




8.1 程序切片技术
程序切片(Program Slicing)旨在从程序中提取满足一定约束条件的代码片段(对指 定变量施加影响的代码指令,或者指定变量所影响的代码片段),是一种重要的程序分解技术。
作用:
-
从大规模程序中精确定位分析员所关心的代码片段,有效缓解程序规模日益增长带来的分析效率难以同步提高的问题。
-
比如,在漏洞挖掘中,我们可以只关注可执行 文件或者源代码某一行敏感函数调用相关的代码片段,来分析是否存在缓冲区溢出漏洞等。
8.1.1 基础定义
1. 程序切片
由Mark Weise博士首先提出。他给出的程序切片定义是:
-
给定一个切片准则 C=(N, V),其中N表示程序P中的指令,V表示变量集,程序P关于 C 的映射即为程序切片。
-
程序切片是由程序中的一些语句和判定表达式组成的集合
按照计算方向分类:
-
前向切片
-
后向切片
对于程序 P 和一个切片准则 C=(N, V),得到的前向切片S是指 P 中受到指令集N和变量集V影响的片段。

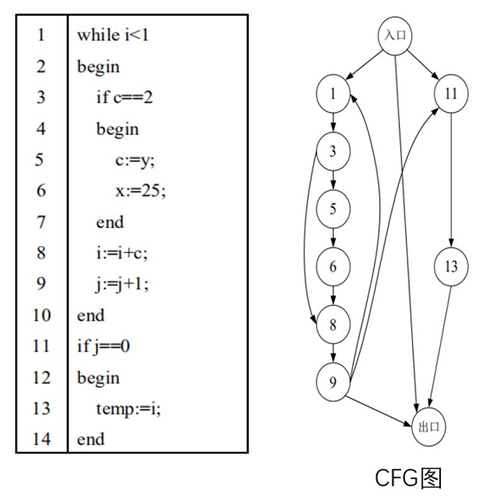
2. 控制流图
-
==控制流图(Control Flow Graph,简称 CFG)==也叫控制流程图,是一个过程或程序的抽 象表现,代表了一个程序执行过程中会遍历到的所有路径。
-
它用图的形式表示一个过程内所 有基本块执行的可能流向, 也能反映一个过程的实时执行过程。
控制流图:一个程序的控制流图CFG可以表示为一个四元组,形如G = (V, E, s, e),
-
其中V表示变量的集合,
-
E表示表示边的集合,
-
s表示控制流图的入口,
-
e表示控制流图的出口。
程序中的每一条指令都映射为CFG上的一个结点,具有控制依赖关系的结点之间用一条 边连接。
-
程序中的控制依赖关系有两种来源:
-
程序上下文;
-
控制指令。
-
-
控制指令对应了分支结构或循环结构,结构里面的所有指令对结构入口的控制指令存在控制依赖关系。如果 一条指令不在分支结构或循环结构里面,则该指令依赖于程序的入口。
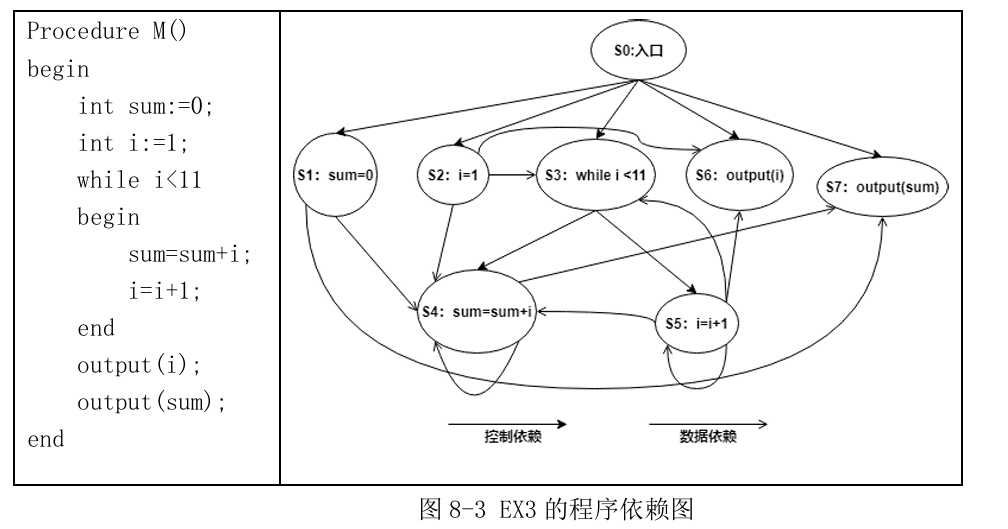
3. 程序依赖图
-
控制依赖表示两个基本块在程序流程上存在的依赖关系;
-
数据依赖表示程序中引用某变量的基本块(或者语句) 对定义该变量的基本块的依赖,即是一种“定义-引用”依赖关系。
程序依赖图:程序依赖图PDG可以表示为一个五元组,形如G = (V, DDE, CDE, s, e),
-
其中V表示变量的集合,
-
DDE表示数据依赖边的集合,
-
CDE表示控制依赖边的集合,每条边连接了图中的两个结点,程序中的每一条指令都映射为PDG上的一个结点。
-
s表示程序依赖图 的入口结点,
-
e表示程序依赖图的出口结点。
在控制流图CFG中,结点之间的边只反映出了程序指令之间的部分控制依赖关系。而在 程序依赖图PDG的建模过程中,需要将一个函数中所有的数据依赖和控制依赖关系遍历出来。
4. 系统依赖图
系统依赖图(System Dependence Graph,SDG)可以表示为一个七元组,形如G = (V,DDE, CDE, CE, TDE, s, e),
-
其中 V 变量的集合,
-
DDE表示数据依赖边的集合,
-
CDE表示控制依赖 边的集合,
-
CE表示函数调用边,
-
TDE表示参数传递造成的传递依赖边的集合,
-
结点s表示系 统依赖图的入口结点,
-
结点e表示系统依赖图的出口结点。
SDG 在PDG的基础上进行了扩充,系统依赖图中加入了对函数调用的处理。 SDG 中的每条边连接了图中的两个结点,程序中的每一条指令都映射为SDG上的一个结点。除此之外,SDG 中还增添了函数调用结点和参数传递结点,并用函数调用边连结函数调 用结点和被调用的函数入口结点,用传递依赖边连结参数传递过程中具有依赖关系的结点。
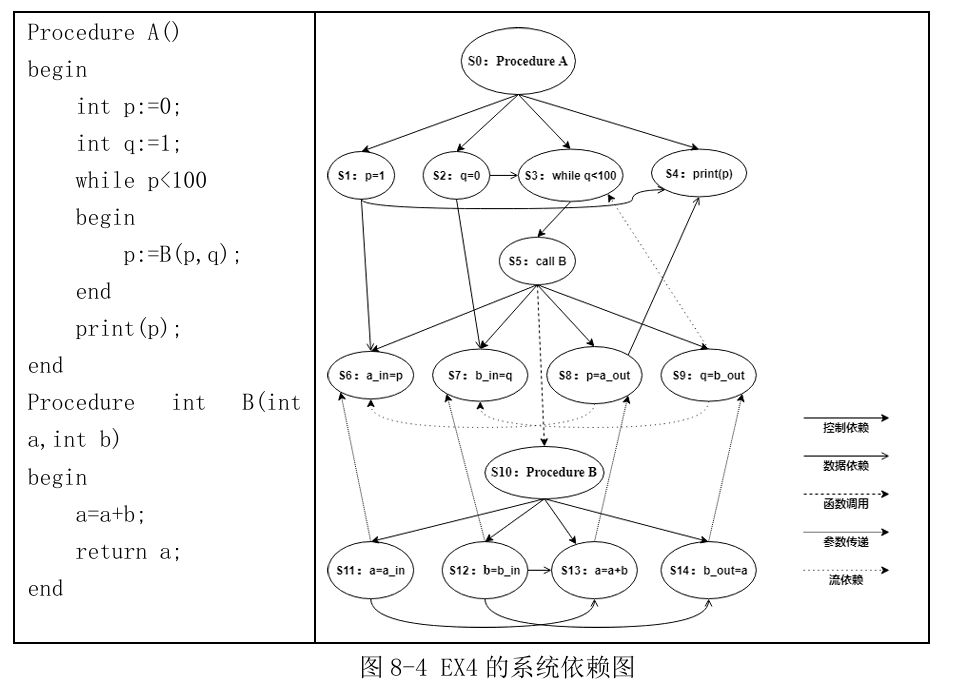
传递依赖边可以分为
-
参数传入边:参数传入边用于连结调用函数和被调用函数之间的参数传入
-
参数传出边:参数传出边用于连结被调用函数想调用函数返回的参数传出
-
流依赖边:流依赖边用于连结同一个函数内部由于函数调用引起的数据依赖。
8.1.2 工作原理
