




 本文深入探讨Xdelta3增量压缩工具的地址编码,包括VCD_SELF、VCD_HERE、NEAR缓存和SAME缓存四种类型。通过概念介绍、实例演示及源码解析,阐述如何根据数据地址和指令进行高效编码和解码操作,以减少内存开销并优化压缩效果。
本文深入探讨Xdelta3增量压缩工具的地址编码,包括VCD_SELF、VCD_HERE、NEAR缓存和SAME缓存四种类型。通过概念介绍、实例演示及源码解析,阐述如何根据数据地址和指令进行高效编码和解码操作,以减少内存开销并优化压缩效果。
前言
通过系列的前面几篇文章,我们对Xdelta3的使用、增量指令以及增量文件都有了详细的了解,从本章开始,我们将通过结合源码来深入讲解整个增量压缩的编码和解码过程。
文章中贴源码的部分,我大多数情况下会以注释的形式进行解释,以便更准确地定位代码位置。
概念介绍
在之前讲解增量文件Window部分的时候,我们说COPY指令的数据地址被单独存放在addr数组中。
然而,为了最大程度上压缩增量文件的大小,ADDR数组中的元素大多数情况下都不是数据的实际地址。因为Base-128编码方式的特点,在编码数据地址的时候,我们期望能用少量的字节数(编码后)来表示一个地址,甚至于仅使用一个字节的低7位来表示,以避免额外的内存开销,这就需要用到我们今天要介绍的地址编码技术。
不知道大家还记不记得在讲解增量指令的那篇文章中,我们介绍过在指令代码表中每条指令都是通过一个三元组(inst,size,mode)来表示。
而这三元组中的mode就是地址编码的类型,因此该值也只有在COPY指令中才有意义。
地址编码总共分为4类,每一类对应的mode值也不同,在开始讲解之前,我们先定义几个名词:
data:当前COPY指令要拷贝的数据addr:拷贝数据data的起始地址here:当前COPY指令的位置(即目标窗口的当前输入位置)en_addr:addr通过地址编码后实际存入ADDR数组中的值
-
VCD_SELF(mode = 0)
当addr的值小于128,或不满足其他地址缓存类型的情况下,使用该类型,ADDR数组中存放的是addr本身的数值(en_addr = addr)。 -
VCD_HERE(mode = 1)
使用here作为参照地址,计算相对于addr的偏移值(here-addr)。当偏移值小于128,或偏移值小于addr且不满足NEAR和SAME缓存的情况下,使用该类型。ADDR数组中存放的是偏移值(en_addr = here - addr)。 -
NEAR缓存(mode = [2, 5])
NEAR缓存使用前s_near条COPY指令的地址addr作为参照地址,计算当前指令的addr相对于NEAR缓存中的addr的偏移值(addr-near_addr)。当偏移值小于128,或偏移值小于前两种地址编码后的结果且不满足SAME缓存的情况下,使用该类型,ADDR数组中存放的是偏移值(en_addr = addr - near_addr)。
