




 本文介绍了序列化的意义、面临的问题及实现方法。阐述了serialVersionUID作用、静态变量和父类序列化等高阶知识。还列举了常见序列化技术,如Java、XML、JSON等,并分析其优缺点。最后从技术层面给出序列化技术的选型建议。
本文介绍了序列化的意义、面临的问题及实现方法。阐述了serialVersionUID作用、静态变量和父类序列化等高阶知识。还列举了常见序列化技术,如Java、XML、JSON等,并分析其优缺点。最后从技术层面给出序列化技术的选型建议。
目录
序列化的意义
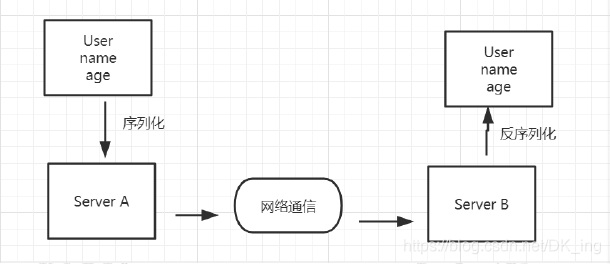
序列化是把对象的状态信息转化为可存储或传输的形式过程,也就是把对象转化为字节序列的过程称为对象的序列化
反序列化是序列化的逆向过程,把字节数组反序列化为对象,把字节序列恢复为对象的过程称为对象的反序列化。
序列化面临的问题
评价一个序列化算法优劣的两个重要指标:序列化以后的数据大小;序列化操作本身的速度及系统资源开销(CPU、内存) ;
Java语言本身提供了对象序列化机制,也是Java语言本身最重要的底层机制之一,Java本身提供的序列化机制存在两个问题
- 序列化的数据比较大,传输效率低
- 其他语言无法识别和对接
如何实现一个序列化操作
在Java中,只要一个类实现了java.io.Serivalizable接口,那么它就可以被序列化
/**
* @author King Chen
* @Date: 2019/3/18 11:27
*/
public interface ISerializer {
/**
* 序列化
*
* @param obj
* @param <T>
* @return
*/
<T> byte[] serialize(T obj);
/**
* 反序列化
*
* @param data
* @param clazz
* @param <T>
* @return
*/
<T> T deserialize(byte[] data, Class<T> clazz);
}基于JDK序列化方式实现
JDK提供了Java对象的序列化方式,主要通过输出流java.io.ObjectOutputStream和对象输入流java.io.ObjectInputStream来实现。其中,被序列化的对象需要实现java.io.Serializable接口
/**
* @author King Chen
* @Date: 2019/3/18 11:31
*/
public class JavaSerializer implements ISerializer {
@Override
public <T> byte[] serialize(T obj) {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
try {
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(obj);
} catch (IOException e) {
e.printStackTrace();
}
return byteArrayOutputStream.toByteArray();
}
@Override
public <T> T deserialize(byte[] data, Class<T> clazz) {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data);
try {
ObjectInput objectInput = new ObjectInputStream(byteArrayInputStream);
return (T) objectInput.readObject();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
return null;
}
}具体实现
通过对一个user对象进行序列化操作
/**
* @author King Chen
* @Date: 2019/3/18 11:37
*/
public class User implements Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
/**
* @author King Chen
* @Date: 2019/3/18 11:38
*/
public class SerializeTest {
public static void main(String[] args) {
ISerializer serializer = new JavaSerializer();
User user = new User();
user.setAge(25);
user.setName("King");
byte[] serialByte = serializer.serialize(user);
User dUser = serializer.deserialize(serialByte, User.class);
System.out.println(dUser);
}
}序列化的高阶认识
serialVersionUID的作用
Java的序列化机制时通过判断类的serialVersionUID来验证版本一致性的,在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地响应实体类的serialVersionUID进行比较,如果相同就认为时一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即InvalidCastException。
如果没有为指定的class配置serialVersionUID,那么Java编译器会自动给这个class进行一个摘要算法,类似于指纹算法,只要这个文件有任何改动,得到的serialVersionUID就会截然不同,可以保证在这么多类中,这个编号是唯一的
serialVersionUID的两种显示的生成方式:
- 默认的1L,比如:private static final long serialVersionUID = 1L;
- 根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段
当实现java.io.Serializable接口的类没有显示的定义一个serialVersionUID变量时候,Java序列化机制会根据编译的Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果Class文件(类名,方法名)没有发生变化(增加空格,换行,注释等),serialVersionUID是不会变化的。
静态变量序列化
/**
* @author King Chen
* @Date: 2019/3/18 11:38
*/
public class SerializeTest {
public static void main(String[] args) {
ISerializer serializer = new JavaSerializer();
User user = new User();
user.setAge(25);
user.setName("King");
byte[] serialByte = serializer.serialize(user);
System.out.println(user + "-" + User.num);
User.num = 10;
User dUser = serializer.deserialize(serialByte, User.class);
System.out.println(dUser + "-" + User.num);
}
}输出结果为10,之所以是这样一个结果,是因为序列化时,并不保存静态变量,序列化保存的是对象的状态,静态比那辆数据类的状态,因此序列化并不保存静态变量
父类的序列化
- 当一个父类没有实现序列化,子类继承该弗列并实现序列化。父类中的属性无法被序列化。
- 当一个父类实现了序列化,子类自动实现序列化。不需要再显示实现Serializable接口
- 当一个对象的实例变量引用了其他对象,序列化该对象时也会把引用对象进行序列化,但是前提是该引用对象必须实现序列化接口。
Transient关键字
Transient关键字的作用是控制变量的序列化,在变量声明前加上Transient关键字,可以阻止该变量被序列化到文件中,在被反序列化后,Transient变量的值被设为初始值,如int是0等。
绕开transient关键字的方法
/**
* @author King Chen
* @Date: 2019/3/18 11:37
*/
public class User implements Serializable {
private String name;
private int age;
private transient String hobby;
private void writeObject(ObjectOutputStream objectOutputStream) throws IOException {
objectOutputStream.defaultWriteObject();
objectOutputStream.writeObject(hobby);
}
private void readObject(ObjectInputStream objectInputStream) throws IOException, ClassNotFoundException {
objectInputStream.defaultReadObject();
hobby = (String) objectInputStream.readObject();
}
......