在实际的程序调试过程中,通常程序员只关注程序的部分行为。
切片准则两要素
-
切片目标变量(如变量z),
-
以及开始切片的代码位置(如z 所在的代码位置:第12行)
严格来说,程序P的切片准则是二元组,其中n是程序中 一条语句的编号,V是切片所关注的变量集合,该集合是P中变量的一个子集。
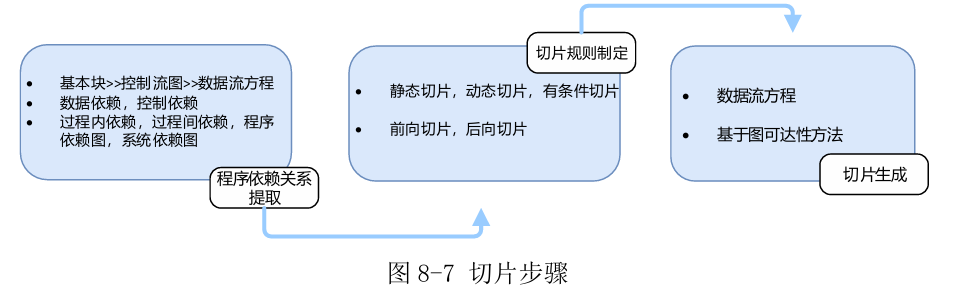
切片步骤:
-
程序依赖关系提取:从程序中提取各类消息,包括控制流和数据流信息,形成程序依赖图
-
切片规则制定:是依据具体的程序分析需求设计切片准则
-
切片生成:依据前述 的切片准则选择相应的程序切片方法,然后对第一步中提取的依赖关系进行分析处理,从而生成程序切片。
按照不同的分类标准有不同的切片类型
| 分类标准 | 切片类型 | 定义描述 |
|---|---|---|
| 是否考虑具体输入 | 静态切片 | 不考虑程序具体输入的切片类型。 |
| 动态切片 | 考虑程序具体输入的切片类型。 | |
| 影响方向 | 后向切片 | 提取对关注变量有影响的代码片段的切片类型。 |
| 前向切片 | 提取被关注变量所影响的代码片段的切片类型。 | |
| 是否可执行 | 可执行切片 | 提取的切片为可执行程序,且需与原程序在语义上保持一致的切片类型(最初的程序切片属于此类)。 |
| 不可执行切片 | 提取的切片为不可执行程序的切片类型。 | |
| 其他类型 | 有条件切片、削片、砍片等 | 除上述分类外的其他切片类型,丰富了程序切片的种类。 |
8.1.3 典型方法
1. 图可达算法
-
根据程序建模分为不同子类。常用的包括
-
基于程序依赖图的图可达性算法和
-
基于系统依赖图的图可达性算法
-
-
在程序依赖图PDG中,具有直接依赖关系和间接依赖关系的结点都用一条边连结,
-
基于 PDG 的图可达性切片算法只需从指定结点遍历每一个具有依赖关系的结点即可,计算过 程比较简单直观。
2. 动态切片
从切片角度,程序切片可以分为静态程序切片、动态程序切片和条件切片等。
动态切片需要考虑程序的特定输入,切片准则是一个三元组(N, V, I),
-
其中 N 是指令集合,
-
V 是变量 集合,
-
I 是输入集合。
事实上,动态切片可以看做静态切片的子集。当图可达算法应用到动态切片中,可以通 过裁剪程序依赖图来实现。
条件切片的切片准则也是一个三元组,形为C = (N, V, 𝐹V),
-
其中 N 和 V 的含义同静 态准则相同,
-
𝐹V是 V 中变量的逻辑约束。
三者关系
-
静态切片和动态切片可以看做条件切片的两个特 例:当𝐹V中的约束条件为空时,得到的切片是静态切片;
-
当𝐹V中的约束固定为某一特定条件 时,得到的切片是动态切片。
8.2 程序插桩技术
8.2.1 插桩概念
-
程序插桩,是借助往被测程序中插入操作,来实现测试目的的方法。
-
简单的说,插桩就 是在代码中插入一段我们自定义的代码,它的目的在于通过我们插入程序中的自定义的代码, 得到期望得到的信息,比如程序的控制流和数据流信息,以此来实现测试或者其他目的。
插桩的例子:
-
在程序中插入输出语句,以监测变量的取值或者状态是否符合预期。这种插桩 手段在服务类应用程序、基于日志的程序调错等。断言是一种特殊的插桩,是在程序的特定 部位插入语句来检查变量的特性。
8.2.2 插桩分类
以下是对程序插桩技术内容的总结:
程序插桩技术分类及特点
| 分类 | 定义 | 优势 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 源代码插桩 | 在程序运行前,通过工具或手动在源码中插入探针,重新编译后运行。 | 1. 基于语法分析精准插桩; 2. 支持人工编码时插桩; 3. 不影响程序逻辑。 | 依赖源代码,无法用于闭源软件、动态链接库等无源码场景。 | 开源软件测试、自研程序缺陷检测。 |
| 静态二进制插桩 | 在程序运行前,直接对编译后的二进制机器码插入探针。 | 无需源代码,可处理二进制文件。 | 1. 机器码复杂度高,插桩难度大; 2. 平台相关性强,可移植性差; 3. 动态链接库插桩困难。 | 闭源软件的静态分析(需完整二进制)。 |
