



 本文精选了多个行业的研究报告,覆盖高端猎头、在线语言教育、菜谱app、搜索引擎、二手车电商、在线旅游、教育培训、招商加盟、浏览器app、基因检测、电子商务、智能手机等行业,提供了丰富的市场洞察。
本文精选了多个行业的研究报告,覆盖高端猎头、在线语言教育、菜谱app、搜索引擎、二手车电商、在线旅游、教育培训、招商加盟、浏览器app、基因检测、电子商务、智能手机等行业,提供了丰富的市场洞察。











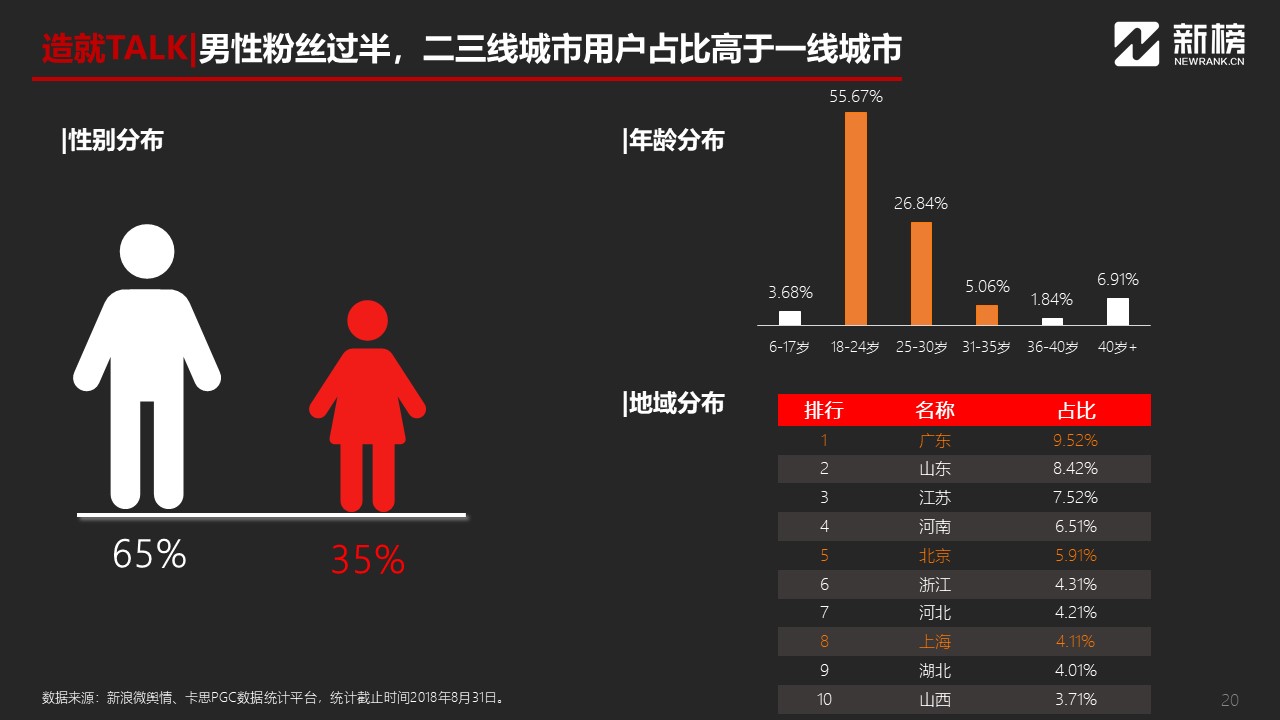


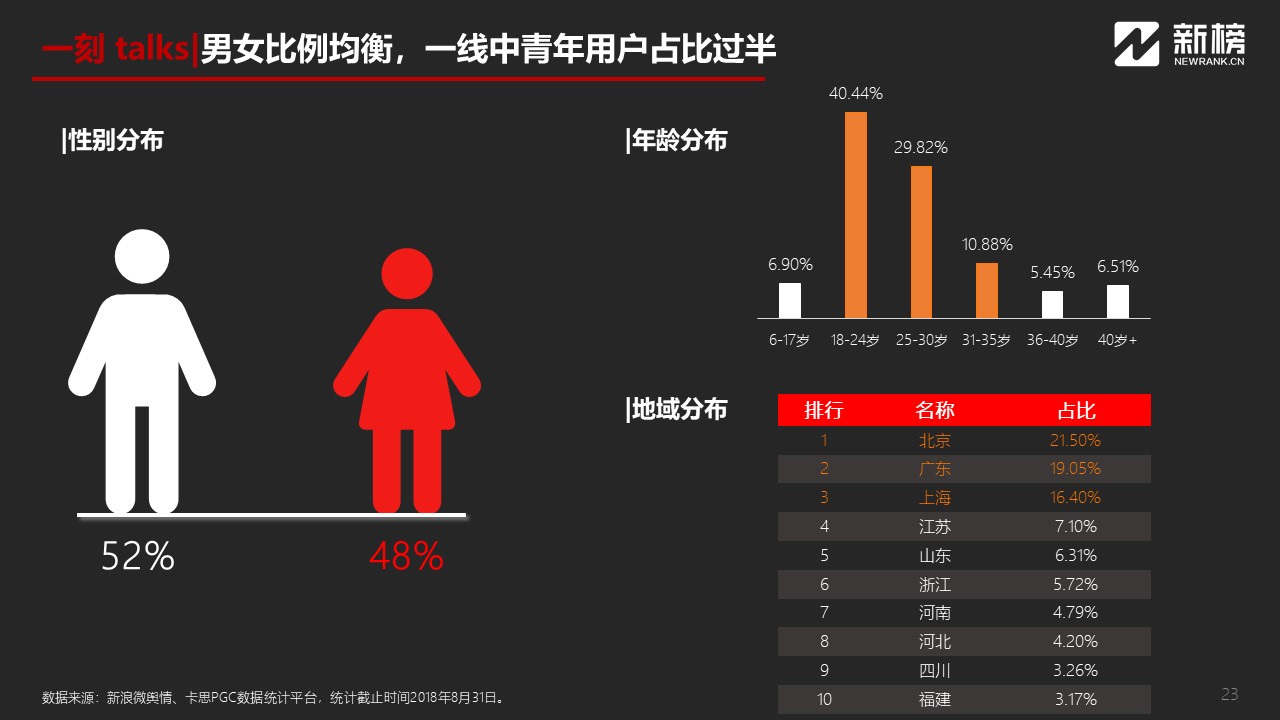



由
新
更多阅读:
- 艾瑞咨询:2016年中国高端猎头行业研究报告(附下载)
- 有道学堂&艾瑞咨询:2015年中国在线语言教育行业研究报告
- 极光大数据:菜谱app行业研究报告
- Cnnic:2011年中国搜索引擎市场研究报告
- 艾瑞咨询:2018年中国二手车电子商务行业研究报告(附下载)
- 艾瑞咨询:2018年中国在线旅游度假行业研究报告(附下载)
- MobData:2018教育培训行业研究报告(附下载)
- 360:2018招商加盟行业研究报告(附下载)
- 极光大数据:2017年12月浏览器app行业研究报告
- 鲸准: 2018基因检测行业研究报告(附下载)
- 新浪:2017中国电子商务行业研究报告(附下载)
- 极光大数据:2018年Q2智能手机行业研究报告(附下载)
- 一本智库:2018现金贷行业研究报告(附下载)
- MobData:K12教育行业研究报告
- 极光大数据:2017年Q4智能手机行业研究报告


















 2805
2805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









