这一阶段,通过建立实体-关系模型(ER模型)来识别系统中的关键实体、属性及其相互关系。概念设计的输出是一个清晰的ER图,作为后续数据库表设计的基础。以下将展示系统的全局E-R图以及各个实体的属性图。
系统全局E-R图如图6-3所示。
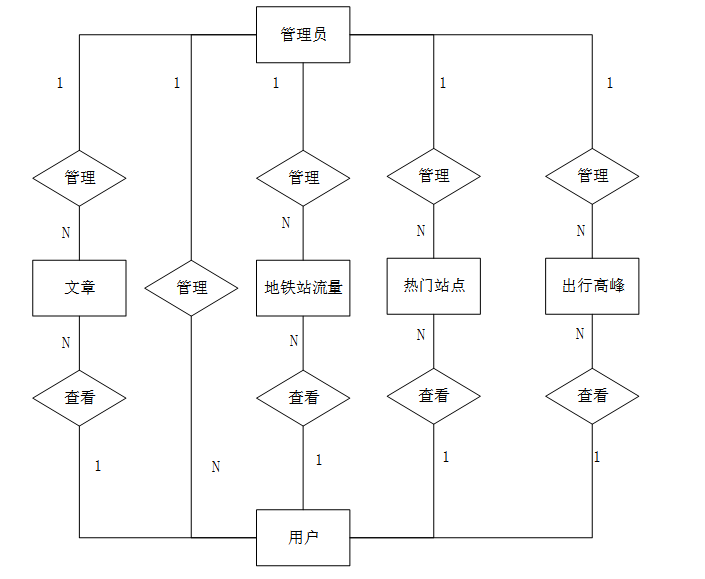
图6-3 系统E-R图
实体包含文章ID、标题、分类、点击数、点赞数、创建时间、更新时间、来源、来源地址、标签、正文、封面图、文章描述等属性,其中文章ID是主键,实体属性图如图6-4所示。实体图如图6-4所示。
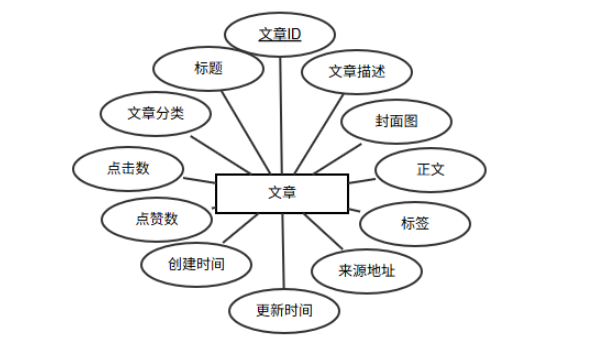
图6-4 文章实体图
实体包含授权ID、用户组、模块名、表名、页面标题、路由路径、父级菜单、父级菜单排序、位置、跳转方式、是否可增加、是否可删除、是否可修改、是否可查看、添加字段、修改字段、查询字段、跨表导航名称、跨表导航、配置、创建时间、更新时间等属性,其中授权ID是主键,实体属性图如图6-5所示。
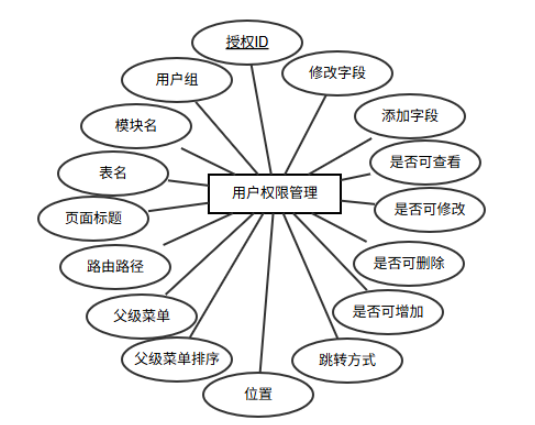
图6-5 管理员实体图
体包含地铁站流量ID、刷卡时间、刷卡次数、地铁线路ID、地铁站ID、刷卡设备ID、进出站类型、用户身份ID、刷卡类型、创建时间、更新时间等属性,其中地铁站流量ID是主键,实体图如图6-6所示。
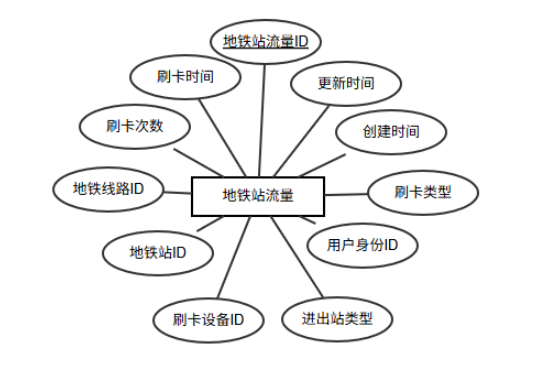
图6-6 地铁站流量实体图
实体包含热门站点ID、刷卡时间、刷卡次数、地铁线路ID、地铁站ID、刷卡设备ID、进出站类型、用户身份ID、刷卡类型、点击数、点赞数、收藏数、评论数、智能推荐、创建时间、更新时间等属性,其中热门站点ID是主键,实体图如图6-7所示。
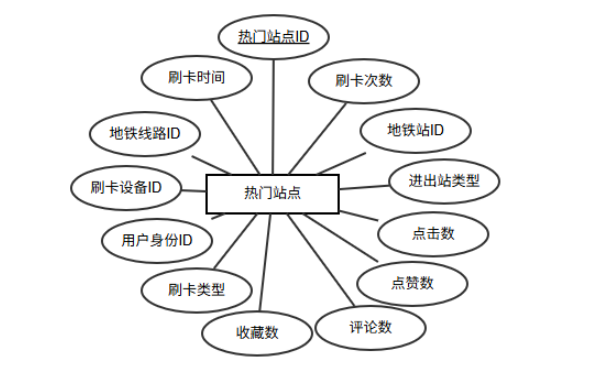
图6-7 热门站点实体图
体包含出行高峰ID、刷卡时间、刷卡次数、地铁线路ID、地铁站ID、刷卡设备ID、进出站类型、用户身份ID、刷卡类型、创建时间、更新时间等属性,其中出行高峰ID是主键,实体图如图6-8所示。
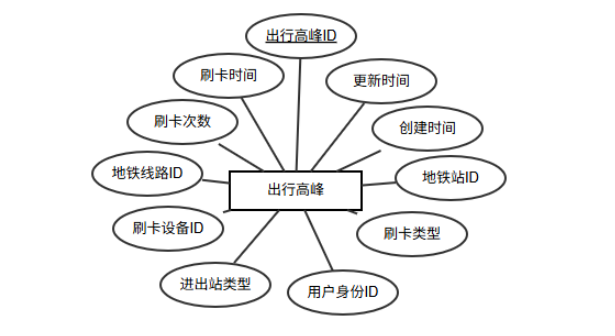
图6-8出行高峰实体图
实体包含用户ID、账户状态、用户组、上次登录时间、手机号码、手机认证、用户名、昵称、密码、邮箱、邮箱认证、头像地址、open_id、创建时间等属性,其中用户ID是主键,实体图如图6-9所示。
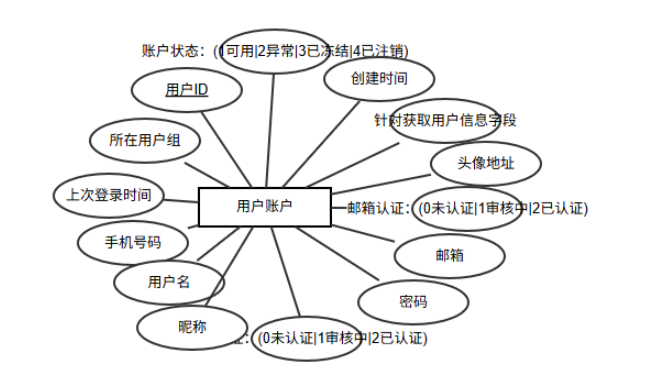
图6-9 用户账户实体图
这一阶段的重点是将概念模型转换为实际的数据库结构,包括表的创建、字段的定义及数据类型的选择。每个实体通常对应于数据库中的一张表,而实体的属性则转化为表的列。以下是系统的数据库表设计展示。
表 4-1 article(文章)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | article_id | mediumint | 是 | 是 | 文章id | |
| 2 | title | varchar | 125 | 是 | 是 | 标题 |
| 3 | type | varchar | 64 | 是 | 否 | 文章分类 |
| 4 | hits | int | 是 | 否 | 点击数 | |
