




 本文深入解析Xdelta3的字符串匹配策略,包括RUN指令匹配、大匹配和小匹配。重点阐述滑动匹配窗口、大匹配哈希表及其匹配流程。文章详细介绍了匹配算法的核心代码,帮助读者理解Xdelta3如何实现高效低成本的字符串匹配。
本文深入解析Xdelta3的字符串匹配策略,包括RUN指令匹配、大匹配和小匹配。重点阐述滑动匹配窗口、大匹配哈希表及其匹配流程。文章详细介绍了匹配算法的核心代码,帮助读者理解Xdelta3如何实现高效低成本的字符串匹配。
前言
拖了这么长时间,终于把Xdelta3的字符串匹配解析做好了,这个部分是我们整个系列解析中最重要的部分,想要把它解释清楚说明白还真不是一件容易的事,着实费了我不少功夫。
闲话少叙,直入主题。(内容比较多,不过相信我,如果耐心看完,一定会有收获^ ^)
介绍
Xdelta3中使用的字符串匹配策略是:全局贪婪,局部懒惰。
在Xdelta3中定义了三种字符串匹配方式:RUN指令匹配、大匹配、小匹配,后面将按照开销程度依次介绍。
在此之前,我们先定义几个变量:
next_in:目标窗口的起始位置。avail_in:目标窗口的长度。input_position:目标窗口当前的输入位置。
假设目标窗口的数据流向是自左向右,那么在input_position左边的数据就是已经匹配完成,被包含在生成的增量指令中的字符串,在input_position右边的数据就是尚未匹配的字符串,也即我们每次匹配的起始位置。inp:临时指针变量,指向目标窗口当前的输入位置,即当前尝试匹配的字符。
在每次匹配开始时inp=next_in+input_position。min_match:最短匹配长度。
即一段匹配的字符串中至少要包含min_match个字符,这个数值是可变的,主要作用是为了避免冗余匹配。match_srcpos:源文件中的匹配位置。
除此之外,函数内部还定义了如下变量,后续源码解析中会用到:
const int DO_SMALL = !(stream->flags & XD3_NOCOMPRESS); //如果没有禁用数据压缩功能则启用小匹配模式
const int DO_LARGE = (stream->src != NULL); //如果存在源文件则启用大匹配模式
const int DO_RUN = (1); //默认开启RUN指令匹配
const uint8_t *inp; //指向输入文件当前位置
uint32_t scksum = 0; //单个字符的校验和
uint32_t scksum_state = 0; //单个字符的32位表示
uint32_t lcksum = 0; //长度为LLOOK的字符串校验和
usize_t sinx; //小匹配哈希表的哈希索引值
usize_t linx; //大匹配哈希表的哈希索引值
uint8_t run_c; //RUN指令操作的字符
usize_t run_l; //字符run_c重复的次数
usize_t match_length; //匹配数据的长度
usize_t match_offset = 0; //将要被编码成COPY指令的匹配数据的起始偏移地址
usize_t next_move_point; //源文件校验和的计算位置
int ret; //返回值
RUN指令匹配
顾名思义,这个字符串匹配方式是针对RUN指令的,当目标文件中某个字符连续出现多次时,我们就需要考虑其是否满足RUN指令的匹配方式。
首先我们要先判断从当前字符inp开始的连续min_match个字符是否都相同,并记录字符的重复次数run_l,若run_l等于min_match,则开始尝试惰性匹配,从inp[run_l]开始依次判断后续字符是否相同,并同时更新run_l的值;直到遇到不相同的字符或达到目标窗口结尾为止。
然后就生成一条RUN指令到指令缓冲区中,该RUN指令的size就等于run_l。但此时并不立即更新input_position,而是将input_position右移一位,并设置min_match = run_l,原因是对于不同类型增量指令的成本来说,COPY指令的开销是要小于RUN指令的,所以我们更期望能找到一串更长的匹配字符串用于生成COPY指令来覆盖这条RUN指令所包含的数据,因此最短匹配长度min_match 也需要更新为run_l。
大匹配
这个字符串匹配方式是发生在源文件中的,所以使用该匹配方式的首要前提就是要包含源文件。
一般来说,字符串匹配都是从一个匹配的字符开始,但在实际情况下,我们不可能每编码一个目标文件的字符就从头到尾检索一遍源文件,这样做的效率是非常低的。因此在Xdelta3中,使用了滑动匹配窗口的匹配算法,它可以使每次匹配检索一段字符串,而非一个字符,从而大幅度提高匹配效率。
滑动匹配窗口
这个算法执行在字符串匹配之前,滑动匹配窗口的作用是计算被窗口包含的字符串的校验和,并记录此时匹配窗口的起始位置;每计算一次字符串校验和后,匹配窗口滑动large_step个字节单位;滑动是由尾部向头部(自右向左)的方向进行,直到窗口的下一次滑动将超过源文件起始位置为止。
滑动匹配窗口的大小为large_look,即每次计算校验和的字符串长度;匹配窗口的大小large_look和滑动距离large_step共同决定了大匹配方式的匹配效率,在Xdelta3中内设了五种字符串匹配的参数配置,其中对large_look和large_step配置的值分别为:
| large_look | large_step | |
|---|---|---|
| DEFAULT | 9 | 3 |
| SLOW | 9 | 2 |
| FAST | 9 | 8 |
| FASTER | 9 | 15 |
| FASTEST | 9 | 26 |
Xdelta3也支持用户自定义字符串匹配参数配置,下面我们以默认配置为例,来进一步了解滑动匹配窗口算法:

