






文章目录
mysql学习(2)
LIKE 子句
LIKE 子句是在 MySQL 中用于在 WHERE 子句中进行模糊匹配的关键字。
它通常与通配符一起使用,用于搜索符合某种模式的字符串。
例子:
普通的where子句(精准)
SELECT column1, column2, ...
FROM table_name
WHERE column_name = xxx;
使用like的where子句(模糊)
SELECT column1, column2, ...
FROM table_name
WHERE column_name LIKE pattern;
-
pattern 是用于匹配的模式,可以包含通配符。
-
可以使用LIKE子句代替等号 =。
LIKE 子句中使用百分号 %字符来表示任意字符,类似于UNIX或正则表达式中的星号 *。
如果没有使用百分号 %, LIKE 子句与等号 = 的效果是一样的。
- LIKE 通常与 % 一同使用,类似于一个元字符的搜索。
- 可以在 DELETE 或 UPDATE 命令中使用 WHERE…LIKE
子句来指定条件。
部分通配符的使用
百分号通配符 %:
% 通配符表示零个或多个字符。
例如,‘a%’ 匹配以字母 ‘a’ 开头的任何字符串。
SELECT * FROM customers
WHERE last_name LIKE 'S%';
下划线通配符 _:
_ 通配符表示一个字符
SELECT * FROM products
WHERE product_name LIKE '_a%';
组合使用 % 和 _
SELECT * FROM users
WHERE username LIKE 'a%o_';
*注意:LIKE查询默认是大小写不敏感的,即不区分大小写。
UNION [ALL]操作符
UNION
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合,并去除重复的行。
UNION 操作符必须由两个或多个 SELECT 语句组成,每个 SELECT 语句的列数和对应位置的数据类型必须相同。
SELECT column1, column2, ...
FROM table1
WHERE condition1
UNION
SELECT column1, column2, ...
FROM table2
WHERE condition2
[ORDER BY column1, column2, ...];
例子:
SELECT product_name FROM products WHERE category = 'Electronics'
UNION
SELECT product_name FROM products WHERE category = 'Clothing'
ORDER BY product_name;
以上 SQL 语句将选择电子产品和服装类别的产品名称,并按产品名称升序排序。
UNION ALL
UNION ALL 不去除重复行。
例子:
SELECT city FROM customers
UNION ALL
SELECT city FROM suppliers
ORDER BY city;
以上 SQL 语句使用 UNION ALL 将客户表和供应商表中的所有城市合并在一起,不去除重复行。
ORDER BY(排序) 语句
ORDER BY(排序) 语句可以按照一个或多个列的值进行升序(ASC)或降序(DESC)排序
默认ASC
语法:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...;
多列排序
例子:
SELECT * FROM employees
ORDER BY department_id ASC, hire_date DESC;
以上 SQL 语句将选择员工表 employees 中的所有员工,
先按部门 ID 升序 ASC 排序,
然后在相同部门中按雇佣日期降序 DESC 排序。
使用数字表示列的位置
SELECT first_name, last_name, salary
FROM employees
ORDER BY 3 DESC, 1 ASC;
以上 SQL 语句将选择员工表 employees 中的名字和工资列,并按第三列(salary)降序 DESC 排序,然后按第一列(first_name)升序 ASC 排序。
使用表达式排序
SELECT product_name, price * discount_rate AS discounted_price
FROM products
ORDER BY discounted_price DESC;
以上 SQL 语句将选择产品表 products 中的产品名称和根据折扣率计算的折扣后价格,并按折扣后价格降序 DESC 排序。
- as 相当于重命名
使用 NULLS FIRST 或 NULLS LAST 处理 NULL 值(MySQL 8.0.16+):
NULL 值排在最后
SELECT product_name, price
FROM products
ORDER BY price DESC NULLS LAST;
以上 SQL 语句将选择产品表 products 中的产品名称和价格,并按价格降序 DESC 排序,将 NULL 值排在最后。
NULL 值排在最前
SELECT product_name, price
FROM products
ORDER BY price DESC NULLS FIRST;
GROUP BY 语句
GROUP BY 语句根据一个或多个列对结果集进行分组。通常与聚合函数一起使用。
语法:
SELECT column1, aggregate_function(column2)
FROM table_name
WHERE condition
GROUP BY column1;
- aggregate_function(column2):对分组后的每个组执行的聚合函数。
在 SQL 中,aggregate_function(column2) 是一种聚合函数,用于对查询结果中的一组数据进行计算。常见的聚合函数包括(之后的学习中重点介绍):
COUNT():计算行的数量。
SUM():计算数值列的总和。
AVG():计算数值列的平均值。
MAX():返回列中的最大值。
MIN():返回列中的最小值。
例子:假设有一个名为 orders 的表,包含以下列:order_id、customer_id、order_date 和 order_amount。
我们想要按照 customer_id 进行分组,并计算每个客户的订单总金额,SQL 语句如下:
SELECT customer_id, SUM(order_amount) AS total_amount
FROM orders
GROUP BY customer_id;
以上实例中,我们使用 GROUP BY customer_id 将结果按 customer_id 列分组,然后使用 SUM(order_amount) 计算每个组中 order_amount 列的总和。
AS total_amount 是为了给计算结果取一个别名,使查询结果更易读。
- GROUP BY 子句通常与聚合函数一起使用,因为分组后需要对每个组进行聚合操作。
- SELECT 子句中的列通常要么是分组列,要么是聚合函数的参数。
- 可以使用多个列进行分组,只需在 GROUP BY 子句中用逗号分隔列名即可。
SELECT column1, column2, aggregate_function(column3)
FROM TABLE_NAME
WHERE condition
GROUP BY column1, column2;
小结
like 子句
可进行模糊过滤,位置处于where子句的“=”同级
常用通配符:%(0~n 个任意字符) ;_(1个任意字符)
union 操作符
union 两个查询结果去重取并集
union all 两个查询结果不去重取并集
order by 排序
语法:order by 列名 [asc/desc];
默认升序asc
可以指定多列,逗号隔开,优先级从前到后
group by 分组
结合聚合函数,根据分组(列名) 展示计算结果
例子:将数据表按名字进行分组,并统计每个人有多少条记录: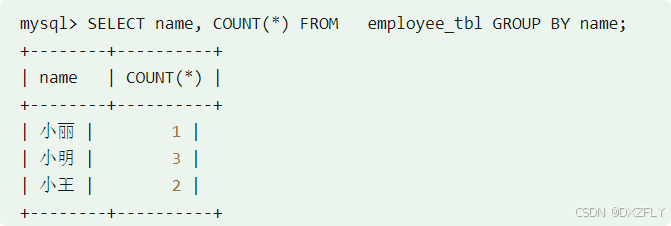
练习题
题目前置数据:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
birthdate DATE
);
INSERT INTO users (username, email, birthdate)
VALUES
('John', 'john@example.com', '1985-07-10'),
('Jane', 'jane@example.com', '1990-11-25'),
('Jason', 'jason@example.com', '1992-04-15'),
('Jack', 'jack@example.com', '1995-03-05'),
('Anna', 'anna@example.com', '2000-08-20'),
('James', 'james@example.com', '1988-09-30');
CREATE TABLE products (
id INT AUTO_INCREMENT PRIMARY KEY,
product_name VARCHAR(100),
category VARCHAR(50),
price DECIMAL(10, 2)
);
INSERT INTO products (product_name, category, price)
VALUES
('Python Programming', 'Books', 75.00),
('SQL Mastery', 'Books', 90.00),
('Smartphone', 'Electronics', 500.00),
('Laptop', 'Electronics', 1200.00),
('T-Shirt', 'Clothing', 30.00);
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department_id INT,
hire_date DATE,
salary DECIMAL(10, 2)
);
INSERT INTO employees (name, department_id, hire_date, salary)
VALUES
('Alice', 1, '2022-01-15', 70000),
('Bob', 2, '2021-05-10', 80000),
('Charlie', 1, '2023-03-20', 60000),
('David', 3, '2020-12-05', 90000),
('Eve', 2, '2019-08-25', 85000);
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
customer_id INT,
order_date DATE,
order_amount DECIMAL(10, 2)
);
INSERT INTO orders (customer_id, order_date, order_amount)
VALUES
(1, '2023-01-15', 150.00),
(2, '2023-02-10', 200.00),
(1, '2023-03-05', 300.00),
(3, '2023-04-20', 400.00),
(2, '2023-05-15', 100.00);
CREATE TABLE customers (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
city VARCHAR(50)
);
CREATE TABLE suppliers (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
city VARCHAR(50)
);
INSERT INTO customers (name, city)
VALUES
('Customer1', 'New York'),
('Customer2', 'Los Angeles'),
('Customer3', 'Chicago');
INSERT INTO suppliers (name, city)
VALUES
('Supplier1', 'San Francisco'),
('Supplier2', 'New York'),
('Supplier3', 'Chicago');
选择题
-
以下哪个语句可以查询以字母 A 开头的客户名称? A. SELECT * FROM customers WHERE name LIKE ‘A’;
B. SELECT * FROM customers WHERE name LIKE ‘A%’;
C. SELECT * FROM customers WHERE name LIKE ‘_A’; -
如果要将两个 SELECT 语句的结果组合为一个集合,并去除重复行,应使用哪个操作符?
