




 本文深入探讨了Java集合框架中的ListIterator,强调其在List遍历和操作上的优势。同时,详细介绍了HashSet、HashMap及底层数据结构,强调了hashCode和equals方法在确保元素唯一性中的关键作用。还提到了TreeSet及其基于二叉树的有序特性。文章最后提出了关于优化元素存储和遍历效率的思考,并提出了几个编程练习,包括设计学生管理系统。
本文深入探讨了Java集合框架中的ListIterator,强调其在List遍历和操作上的优势。同时,详细介绍了HashSet、HashMap及底层数据结构,强调了hashCode和equals方法在确保元素唯一性中的关键作用。还提到了TreeSet及其基于二叉树的有序特性。文章最后提出了关于优化元素存储和遍历效率的思考,并提出了几个编程练习,包括设计学生管理系统。
复习
1.数组作为一种很简单的容器使用,有诸多的缺点,所以针对不同的需求需要有更适合使用的容器,jdk提供了解决方案,集合框架。Collection framework。
2.学习容器就是学习具有不同功能特点的容器类。
3.容器分类:序列、集、映射
4.Collection 是集合部分的顶层的接口:元素无序不唯一,可以有null元素。
5.List 是Collection的子接口:元素有序(添加元素的顺序)不唯一,可以有null。
6.Java.util.ArrayList 底层使用数组实现,是一个带封装的数组的实现类。
7.Java.util.LinkedList 底层使用的数据结构为双向链表。每一个节点包含了数据+前驱节点引用prev+后继节点引用 next。
8.泛型对于容器来说,解决了2个问题:1、避免对容器添加不想加入的元素的类型。2、当想使用元素的具体类型的时候,不需要向下强转。
9.Java.util.Iterator 三个方法。hasNext() 游标后是否有元素,next()让游标后移一个元素的位置,并返回该元素,remove() 删除next()方法最后返回的元素对象。
第一节 ListIterator
迭代器Iterator是集合框架中所专有的遍历方式,也成为集合框架中标准的遍历方式,那么专门针对List这一支容器呢,还有一个迭代器的子类,是专门用于迭代List子类的。
ListIterator 是Iterator 的子接口。是专门用于遍历List 类型容器的迭代器。可以实现从头到尾,和从尾到头的双向的遍历,可以在遍历的过程中,实现对容器中元素的,增删改查的操作。具有不会一次失效的特点。
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
/**
* 学习ListIterator
*/
public class TestListIterator {
public static void main(String[] args) {
List<String> list=new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
//得到list对象的ListIterator对象
ListIterator<String> it=list.listIterator();
while(it.hasNext()){
//it.next(); //让游标往后走一个位置,并返回该元素
//it.previous(); //让游标往回走一个位置,并返回该元素
String next=it.next();
if("c".equals(next)){
//修改刚刚被返回的对象(也就是next所指向的对象)
it.set("C");
}
if("d".equals(next)){
//在刚刚被返回的对象后面添加元素(也就是next所指向的对象)
it.add("D");
}
System.out.println(next);
}
System.out.println();
//上面遍历一次之后,游标到最末尾了,所有再从后往前遍历
while(it.hasPrevious()){
System.out.println(it.previous());
}
System.out.println();
//上面的遍历一遍之后,游标到最前面了,又可以从头到尾又遍历一次
while(it.hasNext()){
System.out.println(it.next());
}
//死循环
/*
while(it.hasPrevious()){
it.previous();//游标往回走一格
it.next(); //游标往后走一格
}
*/
}
}
问题:哪些类型的容器可以使用迭代器遍历?
如果这个类里面提供了得到迭代器的方法,那么就可以使用迭代器遍历,(ArrayList、Vector、LinkedList里面都有一个iterator()方法,这个方法返回的是Iterator的子类对象。所以一个类里面有这个iterator()这个方法,那么一定可以使用迭代器遍历。那么我们就去看哪些类里面包含了这些方法??还有一个问题就是这个iterator()是从哪里来的呀,根儿是什么呀?) 看下源码:
//ArrayList源码
//Overrides mehthod in java.util.AbstractList
//Overrides method in java.uitl.List
public Iterator<E> iterator() {
return new Itr();
}
//List源码
//Overriders method in java.util.Collection
/**
* Returns an iterator over the elements in this list in proper sequence.