| 动态二进制插桩 | 在程序运行时,接管程序并截获二进制指令动态插入探针。 | 1. 无需源代码; 2. 支持动态链接库插桩; 3. 可实时监控运行中的程序。 | 1. 插桩程序开发难度极高; 2. 运行时开销大。 | 程序动态分析、漏洞挖掘、实时监控。 |
-
核心优势
-
不影响程序动态执行结果,支持实时监控与分析。
-
应用领域:程序分析、软件测试、漏洞挖掘、恶意代码检测等。
-
-
面临挑战与解决方案
-
挑战:开发难度大、抽象层次低、运行时开销高。
-
解决方案:使用动态二进制插桩框架,如:
-
Pin:提供二进制指令级抽象,优化运行开销,支持跨平台分析。
-
DynamoRIO:支持动态代码优化与插桩,适用于高性能监控场景。
-
Frida:轻量级框架,支持脚本化插桩,适合移动端和逆向工程。
-
-
-
框架价值
-
降低底层实现复杂度,聚焦工具逻辑开发;
-
抽象二进制指令,提升代码重用性;
-
优化运行效率,减少插桩对程序的性能影响。
-
8.2.3 Pin插桩示例
==课本示例P248==
1. 安装及使用Pin
2. 使用Pintool
3. Pintool
-
基本框架
-
插桩模式
-
指令级插桩
-
了解函数
4. MyPinTool示例
==实验一:在Windows 10环境下,基于MyPinTool工程,复现Pintool里的malloctrace, 关注malloc和free函数的输入输出信息。==
8.3 Hook技术
8.3.1 Hook概念
Hook(钩子),是一种过滤(或叫挂钩)消息的技术。Hook 的目的是过滤一些关键函数 调用,在函数执行前,先执行自己的挂钩函数,达到监控函数调用,改变函数功能的目的。
Hook 技术按照实现原理来分的话可以分为两种:
-
API HOOK:拦截Windows API
-
消息HOOK:拦截Windows消息
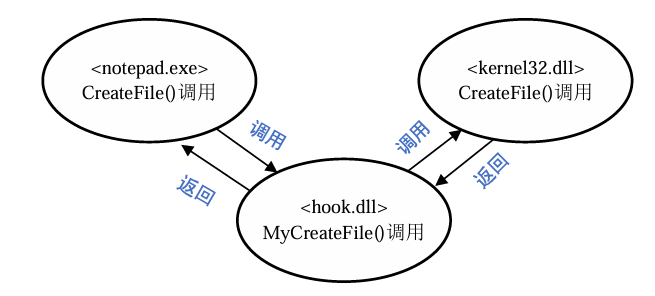
Hook 方法很多,主要包括调试法和注入法。
基于调试的HOOK技术原理:
-
跟调试器的工作机制相似,调试器拥有被调试者(被调试 进程)的所有权限(执行权限、内存访问等)。若进程被另一个进程调试了(如OllyDbg), 异常事件的处理工作将移交给调试者,比如进程发生了除0错误,OllyDbg将接收到这个异 常事件并对进行相应处理。
-
在调试Hook中,用户直接编写用于Hook的调试程序,在程序中使用调试API附加到目标进程,然后在目标进程执行处于暂停状态时设置Hook函数,当重启运行时即可实现API Hook。
-
具体操作是将要钩取的API的起始地址的第一个字节修改为0xCC (或者使用硬件断点)。汇编语言中0xCC代表汇编指令INT3,意指断点(EXCEPTION_BREAKPOINT 异常)
-
当代码调试遇到INT3指令即中断运行,EXCEPTION_BREAKPOINT异常被传送到调试器, 此时调试器就可以设置Hook,然后恢复API的起始地址原值,使程序继续运行。 注入法的Hook使用的比较多,后面就主要介绍一下注入法Hook技术。
8.3.2 消息Hook
1. 消息HOOK
对于Windows系统而言,建立在事件驱动机制上,整个系统都是通过消息传递实现的
-
在Windows系统里,消息Hook就是一个Windows消息的拦截机制,可以拦 截单个进程的消息(线程钩子),也可以拦截所有进程的消息(系统钩子),也可以对拦截的 消息进行自定义的处理:
-
对于同一事件(如鼠标消息)既安装了线程钩子又安装了系统钩子,那么系统 会自动先调用线程钩子,然后调用系统钩子。
-
对同一事件消息可安装多个钩子处理过程,这些钩子处理过程形成了钩子链。当前钩子处理结束后应把钩子信息传递给下一个钩子函数。而且最近安装的钩子放在链的开始,而最早安装的钩子放在最后,==也就是后加入的先获得控制权。==
-
钩子特别是系统钩子会消耗消息处理时间,降低系统性能。只有在必要的时候才安装钩子,在使用完毕后要及时卸载。
-
==函数SetWindowsHookEx。==Windows 提供了一个官方函数 SetWindowsHookEx 用于设置消 息Hook,编程时只要调用该API就能简单地实现Hook,
2. DLL注入示例
-
Windows 系统大量使用DLL作为组件复用,应用程序也会通过DLL实现功能模块的拆分。
