




 本文介绍了无监督学习中的k-means聚类算法及其特殊情况处理,强调了初始化质心的重要性。接着,讨论了异常检测系统,包括高斯正态分布在异常检测中的应用和异常检测与监督学习的区别。推荐系统部分讲解了协同过滤和基于内容过滤的方法。最后,简述了强化学习的基本概念,如状态动作价值函数和贝尔曼方程,并提到了随机环境和连续状态空间的应用。
本文介绍了无监督学习中的k-means聚类算法及其特殊情况处理,强调了初始化质心的重要性。接着,讨论了异常检测系统,包括高斯正态分布在异常检测中的应用和异常检测与监督学习的区别。推荐系统部分讲解了协同过滤和基于内容过滤的方法。最后,简述了强化学习的基本概念,如状态动作价值函数和贝尔曼方程,并提到了随机环境和连续状态空间的应用。
第三课
无监督学习——聚类:
1.概念:查看数据集,将其分成簇(一组相似的数据子集)
2.k-means聚类算法
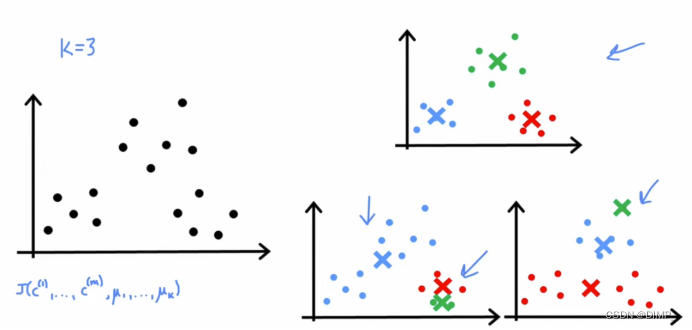
过程:随机初始化簇质心(维度与样本示例相同),通过相似度对比(如果用坐标系表示数据,则对比数据与簇质心的距离),将数据分类。在每一个簇中,取所有数据的平均值作为新的簇质心。重复以上操作,对每个数据分配簇质心,分配结束后移动簇质心,直至簇质心位置不发生变化,此时该算法收敛。

特殊情况处理:若所有数据均未分配给某个簇质心,此时可以消除该簇质心,总簇数减一。或者重新初始化簇质心,让该簇质心能够分配到数据。
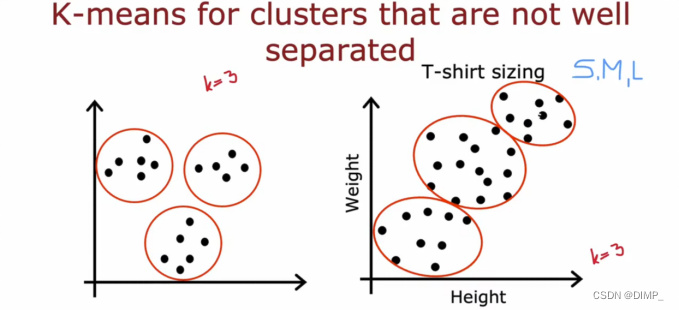
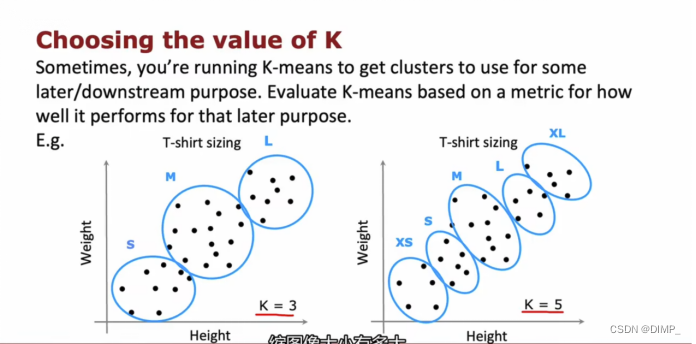
特点:不仅能处理集群良好分布的数据集,也可以处理集群没有很好分离的数据集。
3.代价函数:
下图中的代价函数也被称为失真函数(Distorsion)