*
* @return an iterator over the elements in this list in proper sequence
*/
Iterator<E> iterator(); //这是一个抽象方法,那么List的子类都要实现这个方法
//我们再来看Collection的源码
//Overrides method java.lang.Iterable
/**
* Returns an iterator over the elements in this collection. There are no
* guarantees concerning the order in which the elements are returned
* (unless this collection is an instance of some class that provides a
* guarantee).
*
* @return an <tt>Iterator</tt> over the elements in this collection
*/
Iterator<E> iterator(); //那么Collection的子类都要实现这个方法
//我们再来看Iterable这个接口的源码(这个接口的源码都在这里了):
//在这里我们又认识了一个接口,Iterable(可以被迭代的)
public interface Iterable<T> {
//这个接口里面定义了一个如何得到当前容器对象的迭代器的方法,
//那么所有实现这个方法的子类都要重写它,而且要得到当前容器对象上的迭代器对象。
Iterator<T> iterator();
//
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
//
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
//我们再看一下Iterator这个接口的源码(这个接口的源代码都在这里了)
public interface Iterator<E> {
boolean hasNext();
E next();
//
default void remove() {
throw new UnsupportedOperationException("remove");
}
//
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
因为Collection继承了Iterable接口,实现了iterator()方法,所以Collection和它的子类可以使用迭代器进行遍历。
1.Iterator() 返回的是Iterator 的实现的子类对象。如果一个类中包含了该方法,那么该类容器的对象一定是可以使用迭代器遍历的。
2.Java.lang.Iterable 接口中定义了 iterator() 方法。所有该接口的子类都需要实现该方法,用来得到当前容器对象的迭代器对象。Collection 接口继承了该接口,所以所有的Collection的实现在子类都应该实现该方法。所以 List 和 Set 的子类都可以使用迭代器遍历元素。
3.所有实现了Iterable接口的类的对象都实现了iterator()方法,都可以生成一个迭代器对象,可以使用Iterator迭代器进行遍历。Iterator中的抽象方法,是由它的子类(具体是哪个子类实现这里不讨论)实现的,我们平时用的Iterator it=new set.iterator(); 这里是父类引用指向子类对象,当调用it.next()方法时,就是多态了。
第二节Set
1.HashSet
Set 元素的特点无序、唯一,可以有一个null.
HashSet 元素特点:无序、唯一,可以有一个null。底层使用的数据结构为哈希表。哈希表也称为散列表。
2.哈希表的特点和HashSet 的工作原理

说明:1.对于一个Integer对象来说,它的哈希码的就是它自身。
2.hashCode()方法是Object类当中的一个方法,所以所有的对象都可以调用。
3,。假如让我们自己写一个遍历的算法去遍历一个哈希表的数据结构怎么遍历呀?我们要以一维数组为基础,从头开始遍历,先遍历下标是0的,如果它有链表,那是不是还要把它的链表遍历完了呀!以此类推。。。。。
3.我们说过在哈希表中查找一个元素是很快的,由于它是无序的,所以不能根据下标进行查找,只能根据内容进行查找。
4.查找一个元素的过程,先计算它的哈希码,然后做同样的算法运算,得到位置值。然后去哈希表中找到相应的位置,如果没有链表,直接比较、取数据就行了;如果这里面还有一个链表,那么就从链表的头,用equals进行比较,直到相等的时候取值。
5.HashSet重要在数据结构,用的不多,因为对对象的访问只能通过内容,不能通过索引或者通过其他的信息。
6.如何提高哈希表的工作效率?当然是链表的长度越短效率越高了。如何保证链表越短,当然是元素存的越均匀链表越短,所以我们希望元素可以均匀的散列在这个数组范围内。
7.没有获得某一个元素的方法,只能判断里面有没有这个元素,但是不能获得它,(仅仅能通过遍历来获得),所以用的非常的少。
/**