| 5 | praise_len | int | 是 | 否 | 点赞数 | |
| 6 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 7 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 8 | source | varchar | 255 | 否 | 否 | 来源 |
| 9 | url | varchar | 255 | 否 | 否 | 来源地址 |
| 10 | tag | varchar | 255 | 否 | 否 | 标签 |
| 11 | content | longtext | 4294967295 | 否 | 否 | 正文 |
| 12 | img | varchar | 255 | 否 | 否 | 封面图 |
| 13 | description | text | 65535 | 否 | 否 | 文章描述 |
表 4-2 auth(用户权限管理)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | auth_id | int | 是 | 是 | 授权ID | |
| 2 | user_group | varchar | 64 | 否 | 否 | 用户组 |
| 3 | mod_name | varchar | 64 | 否 | 否 | 模块名 |
| 4 | table_name | varchar | 64 | 否 | 否 | 表名 |
| 5 | page_title | varchar | 255 | 否 | 否 | 页面标题 |
| 6 | path | varchar | 255 | 否 | 否 | 路由路径 |
| 7 | parent | varchar | 64 | 否 | 否 | 父级菜单 |
| 8 | parent_sort | int | 是 | 否 | 父级菜单排序 | |
| 9 | position | varchar | 32 | 否 | 否 | 位置 |
| 10 | mode | varchar | 32 | 是 | 否 | 跳转方式 |
| 11 | add | tinyint | 是 | 否 | 是否可增加 | |
| 12 | del | tinyint | 是 | 否 | 是否可删除 | |
| 13 | set | tinyint | 是 | 否 | 是否可修改 | |
| 14 | get | tinyint | 是 | 否 | 是否可查看 | |
| 15 | field_add | text | 65535 | 否 | 否 | 添加字段 |
| 16 | field_set | text | 65535 | 否 | 否 | 修改字段 |
| 17 | field_get | text | 65535 | 否 | 否 | 查询字段 |
| 18 | table_nav_name | varchar | 500 | 否 | 否 | 跨表导航名称 |
| 19 | table_nav | varchar | 500 | 否 | 否 | 跨表导航 |
| 20 | option | text | 65535 | 否 | 否 | 配置 |