如图所示,匹配窗口从源文件末尾开始,包含长度为large_look个字节的字符串,每次向前滑动large_step个字节,直到源文件的起始位置。
计算源窗口校验和的函数源码解析:
//使用滑动匹配窗口算法推进源文件数据校验和的计算,若计算完所有源数据,则next_move_point = USIZE_T_MAX,否则next_move_point指向下一次计算校验和的位置。
static int xd3_srcwin_move_point(xd3_stream *stream, usize_t *next_move_point)
{
xoff_t target_cksum_pos; //源校验和的目标计算位置
xoff_t absolute_input_pos; //目标文件的绝对输入位置(加上目标文件的起始偏移量)
//当源文件的长度是已知时
if (stream->src->eof_known)
{
xoff_t source_size = xd3_source_eof(stream->src); //获取整个源文件的长度
//stream->srcwin_cksum_pos是已计算校验和的源文件位置
if (stream->srcwin_cksum_pos == source_size)
{
*next_move_point = USIZE_T_MAX;
return 0;
}
}
absolute_input_pos = stream->total_in + stream->input_position;
//确定要计算校验和的源数据范围
if (absolute_input_pos < stream->src->max_winsize / 2)
{
target_cksum_pos = stream->src->max_winsize;
}
else
{
target_cksum_pos = absolute_input_pos + stream->src->max_winsize / 2 + stream->src->blksize * 2;
target_cksum_pos &= ~stream->src->maskby;
}
//当匹配的字符串已经越过了上一次最后计算源校验和的位置时,不计算已经匹配的源数据校验和
if (stream->maxsrcaddr > stream->srcwin_cksum_pos)
{
stream->srcwin_cksum_pos = stream->maxsrcaddr;
}
if (target_cksum_pos < stream->srcwin_cksum_pos)
{
target_cksum_pos = stream->srcwin_cksum_pos;
}
//开始计算源校验和,源文件通常比较大,因此会被分割成多个源窗口,每个源窗口也被称为源块
while (stream->srcwin_cksum_pos < target_cksum_pos && (!stream->src->eof_known || stream->srcwin_cksum_pos < xd3_source_eof(stream->src)))
{
xoff_t blkno; //当前计算校验和的源窗口块号
xoff_t blkbaseoffset; //当前计算校验和的源窗口起始偏移地址
usize_t blkrem; //用于暂存已计算过校验和的源位置
ssize_t oldpos; //已计算过校验和的源位置
ssize_t blkpos; //滑动匹配窗口的起始位置(从源窗口的尾部向首部滑动): do { blkpos-- } while (blkpos >= oldpos);
int ret;
//xd3_blksize_div函数计算stream->srcwin_cksum_pos对应的源窗口块号blkno,并计算该地址在块内的偏移位置blkrem。
xd3_blksize_div(stream->srcwin_cksum_pos, stream->src, &blkno, &blkrem);
oldpos = blkrem;
//xd3_getblk函数用于获取源窗口块号为blkno的相关信息,成功返回0
if ((ret = xd3_getblk(stream, blkno)))
{
if (ret == XD3_TOOFARBACK)
{
ret = XD3_INTERNAL;
}
return ret;
}
blkpos = xd3_bytes_on_srcblk(stream->src, blkno); //xd3_bytes_on_srcblk函数返回块号blkno的长度
//如果滑动匹配窗口越过源窗口的起始位置,则表示已计算完当前源窗口的校验和
if (blkpos < (ssize_t)stream->smatcher.large_look)
{
stream->srcwin_cksum_pos = (blkno + 1) * stream->src->blksize;
continue;
}
blkpos -= stream->smatcher.large_look;
blkbaseoffset = stream->src->blksize * blkno;
/* 从源窗口的末尾开始计算滑动匹配窗口内数据的校验和,每次计算large_look个字节,每次计算后匹配窗口向块首滑动large_step个字节;
* 并将每次计算得到的校验和通过hash函数计算出哈希表large_table的索引值hval,large_table[hval] = (滑动匹配窗口的起始地址 + HASH_CKOFFSET) */
do
{
uint32_t cksum = xd3_lcksum(stream->src->curblk + blkpos, stream->smatcher.large_look); //计算匹配窗口数据的校验和