* 测试HashSet的一些方法
*/
public class TestHashSet {
public static void main(String[] args) {
Set<String> set=new HashSet<>();
set.add("China");
set.add("Japan");
set.add("America");
set.add("Italia");
set.add("China");
//不能直接修改
//可以删除
set.remove("Japan");
//添加(这个添加并不一定刚好添加到刚被删元素的位置)
set.add("China_1");
//可以有一个null元素
set.add(null);
set.add(null);
//没有获得某个元素的方法
System.out.println(set);
//可以判断是不是包含某个元素
System.out.println(set.contains("China"));//返回true
//元素个数
set.size();
//set.clear();
set.isEmpty();
set.toArray();
//遍历两种方式:迭代器和foreach
Iterator<String> it=set.iterator();
while(it.hasNext()){
String s=it.next();
System.out.println(s);
}
for (String s:set) {
System.out.println(s);
}
}
}
3.hashCode和equals方法
Object类的hashCode()方法是一个native 方法,调用的底层的c的方法实现的。实际上,由 Object 类定义的 hashCode 方法会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的) 。
如果希望不同的对象,如果内容相同,也不能添加到HashSet 中的话,那么需要在元素对应的类中重写 hashCode(),以保证相同内容的对象返回相同的哈希码值。还要重写equals方法保证内容相同,equals返回true。
如果希望某种类型的对象添加到HashSet容器中,而且希望根据内容去重,那么就需要在该类中重写hashCode 和 equals 方法。
重写equals 和 hashCode需要遵循的规范:如果两个对象通过equals 比较相等,那么哈希码的值是否必须一致?是的,必须一致。如果equals比较不同,那么哈希码可以相同,但是要尽量不同,才可以保证HashSet的高效率。
重写equals 和 hashCode需要遵循的规范:如果两个对象的哈希码一致,那么equals 方法比较是否必须一致?不是必须的。
| 源码Object类里面的hashCode() public native int hashCode(); |
|---|
说明:1.重写hashCode()方法的目的就是,相同内容的对象,它的哈希码是一致的。重写equals()方法的目的是,相同内容的对象通过equals比较实相等的。
这里面的native,指本地的意思,调用过的本地的方法,也就是调用的底层的用C的代码实现的方法,(java里面有些功能,直接使用java是实现不了的,必须依赖于更底层的语言才能实现)
import java.util.HashSet;
import java.util.Set;
/**
*如果两个对象的内容相等(即属性相等),我们希望两个对象的哈希码是一致的,需要类重写hashCode()和equals()方法
*/
public class TestHashSet1 {
public static void main(String[] args) {
Set set=new HashSet();
set.add(new String("123"));//String类已经重写了hashCode()方法和equals()方法
set.add(new String("abc"));
//如果两个对象的内容相等(即属性相等),我们希望两个对象的哈希码是一致的
Student s1=new Student("小花",19,90);
Student s2=new Student("小花",19,90);
set.add(s1);
set.add(s2);
System.out.println(set);
}
}
class Student{
private String name;
private int age;
private int score;
public Student(String name, int age, int score) {
this.name = name;
this.age = age;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", score=" + score +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
if (score != student.score) return false;