| 21 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 22 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-3 subway_station_traffic(地铁站流量)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | subway_station_traffic_id | int | 是 | 是 | 地铁站流量ID | |
| 2 | card_swiping_time | varchar | 64 | 否 | 否 | 刷卡时间 |
| 3 | number_of_card_swipes | varchar | 64 | 否 | 否 | 刷卡次数 |
| 4 | subway_line_id | varchar | 64 | 否 | 否 | 地铁线路ID |
| 5 | subway_station_id | varchar | 64 | 否 | 否 | 地铁站ID |
| 6 | card_swiping_device_id | varchar | 64 | 否 | 否 | 刷卡设备ID |
| 7 | entry_and_exit_station_type | varchar | 64 | 否 | 否 | 进出站类型 |
| 8 | user_identity_id | varchar | 64 | 否 | 否 | 用户身份ID |
| 9 | card_type | varchar | 64 | 否 | 否 | 刷卡类型 |
| 10 | create_time | datetime | 是 | 否 | 创建时间 | |
| 11 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-4 top_sites(热门站点)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | top_sites_id | int | 是 | 是 | 热门站点ID | |
| 2 | card_swiping_time | varchar | 64 | 否 | 否 | 刷卡时间 |
| 3 | number_of_card_swipes | varchar | 64 | 否 | 否 | 刷卡次数 |
| 4 | subway_line_id | varchar | 64 | 否 | 否 | 地铁线路ID |
| 5 | subway_station_id | varchar | 64 | 否 | 否 | 地铁站ID |
| 6 | card_swiping_device_id | varchar | 64 | 否 | 否 | 刷卡设备ID |
| 7 | entry_and_exit_station_type | varchar | 64 | 否 | 否 | 进出站类型 |
| 8 | user_identity_id | varchar | 64 | 否 | 否 | 用户身份ID |
| 9 | card_type | varchar | 64 | 否 | 否 | 刷卡类型 |
| 10 | hits | int | 是 | 否 | 点击数 | |
| 11 | praise_len | int | 是 | 否 | 点赞数 | |