s_near是一个预设的整数值,用来表示NEAR缓存的数量。在VCDIFF的默认指令代码表中s_near的值为4,因此mode的取值范围在2~5之间,用户也可以通过自定义代码表来修改这个值。

-
SAME缓存(mode = [6, 8])
每次编码一条COPY指令时,其地址addr都将被保存至SAME缓存中,每次新编码一个地址时,都会检索SAME缓存,若其中有与之相等的addr值,则该地址被编码为SAME缓存中的索引值,该索引就对应addr值。
SAME缓存总共可以存储s_same*256个不重复的地址,s_same是一个预设的整数值,用来表示SAME缓存区域的数量,在VCDIFF的默认指令代码表中s_same的值为3,因此mode的取值范围在6~8之间,用户也可以通过自定义代码表来修改这个值。每块区域最多可以含有256个地址,因此一块区域内的索引值仅需一个字节长度即可表示。但实际上这s_same块区域的索引值是连续的,也就是说,在存值取值时,SAME缓存所能取到最大索引值为(s_same*256)-1。
SAME缓存采用哈希表的方式存储addr,其哈希函数为:i_same = addr % (s_same * 256),i_same为存放addr的索引值,ADDR数组中存放的是索引值i_same。

实例演示
这么说可能有点抽象,我们照例还是通过例子来进一步理解,假设某个将要编码的目标窗口和其对应的源窗口如下:

如果全部使用COPY指令编码该目标窗口的前33个字节,则将生成以下六条COPY指令(指令格式为COPY(size, addr))。我们将依次解析每条COPY指令的地址编码:
- COPY(4, 4306)
此时here=10000,指令的addr=4306,使用here作为参照地址的偏移值(here-addr)=5694>4306,NEAR和SAME缓存都为空,因此只能选择VCD_SELF类型编码地址(mode=0),en_addr=4306并存入ADDR数组中,同时将addr存入NEAR和SAME缓存,其中SAME缓存的索引值i_same=4306%(3*256)=376。

- COPY(7, 4399)
此时here=10004,指令的addr=4399,使用here作为参照地址的偏移值(here-addr)=5605>4399,NEAR缓存中的最小偏移值(4399-4306)为93,小于128,因此选择NEAR缓存类型编码地址(4306在NEAR缓存中的索引值为0,所以mode=2),en_addr=93并存入ADDR数组中,同时将addr存入NEAR和SAME缓存,其中SAME缓存的索引值i_same=4399%(3*256)=559。

- COPY(3, 9909)
此时here=10011,指令的addr=9909,使用here作为参照地址的偏移值(here-addr)=102<128,因此选择VCD_HERE类型编码地址(mode=1),en_addr=102并存入ADDR数组中,同时将addr存入NEAR和SAME缓存,其中SAME缓存的索引值i_same=9909%(3*256)=693。