usize_t hval = xd3_checksum_hash(&stream->large_hash, cksum); //计算cksum的哈希值hval
stream->large_table[hval] = (usize_t)(blkbaseoffset + (xoff_t)(blkpos + HASH_CKOFFSET)); //用hval作为索引存放匹配窗口的起始地址
blkpos -= stream->smatcher.large_step; //匹配窗口滑动large_step个字节
} while (blkpos >= oldpos);
stream->srcwin_cksum_pos = (blkno + 1) * stream->src->blksize;
}
/* 当知道源文件结尾时,若srcwin_cksum_pos的位置超过或刚好到达源文件结尾,则源校验和计算完成;
* stream->srcwin_cksum_pos = source_size;next_move_point = USIZE_T_MAX,返回0。*/
if (stream->src->eof_known)
{
xoff_t source_size = xd3_source_eof(stream->src); //源文件的结束地址
if (stream->srcwin_cksum_pos >= source_size)
{
stream->srcwin_cksum_pos = source_size;
*next_move_point = USIZE_T_MAX;
return 0;
}
}
//更新next_move_point
*next_move_point = stream->input_position + stream->src->blksize - ((stream->srcwin_cksum_pos - target_cksum_pos) & stream->src->maskby);
return 0;
}
大匹配哈希表
每次计算完一个匹配窗口中字符串的校验和后,就需要将当前窗口的起始位置记录下来,那么就需要一张表来存储这些位置信息。在Xdelta3中定义了一张用于保存滑动匹配窗口起始位置的哈希表,我们简称它为大匹配哈希表。
每次计算出来的校验和通过哈希函数生成一个哈希值,而这个哈希值就作为在大匹配哈希表中保存该匹配窗口起始位置信息的索引值。
大匹配流程
由于大匹配字符串方式使用的是哈希表检索,因此就不需要遍历查找匹配,而是在每次匹配开始时,先计算目标文件当前位置开始large_look个字节的字符串的校验和,然后通过哈希函数计算出该校验和的哈希值,将此哈希值作为索引检索大匹配哈希表,如果该索引位置上存在数据,则表示源文件中含有匹配的字符串。
接着从大匹配哈希表中取出匹配字符串的起始位置,基于该位置开始尝试将匹配的字符串向两侧展开,以期望获得更长的匹配字符串,我们接着上面的例子来讲解:
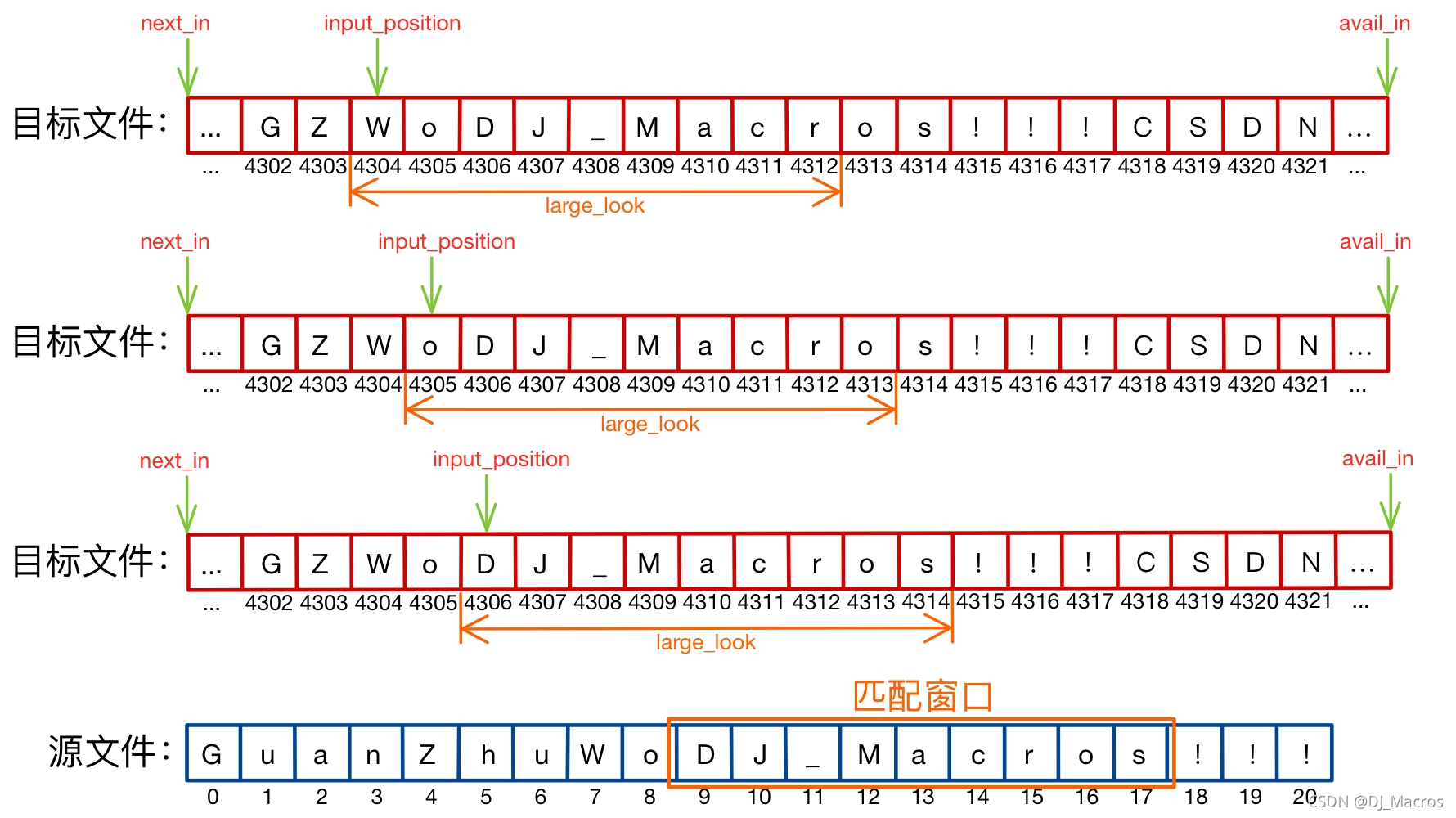
假设有如图所示的目标文件,此时input_position指向下标为4304的字符'W',计算字符串"WoDJ_Macr"的校验和,并将该校验和通过哈希函数得到的哈希值作为大匹配哈希表的索引,发现索引值为空,则表示该字符串在源文件中没有对应匹配,input_position向右移动一位,继续从下一个字符开始尝试匹配。
下一段长度为input_position的字符串"oDJ_Macro"同样在源文件中没有匹配的字符串,input_position再向右移动一位。
此时计算的字符串"DJ_Macros",其校验和的哈希值在大匹配哈希表中的索引不为空,则表示该字符串在源文件中有对应的匹配。通过索引得到源文件中的匹配位置match_srcpos = 9,此时input_position = 4306,以这两个位置为基准,开始向两侧尝试拓展匹配字符串,因为我们在进行滑动匹配窗口算法时滑动的距离large_step不为1,所以无法保证字符串匹配位置的左侧(滑动匹配窗口略过的部分)不存在匹配字符,因此我们也需要向左侧尝试拓展匹配。
向左侧尝试拓展之后发现,存在匹配的字符串"Wo",将其拓展至匹配字符串中,此时匹配的字符串为"WoDJ_Macros"。接着向右尝试拓展,发现存在匹配的字符串"!!!",将其拓展至匹配字符串中,最终完整的匹配字符串就为"WoDJ_Macros!!!"。
最后将匹配的字符串编码成COPY指令,并更新input_position的位置即可。
拓展匹配字符串的函数源码解析:
/* 拓展匹配字符串,当前源文件匹配位置stream->match_srcpos对应目标文件匹配位置stream->input_position,
* 从匹配位置开始尝试向后(左)和向前(右)拓展,找到最长的关于目标文件的匹配字符串,并生成一条COPY指令 */
static int xd3_source_extend_match(xd3_stream *stream)
{
int ret;
xd3_source *const src = stream->src; //源文件的结构指针
xoff_t matchoff; //用于索引当前源文件中匹配的字符位置(是一个相对于源文件基址srcbass的偏移地址)
usize_t streamoff; //用于索引当前目标文件中匹配的字符位置(是一个相对于目标文件基址taroff的偏移地址)
xoff_t tryblk; //当前尝试匹配位置在源文件中对应的源窗口块号
usize_t tryoff; //当前尝试匹配位置在源文件中对应的源窗口内的偏移位置
usize_t tryrem; //当前可尝试匹配的字节数
usize_t matched; //向前拓展匹配的字符数
//先尝试向后(左)拓展匹配字符串
