




 本文详细介绍了使用Python读取PDF文件的方法,包括如何利用pdfminer库解析PDF文档、获取页面内容及文本信息。通过示例代码展示了从打开PDF文件到读取文本的全过程,适合初学者了解Python处理PDF的基本流程。
本文详细介绍了使用Python读取PDF文件的方法,包括如何利用pdfminer库解析PDF文档、获取页面内容及文本信息。通过示例代码展示了从打开PDF文件到读取文本的全过程,适合初学者了解Python处理PDF的基本流程。
pdf读取总刚要:
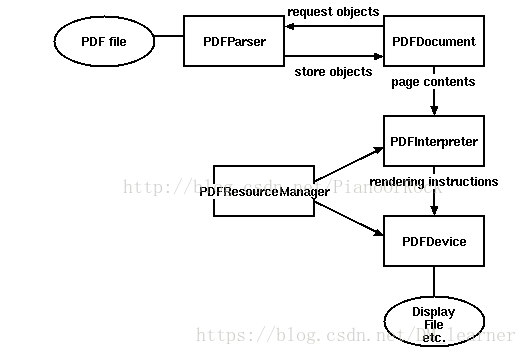
(1)
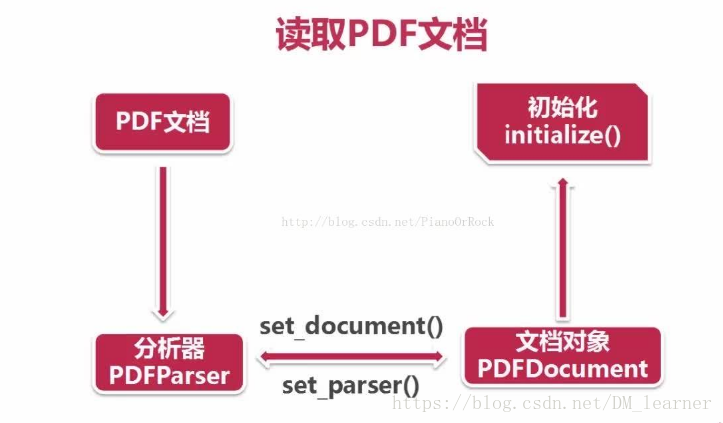
(2)
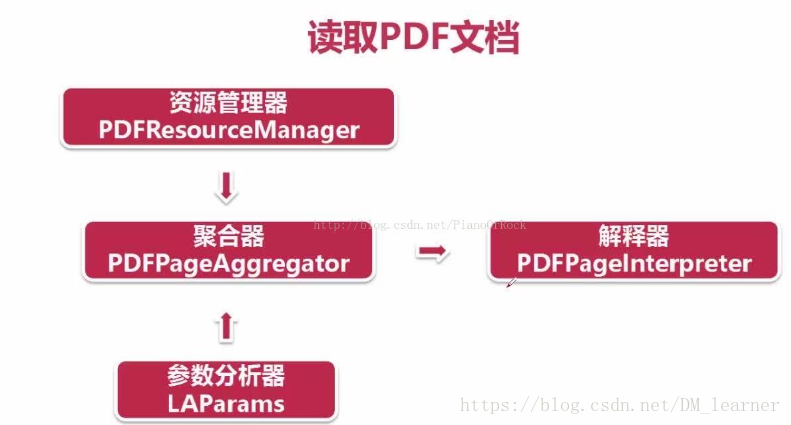
(3)
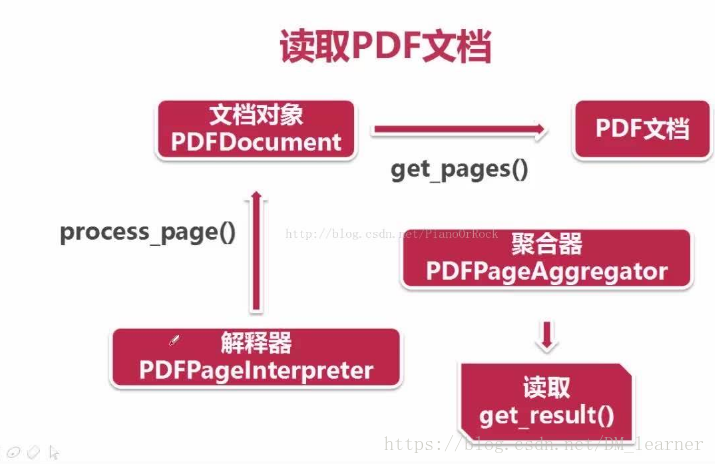
代码如下:
#!/usr/bin/env python3
#coding=utf-8
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager,PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pprint import pprint
#获取文档对象
pdf=open(r'C:\Users\pc\Desktop\医疗数据\医疗机构数据\2015年全省各地区每千人口床位、人员、医生、护士数(常住).pdf','rb',encoding='Unicode')
#创建一个与文档关联的解释器
parser=PDFParser(pdf)
#创建一个PDF文档对象
doc=PDFDocument()
#连接文档对象和文件解释器
parser.set_document(doc) #存储对象
doc.set_parser(parser) #请求对象
#文档初始化
doc.initialize('')
#创建PDF资源管理器
resources=PDFResourceManager()
#创建参数分析器
analyparam=LAParams()
#创建一个聚合器,并接受资源管理器,参数分析器作为参数
polymerizer=PDFPageAggregator(resources,laparams=analyparam)
#创建一个页面解释器,将PDF资源管理器和聚合器作为参数
pageInterpreter=PDFPageInterpreter(resources,polymerizer)
#使用文档对象获取页面的集合
for page in doc.get_pages():
#使用页面解释器读取页面信息
pageInterpreter.process_page(page)
#使用聚合器读取页面内容
layout=polymerizer.get_result()
for out in layout:
if hasattr(out,'get_text'):
pprint(out.get_text)
注:对于python读取pdf文件,要想成功必须pdf文件是一个比较规范的格式,如果是一个不规范的表格形式,就会出现乱码错误,个人觉得python读取pdf文件的准确性,并不是特别高,希望读者多用别的方法尝试。

















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