return name.equals(student.name);
}
@Override
public int hashCode() {
int result = name.hashCode();
result = 31 * result + age;
result = 31 * result + score;
return result;
}
}
看一下HashSet的底层源码
//HashSet的底层源码
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map; //可以看到底层有一个HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() { //构造方法,我们new 一个HashSet的时候,HashMap()被初始化了。
map = new HashMap<>();
}
-----------------------------------------------------------------------------------------------------------
//再看一下add方法,也是
public boolean add(E e) {
return map.put(e, PRESENT)==null;//我们向里面添加元素的时候,添进来的元素是作为key加入到HashMap中的,所有的value都是默认的PRESENT
}
综上源码我们可以得出,HashSet的底层是由HashMap来实现的。它只用了HashMap中Entry的key部分,也就是说HashMap的key就是HashSet的元素,每一个Entry的value都是同一个值,为了节省内存。
到put()方法在1.8版本里面如果链表的长度超过了8,将链表里面的元素用二叉树来存。而二叉树的查找效率要比链表高一些,但是二叉树比较消耗空间。
4.LinkedHashSet
该类是HashSet 的子类,该类在原有的父类的基础上,又添加了一个单向链表,用于维护元素被添加的顺序。(即把添加的元素放到了哈希表中,同时把添加的顺序放到了这个单向链表里面去了,所以在遍历的时候,是通过这个链表遍历的)LinkedHashSet就是有序的(添加的顺序),唯一的,可有一个null。
import java.util.LinkedHashSet;
import java.util.Set;
/**
* 测试LinkedHashSet的有序性
*/
public class TestLinkedHashSet{
public static void main(String[] args) {
Set set=new LinkedHashSet();
set.add("Monday");
set.add("Turesday");
set.add("Wednesday");
set.add("Thursday");
set.add("Friday");
System.out.println(set);//[Monday, Turesday, Wednesday, Thursday, Friday]
}
}
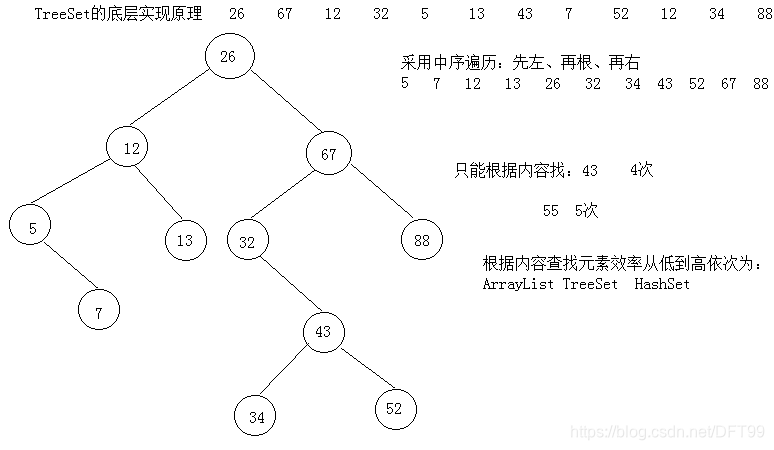
第三节 TreeSet
1.TreeSet底层使用二叉树,元素特点:有序的(升序),唯一的。
2.元素的有序性和唯一性都是由内部比较器或者是外部比较器来保证的。
3.如果比较的结果返回为0,代表当前对象和被比较的对象是想等的,那么当前对象就不被添加了。
4.内部比较器接口:java.lang.Comparable
5.外部比较器接口:java.uitl.Comparator
2.图示
import java.util.Set;
import java.util.TreeSet;
/**
*测试TreeSet元素的有序性
*/
public class TestTreeSet {
public static void main(String[] args) {
Set<Integer> set=new TreeSet<>();
set.add(26);
set.add(67);
set.add(12);
set.add(32);
set.add(5);
set.add(13);
set.add(43);
set.add(7);
set.add(52);
set.add(12);
set.add(34);
set.add(88);
System.out.println(set);//[5, 7, 12, 13, 26, 32, 34, 43, 52, 67, 88]
}
}
说明:1.首先一个二叉树先要有一个根root,把第一个元素放在这个根的位置,然后把所有的比26大的数放在它的右子数上面,把所有比26小的放在它的左子数上面去。以此类推。。。。。。
2.在放入往树中添加元素的时候,涉及到了大量的比较,要么让元素自身实现的内部比较器接口,要么给这个treeSet对象指定外部比较器。
3.TreeSet在遍历的时候采用的是中序遍历(啥叫中序遍历?先左,后根,再右)
4.问:根据内容查找一个元素,利用ArrayList、HashSet、TreeSet效率的排序?