if (stream->match_state == MATCH_BACKWARD)
{
//更新源文件和目标文件中的匹配位置(此时指向的位置是匹配字符串的头部)
matchoff = stream->match_srcpos - stream->match_back;
streamoff = stream->input_position - stream->match_back;
//获取当前源文件匹配位置matchoff所在的源窗口块号tryblk和块内偏移位置tryoff
xd3_blksize_div(matchoff, src, &tryblk, &tryoff);
//在限制范围内尝试向后拓展匹配字符串
while (stream->match_back < stream->match_maxback)
{
//如果匹配位置达到源窗口的起始位置,则跨窗口继续匹配
if (tryoff == 0)
{
tryoff = src->blksize;
tryblk -= 1;
}
if ((ret = xd3_getblk(stream, tryblk)))
{
//如果当前源块tryblk的位置太靠后,若向后无匹配字符,就结束拓展尝试,因为这种情况下我们断言向前也不会有匹配字符;否则改为向前尝试拓展匹配
if (ret == XD3_TOOFARBACK)
{
if (stream->match_back == 0)
{
goto donefwd;
}
goto doneback;
}
return ret;
}
//更新当前可尝试匹配的字节数(二者取较小值)
tryrem = xd3_min(tryoff, stream->match_maxback - stream->match_back);
//开始向后迭代比较源文件和目标文件向后拓展的字符是否匹配
for (; tryrem != 0; tryrem -= 1, stream->match_back += 1)
{
if (src->curblk[tryoff - 1] != stream->next_in[streamoff - 1])
{
goto doneback;
}
//若字符匹配则同时更新源文件和目标文件的匹配字符位置
tryoff -= 1;
streamoff -= 1;
}
}
//向后拓展匹配完成,开始尝试向前拓展匹配
doneback:
stream->match_state = MATCH_FORWARD;
}
//更新源文件和目标文件中的匹配位置(此时指向的位置是匹配字符串的尾部)
matchoff = stream->match_srcpos + stream->match_fwd;
streamoff = stream->input_position + stream->match_fwd;
xd3_blksize_div(matchoff, src, &tryblk, &tryoff);
while (stream->match_fwd < stream->match_maxfwd)
{
//如果匹配位置达到源窗口的结束位置,则跨窗口继续匹配
if (tryoff == src->blksize)
{
tryoff = 0;
tryblk += 1;
}
//这里如果在获取源块时返回XD3_TOOFARBACK,就直接结束拓展尝试
if ((ret = xd3_getblk(stream, tryblk)))
{
if (ret == XD3_TOOFARBACK)
{
goto donefwd;
}
return ret;
}
tryrem = xd3_min(stream->match_maxfwd - stream->match_fwd, src->onblk - tryoff);
//这种情况表示我们已经检索到了源文件的末尾
if (tryrem == 0)
{
break;
}
/* xd3_forward_match函数用于比较数组(src->curblk + tryoff)和数组(stream->next_in + streamoff)的前tryrem个字符,返回相等字符的数量
* src->curblk是当前源窗口的起始位置,在调用函数xd3_getblk时被设置 */
matched = xd3_forward_match(src->curblk + tryoff, stream->next_in + streamoff, tryrem);
tryoff += matched;
streamoff += matched;
stream->match_fwd += matched;
//如果匹配的字符数等于tryrem,表示当前源窗口可匹配部分的字符完全匹配,尝试匹配下一源窗口的字符;否则结束向前拓展匹配。
if (tryrem != matched)
{
break;
}
}
//向前拓展匹配完成,匹配状态stream->match_state改为搜索匹配MATCH_SEARCHING
donefwd:
stream->match_state = MATCH_SEARCHING;
//为了减少冗余,不保留过短的匹配字符串
if (stream->match_fwd < stream->min_match)
{
stream->match_fwd = 0;
}
else
{
usize_t total = stream->match_fwd + stream->match_back; //匹配的数据的总长度
//将拓展后的字符串整合为完整字符串,修正相关的变量
usize_t target_position = stream->input_position - stream->match_back; //目标窗口中匹配的数据起始位置
usize_t match_length = stream->match_back + stream->match_fwd; //源窗口中匹配的数据的长度