- COPY(9, 8888)
此时here=10014,指令的addr=8888,使用here作为参照地址的偏移值(here-addr)=1126<8888,NEAR缓存中的最小偏移值(8888-4399)为4489>1126(NEAR缓存偏移量的计算公式为addr-near_addr),且SAME缓存中没有相同的addr值,因此选择VCD_HERE类型编码地址(mode=1),en_addr=1126并存入ADDR数组中,同时将addr存入NEAR和SAME缓存,其中SAME缓存的索引值i_same=8888%(3*256)=440。
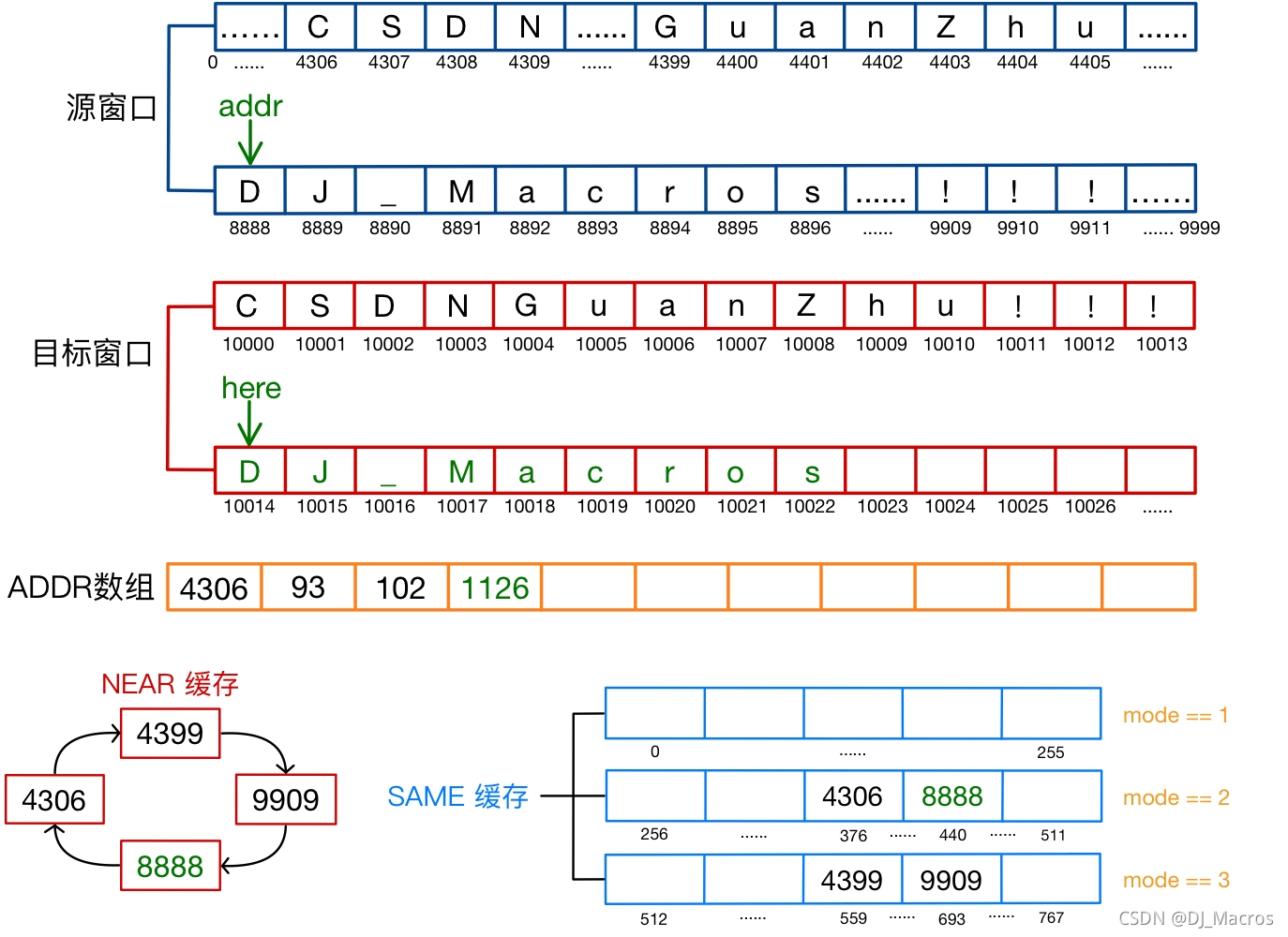
- COPY(6, 8891)
此时here=10023,指令的addr=8891,使用here作为参照地址的偏移值(here-addr)=1132<8891,NEAR缓存中的最小偏移值(8891-8888)为3<128,因此选择NEAR缓存类型编码地址(8888在NEAR缓存中的索引值为3,所以mode=5),en_addr=3并存入ADDR数组中,同时将addr存入NEAR和SAME缓存,其中SAME缓存的索引值i_same=8891%(3*256)=443。
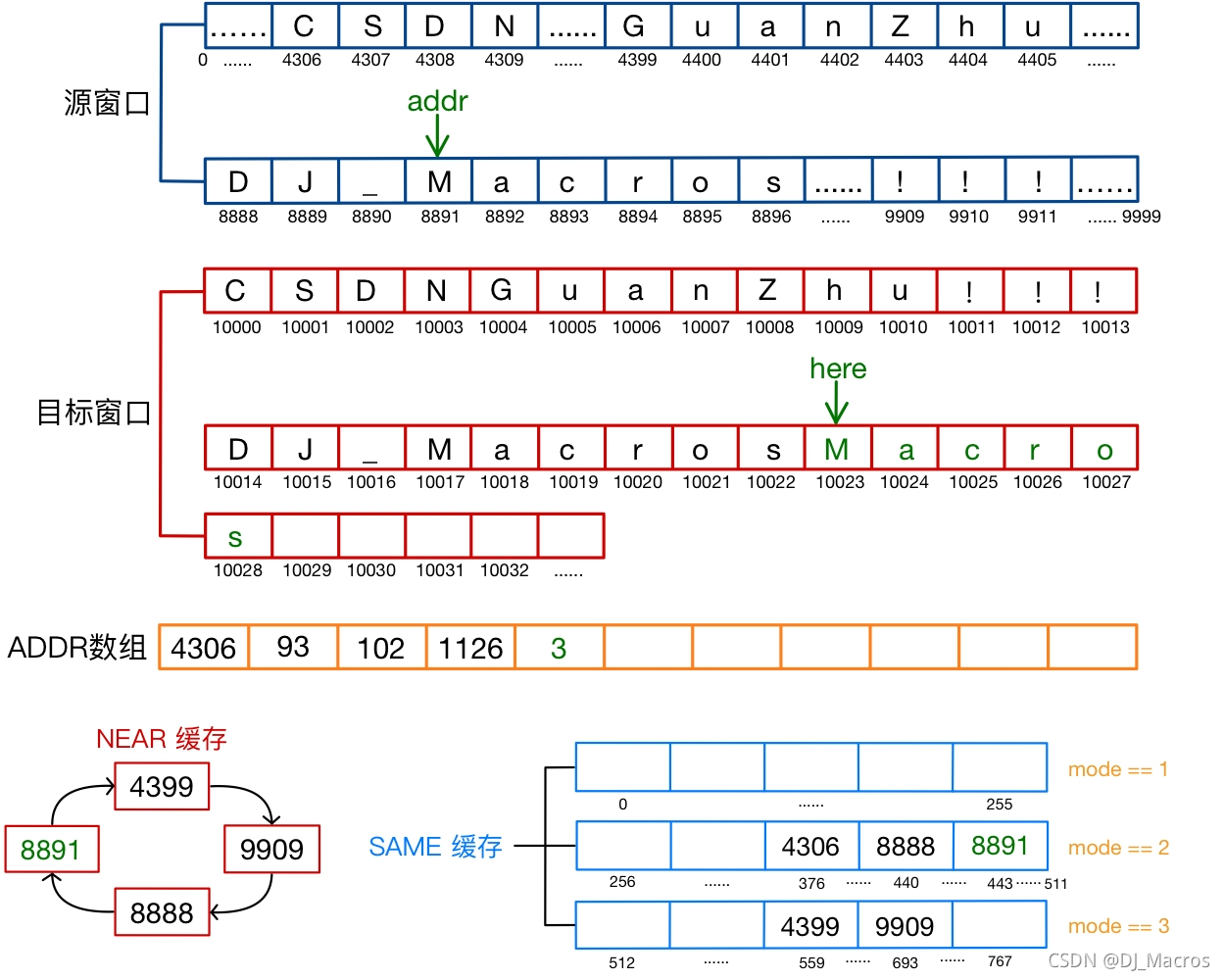
- COPY(4, 4306)
此时here=10029,指令的addr=4306,使用here作为参照地址的偏移值(here-addr)=5723>4306,NEAR缓存中没有小于4306的地址缓存,但通过哈希函数计算出地址4306对应的SAME缓存索引值为376,通过寻址发现SAME缓存中该索引处不为空,经过比较发现就是地址4306,因此选择使用SAME缓存类型编码地址(索引值376在SAME缓存中处于第2块区域,所以mode=7),en_addr=376并存入ADDR数组中,同时将addr存入NEAR缓存。
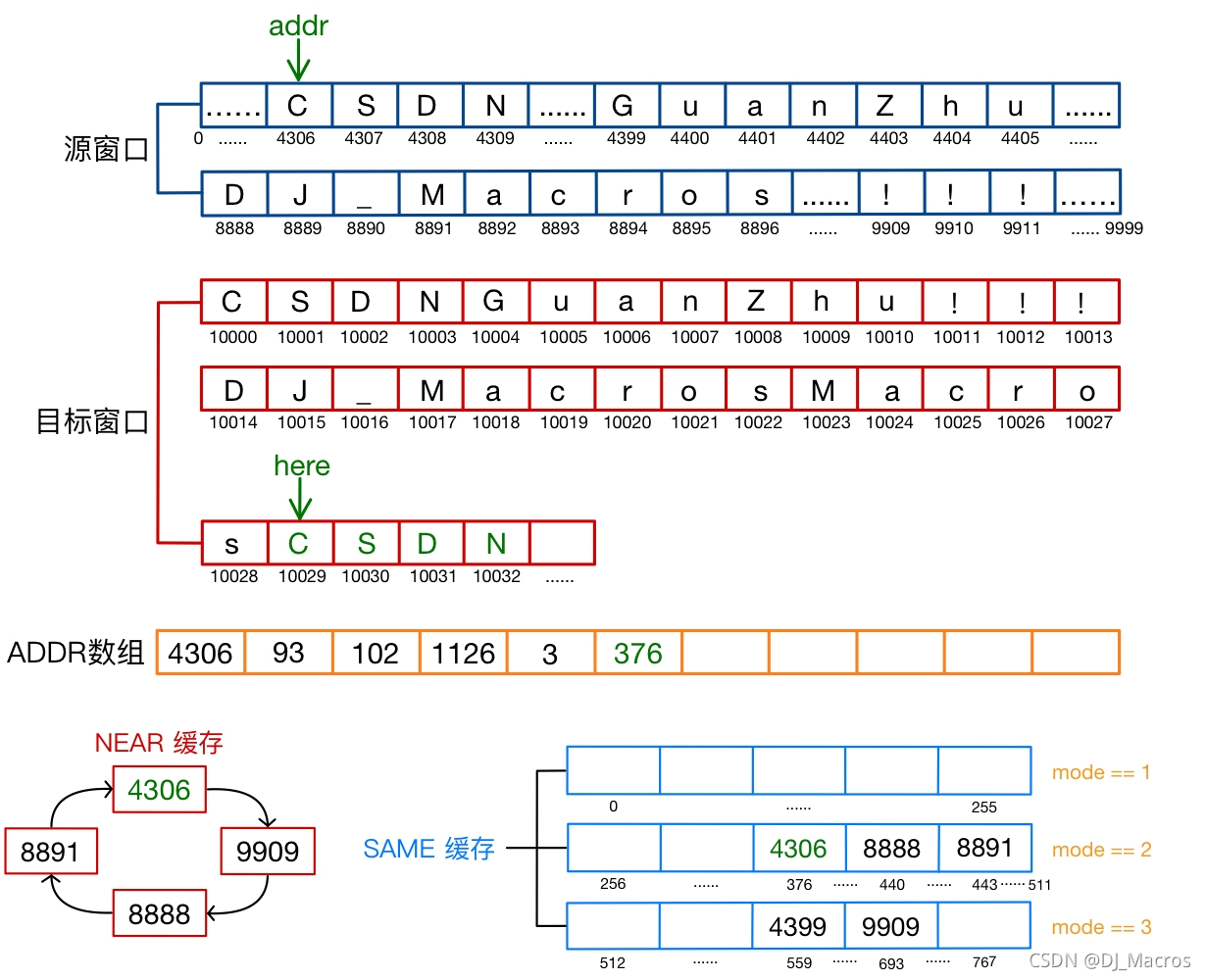
以上就是六条COPY指令的地址编码过程,需要注意的是,每次编码和解码地址的操作之后,都会将addr的值更新到NEAR和SAME缓存中,因此,不论是编码还是解码,同一条COPY指令的NEAR和SAME缓存中的情形是完全相同的。
源码解析
接下来我们将通过源码进一步了解地址的编码和解码操作,这部分的讲解我将大部分嵌入在源码的注释中,注释的颜色可能不太明显,还请认真阅读。
首先不论编码还是解码地址,都需要进行更新NEAR和SAME缓存的操作,因此先介绍这部分的代码。
更新缓存
//地址缓存的结构体
typedef struct _xd3_addr_cache
{
usize_t s_near; //默认为4
usize_t s_same; //默认为3
usize_t next_slot; //NEAR缓存的索引值,由于NEAR缓存是一个循环数组,因此next_slot的值是在[0,s_near-1]中循环取值
