




 本文探讨了数据预处理的重要性,包括无量纲化、二值化、哑编码和缺失值处理,以及特征选择和降维的方法。无量纲化确保特征在同一尺度,二值化处理信息冗余,哑编码转换定性特征。特征选择通过相关性分析、模型构建、L1正则化、预选模型打分和深度学习实现。降维技术如PCA和LDA用于减少数据维度。
本文探讨了数据预处理的重要性,包括无量纲化、二值化、哑编码和缺失值处理,以及特征选择和降维的方法。无量纲化确保特征在同一尺度,二值化处理信息冗余,哑编码转换定性特征。特征选择通过相关性分析、模型构建、L1正则化、预选模型打分和深度学习实现。降维技术如PCA和LDA用于减少数据维度。
https://blog.youkuaiyun.com/qq_39521554/article/details/78877505
https://blog.youkuaiyun.com/u010358304/article/details/80693541
1、数据的预处理
- 为什么需要数据的预处理?
- 不属于同一量纲:即特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题。
- 信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题。
- 定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。通常使用哑编码的方式将定性特征转换为定量特征:假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果。
- 存在缺失值:缺失值需要补充。
- 信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的,之前提到在线性模型中,使用对定性特征哑编码可以达到非线性的效果。类似地,对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果。
1.1、无量纲化
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
1.1.1、标准化
标准化需要计算特征的均值和标准差,公式表达为:
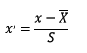
1.1.2、区间放缩法
区间缩放法的思路有多种,常见的一种为利用两个最值进行缩放,公式表达为:
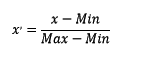
1.2、对定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下:
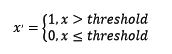
1.3、对定性特征哑编码
1.4、缺失值的计算
- 若缺失值的样本总数比例极高,直接舍弃。如果作为特征加入的话,可能反倒代入noise,影响最后的结果;
- 缺失值样本适中,且属性为非连续属性(eg.类目属性),那就把NaN作为一个新类别,加到类别特征中去;
- 缺失值样本适中,且属性为连续属性,考虑给定一个step,然后离散化,之后把NaN作为一个type加到属性类目中;
- 若缺失值个数不多,可以根据已有的数据进行拟合(rf等),进行补充。
2、特征选择
- 计算每一个特征与响应变量的相关性:工程上常用的手段有计算皮尔逊系数和互信息系数,皮尔逊系数只能衡量线性相关性而互信息系数能够很好地度量各种相关性,但是计算相对复杂一些,好在很多toolkit里边都包含了这个工具(如sklearn的MINE),得到相关性之后就可以排序选择特征了.(其实就是计算输出关于输入的导数,如果某个特征很大程度上影响了输出,那么该特征就会比较重要)。
- 构建单个特征的模型,通过模型的准确性为特征排序,借此来选择特征。当选择到了目标特征之后,再用来训练最终的模型。
- 通过L1正则项来选择特征:L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性,但是要注意,L1没有选到的特征不代表不重要,原因是两个具有高相关性的特征可能只保留了一个,如果要确定哪个特征重要应再通过L2正则方法交叉检验。
- 训练能够对特征打分的预选模型:RandomForest和Logistic Regression等都能对模型的特征打分,通过打分获得相关性后再训练最终模型;
- 通过特征组合后再来选择特征:如对用户id和用户特征组合来获得较大的特征集再来选择特征,这种做法在推荐系统和广告系统中比较常见,这也是所谓亿级甚至十亿级特征的主要来源,原因是用户数据比较稀疏,组合特征能够同时兼顾全局模型和个性化模型,这个问题有机会可以展开讲。
- 通过深度学习来进行特征选择:目前这种手段正在随着深度学习的流行而成为一种手段,尤其是在计算机视觉领域,原因是深度学习具有自动学习特征的能力,这也是深度学习又叫unsupervisedfeature learning的原因。从深度学习模型中选择某一神经层的特征后就可以用来进行最终目标模型的训练了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