xoff_t match_position = stream->match_srcpos - stream->match_back; //源窗口中匹配的数据的起始位置
xoff_t match_end = stream->match_srcpos + stream->match_fwd; //源窗口中匹配的数据的结束位置
//当指令缓冲区iopt_used中存在其指令数据被向后拓展匹配的字符串完全覆盖的指令时,需要将该指令从指令缓冲区中移除
if (stream->match_back > 0)
{
//函数xd3_iopt_erase的作用是删除指令缓冲区stream->iopt_used中所有指令的数据起始位置晚于target_position的指令
xd3_iopt_erase(stream, target_position, total);
}
stream->match_back = 0;
//更新范围
if (stream->match_maxaddr == 0 || match_position < stream->match_minaddr)
{
stream->match_minaddr = match_position;
}
if (match_end > stream->match_maxaddr)
{
stream->match_maxaddr = match_end;
}
if (match_end > stream->maxsrcaddr)
{
stream->maxsrcaddr = match_end;
}
/* 生成COPY指令。函数xd3_found_match的作用是生成一条COPY指令,其中参数target_position表示该指令所在的输入位置,
* match_length就是COPY指令中的size,match_position就是COPY指令中的addr,数字1表示该拷贝字符串来自源文件*/
if ((ret = xd3_found_match(stream,
target_position, /* decoder position */
match_length, /* length */
match_position, /* address */
1 /* is_source */)))
{
return ret;
}
//如果最终的匹配字符串的结尾刚好到达目标窗口的结尾时,设置继续匹配一下个目标窗口
if (target_position + match_length == stream->avail_in)
{
stream->match_state = MATCH_TARGET;
stream->match_srcpos = match_end;
}
}
return 0;
}
小匹配
这个字符串匹配方式是发生在目标文件中的,准确地来说应该是发生在目标文件已编码的数据部分。
由于该匹配位于正在编码的目标文件中,因此是动态匹配的,那么就无法按照大匹配方式那样通过一段字符串来匹配,只能按单个字符进行匹配。
小匹配哈希表
在小匹配中同样存在一张用于存放位置信息的哈希表,在编码目标文件的过程中,每编码一个字符,就会将该字符的校验和通过哈希函数生成一个哈希值,而这个哈希值就作为在小匹配哈希表中保存该字符位置信息的索引值。
不同于大匹配哈希表的是,同样的字符其校验和相同,那么计算得到的哈希值也是相同的,这样就会造成哈希冲突,Xdelta3中使用双哈希法来解决哈希冲突的问题。因为我们希望优先尝试离当前编码位置最近的匹配字符,所以当发生哈希冲突时,直接哈希索引的位置总是用来保存最新的字符位置信息,而原先的位置信息则保存在另一张哈希表中。
更新小匹配哈希表的函数源码解析:
//参数:inx为该字符的哈希值,也是小匹配哈希表的索引值;scksum为该字符的校验和;pos为该字符的当前位置
static void xd3_scksum_insert(xd3_stream *stream, usize_t inx, usize_t scksum, usize_t pos)
{
//stream->small_prev也是一张哈希表,用于保存小匹配哈希表中发生哈希冲突的地址
if (stream->small_prev)
{
usize_t last_pos = stream->small_table[inx]; //先取出该位置上的原地址信息
//用新地址的掩码作为哈希表stream->small_prev的索引值,新建一个结点
xd3_slist *pos_list = &stream->small_prev[pos & stream->sprevmask];
pos_list->last_pos = last_pos; //将原地址信息保存在这个新结点中
}
//将带偏移量的新地址存入小匹配哈希表中
stream->small_table[inx] = pos + HASH_CKOFFSET;
}
小匹配流程
Xdelta3是按字节编码的,因此在开始字符串匹配流程之前,每编码一个字符,就会判断该字符是否存在于小匹配哈希表中,若不存在则将其插入小匹配哈希表中;若存在则从小匹配哈希表中对应的索引位置取出地址信息,此地址信息为该字符上一次出现在目标窗口中的位置,我们称其为匹配位置。
接着从匹配位置开始,以目标窗口的输入位置为基准,开始向前(右)迭代比较字符,尝试拓展匹配字符串,直到比较的字符不相同或达到目标窗口的边界为止。最后要更新小匹配哈希表中该字符的位置,并将得到的匹配字符串编码成一条COPY指令。
如果该字符出现过多次,那么通过地址哈希索引可以取得该字符更早以前出现的地址信息,同样根据这些地址信息尝试拓展匹配字符串,最终保留其中最长的匹配字符串。
这部分应该比较好理解,就不画演示图了,直接上源码解析吧:
小匹配拓展字符串函数源码解析:
//参数:base为匹配字符的地址,match_offset为匹配字符串的起始地址;该函数返回匹配的字符串长度
static usize_t xd3_smatch(xd3_stream *stream, usize_t base, usize_t scksum, usize_t *match_offset)
{
usize_t cmp_len; //用于暂存匹配的字符串长度
usize_t match_length = 0; //匹配的字符串长度
usize_t chain = (stream->min_match == MIN_MATCH ? stream->smatcher.small_chain : stream->smatcher.small_lchain); //可追溯字符曾经出现过的地址信息的次数
const uint8_t *inp_max = stream->next_in + stream->avail_in; //目标窗口的结束位置
const uint8_t *inp; //目标窗口的输入位置
const uint8_t *ref; //目标窗口的匹配位置
base -= HASH_CKOFFSET; //从小匹配哈希表中取出的地址信息是带有偏移量的
again:
ref = stream->next_in + base;
inp = stream->next_in + stream->input_position;
//向前拓展寻找可能匹配的字符
while (inp < inp_max && *inp == *ref)
{
++inp;
++ref;
}
cmp_len = (usize_t)(inp - (stream->next_in + stream->input_position)); //计算匹配的字符长度
//更新为最长匹配的字符串
if (cmp_len > match_length)
{
(match_length) = cmp_len;
(*match_offset) = base;
//如果匹配完整个目标窗口或有设置long_enough参数时,结束字符串匹配
if (inp == inp_max || cmp_len >= stream->smatcher.long_enough)
{
goto done;
}
}
//如果该匹配字符曾经出现过,追溯更早之前出现的位置,尝试能否获取更长的匹配
while (--chain != 0)
{
usize_t prev_pos = stream->small_prev[base & stream->sprevmask].last_pos; //字符上一次出现的地址信息
usize_t diff_pos; //该匹配字符的位置与目标窗口当前输入位置的距离
if (prev_pos == 0)
{
break;
}
prev_pos -= HASH_CKOFFSET;
//prev_pos的位置不可能大于base
if (prev_pos > base)
{
break;
}
base = prev_pos;
diff_pos = stream->input_position - base;
//如果该匹配字符位置距离输入位置太远,将放弃尝试
if (diff_pos & ~stream->sprevmask)
{
break;
}
//重复上面的匹配步骤
goto again;
}
//匹配完成后,考虑到编码的成本和效率,综合匹配的字符串长度和匹配位置与输入位置的距离,判断是否保留此次匹配的字符串
done:
if (match_length == 4 && stream->input_position - (*match_offset) >= 1 << 14)
{
return 0;
}
if (match_length == 5 && stream->input_position - (*match_offset) >= 1 << 21)
{
return 0;
}
return match_length;
}
字符串匹配完整流程
好了,三种字符串匹配方式我们都已经讲解完了,最后就是将这三种方式封装在一起,共同实现低成本高效率的字符串匹配。
参数配置
上面我们简单展示过五种字符串匹配的参数配置中的large_look和large_step参数,在讲解完整的字符串匹配流程前,先展示完整的五种字符串匹配参数配置(该配置位于文件xdelta3-cfgs.h中):
| large_look | large_step | small_look | small_chain | small_lchain | max_lazy | long_enough | |
|---|---|---|---|---|---|---|---|
| DEFAULT | 9 | 3 | 4 | 8 | 2 | 36 | 70 |
| SLOW | 9 | 2 | 4 | 44 | 13 | 90 | 70 |
| FAST | 9 | 8 | 4 | 4 | 1 | 18 | 35 |
| FASTER | 9 | 15 | 4 | 1 | 1 | 18 | 18 |
| FASTEST | 9 | 26 | 4 | 1 | 1 | 6 | 6 |
源码解析
static int XD3_TEMPLATE(xd3_string_match_)(xd3_stream *stream)
{
const int DO_SMALL = !(stream->flags & XD3_NOCOMPRESS); //如果没有禁用数据压缩功能则启用小匹配模式
const int DO_LARGE = (stream->src != NULL); //如果存在源文件则启用大匹配模式
const int DO_RUN = (1); //默认开启RUN指令匹配
const uint8_t *inp; //指向目标窗口当前的输入位置