| 12 | collect_len | int | 是 | 否 | 收藏数 | |
| 13 | comment_len | int | 是 | 否 | 评论数 | |
| 14 | recommend | int | 是 | 否 | 智能推荐 | |
| 15 | create_time | datetime | 是 | 否 | 创建时间 | |
| 16 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-5 travel_peak(出行高峰)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | travel_peak_id | int | 是 | 是 | 出行高峰ID | |
| 2 | card_swiping_time | varchar | 64 | 否 | 否 | 刷卡时间 |
| 3 | number_of_card_swipes | varchar | 64 | 否 | 否 | 刷卡次数 |
| 4 | subway_line_id | varchar | 64 | 否 | 否 | 地铁线路ID |
| 5 | subway_station_id | varchar | 64 | 否 | 否 | 地铁站ID |
| 6 | card_swiping_device_id | varchar | 64 | 否 | 否 | 刷卡设备ID |
| 7 | entry_and_exit_station_type | varchar | 64 | 否 | 否 | 进出站类型 |
| 8 | user_identity_id | varchar | 64 | 否 | 否 | 用户身份ID |
| 9 | card_type | varchar | 64 | 否 | 否 | 刷卡类型 |
| 10 | create_time | datetime | 是 | 否 | 创建时间 | |
| 11 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-6 user(用户账户)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | user_id | int | 是 | 是 | 用户ID | |
| 2 | state | smallint | 是 | 否 | 账户状态:(1可用|2异常|3已冻结|4已注销) | |
| 3 | user_group | varchar | 32 | 否 | 否 | 所在用户组 |
| 4 | login_time | timestamp | 是 | 否 | 上次登录时间 | |
| 5 | phone | varchar | 11 | 否 | 否 | 手机号码 |
| 6 | phone_state | smallint | 是 | 否 | 手机认证:(0未认证|1审核中|2已认证) | |
| 7 | username | varchar | 16 | 是 | 否 | 用户名 |
| 8 | nickname | varchar | 16 | 否 | 否 | 昵称 |
| 9 | password | varchar | 64 | 是 | 否 | 密码 |
