




 本文介绍了Spark,它是快速通用的集群计算平台,能在内存计算,速度快且高效。阐述其核心特性,包括Spark Core、SQL、Streaming、MLlib、GraphX及集群管理器。还提及用途,可用于大数据科学和开发数据处理应用,且支持多种存储系统。
本文介绍了Spark,它是快速通用的集群计算平台,能在内存计算,速度快且高效。阐述其核心特性,包括Spark Core、SQL、Streaming、MLlib、GraphX及集群管理器。还提及用途,可用于大数据科学和开发数据处理应用,且支持多种存储系统。
1、Spark是什么?
Spark是一个用来实现快速而通用的集群计算平台。
在速度方面,Spark扩展了广泛使用的MR(MapReduce以后就叫mr)计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。在处理大规模数据集时,速度是非常重要地。速度快就意味着我们可以进行交互式地数据操作,否则我们每次操作就需要等待数分钟甚至数小时。Spark的一个主要特点就是能够在内存中进行计算,因而更快。不过即使是必须在磁盘上进行的复杂计算,Spark依然比mr更加高效。
总的来说,Spark适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。Spark给我一种大数据界的Spring的错觉。丰富的接口,多语言支持,贼溜。。。
2、Spark核心特性
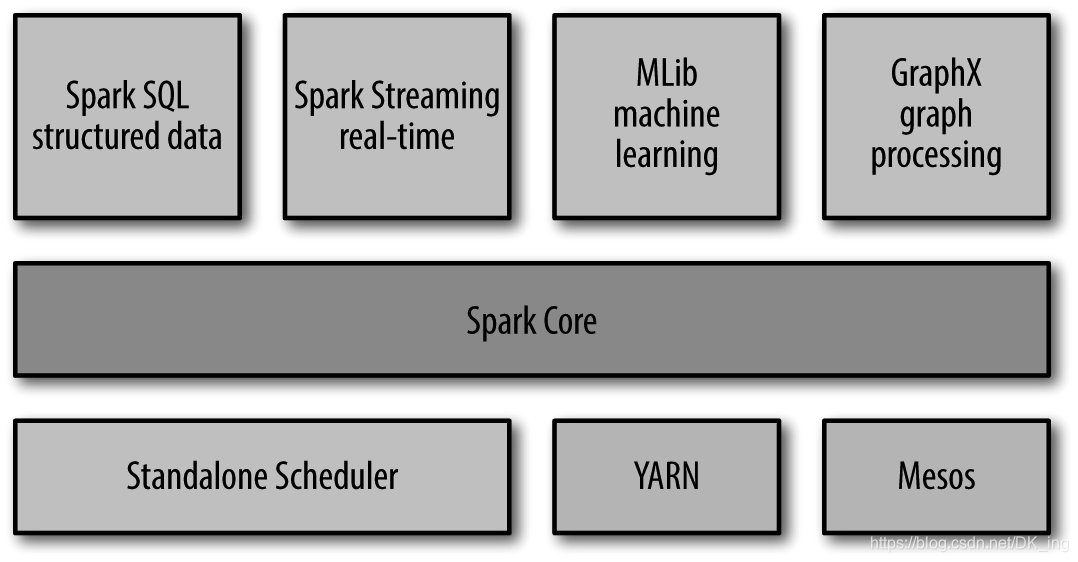
Spark Core
实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。其中包含了核心RDD(resilient distributed dataset)弹性分布式数据集的API定义。RDD贯穿Spark。
Spark SQL
Spark SQL是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL或者Apache hive版本的sql来查询数据。Spark SQL支持多种数据源,Hive为最常用文件式存储库,与hdfs结合使用,hive完美支持了parquet(折磨了我好几天的变态结构。。。)等结构。
Spark Streaming
Spark Streaming是Spark的流式计算,项目中多用于处理消息中间件如kafka,rabbitmq的消息队列。
MLlib
Spark中还包含一个提供常见的机器学习ML功能的程序库,这个比较6了,暂时还没用过,提供了很多种机器学习算法,包括分类、回归、聚集、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
GraphX
是用来操作图的程序库,可以进行并行的图计算。
集群管理器
Spark支持在各种集群管理器上运行,包括YARN、Mesos等等。
3、Spark用途
大数据科学领域,咳咳咱就不说了,咱不懂,咱也不敢问。。。
Spark的另一个主要用例是针对工程师的。为使用Spark开发生产环境中的数据处理应用的软件开发。
4、Other
Spark的存储层次,Spark不仅可以将任何Hadoop分布式文件系统HDFS上的文件读取为分布式数据集,也可以支持其他支持Hadoop接口的系统,如本地文件、Cassandra、Hive、Hbase、DB等等。我们需要清楚的是,Hadoop并非Spark的必要条件,Spark支持任何实现了Hadoop接口的存储系统,6不6.

















 2317
2317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