}注:ObjectOutputStream使用了反射来寻找是否声明了这两个方法。因为ObjectOutputStream使用getPrivateMethod,所以这些方法必须声明为private供ObjectOutputStream使用。
序列化的存储规则
对统一个对象进行两次序列化,第二次写入对象时文件只增加了5字节,Java序列化机制为了节省磁盘空间,具有特定的存储规则,当写入同一对象的文件时,并不会再将对象的内容进行存储,而只是再次存储一份引用,上面增加的5字节的存储空间就是新增引用和一些控制信息的空间。反序列化时,恢复引用关系,该存储规则极大的节省了存储空间。
常见的序列化技术
使用Java进行序列化
优点:Java语言本身提供,使用比较方便和简单
缺点:不支持跨语言处理、性能相对不是很好,序列化以后产生的数据相对较大
XML序列化框架
XML序列化的好处在于可读性好,方便阅读和调试。但是序列化以后的字节码文件比较大,而且效率不高,适用于对性能不高,而且QPS较低的企业级内部系统之间的数据交换场景,同时XML又具有语言无关性,所以还可以用于异构系统之间的数据交换和协议。比如我们熟悉的WebService,就是采用XML格式对数据进行序列化的
JSON序列化框架
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,相对于XML来说,JSON的字节流更小,而且可读性也非常好。现在JSON数据格式咋i企业运用是最普遍的
JSON序列话常用的开源工具有很多:
- Jackson(https://github.com/FasterXML/jackson)
- FastJson(https://github.com/alibaba/fastjon)
- Google 的GSON (https://github.com/google/gson)
这几种json序列化工具中,Jackson与fastJson要比GSON的性能好,但是Jackson、GSON的稳定性比FastJson好。而FastJson的优势在于提供的API非常容易使用
Hessian序列化框架
Hessian是一个支持跨语言传输的二进制序列化协议,相对于Java默认的序列化机制来说,Hessian具有更好的性能和易用性,而且支持多种不同的语言
实际上Dubbo采用的就是Hessian序列化来实现,只不过Dubbo对Hessian进行了重构,性能更高
Protobuf序列化框架
Protobuf是Google的一种数据交换格式,它独立于语言、平台。
Google提供了多种语言来实现,比如Java、C、Go、Python,每一种实现都包含了相应语言的编译器和库文件
Protobuf使用比较广泛,主要是空间开销小和性能比较好,非常适合用于公司内部对性能要求高的RPC调用。另外由于解析性能比较高,序列化以后数据量相对较少,所以也可以应用再对象的持久化场景中但是要使用Protobuf会相对来说比较麻烦,因为它有自己的语法,有自己的编译器
- 下载Protobuf工具:https://github.com/google/protobuf/releases
- 编写proto文件
-
proto的语法syntax="proto2"; package com.gupaoedu.serial; option java_package = "com.gupaoedu.serial"; option java_outer_classname="UserProtos"; message User { required string name=1; required int32 age=2; }- 包名
- option选项
- 消息模型(消息对象、字段(字段修饰符-required/optional/repeated)、字段类型(基本数据类型、枚举、消息对象)、字段名、标识号)
-
- 生成实体类
.\protoc.exe --java_out=./ ./user.proto- 在protoc.exe安装目录下执行如下命令
- 运行查看结果
- 将生成以后的UserProto.java拷贝到项目中
序列化技术的选型
技术层面
- 序列化空间开销,也就是序列化产生的结果大小,这个影响到传输的性能
- 序列话过程中小号的时长,序列化小号时间过长影响到业务的响应时间
- 序列化协议是否支持跨平台、跨语言。仅为现在的框架更加灵活,如果存在异构系统通信需求,那么这个是必须要考虑的
- 可扩展性/兼容性,在实际业务开发中,系统往往需要随着需求的快速迭代来是西安快速更新,这就要求我们采用的序列化协议基于良好的可扩展性/兼容性,比如现有的序列化数据结构中新增一个业务字段,不会影响到现有的服务
- 技术的流行程度,越流行的技术意味着使用的公司越多,那么很多坑已经淌过并且得到了解决,技术解决方案也相对成熟
- 学习难度和易用性
选型建议
- 对性能要求不高的场景,可以采用基于XML的SOAP协议
- 对性能和间接性有比较高要求的场景,那么Hessian、Protobuf、Thrift、Avro都可以
- 基于前后端分离,或者独立的对外API服务,选用JSON是比较好的,对于调试、可读性都是很不错的
- Avro设计理念偏于动态类型语言,那么这类场景使用Avro是可以的

















 2123
2123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