-
DLL 注入技术是向一个正在运行的进程插入自有DLL的过程。
-
DLL注入的目的是将代码放进另一个进程的地址空间中,现在被广泛应用在软件分析、软件破解、恶意代码等领域,注 入方法也很多,比如利用注册表注入、CreateRemoteThread远程线程调用注入等。
-
在Windows 中,利用SetWindowsHookEx 函数创建钩子(Hooks)可以实现DLL注入。
在实验二中,将利用SetwindowsHookEx可以钩取一个键盘消息,并且调用钩子处理函数 来处理这个消息,所达到的效果和dll注入是一样的(执行DLL内部的代码)。下面的代码中, 首先通过LoadLibrary函数将DLL加载至可执行程序中。调用GetProcessAddress函数从DLL 中获取注入地址。最后设置一个全局钩子(参数设置为0表示监视全局线程),监视程序。
==实验二:利用SetWindowsHookEx 函数向记事本进程注入 DLL 文件,以实现键盘消息的 Hook。==
思路
-
编制生成 KeyHook.dll,即一个含有键盘消息 Hook 函数的(KeyboardProc)的 DLL 文件;
-
编制程序HookMain用于加载KeyHook.dll文件,通过SetSetWindowsHookEx()安 装键盘消息 Hook 函数(KeyboardProc)。
-
若其他进程(explorer.exe、iexplorer.exe、 notepad.exe 等)中发生键盘输入事件,OS就会强制将KeyHook.dll加载到相应进程的内存, 然后调用KeyboardProc()函数。
8.3.3 API Hook
API HOOK 技术是对 API 函数进行Hook(挂钩)的技术。API HOOK的基本方法
-
通过 hook“接触”到需要修改的API函数入口点,改变它的地址指向新的自定义的函数。
用途:
-
对某些Win32 API调用过程进行拦截,实现在API调用前/后运行用 户的Hook代码、查看或操作传递给API的参数或API函数的返回值、取消对API的调用,或 更改执行流程,运行用户代码。
-
微软也在Windows操作系统里面使用了这个技术,如Windows 兼容模式等。
-
计算机病毒经常使用API HOOK技术来达到隐藏自己的目的。在软件分析里,可 以通过API HOOK,实现特定函数的分析。
8.4 符号执行技术
8.4.1 基本原理
1. 程序执行状态
-
引入原因:符号执行中,符号变量使分支走向不确定,原程序状态信息不足以完整描述执行状态,因此引入路径约束条件pc来描述程序执行的控制流向。
-
定义及作用:pc是符号执行过程中对路径上条件分支走向的选择情况,是一个bool表达式,由符号执行路径上涉及的if条件语句中的表达式及表达式的真值选择拼接而成。
-
根据pc可确定一次符号执行的完整路径,辅助符号执行引擎选择执行分支并记录执行过程。
-
-
示例:假设符号执行经过3个与符号变量相关的if条件语句
-
if₁(a₁ ≥ 0)、if₂(a₁ + 2 * a₂ ≥ 0)、if₃(a₃ ≥ 0) ,
-
引擎选择if₁:true,if₂:true,if₃:false ,
-
则pc表示为(a₁ ≥ 0 ∧ a₁ + 2 * a₂ ≥ 0 ∧ ¬(a₃ ≥ 0)) 。
-
在if语句处,若执行then分支,pc包含该if条件表达式(如R≥0 );
-
若执行else分支,pc包含该表达式的否定(¬(R≥0) ) ,pc初始值为true。
-
-
与分支关系及求解:符号执行分支仅与if语句相关,选择then分支时pc = pc ∧ q(q为if条件表达式),选择else分支时pc = pc ∧ ¬q 。pc真值恒为true,确定pc对应路径的程序输入参数,可使用约束求解器对pc进行求解。
2. 符号传播
-
基本概念:在符号执行中,符号量代替实际值作为输入,运算时传递符号值而非实际值,
-
例如加法操作是将符号值相加的量传递给和,实际操作常是对应内存地址数据变化。
-
-
示例说明:
-
以
int x; int y, z; y=x\*3; z=y+5;代码为例 -
最初符号映射表中变量x的地址addr_x对应符号表达式X。
-
执行语句3时,y值取决于x,y的地址addr_y关联符号表达式X*3 ;