4.初始化K-means:
位置:最常见的初始化簇质心位置的方法时选某几个训练样本作为簇质心的位置,多次初始化,选择使代价函数最小的一组簇质心
代价函数可能有多个局部最小值时,到达某个局部最小值时,循环结束,簇质心位置便确定,最后分类的结果大相径庭。所以我们需要多次初始化簇质心,选择使代价函数最小的一组。
数量:
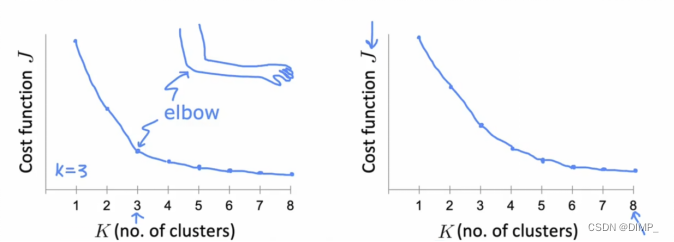
肘部法则:将代价函数视为簇数量的函数,寻找拐点,该拐点对应的簇数量即最佳K值
很多时候代价函数是平滑的,没有拐点,更好的方法是根据实际情况,确定K值的数量
PS:思考为什么不取使代价函数最小对应的K值(重点理解!)
异常检测系统:
1.异常事件:对含特征x1 x2的样本进行建模,每一个蓝色圆圈代表模型的一种情况。当圆圈越小,样本出现在其中的可能性更高,出现在圆圈以外的区域就更低。通过特征x1 x2推测测试样本xtest的P(x),即xtest属于正常情况的概率。当ε很小时,此时我们说该样本异常。
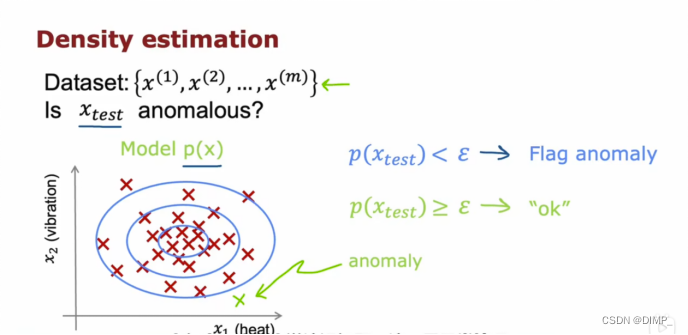
2.高斯正态分布
含义:μ代表数据的平均值 σ为标准差 纵轴表示该数字对应的概率
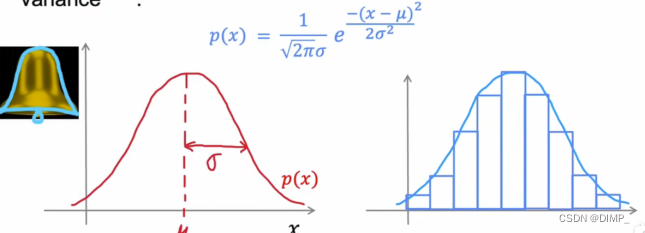
不同的μσ对正态分布图形的影响:
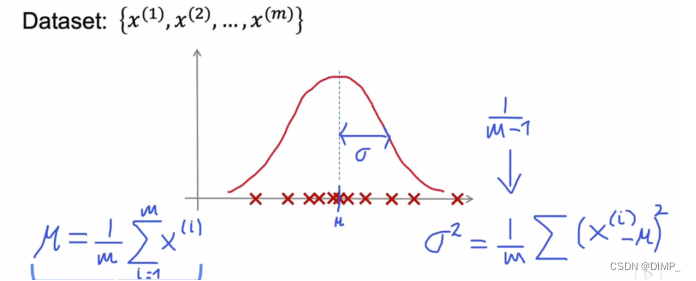
对数据集的数据建立正态分布:
根据数据的平均值和标准差建立正态分布,建立好的分布为训练样本来自的概率分布(重点理解!)
下图只针对有一个特征的数据集,对于有多个特征的数据集,可以用单个高斯值构建复杂的异常检测算法。
3.异常检测算法:
建立有多个特征的数据集的P(x)模型,需要根据单个特征的平均值和方差计算分别计算该特征特征的P(x),所有特征的P(x)相乘所得结果为属于正常情况的概率。

异常检测的过程:

4.开发与评估异常检测系统
开发:通过拟合高斯分布从训练集中学习
评估:
方法一:有训练集 交叉验证集 测试集三部分
方法二:有训练集 测试集两部分,对于没有足够的数据来创建一个与交叉验证集不同的完全独立的测试集很有意义,比如某个数据集有10000个数据,但仅有两个异常数据。该方法很大程度上会过度适应交叉验证集,因此它的未来预测效果会明显差一些。