usize_t *near_array; //NEAR缓存,用于存储前s_near条COPY指令的地址,为后续COPY指令的地址计算提供参照
/* SAME缓存,将之前的COPY指令地址存入SAME缓存,如果之后的COPY指令地址是之前使用过的,就可以直接通过索引取值;
* 由于地址偏移约定用单个字节表示,因此索引值不能超过255,所以每块区域只能存储256个地址,共能存储(s_same*256)个地址 */
usize_t *same_array;
}xd3_addr_cache;
//缓存更新函数
static void xd3_update_cache(xd3_addr_cache *acache, usize_t addr)
{
if (acache->s_near > 0)
{
acache->near_array[acache->next_slot] = addr; //将addr存入NEAR缓存中
acache->next_slot = (acache->next_slot + 1) % acache->s_near; //更新索引值next_slot
}
if (acache->s_same > 0)
{
acache->same_array[addr % (acache->s_same * 256)] = addr; //将addr存入SAME缓存中对应的索引处
}
}
然后就是地址编码和解码的相关实现,在Xdelta3的源码中,参数stream是主函数的局部变量,用于保存整个处理流程中的所有相关数据。
编码地址
//参数:addr为COPY指令的数据起始地址,here为目标窗口的当前输入位置,mode为该地址的编码类型
static int xd3_encode_address(xd3_stream *stream, usize_t addr, usize_t here, uint8_t *mode)
{
usize_t d, bestd; //变量d是计算每种类型所能达到的最小地址编码值,变量bestd是最终存入ADDR数组中的地址编码值
usize_t i, bestm, ret; //变量i用于记录NEAR缓存的索引值,变量bestm是最终编码的mode值,变量ret是返回值
xd3_addr_cache *acache = &stream->acache; //地址缓存
//宏定义判断,如果x不超过127(能用一个字节的低7位表示)就将x存入ADDR数组,因为已经没有再减小的必要了
#define SMALLEST_INT(x) \
do \
{ \
if (((x) & ~127U) == 0) \
{ \
goto good; \
} \
} while (0)
//刚开始先判断能否直接使用VCD_SELF类型编码
bestd = addr;
bestm = VCD_SELF;
XD3_ASSERT(addr < here);
SMALLEST_INT(bestd);