-
执行语句4时,z与y、x相关,addr_z关联符号表达式X*3 + 5 。
-
最终内存中addr_x、addr_y、addr_z分别保存X、X*3、X*3 + 5 。
-
-
主要作用与问题:主要作用是建立符号变量传播关系并更新映射关系。在二进制程序分析中,常将二进制代码转化为汇编语言,但汇编中逻辑结构复杂,给符号传播分析带来困难,这也是符号执行存在的问题之一。
3. 符号执行树
-
定义与构成:程序所有执行路径可表示为符号执行树
-
树中节点对应程序语句,节点间边表示语句执行顺序或跳转关系。
-
if语句处左子树为true分支,右子树为false分支,还包含指令计数、pc(路径约束条件)、变量符号值等程序执行状态信息 。
-
-
示例分析:以
foobar函数为例,通过构造执行树分析使assert函数输出失败时变量a和b取值。程序开始时pc为true,遇到分支时pc取值变化。==对非叶节点条件求解可获变量具体值==,如满足特定条件时可得出
a=2,b=0会使assert报错 。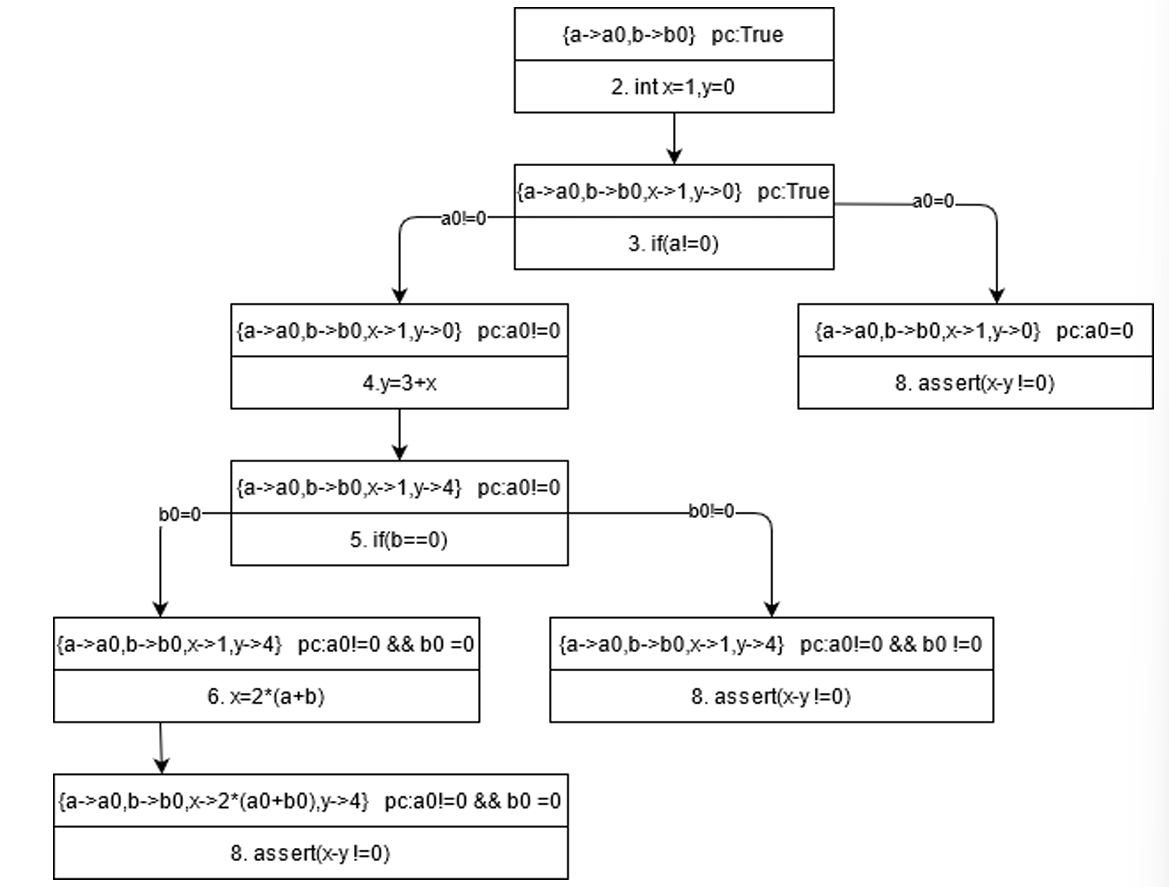
-
特性
-
叶节点输入值:每个叶节点对应一组具体输入值,可使程序执行到该状态。无设计编码错误时,叶节点pc表达式恒真,其符号变量可求解得出实际输入值;若pc表达式无解,对应路径存在逻辑问题、不可达。
-
执行状态区别:任意两个叶节点执行状态有别,因执行路径从根节点起始,在某节点处分叉,分别走不同分支,最终状态不同。
-
4. 约束求解
-
求解器理论模型
-
SAT求解器(可满足性问题):解决布尔可满足性问题,即判断由布尔变量组成的布尔表达式是否存在一组值使其为真,适用于命题逻辑公式问题,但很多实际问题无法直接转换求解。
-
SMT求解器(可满足性模理论):在SAT问题基础上扩展而来,求解范围从命题逻辑公式扩展到一阶逻辑所表达的公式,包含多种求解方法,可解决更多问题。
-
-
Z3求解器
-
简介:微软出品的开源SMT约束求解器,能为给定部分约束条件寻求一组满足条件的解,用于软件验证、程序分析等工业领域,也用于软件/硬件验证测试、约束解决等其他领域,CTF领域中密码题、二进制逆向等问题也常使用 ,二进制分析框架angr内置修改版Z3 。
-
安装(Windows):下载x64 - win版解压,配置PATH环境变量,安装Python,通过执行示例文件测试安装。
-
语法:常用API有
Solver()创建通用求解器、add()添加约束条件、check()检测解的情况、model()得出正解 ,并通过示例代码展示了变量定义、约束条件添加及求解结果显示过程。
-
8.4.2 方法分类
| 分类 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 静态符号执行 | 不实际执行程序,通过解析程序用符号值模拟执行 | 代价小、效率高 | 执行效率低、系统开销大,因忽略运行时状态信息易造成误报 |
| 动态符号执行(混合符号执行) | 以具体数值输入执行程序代码,在实际执行路径基础上,用符号执行技术分析路径,提取约束表达式,经变形求解后生成新测试用例,迭代遍历所有执行路径 | 结合真实执行和传统符号执行优点,在保证测试精度前提下可快速遍历程序执行树 | - |
| 选择性符号执行 | 对程序员感兴趣部分进行符号执行,其余部分用真实值执行 | 在特定任务环境下可进一步提升执行效率 | - |
8.4.3 Angr应用示例
Angr 是一个二进制代码分析工具,能够自动化完成二进制文件的分析,并找出漏洞。
1. Angr安装
2. Angr示例
-
常规符号执行解题思路
-
新建工程与加载文件:使用
angr.Project新建一个Angr工程,载入二进制文件,并通过load_options设置auto_load_libs为False,避免自动载入依赖库带来的干扰。例如p = anggr.Project('./issue', load_options={"auto_load_libs": False})。 -
初始化程序状态:利用
p.factory.entry_state()初始化一个模拟程序状态的SimState对象state,该对象包含程序运行时动态变化的数据。也可通过blank_state指定程序起始运行地址 。 -