| 10 | | varchar | 64 | 否 | 否 | 邮箱 |
| 11 | email_state | smallint | 是 | 否 | 邮箱认证:(0未认证|1审核中|2已认证) | |
| 12 | avatar | varchar | 255 | 否 | 否 | 头像地址 |
| 13 | open_id | varchar | 255 | 否 | 否 | 针对获取用户信息字段 |
| 14 | create_time | timestamp | 是 | 否 | 创建时间 |
第七章 系统实现
用户通过输入用户名和密码进行登录,新用户点击注册按钮进入注册页面,填写必要信息完成注册。登录后,用户可进入系统查看功能菜单。登录注册界面如图7-1所示。
图7-1 登录注册界面
用户登录后进入个人信息页面,可查看并编辑个人资料,如昵称、头像、联系方式等。用户还可查看账户状态和登录记录,完成信息修改后点击保存按钮生效。个人信息界面如图7-2所示。
图7-2 个人信息界面
用户在地铁数据页面可查看地铁站流量、热门站点和出行高峰等信息。页面提供筛选功能,用户可根据时间、站点等条件查询数据,点击详情可查看具体数据图表。地铁数据界面如图7-3所示。

图7-3 地铁数据界面
用户进入预测分析页面,选择地铁站点和时间范围后,系统生成流量预测图表。用户可查看预测结果,对比历史数据,了解未来地铁流量趋势,为出行提供参考。预测分析界面如图7-4所示。
图7-4 预测分析界面
管理员登录系统后进入用户管理页面,可查看所有用户列表,包括用户ID、用户名、注册时间等信息。管理员可对用户进行编辑、禁用、删除等操作,还可批量导入用户数据。用户管理界面如图7-5所示。
图7-5 用户管理界面
管理员在地铁数据管理页面可上传、编辑和删除地铁站流量数据,支持批量导入数据文件。管理员还可设置数据展示的时间范围和站点范围,确保数据准确性和完整性。地铁数据管理界面如图7-6所示。
图7-6 地铁数据管理界面
管理员进入预测分析管理页面,可配置预测模型参数,选择不同的预测算法。管理员还可查看预测结果的历史记录,对比实际数据,评估模型准确性,优化预测效果。预测分析管理界面如图7-7所示。
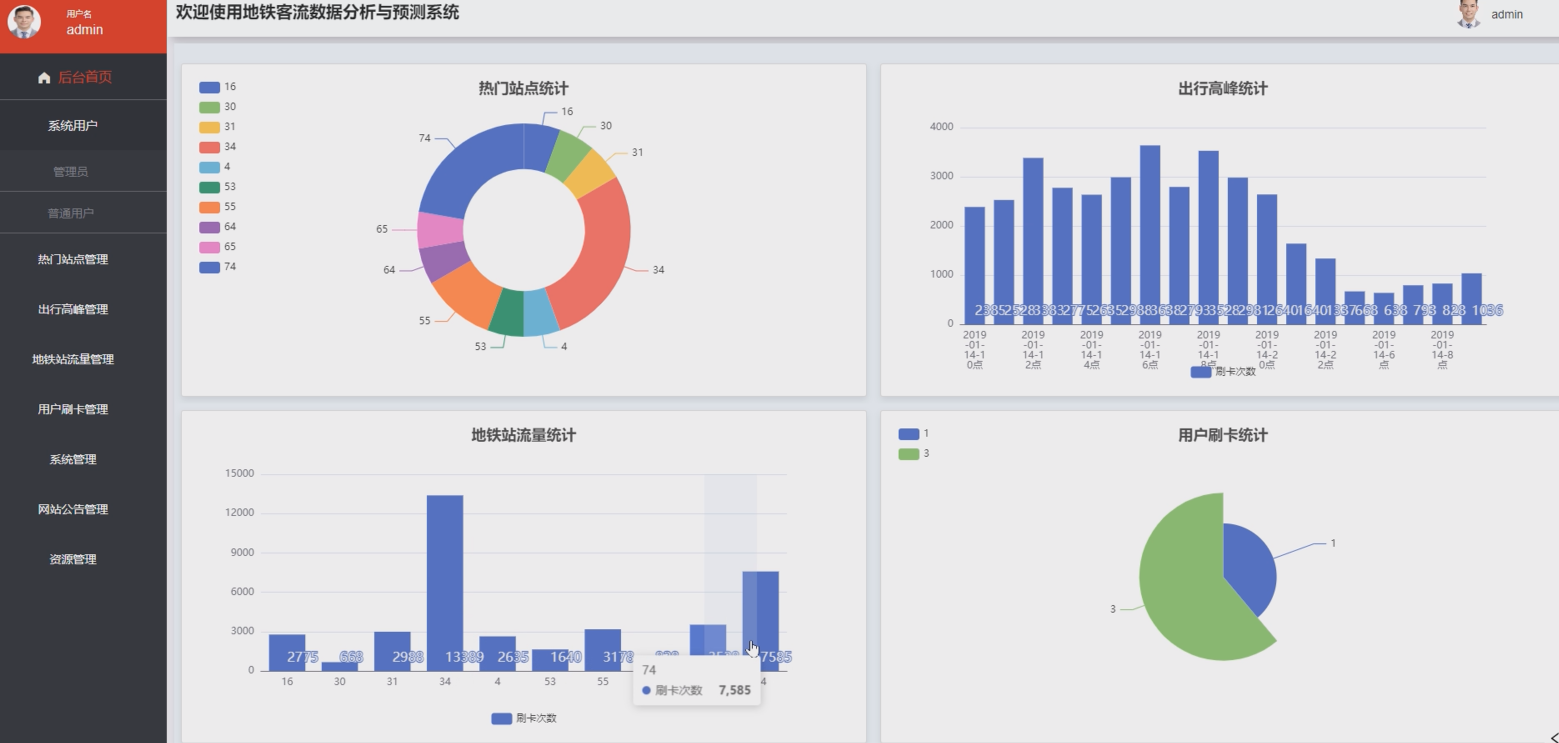
图7-7 预测分析管理界面
第八章 系统测试
系统测试的主要目标是全面验证和确认软件系统作为一个整体是否满足预定义的需求规格,保证所有功能、性能、安全性、兼容性和用户体验等方面达到设计标准。通过模拟用户的使用场景,测试发现和修复任何可能影响软件质量和稳定性的缺陷或问题。这包括验证软件的所有功能是否按照需求文档正确执行,评估系统在高负载和高并发条件下的表现,保证安全措施能有效防止未授权访问和数据泄露,确认软件能够在其预定的硬件和软件环境中正常运行。系统测试致力于保证软件产品在交付给最终用户之前,其质量、性能和安全性都达到最高标准。
软件测试方法主要分为静态测试和动态测试两大类。静态测试是不通过执行代码来检查软件的错误,主要有代码审查、静态分析等技术,用于早期发现软件设计和实现中的问题。动态测试则涉及到实际运行软件来验证其功能和性能,它可以进一步分为白盒测试、黑盒测试和灰盒测试。白盒测试关注于程序内部逻辑和代码结构,黑盒测试着重于测试软件的功能性能而不考虑内部实现,而灰盒测试则是介于白盒和黑盒之间的一种测试方法。还有一系列专门的测试方法,如单元测试、集成测试、系统测试和验收测试,它们从不同的层次对软件进行测试,保证软件在各个方面都能满足需求规格。通过综合运用这些方法,可以有效地提高软件质量,减少缺陷,确保软件的可靠性和性能。