uint32_t scksum = 0; //单个字符的校验和
uint32_t scksum_state = 0; //单个字符的32位表示
uint32_t lcksum = 0; //长度为LLOOK的字符串校验和
usize_t sinx; //小匹配哈希表的哈希索引值
usize_t linx; //大匹配哈希表的哈希索引值
uint8_t run_c; //RUN指令操作的字符
usize_t run_l; //字符run_c重复的次数
usize_t match_length; //匹配数据的长度
usize_t match_offset = 0; //将要被编码成COPY指令的匹配数据的起始偏移地址
usize_t next_move_point; //源文件校验和的计算位置
int ret; //返回值
//如果由于设置导致不进行任何一种的字符串匹配,或目标窗口中未编码数据少于最小匹配长度SLOOK(small_look),则直接返回
if (!(DO_SMALL || DO_LARGE || DO_RUN) || stream->input_position + SLOOK > stream->avail_in)
{
goto loopnomore;
}
//为需要使用到的哈希表分配内存空间
if ((ret = xd3_string_match_init(stream)))
{
return ret;
}
//重新回到这个标签时,表示前面匹配的数据已经生成了一条确定的增量指令,并已经更新stream->input_position的位置
restartloop:
//每次都检查目标窗口的未编码数据是否满足最小匹配长度
if (stream->input_position + SLOOK > stream->avail_in)
{
goto loopnomore;
}
//更新最小匹配长度。函数xd3_iopt_last_matched的作用是返回目标窗口中最后一次匹配的字符位置
if (xd3_iopt_last_matched(stream) > stream->input_position)
{
stream->min_match = xd3_max(MIN_MATCH, 1 + xd3_iopt_last_matched(stream) - stream->input_position);
}
else
{
stream->min_match = MIN_MATCH;
}
//更新inp位置
inp = stream->next_in + stream->input_position;
//计算当前尝试匹配字符的校验和,即小匹配校验和
if (DO_SMALL)
{
scksum = xd3_scksum(&scksum_state, inp, SLOOK);
}
//run_c = inp[SLOOK - 1];函数xd3_comprun的作用是返回数组inp前SLOOK个元素中,字符run_c连续出现的次数
if (DO_RUN)
{
run_l = xd3_comprun(inp, SLOOK, &run_c);
}
//计算从当前尝试匹配字符开始长度为LLOOK的字符串校验和,即大匹配校验和
if (DO_LARGE && (stream->input_position + LLOOK <= stream->avail_in))
{
if ((ret = xd3_srcwin_move_point(stream, &next_move_point)))
{
return ret;
}
lcksum = xd3_lcksum(inp, LLOOK);
}
//这个宏用于判断是否要进行惰性匹配
#define TRYLAZYLEN(LEN, POS, MAX) ((MAXLAZY) > 0 && (LEN) < (MAXLAZY) && (POS) + (LEN) <= (MAX)-2)
/* 每次生成一条指令时都会调用该宏,如果匹配的长度足够大,则更新目标窗口的输入位置并重新开始匹配循环
* 否则更新最小匹配长度min_match 以及三种匹配方式所需的变量后,循环迭代一次 */
#define HANDLELAZY(mlen) \
if (TRYLAZYLEN((mlen), (stream->input_position), (stream->avail_in))) \
{ \
stream->min_match = (mlen) + LEAST_MATCH_INCR; \
goto updateone; \
} \
else \
{ \
stream->input_position += (mlen); \
goto restartloop; \
}
//匹配循环入口,每次迭代一个字符,直到找到匹配字符
for (;; inp += 1, stream->input_position += 1)
{
//按照开销顺序,先尝试RUN指令匹配
if (DO_RUN && run_l == SLOOK)
{
usize_t max_len = stream->avail_in - stream->input_position;
while (run_l < max_len && inp[run_l] == run_c)
{
run_l += 1;
}
if (run_l >= stream->min_match && run_l >= MIN_RUN)
{
//函数xd3_emit_run的作用是生成一条RUN指令到指令缓冲区中,参数stream->input_position是指令的编码位置,run_l和run_c分别是指令的size和data
if ((ret = xd3_emit_run(stream, stream->input_position, run_l, &run_c)))
{
return ret;