符号化变量:使用
claripy.BVS创建符号变量,如u = claripy.BVS('u', 8),并将其存储到二进制文件对应的存储区,如state.memory.store(0x0804A021, u)。 -
创建模拟管理器:通过
p.factory.simulation_manager(state)创建SimulationManager对象sm,用于管理程序执行过程。 -
符号执行与状态搜索:使用
sm.explore进行符号执行,通过指定find和avoid条件筛选符合要求的状态。find条件可通过函数判断输出是否符合预期(如def correct(state): try: return b'win' in state.posix.dumps(1) except: return False),也可直接指定目标地址(如0x080484e3);avoid条件同理 。 -
求解符号变量:获得符合条件的
state后,使用solver求解器的相关函数(如eval_upto可求解指定个数可能的解,eval评估表达式获得所有可能解,eval_one获得唯一解 )来求解符号变量的值,如return sm.found[0].solver.eval_upto(u, 256)。
-
-
使用hook函数优化的解题思路
-
新建工程与加载文件:同常规思路,使用
angr.Project新建工程并载入文件,设置auto_load_libs为False。 -
定义hook函数:定义
hook_demo函数,如def hook_demo(state): state.regs.eax = 0,用于替换特定地址(如0x08048485)的指令执行逻辑,提升符号执行性能。通过p.hook(addr=0x08048485, hook=hook_demo, length=2)将hook函数挂载到指定地址 。 -
初始化程序状态:使用
p.factory.blank_state指定地址(如0x0804846B)初始化SimState对象state,并设置相关选项(如add_options={"SYMBOLIC_WRITE_ADDRESSES"}) 。 -
符号化变量:与常规思路相同,使用
claripy.BVS创建符号变量并存储到对应地址 。 -
创建模拟管理器:通过
p.factory.simulation_manager(state)创建SimulationManager对象sm。 -
符号执行与状态搜索:使用
sm.explore进行符号执行,根据源程序逻辑指定find条件(如0x080484DB),由于win和lose互斥,只需给定find条件即可 。 -
求解符号变量:获得符合条件的
state后,使用solver求解器的eval函数求解符号变量的值并打印,如print(repr(st.solver.eval(u)))。
-
常规符号执行解题思路代码添加注释
import angr
import claripy
def main():
# 1. 新建一个工程,导入二进制文件,不自动加载依赖项
p = angr.Project('./issue', load_options={"auto_load_libs": False})
# 2. 初始化一个模拟程序状态的SimState对象state,从入口点执行
state = p.factory.entry_state()
# 3. 创建一个符号变量,名为u,以8位bitvector形式存在
u = claripy.BVS('u', 8)
# 把符号变量u存储到指定地址0x0804A021
state.memory.store(0x0804A021, u)
# 4. 创建一个SimulationManager对象,管理程序执行
sm = p.factory.simulation_manager(state)
def correct(state):
try:
# 判断输出中是否包含'win'字符串
return b'win' in state.posix.dumps(1)
except:
return False
def wrong(state):
try:
# 判断输出中是否包含'lose'字符串
return b'lose' in state.posix.dumps(1)