在本系统中,测试方法主要依赖于测试用例的设计与执行。测试用例是根据系统需求文档编写的,覆盖所有功能模块及其边界情况。每个测试用例包含输入数据、预期结果和实际结果的对比,以验证系统的功能是否按预期工作。
该表是用来验证用户登录和注册功能的正确性和完整性。登录注册功能测试用例表如表8-1所示。
表8-1 登入注册功能测试表
| 测试项 | 测试用例 | 预期结果 | 结论 |
| 登入注册功能测试 | 1. 输入已注册的用户名和密码,点击登录按钮。 2. 输入未注册的用户名和密码,点击登录按钮。 3. 点击注册按钮,进入注册页面,填写完整信息并提交。 | 1. 登录成功,跳转到系统主页面。 2. 提示“用户名或密码错误”。 3. 注册成功,跳转到登录页面。 | 与预期结果一致 |
| 4. 注册时输入已存在的用户名,提交注册信息。 5. 注册时输入不符合要求的密码(如少于6位)。 | 4. 提示“用户名已存在”。 5. 提示“密码格式不正确”。 | 与预期结果一致 |
该表是用来验证用户个人信息功能的正确性和完整性。个人信息功能测试用例表如表8-2所示。
表8-2 个人信息功能测试表
| 测试项 | 测试用例 | 预期结果 | 结论 |
| 个人信息功能测试 | 1. 登录后进入个人信息页面,查看默认信息。 2. 修改昵称和头像,点击保存按钮。 3. 修改联系方式为无效格式(如非手机号格式)。 | 1. 显示用户的基本信息。 2. 修改成功,提示“保存成功”。 3. 提示“联系方式格式错误”。 | 与预期结果一致 |
| 4. 查看登录记录,确认记录的准确性。 | 4. 显示用户的历史登录时间、IP地址等信息。 | 与预期结果一致 |
该表是用来验证地铁数据功能的正确性和完整性。地铁数据功能测试用例表如表8-3所示。
表8-4 地铁数据功能测试表
| 测试项 | 测试用例 | 预期结果 | 结论 |
| 地铁数据功能测试 | 1. 进入地铁数据页面,不输入任何筛选条件,点击查询按钮。 2. 输入有效的时间范围和站点名称进行筛选。 3. 点击某条数据的“详情”按钮。 | 1. 显示所有地铁数据记录。 2. 显示符合条件的地铁数据记录。 3. 弹出详细数据图表。 | 与预期结果一致 |
| 4. 输入无效的时间范围(如结束时间早于开始时间)。 | 4. 提示“时间范围无效”。 | 与预期结果一致 |
该表是用来验证预测分析功能的正确性和完整性。预测分析功能测试用例表如表8-4所示。
表8-4 预测分析功能测试表
| 测试项 | 测试用例 | 预期结果 | 结论 |
| 预测分析功能测试 | 1. 进入预测分析页面,选择一个地铁站点和时间范围,点击生成图表按钮。 2. 选择的时间范围超出系统允许的范围。 3. 查看预测结果与历史数据对比图。 | 1. 生成流量预测图表。 2. 提示“时间范围超出限制”。 3. 显示预测结果与历史数据的对比。 | 与预期结果一致 |
| 4. 未选择地铁站点,直接点击生成图表按钮。 | 4. 提示“请选择地铁站点”。 | 与预期结果一致 |
该表是用来验证管理员用户管理功能的正确性和完整性。用户管理功能测试用例表如表8-5所示。