5.异常检测和监督学习对比
当有少量的正样本和大量的负样本时,如何选择:异常检测试图找到全新的正样本,改正样本可能不同于以前见过的任何样本。监督学习会观察正样本,试图确定未来的样本呢是否与已经看到的正样本相似。
下图是异常检测和监督学习应用的例子

6.异常检测的特征选择
构造新特征,令训练集数据近似高斯,交叉验证集和测试集也要相应变化。
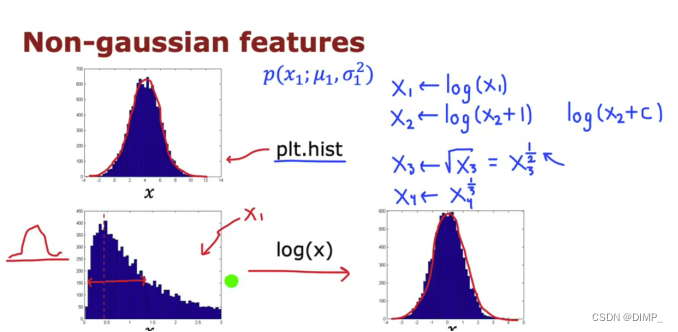
若交叉验证集和测试集中有一个异常样本,该样本的概率较高,算法无法将这个特定的样本标记为异常,我们需要致使异常的原因,构造出新的特征,新特征需要把该异常样本和普通样本分开。

推荐系统
1.阐述
以电影推荐系统为例,系统根据用户已打分电影的评分,对未打分电影进行预测,并在未打分电影选出预测评分较高的电影。
2.推荐算法的代价函数
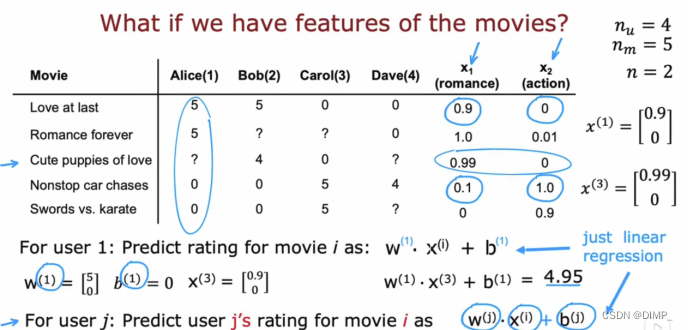
假设电影的评分wj*xi+bj,wj bj是用于预测用户j给电影i评分的参数,xi是电影i的特征向量(重点理解它的合理性!)
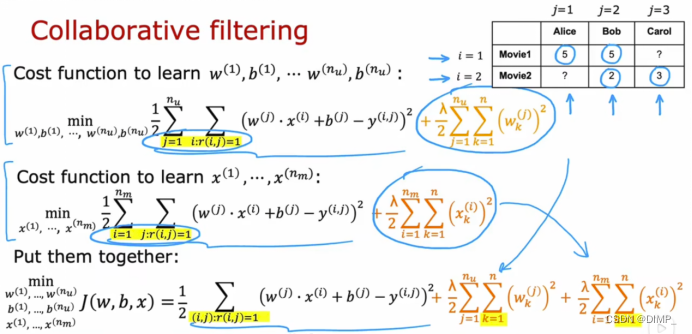
针对用户j的推荐系统的代价函数如下图2
针对所有用户的推荐系统的代价函数如图3(每个用户的wj bj是不同的)


相似特征:给定电影i的特征x(i),查找与电影i相关的电影,可以查看和x(i)相似的x(k)的电影k。就像是我喜欢的一个电影是动作片,那我要根据动作这个特征寻找与之相似的电影。方法如下

3.协同过滤
如果没有特征X,则可以使用协同过滤从数据中学习到这些特征X1,X2...
多个用户对同一部电影进行评分,可以据此猜测这部电影的合适特征。反过来,可以预测用户未评分的电影。(重点理解!!!)
求参过程:假设已用户j的参数wj bj,通过最小化特征向量xi的代价函数,通过梯度下降选择最佳的特征向量。为了学习所有特征,对从i=1的电影数量进行求和。(重点理解!)