except:
return False
# 5. 进行符号执行,找到符合correct条件且避免wrong条件的状态
sm.explore(find=correct, avoid=wrong)
# 6. 获得符合条件的state后,求解u的值
return sm.found[0].solver.eval_upto(u, 256)
if __name__ == '__main__':
print(repr(main()))
使用hook函数优化的解题思路代码添加注释
# 声明编码格式
# coding=utf-8
import angr
import claripy
def hook_demo(state):
# 将eax寄存器的值设置为0
state.regs.eax = 0
# 新建一个工程,导入二进制文件,不自动加载依赖项
p = angr.Project('./issue', load_options={"auto_load_libs": False})
# 将0x08048485处长度为2的指令用hook_demo函数替代
p.hook(addr=0x08048485, hook=hook_demo, length=2)
# 从地址0x0804846B初始化一个SimState对象state,并设置符号化写地址选项
state = p.factory.blank_state(addr=0x0804846B, add_options={"SYMBOLIC_WRITE_ADDRESSES"})
# 创建一个符号变量,名为u,以8位bitvector形式存在
u = claripy.BVS('u', 8)
# 把符号变量u存储到指定地址0x0804A021
state.memory.store(0x0804A021, u)
# 创建一个SimulationManager对象,管理程序执行
sm = p.factory.simulation_manager(state)
# 进行符号执行,找到符合条件的状态,这里根据源程序逻辑指定find条件为0x080484DB
sm.explore(find=0x080484DB)
# 获取符合条件的状态
st = sm.found[0]
# 求解符号变量u的值并打印
print(repr(st.solver.eval(u)))
8.5 污点分析技术
-
技术定位:污点分析是信息流分析的实践技术,而信息流分析在信息安全领域研究40年,是分析信息流策略是否有效实施的技术 。
-
基本原理:标记程序中的外部输入数据或内部数据为污点,分析带污点数据的传播。若污点数据信息传播给未标记数据,将其标记为污点;若污点数据传递到重要区域或信息泄露点,意味着违反信息流策略 。
-
应用领域:广泛应用于隐私数据泄露检测、漏洞挖掘等实际场景。
8.5.1 基本原理
污点分析可以抽象成一个三元组〈sources,sinks,sanitizers〉的形式,
-
其中,source 即污点源,代表直接引入不受信任的数据或者机密数据到系统中;
-
sink即污点汇聚点,代表 直接产生安全敏感操作(违反数据完整性)或者泄露隐私数据到外界(违反数据保密性);
-
sanitizer 即无害处理,代表通过数据加密或者移除危害操作等手段使数据传播不再对软件 系统的信息安全产生危害。
污点分析就是分析程序中由污点源引入的数据是否能够不经无害处理,而直接传播到污 点汇聚点。如果不能,说明系统是信息流安全的;否则,说明系统产生了隐私数据泄露或危 险数据操作等安全问题。
三个阶段
1. 识别污点源和汇聚点
-
重要性:是污点分析的前提。
-
识别困难原因:系统模型、编程语言差异以及关注的安全漏洞类型不同,缺乏通用方法。
-
现有方法分类:
-
使用启发式策略标记,如将程序外部输入视为“污”数据;
-
依据应用程序API或重要数据类型手工标记;
-
利用统计或机器学习技术自动识别标记。
-
2. 污点传播分析
-
定义:分析污点标记数据在程序中的传播途径。
-
分类及原理:
-
显式流分析:分析污点标记如何随程序中变量之间的数据依赖关系传播
-
如变量a、b被标记为污点源,依赖它们的变量x、y会被传播污点标记,若x、y到达污点汇聚点,可判定存在信息泄漏问题。
-