//判断是否使用VCD_HERE类型编码
if ((d = here - addr) < bestd)
{
bestd = d;
bestm = VCD_HERE;
SMALLEST_INT(bestd);
}
//遍历NEAR缓存,计算使用前4(默认情况下)条COPY指令地址做参照,能否进一步减小地址编码大小
for (i = 0; i < acache->s_near; i += 1)
{
if (addr >= acache->near_array[i])
{
d = addr - acache->near_array[i];
if (d < bestd)
{
bestd = d;
bestm = i + 2; //i是NEAR缓存的索引值,2是VCD_SELF和VCD_HERE两个类型
SMALLEST_INT(bestd);
}
}
}
//如果SAME缓存中存在该地址,则直接使用该地址在SAME缓存中的索引值作为地址编码值
if (acache->s_same > 0 && acache->same_array[d = addr % (acache->s_same * 256)] == addr)
{
bestd = d % 256; //确保bestd可以用一个字节表示,bestd是在SAME缓存当前第(d/256)个区域中的索引值
bestm = acache->s_near + 2 + d / 256; //SAME编码类型在VCD_SELF, VCD_HERE和NEAR编码类型之后,(d/256)为对应的SAME缓存内部的mode值(区域块)
if ((ret = xd3_emit_byte(stream, &ADDR_TAIL(stream), bestd))) //将bestd按单字节存入ADDR数组中,成功返回0
{
return ret;
}
}
else
{
good:
if ((ret = xd3_emit_size(stream, &ADDR_TAIL(stream), bestd))) //将bestd按32位整数分割成字节存入ADDR数组中,成功返回0
{
return ret;
}
}
xd3_update_cache(acache, addr); //每编码一个地址都更新一次地址缓存
(*mode) += bestm; //记录mode值
return 0;
}
解码地址
//参数:here为目标窗口的当前输入位置,mode为地址编码类型(范围0~8),inpp为输入缓冲区(此函数内就为ADDR数组),max为缓冲区inpp中的元素数量,valp用于存放解码后的实际地址
static int xd3_decode_address(xd3_stream *stream, usize_t here, usize_t mode, const uint8_t **inpp, const uint8_t *max, uint32_t *valp)
{
int ret;