将参数wj bj xi的代价函数合并,得到一个三个参数的代价函数。最小化这个代价函数确定推荐系统参数,这个系统是很有效的。

限制:1.不擅长冷启动,比如很少用户对某电影评分(重点思考,是因为无法确定xi?)或者新用户的评分很少,则协同过滤结果可能不准确。
2.不能使用附带信息或有关项目或用户的附带信息(重点理解!!)
5.二元标签的协同过滤:
用户不会给到具体的数字评级,如0-5,仅给出一个感觉,如:不喜欢或者喜欢,这就是二元标签。
系统常分析用户的行为来判断用户喜欢还是不喜欢该商品:比如用户是否点开了广告,是否收藏了它,用户浏览的时间等。1表示用户对物品表示肯定,2为否定,?为未使用/看到过物品。
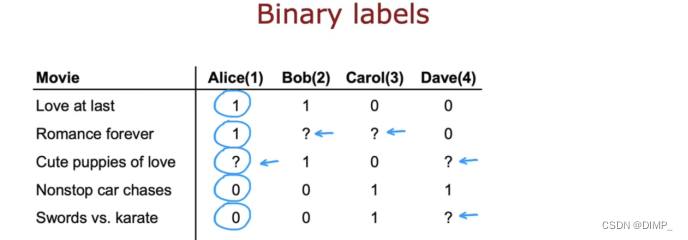
二元标签的推荐系统需要我们给出用户给出1的概率,据此推荐物品。由线性回归推广到使用逻辑回归来解决二进制标签的问题。


6.均值归一化
当用户对物品均没有评分时,使用协同过滤预测该用户对物品的打分,该分数趋近于0,显然这种预测是不合理的(思考!)。均值归一化能够更好预测没有评价过的新用户的打分情况。
均值归一化后新用户的预测评价其实是该物品你的平均评价分数,这样的预测显然是更合理的。


7.基于内容过滤
协同过滤是已知某些用户给某些物品的评分,算法利用这些数据向你推荐物品。(重点理解!)基于内容过滤会根据用户和物品的特征,做好匹配后向你推荐物品。
某用户在某电影中的评分为vuj和vmi的点乘,要求vuj和vmi维度相同。其中vuj:v代表向量,u代表用户,j代表用户j vmi:v代表向量,m代表电影,i代表电影i。

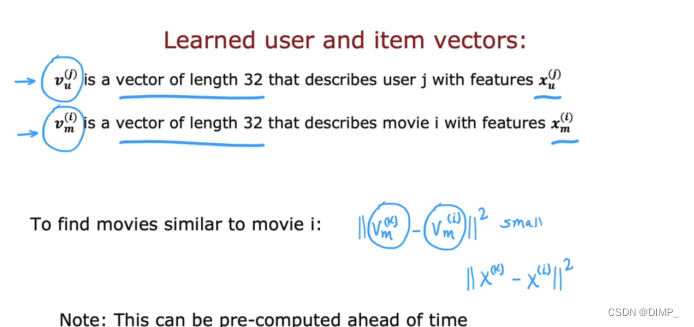
8.利用深度学习求能够展示用户偏好的向量Vu和展示电影特征的向量Vm:
最小化用于训练用户和电影网络的所有参数的代价函数,在代价函数中可以添加正则化项来激励神经网络保持这些参数值很小(??这是什么意思)
也可以寻找相似的物品,原理与协同过滤一样
9.从大型目录中推荐
如果要通过神经网络获取数万的项目,并计算内积来确定推荐的产品,这就必须要求运行数万次的神经网络,系统推荐速度过慢。因此大规模的推荐系统采用数据检索和排名来实现推荐。
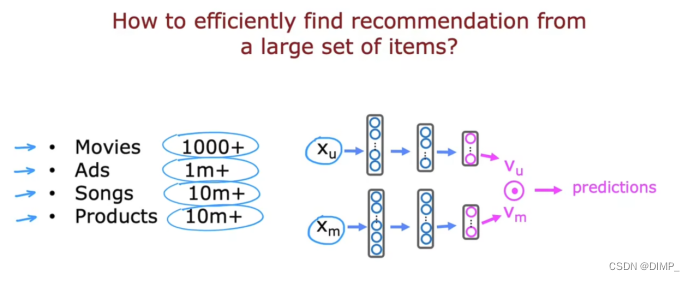
数据检索可以包括通过用户最近观看的10部电影找到与之相似的电影、推荐观看最多3种类型的电影top10、推荐该地区观看次数top20等...这样就可以大幅度减少要获取的项目。然后,据检索后电影的特征向量和用户的特征向量点乘,选择评分高的电影或者P(y(i,j))=1的电影。
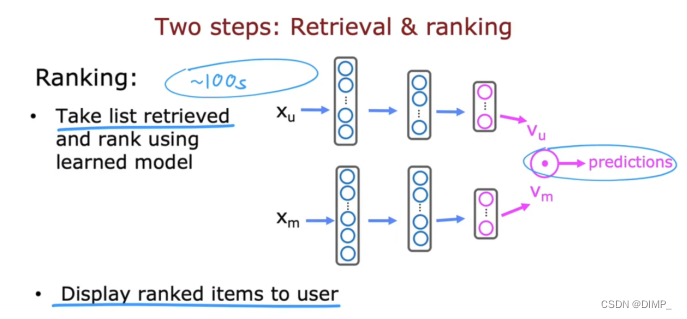
10.推荐系统的弊端
无法过滤流量和讨论度高的不良内容,如:社交媒体的不好言论可能点击量很高,这就形成正反馈,点击量越高,这篇内容就越可能被推荐。