| 测试项 | 测试用例 | 预期结果 | 结论 |
| 用户管理功能测试 | 1. 管理员登录后进入用户管理页面,查看用户列表。 2. 点击“编辑”按钮,修改用户信息并保存。 3. 点击“删除”按钮,删除一个用户。 | 1. 显示所有用户的基本信息。 2. 修改成功,提示“用户信息已更新”。 3. 用户被删除,提示“删除成功”。 | 与预期结果一致 |
| 4. 尝试编辑不存在的用户信息。 | 4. 提示“用户不存在”。 | 与预期结果一致 |
该表是用来验证管理员地铁数据管理功能的正确性和完整性。地铁数据管理功能测试用例表如表8-6所示。
表8-6 地铁数据管理功能测试表
| 测试项 | 测试用例 | 预期结果 | 结论 |
| 地铁数据管理功能测试 | 1. 管理员进入地铁数据管理页面,上传一个有效的数据文件。 2. 编辑某条地铁数据记录,修改流量数值并保存。 3. 删除某条地铁数据记录。 | 1. 数据文件上传成功,提示“上传成功”。 2. 修改成功,提示“数据已更新”。 3. 数据被删除,提示“删除成功”。 | 与预期结果一致 |
| 4. 上传格式不正确的数据文件。 | 4. 提示“文件格式错误”。 | 与预期结果一致 |
在对系统主要功能进行测试后,得出以下结论:登录注册功能表现稳定,能够准确处理合法与非法输入,用户可顺利登录或注册。个人信息功能运行正常,用户可查看并成功修改个人资料,系统对无效格式的输入进行了正确提示。地铁数据功能测试表明,数据查询与筛选操作准确无误,详情查看功能正常,系统对无效查询条件进行了有效拦截。预测分析功能测试结果显示,系统能够根据用户输入生成准确的预测图表,并在超出范围或未选择必要条件时给出恰当提示。用户管理功能测试中,管理员可正常查看、编辑、删除用户信息,系统对不存在的用户操作进行了正确处理。地铁数据管理功能测试验证了数据上传、编辑、删除操作的准确性,对格式错误的文件上传进行了有效阻止。整体而言,系统各主要功能模块均达到了设计要求,测试结果与预期一致,具备良好的稳定性和准确性。
第九章 总结
本研究围绕地铁数据管理系统的设计与实现展开,旨在通过随机森林算法与 Flask Web 框架构建一个高效、稳定且功能完备的系统。研究从用户与管理员两个角度出发,深入分析了功能需求,涵盖用户登录注册、个人信息管理、地铁数据查询与预测分析,以及管理员对用户、地铁数据和预测分析的管理功能。在技术选型上,结合 Python 语言、Echarts 数据可视化工具、Vue 前端框架、Flask 后端框架和 MySQL 数据库,确保系统具备良好的扩展性与兼容性。通过对随机森林算法的优化设计,实现了地铁流量的精准预测,为用户出行提供科学依据。系统采用模块化设计,实现了路由动态加载与中间件跨域处理,提升了开发效率与用户体验。
在系统实现阶段,详细设计了数据库表结构,完成了用户功能与管理员功能的开发。测试阶段,针对各功能模块进行了全面测试,验证了系统的稳定性和准确性。测试结果表明,系统能够满足用户与管理员的多样化需求,各功能模块运行正常,达到了预期的设计目标。本研究不仅为地铁数据管理提供了一种有效的解决方案,也为相关领域的系统开发提供了参考借鉴,具有一定的理论与实践价值。
参考文献
- 杨烁.北京市某地铁站环控系统能耗分析及预测模拟[D].北方工业大学,2024.DOI:10.26926/d.cnki.gbfgu.2024.000394.