}
/* 记录stream->min_match = run_l + LEAST_MATCH_INCR(0),然后跳转到updateone标签;
* 虽然生成了RUN指令,但并不会马上更新input_position,会继续寻找适合COPY指令的匹配字符串,
* 但其匹配的长度必须超过min_match,否则没有意义,每次inp往前迭代1个字节时min_match都会相应的减1 */
HANDLELAZY(run_l);
}
}
//接着尝试大匹配
if (DO_LARGE && (stream->input_position + LLOOK <= stream->avail_in))
{
//在开始匹配之前,先更新源校验和的位置
if ((stream->input_position >= next_move_point) && (ret = xd3_srcwin_move_point(stream, &next_move_point)))
{
return ret;
}
linx = xd3_checksum_hash(&stream->large_hash, lcksum); //计算校验和lcksum的哈希值
if (stream->large_table[linx] != 0)
{
//函数xd3_source_cksum_offset的作用是调整地址信息的位数
xoff_t adj_offset = xd3_source_cksum_offset(stream, stream->large_table[linx] - HASH_CKOFFSET);
//函数xd3_source_match_setup设置了拓展匹配字符串所能拓展的最大距离(向前和向后)
if (xd3_source_match_setup(stream, adj_offset) == 0)
{
if ((ret = xd3_source_extend_match(stream)))
{
return ret;
}
//更新input_position的位置,如果没有匹配,match_fwd为零
if (stream->match_fwd > 0)
{
HANDLELAZY(stream->match_fwd);
}
}
}
}
//最后尝试小匹配
if (DO_SMALL)
{
sinx = xd3_checksum_hash(&stream->small_hash, scksum); //计算校验和scksum的哈希值
if (stream->small_table[sinx] != 0)
{
match_length = xd3_smatch(stream, stream->small_table[sinx], scksum, &match_offset);
}
else
{
match_length = 0;
}
//将该字符的最新地址信息更新到小匹配哈希表中
xd3_scksum_insert(stream, sinx, scksum, stream->input_position);
if (match_length >= stream->min_match)
{
//生成一条COPY指令到指令缓冲区中
if ((ret = xd3_found_match(stream,
stream->input_position,/* decoder position */
match_length, /* length */
(xoff_t)match_offset, /* address */
0 /* is_source */ )))
{
return ret;
}
//生成一条COPY指令后更新stream->input_position += match_length;并回到restartloop标签
HANDLELAZY(match_length);
}
}
//每次迭代前先更新min_match
if (stream->min_match > MIN_MATCH)
{
stream->min_match -= 1;
}
//此标签在向前推进一个字符之前,先进行一些必要的检查和更新
updateone:
if (stream->input_position + SLOOK == stream->avail_in)
{
goto loopnomore;
}
if (DO_RUN)
{
//更新run_c和run_l的状态
NEXTRUN(inp[SLOOK]);
}
if (DO_SMALL)
{
//更新校验和scksum
scksum = xd3_small_cksum_update(&scksum_state, inp, SLOOK);
}
if (DO_LARGE && (stream->input_position + LLOOK < stream->avail_in))
{
//更新校验和lcksum
lcksum = xd3_large_cksum_update(lcksum, inp, LLOOK);
}
}
loopnomore:
return 0;
}
至此,有关Xdelta3字符串匹配的全部内容都解析完毕,如果有不理解的建议结合源码解析多看几遍。
本章小结
本章对Xdelta3的三种字符串匹配方式:RUN指令匹配、大匹配、小匹配分别进行了详细的讲解,同时也对其中的核心代码实现进行了解析,最后完整的梳理了一遍字符串匹配的实现流程。
关于Xdelta3的大部分核心内容基本都讲解完了,最近工作比较忙,后续如果有时间会考虑再出两篇关于编码和解码的完整流程解析,帮助大家梳理流程,更好的理解Xdelta3的工作原理。
最后如果觉得写的还不错,记得点赞收藏哦,这是我更新的最大动力~
本章内容有任何疑问也欢迎留言私信我~


















 7808
7808






 到【灌水乐园】发言
到【灌水乐园】发言