强化学习:
1.强化学习的提出
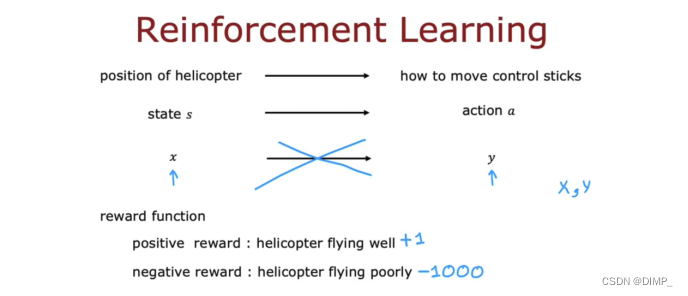
以特技表演的直升飞机为例,我们需要将飞机的状态映射成动作,该动作指的是控制杆移动的距离。用监督学习训练飞机,我们很难确定正确的输出是什么(因为飞机在空中移动时,正确动作是模糊的),即很难得到一个x和理想动作y的数据集。
强化学习的关键输入是奖励(函数),告诉它该做什么,而不是怎样去做。每次采取行动时考虑状态、奖励、下一次的状态、行动四个因素。
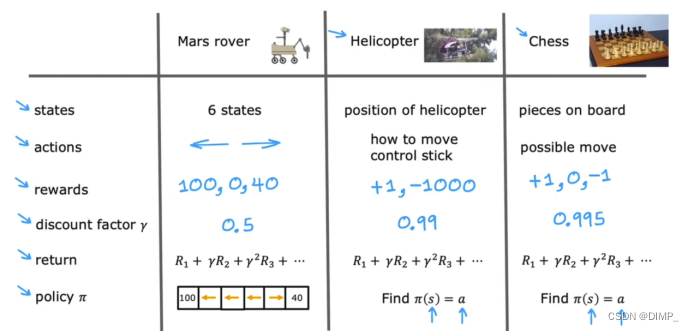
2.应用(重点理解!!)

3.回报
以平常生活经验来说,回报就是与付出的行动相比,哪个更有吸引力,性价比更高。在强化学习中,引入折扣(近似等于1,但小于1),表示离现状态更远的奖励会打折扣。回报是系统获奖励折扣后的总和,通过最大化回报,确定现状态下采取的行动。例子如下。

使用奖励系统的例子如下(重点理解!!):
4.状态动作价值函数
状态动作价值函数是关于可能所处的状态s和做出的行动a的函数,Q(s,a)为对应的回报。我采取当前状态的最佳行动a的最大化回报,这样就可以计算最优策略π(s)

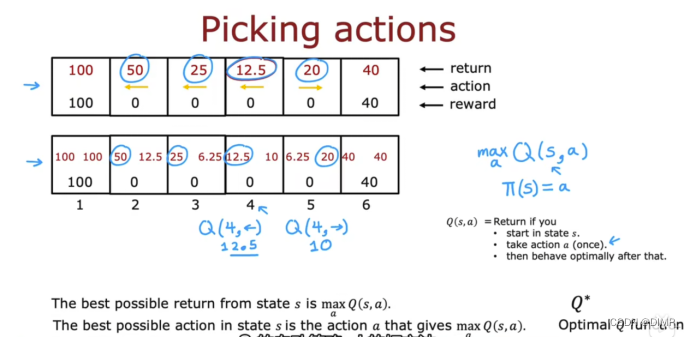
5.贝尔曼方程
贝尔曼方程用来计算状态动作函数,即Q(s,a)=当前状态的奖励+下一状态最大的奖励。

下图为用贝尔曼方程用来计算状态动作函数的例子:(重点理解与原来计算状态动作函数有什么不同!!)