A. UNION ALL
B. UNION
C. JOIN -
下列哪个 ORDER BY 语句能将产品按价格降序排列,并将 NULL 值排在最后? A. ORDER BY price DESC;
B. ORDER BY price DESC NULLS LAST;
C. ORDER BY price ASC NULLS FIRST;
填空题
- 在 SQL 中,% 通配符用于匹配 _______ 个或多个任意字符,而 _ 通配符用于匹配 _______ 个字符。
- UNION 操作符会将查询结果合并并去除 _______ 行,UNION ALL 则不会去重。
- 在使用 ORDER BY 时,如果不指定排序方式,默认采用 _______ 排序。
- 如果要查找 email 字段为空的用户记录,应使用 _______ 条件。
判断题
- ( ) LIKE 子句中的 % 可以匹配任意数量的字符,包括 0 个字符。
- ( ) 使用 UNION ALL 会去除所有重复行。
- ( ) 在 MySQL 中,ORDER BY 默认按照降序排序。
- ( ) 使用 GROUP BY 后,查询结果中只能出现分组字段和聚合函数。
- ( ) ORDER BY 可以使用列名的序号进行排序,例如 ORDER BY 2 DESC 按第二列降序排列。
编写 SQL 语句
-
使用 LIKE 进行模糊查询(users表):
查询所有用户名以 J 开头且以 n 结尾的用户。 -
UNION 操作符的使用(products):
查询所有分类为 “Books” 或 “Electronics” 的产品,并按产品名称升序排列。 -
ORDER BY 多列排序(employees):
从 employees 表中查询员工信息,先按部门 ID 升序排列,再按入职日期降序排列。 -
GROUP BY 结合聚合函数(orders):
从 orders 表中查询每个客户的订单总金额,并按总金额降序排列。
扩展题
-
LIKE 子句的组合使用(users):
如何编写一个 SQL 语句,查询所有用户名以 “a” 开头、长度为 5 个字符的用户? -
UNION 和 ORDER BY 的结合使用(customers和suppliers):
如何查询两个不同表中的城市名称,并按城市名称升序排列? -
GROUP BY 的多列分组(orders):
如何编写 SQL 语句,将 orders 表按 customer_id 和 order_date 进行分组,并查询每组的订单数量?
答案
选择题
- B
- B
- B
填空题
- 0;1
- 重复
- 升序
- email is null (注意:不是email = nul)
判断题
- true
- false
- false
- true(在使用 GROUP BY 子句时,查询结果中只能包括分组字段和与这些分组数据相关的聚合函数结果。)
- true
编写题:
– 1
select `username` from users
where `username`like 'J%n';
– 2
-- 由于是同一张表,所有数据类型和列数是相同的,以下写法不会报错
select * from products
where category = 'Books'
union
select * from products
where category = 'Electronics'
ORDER BY `product_name`;
-- 更好的写法是:
SELECT product_name FROM products
WHERE category = 'Books'
UNION
SELECT product_name FROM products
WHERE category = 'Electronics'
ORDER BY product_name;
-- 不过由于是同一张表,其实还可以用OR 或 IN
-- (UNION 的目的是将不同来源的查询结果集合并(可能是不同表或查询条件)。)
-- or
SELECT * FROM products
WHERE category = 'Books' OR category = 'Electronics';
-- 注意:错误写法--WHERE category = 'Books' OR 'Electronics';
-- IN 运算符是一种更简洁的写法,用于匹配多个值。
SELECT * FROM products
WHERE category IN ('Books', 'Electronics');
– 3
select * from employees
ORDER BY department_id ASC,hire_date DESC;
– 4
select customer_id,SUM(`order_amount`) as `sum`from orders
group by customer_id
ORDER BY sum DESC;
注意关注
填空题4、判断题4、编写题2


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