效率由高到底:HashSet(直接定位)—>TreeSet—>---ArrayList
/**
* 测试使用TreeSet容器,要么元素实现内部比较器接口,要么指出外部比较器对象
*/
public class TestTreeSetCompare {
public static void main(String[] args) {
test1();
test2();
}
//使用内部比较器(也就是说我们在创建TreeSet对象的时候,那么TreeSet这个容器里面你放什么,就得让它所对应的类型要实现内部比较器)
public static void test1(){
Set<Stu> set=new TreeSet<>();
set.add(new Stu("小兰",12,100));
set.add(new Stu("小刚3",11,90));
set.add(new Stu("小刚2",11,100));
set.add(new Stu("小刚1",11,90));
set.add(new Stu("小花",13,80));
System.out.println(set);
}
public static void test2(){
//使用外部比较器(使用方法匿名内部类来实现)
Comparator<Stu> com=new Comparator<Stu>() {
@Override
public int compare(Stu o1, Stu o2) {
System.out.println("外部比价器被调用");
int result=o1.getAge()-o2.getAge();
if(result==0){
result=o1.getScore()-o2.getScore();
if(result==0){
result=o1.getName().compareTo(o2.getName());
}
}
return result;
}
};
//使用外部比较器的时候要指定外部比较器对象
Set<Stu> set=new TreeSet<>(com);// 这里面的这个com传给了Set对象的实例成员
set.add(new Stu("小兰",12,100));
set.add(new Stu("小刚3",11,90));
set.add(new Stu("小刚2",11,100));
set.add(new Stu("小刚1",11,90));
set.add(new Stu("小花",13,80));
System.out.println(set);
}
}
class Stu implements Comparable<Stu>{
private String name;
private int age;
private int score;
public Stu(String name, int age, int score) {
this.name = name;
this.age = age;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "\nStu{" +
"name='" + name + '\'' +
", age=" + age +
", score=" + score +
'}';
}
@Override
public int compareTo(Stu o) {
//词句用于测试内部比较器有没有被调用
System.out.println("内部比价器被调用");
int result;
result=this.age-o.getAge();
if(result==0){
result=this.score-o.getScore();
if(result==0){
result=name.compareTo(o.name);
}
}
return result;
}
}
说明:1.如果Student没有重写compareTo()方法,会报错:java.lang.classCastException: Stu cannot be cast to java.lang.Comparable
在每一次进行元素添加的时候,都要进行比较,这种写法( set.add(new Stu(“小兰”,12,100));)的添加用的是内部比较器Comparable,它的比较的方法是CompareTo(),它要把这个Student对象转为Comapable类型,调用它的ComparaTo()方法。但是由于Stu此时还没有继承Comparable接口,所以转不了。因此会报错。
2.这个com进来了给了set对象的实例成员。如下,那么我们看一下源代码:
//(代码片段)
//使用外部比较器的时候要指定外部比较器对象
Set<Stu> set=new TreeSet<>(com);// 这里面的这个com传给了Set对象的实例成员
set.add(new Stu("小兰",12,100));
----------------------------------------------------------------------------------------------------------
//源代码TreeSet
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
//再点TreeMap转到TreeMap的源码:
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
//再点这个comaprator则转到TreeMap里面的实例成员,如下源码:
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
*/
private final Comparator<? super K> comparator;
第四节 HashMap
映射:往map容器中添加元素的过程:map中存放的是键值对对象。(key+value)被封装成了一个Node,添加到映射中。
1.基本使用
得出的结论:key是唯一的,可以有一个null,value可以不唯一,可以有多个null。元素是无序的。
import java.util.HashMap;
import java.util.Map;
/**
* HashMap的一些常用方法
*/
public class TestHashMap {
public static void main(String[] args) {
Map<String,String> map=new HashMap<>();
//添加元素,Map对象中元素key必须是唯一的
//如果后添加的元素key与之前的有相同的,会覆盖掉之前的内容
map.put("cn","China");
map.put("jp","Japan");
map.put("uk","Englind");
map.put("us","America");
map.put("uk","United Kingdom");
map.put("fr","France");
map.put("xjp",null);
map.put(null,"Japan");
map.put(null,null);
//删除 通过key删除包含整个key+value 的Node
map.remove("jp");
map.remove("xjp");
map.remove(null);
//修改
map.put("us","China-1");
//获得
String value=map.get("cn");
System.out.println(value); //打印结果China
//其他方法