6.随机环境
在随机环境中,机器可能不会完全按照最佳回报选择下一步行动,这里提出最大化折扣奖励总和的平均值来模拟出现随机环境的情况

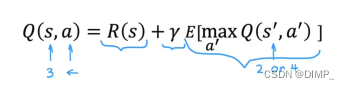
7.连续状态空间
连续状态空间指的是问题状态不仅是少数可能的离散值之一,它是一个数字向量

8.学习状态值函数
通过训练神经网络来计算近似逼近Q(s,a):运行下面算法,从Q(s,a)随即猜测开始,训练模型来提高Q(s,a)的猜测。将Q(s,a)设置为学习完成神经网络并更新的Q_new(s,a)。
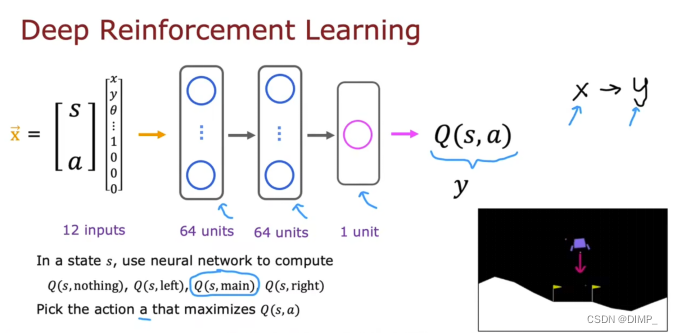

使用贝尔曼方程来创建大量x,y样本对的训练集,x是状态动作对,y是目标值Q(s,a),然后使用监督学习,让x映射到y

9.算法改进:
贪婪算法
当神经网络还在学习中,Q(s,a)可能还没有一个很好的估计,此时有两种选择:一是利用目前对Q(s,a)的猜测,选择使其最大化的动作a,但这个Q(s,a)可能不是一个好的选择。在极少数的情况下,我们会随机选择一个动作,称为探索步骤(重点理解为什么会有这样的选择出现!),探索时间用ξ表示。
一开始可能ξ设置的很高,随后ξ逐渐降低,这样能更好地选择最大化的动作(重点理解!!)

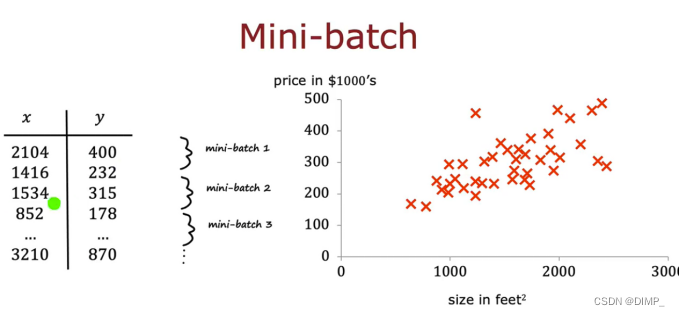
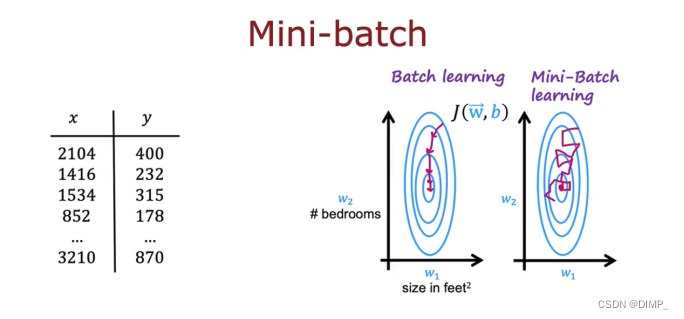
小批量:
当训练集很大时,梯度下降算法变得很慢(思考!),这里提出了Mini-bath梯度下降,即在算法的某迭代种仅会聚集部分的数据集,这样每次迭代运行得都很快。

软更新(重点理解!!):

上述内容仅作框架整理!

















 2271
2271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