-
隐式流分析:分析污点标记如何随程序中变量之间的控制依赖关系传播,也就是分析污点标记如何从条件指令传播到其所控制的语句。
-
如变量X的污点标记可经控制依赖关系传播给Y,隐式流处理不当会导致欠污染(该标记未标记)或过污染(标记过多扩散)问题,目前研究重点是减少此类情况。
-
-
-
隐式流污点传播的重要性:隐式流污点传播若处理不当,会导致污点分析结果不精确。
-
欠污染问题:因隐式流污点传播处理不当,本应被标记的变量未被标记,此为欠污染问题。
-
过污染问题:由于污点标记数量过多,致使污点变量大量扩散,这是过污染问题。
-
研究重点:目前针对隐式流问题,研究方向是尽量减少欠污染和过污染情况。
3. 无害处理
-
定义及作用:污点数据传播中经无害处理模块后,不再携带敏感信息或操作不会危害系统,可移除污点标记,降低标记数量,提高分析效率,避免分析结果不精确。
-
应用场景:
-
保护保密性时,加密库函数可作无害处理模块,因加密算法使攻击者难算密码且加密后数据威胁小;
-
保护完整性时,输入验证模块(如PHP的htmlentities函数防代码注入)可作无害处理模块,使输入数据安全 。
-
8.5.2 显式流分析
根据分析过程中是否需要运行程序,将污点传播分析分为两类
1. 静态分析
-
定义:在不运行且不修改代码前提下,通过分析程序变量间数据依赖关系,检测数据从污点源到污点汇聚点的传播情况。
-
分析对象:一般为程序源码或中间表示。
-
分析方法:将显式流静态分析转化为静态数据依赖分析,先构建函数调用图,再在函数内或函数间依程序特性进行数据流传播分析。
-
传播方式:包括直接赋值传播、函数(过程)调用传播、别名(指针)传播。以Java程序为例展示传播过程。
-
研究重点:为别名传播分析提供更精确、高效方案。
-
因高精确度静态分析时空开销大,尝试按需定制别名分析方法解决别名传播问题。
-
2. 动态分析
-
定义:在程序运行时,实时监控污点数据传播,检测其从污点源到污点汇聚点的情况。
-
实现方式:先为污点数据扩展污点标记标签并存储,再依指令类型和操作数设计传播逻辑。
-
分类及特点:
-
基于硬件:需定制硬件,扩展寄存器或内存标记位存污点标记,可降低开销,
-
但难支持高语义逻辑安全策略,需重新设计处理器结构。
-
-
基于软件:修改二进制代码存储与传播污点标记,如TaintEraser,优点是无需更改硬件,可支持高语义逻辑安全策略,
-
缺点是插桩或代码重写开销大。
-
-
混合型:折中方案,如Flexitaint、PIFT ,通过少量硬件改动保证高语义逻辑安全策略。
-
-
研究重点:
-
设计传播逻辑:定义常见污点传播逻辑规则,如对不同指令的标记传播方式。
-
降低分析代价:思路包括有选择分析指令,如LIFT快速路径优化;用低开销机制代替高开销机制,如LIFT快速切换优化。
-
8.5.3 隐式流分析
-
定义与分类:隐式流分析是分析污点数据通过控制依赖进行传播的过程,可分为静态分析和动态分析两类。忽略该分析会致欠污染,分析不当则可能出现欠污染和过污染 。
-
静态分析
-
核心问题:
-
精度与效率难以兼顾。精确分析需分析每个分支控制条件,但路径敏感数据流分析会致路径爆炸、开销大;
-
简单标记分支语句方法虽降开销,却会引发过污染,使污点大量扩散,报告信息过多难用。
-
-
-
动态分析的三个问题
-
首要问题:确定污点控制条件下需标记语句的范围。因动态执行轨迹无法反映指令控制依赖关系,现==多借助离线静态分析辅助判断==,利用控制流图节点间后支配关系解决隐式流标记问题 。
-
部分泄漏(漏报)问题:指污点信息通过动态未执行部分传播泄漏。仅标记分支条件下语句会引发此问题,解决方法是标记污点分支控制范围内所有赋值语句变量,但会导致过污染 。
-
分支选择问题:单纯传播所有含污点标记分支会致过污染,需依信息泄漏范围定量设计污点标记分支选择策略。如不同分支条件下攻击者还原信息难易度不同,对某些分支传播意义不大。虽有相关研究,但仍存未解决问题,如DTA++工具仅关注信息完整保存分支,存在信息仍可从其他范围泄漏的情况 。
-

















 2863
2863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