//map.containsKey(""); //是否包含了某一个key
// map.clear();
//map.containsValue(""); //是不是包含了某一个value
// map.isEmpty();
//map.size(); //元素个数也就是key的个数
System.out.println(map);
}
}
2.遍历
import java.util.*;
import java.util.Map.Entry;
/**
* HashMap的遍历
*/
public class TestHashMap2 {
public static void main(String[] args) {
Map<String,String> map=new HashMap<>();
//添加元素,Map对象中元素key必须是唯一的
//如果后添加的元素key与之前的有相同的,会覆盖掉之前的内容
map.put("cn","China");
map.put("jp","Japan");
map.put("uk","Englind");
map.put("us","America");
map.put("uk","United Kingdom");
map.put("fr","France");
//遍历
//1.得到所有map中的key
//map中的特点(无序,唯一)就是Set元素的特点
Set<String> set=map.keySet();
Iterator<String> iterator=set.iterator();
while(iterator.hasNext()){
//得到每一个key值
String key=iterator.next();
//通过key的值得到value
String value=map.get(key);
System.out.print(key+"="+value+"\t");
}
System.out.println("\n"); //输出一个换行
//2.通过map中的所有的value 不能通过value找到对应的key
//特点:无序、不唯一
Collection<String> values=map.values();
Iterator<String> it=values.iterator();
while(it.hasNext()){
//得到每一个value,不能找到对应的key
String value=it.next();
System.out.print("value="+value+"\t");
}
System.out.println("\n");//输出一个换行
//3.得到所有的键值对对象,每一个键值对,被称为一个entry(得到的是一个Set对象,里面放的是一堆entry)
//Entry是Map中的一个内部接口。
Set<Entry<String,String>> entries=map.entrySet();
Iterator<Entry<String,String>> it1=entries.iterator();
while(it1.hasNext()){
//得到每一个键值对对象
Entry<String,String> entry=it1.next();
String key=entry.getKey();
}
}
}
| Set<Entry<String,String>> entries=map.entrySet(); |
|---|
注意:这里面Set<Map.Entry<String,String>>,由于Entry是Map的内部接口,所以Idea会提示这个写,但是我们一般写成上面那种,这时候需要导个包进来java.util.Map.Entry进来。
3.往Map 中添加元素的过程
1:将key 和 value 两个对象 生成一个Node对象。将整个Node放到底层的哈希表中。
2:计算 Node 中的 key 的哈希码,然后再经过计算,来确定整个Node 在哈希表中的位置。
3:将整个Node 存入 根据key 计算的 在哈希表中的位置,如果该位置已经有Node了。用当前的Node 的key 和已经存在的Node 的key 进行equals比较。如果key 相等,将原有的Node 中的value 替换为当前的Node 的value。如果key不相等,加链表,新的Node作为链表的头。新的Node 的next指向原来的Node。
4:如果根据key计算的位置还没有Node,那么就直接将Node 存入。
5:**HashMap 中key 的特点就是HashSet 中元素的特点。**无序、唯一、可以有一个null。
我们看一下源码,这个源码我们看的是1.7版本的(由于1.8做了很大的调整,不太好看了):
//HashMap类先看put方法
//首先是类名
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
//中间内容省略
}
-----------------------------------------------------------------------------------------------------------
//先看put()方法
public V put(K key, V value) {
if (key == null) //这一步是进行特殊处理,这里我们就不往里层看了
return putForNullKey(value);
int hash = hash(key); //第一步:计算key的哈希值,我们往里面看一下见下一节代码。
int i = indexFor(hash, table.length); //这个table就是哈希表的一维数组,点进去看一下//又经过计算得到最终在数组里面的存放的位置
//这里还做了个备份,将原有的table[i]值赋值给了e;循环条件e!=null,代表着这里面已经有值了;e.next 代表遍历整个链表
//所以这个循环代表着,如果这里面已经有元素了,遍历整个链表的过程。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {//这行的这个table[i]指一维表里面i位置已经存在Entry
Object k;
//如果数组里面table[i]的哈希值等于向传进来的;并且挡墙的key和传进来的key是同一个,或者是key的内容相等。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {//key相同的怎么办?用新的value把原来的替换掉。
V oldValue = e.value; //这里就是原来的value进行备份
e.value = value; //用新的value将原value替换掉
e.recordAccess(this);
return oldValue; //返回原来的旧value
}
}
modCount++;
addEntry(hash, key, value, i); //如果这个数组位置没有值直接添加就行了
return null;
}
-----------------------------------------------------------------------------------------------------------
//计算key的哈希值
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode(); //得到key的哈希码