- 庞浩,倪海超,郝志升.基于大数据的地铁供电系统运行状态预测与维护[J].价值工程,2024,43(02):45-47.DOI:10.3969/j.issn.1006-4311.2024.02.014.
- 刘小双.基于时间序列的城市夜间光环境演变分析与预测研究[D].大连理工大学,2022.DOI:10.26991/d.cnki.gdllu.2022.002252.
- Yan H ,Xiaodi W ,Jianzhou W , et al.A novel interval-valued carbon price analysis and forecasting system based on multi-objective ensemble strategy for carbon trading market[J].Expert Systems With Applications,2024,244122912-.
- Kim U J ,김종운 ,Cho S H , et al.Gait Analysis and Prediction System for Real-time Control of Artificial Legs Using Deep Learning Algorithm[J].한국정밀공학회 학술발표대회 논문집,2020,
- Guo Z .Research on Big Data Analysis and Prediction System Based on Deep Learning[J].Automation and Machine Learning,2023,4(1):
- 张杰. 基于Python技术的计算机软件开发系统设计[J].电脑编程技巧与维护,2024,(12):31-33.
- 纪芳. 高校Python编程语言课程教学改革探索[N].河南经济报,2024-08-15(012).
- 贺国平,张国荣. 大数据技术背景下Python程序设计研究[J].软件,2024,45(08):28-30.
- 季玉洁,李观石,唐天琪.基于Echarts的自然资源大数据可视化系统设计与实现[J].无线互联科技,2025,22(07):44-51.
- 韦松,原秋燕,欧阳兆晃,等.基于ECharts的生态农业数据可视化平台设计与实现[J].物联网技术,2025,15(01):122-126.DOI:10.16667/j.issn.2095-1302.2025.01.029.
- 张俊萌,梁志达.基于ECharts的康养数据可视化系统的设计与实现[J].工业控制计算机,2024,37(11):155-156.
- 朱永萍.基于Vue的可视化编辑器的研究与实现[J].工业控制计算机,2025,38(04):90-92.
- 赵叶平,陈圣,马军,等.基于Spring Boot+VUE+Uni-app框架的文明城市智慧管理系统设计与实现[J].工业控制计算机,2025,38(04):139-140+153.
- 刘盛,王占云.基于SpringBoot+Vue微服务架构的科研样本库管理系统的设计与实现[J].信息系统工程,2025,(04):4-7.
- 王朝辉.基于Flask框架的测试集成系统设计与实现[J].科技创新与应用,2024,14(33):115-118.DOI:10.19981/j.CN23-1581/G3.2024.33.028.
- 王晓雷,王钱庆,王鲜芳.基于Flask数据可视化的网页端显示方法研究[J].无线互联科技,2024,21(15):10-13+20.
- 张金聪,高晓红,郑艺文.基于Flask和Vue的猕猴桃信息管理系统的设计与开发[J].电脑知识与技术,2024,20(20):47-49.DOI:10.14004/j.cnki.ckt.2024.1063.
致 谢
在本文的完成过程中,收到了来自多方面的宝贵支持和帮助,对此我表示深深的感激。
衷心感谢我的指导老师。老师以其深厚的专业知识和丰富的实践经验,为我的研究工作提供了宝贵的指导和建议。在整个研究过程中,老师不仅耐心细致地解答了我的疑问,还提供了许多有见地的意见,帮助我更深入地理解研究主题,并指引我克服了研究过程中遇到的各种困难。我要感谢我的同学们,他们在研究过程中给予了我大量的帮助和支持。我们之间的讨论和交流极大地丰富了我的研究视野,并激发了我对课题的思考和探索。他们的友谊和协作使我在学术旅程中感到温暖和鼓舞。我还要对学校表达深深的感激之情。学校提供的良好学习环境和丰富的教学资源为我的学术研究和论文撰写提供了坚实的基础。学校的各种学术活动都极大地丰富了我的研究经验,并为我提供了展示和验证研究成果的平台。
再次感谢所有给予我帮助和支持的老师、同学和学校。是你们的支持和鼓励使我得以顺利完成这项研究工作。
请关注点赞+私信博主,免费领取项目源码


















 1412
1412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