usize_t same_start = 2 + stream->acache.s_near; //SAME编码类型的mode值从6开始
//编码类型为VCD_SELF、VCD_HERE和NEAR的地址都被编码成整数
if (mode < same_start)
{
//从ADDR数组中读取一个整数(有可能是单个字节)并存入变量valp中
if ((ret = xd3_read_size(stream, inpp, max, valp)))
{
return ret;
}
switch (mode)
{
//VCD_SELF编码类型,valp就是地址本身
case VCD_SELF:
break;
//VCD_HERE编码类型
case VCD_HERE:
(*valp) = here - (*valp); //由于编码时(valp = here - addr),所以现在还原地址值:valp = here - (here - addr) = addr
break;
//NEAR编码类型
default:
/* 由于编码时(valp = addr - stream->acache.near_array[mode - 2]),所以现在还原地址值:
* valp = (addr - stream->acache.near_array[mode - 2]) + stream->acache.near_array[mode - 2] = addr */
(*valp) += stream->acache.near_array[mode - 2];
break;
}
}
//SAME类型编码的地址被编码成单个字节,此时ADDR数组指针**inpp就指向该字节
else
{
//合法性判断
if (*inpp == max)
{
stream->msg = "address underflow";
return XD3_INVALID_INPUT;
}
mode -= same_start; //计算SAME缓存的内部mode值,即区域块号
(*valp) = stream->acache.same_array[mode * 256 + (**inpp)]; //将单字节的编码值(**inpp)加上偏移量(mode*256)后得到SAME缓存的索引值,通过索引取值
(*inpp) += 1; //读取一个字节
}
xd3_update_cache(&stream->acache, *valp); //每解码一个地址都更新一次地址缓存
return 0;
}
以上就关于COPY指令地址编码和解码的相关代码实现。
本章小结
本章对COPY指令的地址编码和解码操作进行了详细的讲解,并通过解析源码来展示具体实现。
下一章节我们将讲解Xdelta3中的字符串匹配算法,同样会结合源码解析其具体实现。
还是那句话,如果喜欢可以点赞关注再走哦,本章内容有任何疑问也欢迎留言私信我~

















 779
779






 到【灌水乐园】发言
到【灌水乐园】发言