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12); //将哈希码进行一系列的运算得到哈希值,经过这个一系列运算之后,才能将哈希码对应到一维数组的范围内区。(但是这个位置还不是最终存在数组里面的位置,还需要计算)
return h ^ (h >>> 7) ^ (h >>> 4);
}
-----------------------------------------------------------------------------------------------------------
transient Entry<K,V>[] table; //HashMap的属性,也就是哈希表的一维数组,table里面放的是Entry
-----------------------------------------------------------------------------------------------------------
//这是HashMap的内部类,上面put()方法中的代码,e.hash == hash,由于就是table[i],那么table[i]是一个Entry对象,将这个对象传入hash()方法中,再通过 对象.hashCode()得到对象的哈希码,再经过一系列的算法得到哈希值。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
-----------------------------------------------------------------------------------------------------------
//从put()方法中点过来的,如果算法计算得到的数组位置没有元素,直接添加就行了。
void addEntry(int hash, K key, V value, int bucketIndex) { //我们要将key和value封装成一个Entry放到bucketIndex这个位置上来
if ((size >= threshold) && (null != table[bucketIndex])) {//这句是判断数组要扩容的,如果我元素的个数大于一个极值(需要扩容的最小值),并且bucketIndex这个位置还不能为空,则扩容。
resize(2 * table.length); //以原来长度的两倍进行扩容
hash = (null != key) ? hash(key) : 0;//扩容以后重新确定位置
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);//点进去看一下
}
-----------------------------------------------------------------------------------------------------------
//创建一个entry
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; //将原位置上的entry做了一个备份,因为后面修改了这个位置上的entry,所以这里要做备份。
table[bucketIndex] = new Entry<>(hash, key, value, e);//这里面的e就是旧entry 的next指向的元素,我们点进去看一下
size++;
}
-----------------------------------------------------------------------------------------------------------
Entry(int h, K k, V v, Entry<K,V> n) { //这里面的n代表着next
value = v;
next = n;
key = k;
hash = h;
}
//以上就是添加的过程。
我们再继续看一下源码:
//HashMap的属性,填充因子等
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f; //填充因子
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table; // entry数组
/**
* The number of key-value mappings contained in this map.
*/
transient int size; //元素个数
说明:DEFAULT_LOAD_FACTOR这个叫默认的填充因子,这个是扩容系数,由于元素的位置是通过hashCode()确定的,所以我们不能保证数组里面的所有的位置都被占用,如果出现极端的请况有可能这里面数组中只有一个元素,然后链表特别长,影响效率,为了避免出现这种请况,出现了一种策略,当数组种的元素被使用的个数和长度的比值大于等于这个填充因子的时候,再往里面加元素就要扩容了。(例如:数组的长度为100,已经用了75个值了,如果再往里面添加元素,这时候需要扩容到200,然后重新散列)
//HashMap类remove()方法的源码(不作为重点)
/**
* Removes and returns the entry associated with the specified key
* in the HashMap. Returns null if the HashMap contains no mapping
* for this key.
*/
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
4.总结
1.HashMap 底层使用哈希表实现。
2.HashMap中存入的元素是一对 键值 对 数据。 这一对数据被封装成了 Entry。一个Entry中包含了key+value+next。
3.将一个Entry存入HashMap的过程,是通过计算entry 中的key 的哈希码来决定的。通过计算key 的哈希码来决定整个Entry 存入哈希表 中的位置。
4.Key的特点是无序的,唯一的,可以有一个null。
5.Value 的特点是无序的,不唯一的,可以有多个null。
6.HashMap中定义了 static final float DEFAULT_LOAD_FACTOR = 0.75f 填充因子,该值是用于 哈希表的扩容的。当一维数组中被使用的元素的个数和数组长度的比值大于等于该值的时候,就需要扩容了,每次扩容为现有长度的2倍。数组的初始长度为16.
7.HashMap中元素的key 的特点和HashSet 中元素的特点一致。
8.在jdk1.8,如果哈希表中的链表的长度超过了8,那么链表将被转换为二叉树存储元素。来提升访问元素的效率。
HashSet 的底层实现是使用了HashMap 只使用了HashMap 的key 部分。HashMap key 的特点就是HashSet 元素的特点。HashSet 中 使用的HashMap 的 元素的value 是一个final static Object 对象。所有的key 共用了一个value。来达到节省内存的目的。
今日练习:
1:自定义一个方法,该方法实现获得一个随机的小写字符。
2:通过调用上面的方法,实现算法:在某种类型的容器中只保留 26 个英文小写字母。不能存在重复的字符的算法。
3:大活:使用合适的容器实现学生管理系统。
学生属性:学号,名字,年龄,性别。
实现的功能:
遍历所有学生信息
添加学生信息
根据学号查找学生
根据名字查找学生
根据学号删除学生
根据学号修改学生

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









