




强化学习(四)—— Actor-Critic
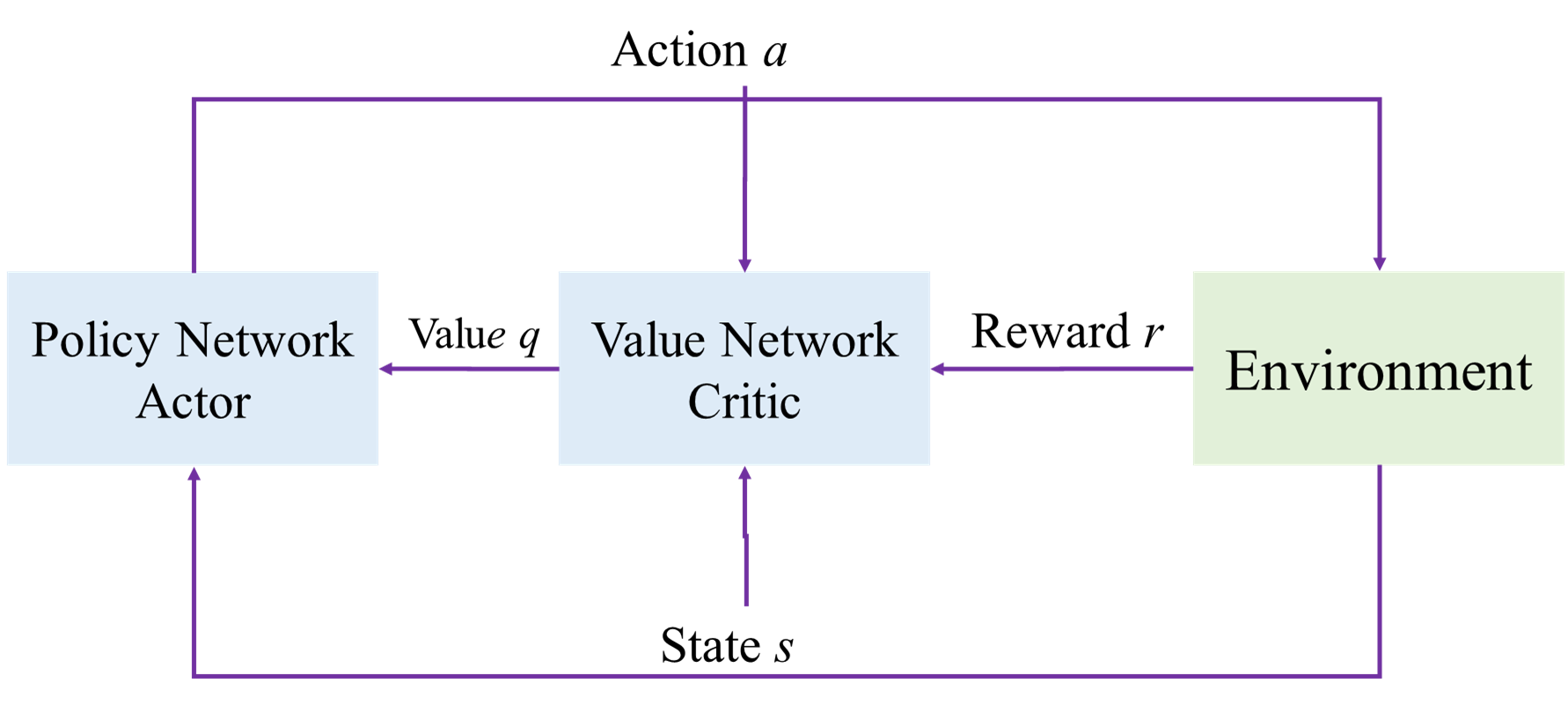
1. 网络结构
-
状态价值函数:
V π ( s t ) = ∑ a Q π ( s t , a ) ⋅ π ( a ∣ s t ) V_\pi(s_t)=\sum_aQ_\pi(s_t,a)\cdot\pi(a|s_t) Vπ(st)=a∑Qπ(st,a)⋅π(a∣st) -
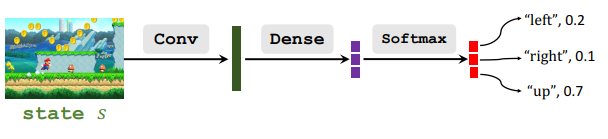
通过策略网络近似策略函数:
π ( a ∣ s ) ≈ π ( a ∣ s ; θ ) \pi(a|s)\approx\pi(a|s;\theta) π(a∣s)≈π(a∣s;θ)
-
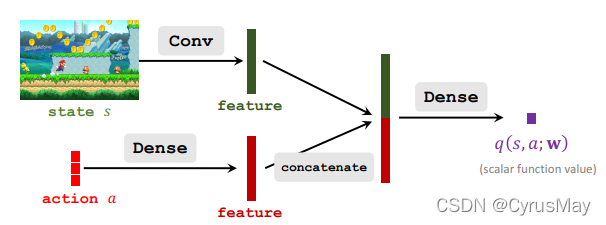
通过价值网络近似动作价值函数:
q ( s , a ; W ) ≈ Q ( s , a ) q(s,a;W)\approx Q(s,a) q(s,a;W)≈Q(s,a)
-
神经网络近似后的状态价值函数:
V ( s ; θ , W ) = ∑ a q ( s , a ; W ) ∗ π ( a ∣ s ; θ ) V(s;\theta ,W)=\sum_aq(s,a;W)*\pi(a|s;\theta) V(s;θ,W)=a∑q(s,a;W)∗π(a∣s;θ) -
通过对策略网络不断更新以增加状态价值函数值。
-
通过对价值网络不断更新来更好的预测所获得的回报。
2. 网络函数
Policy Network
- 通过策略网络近似策略函数
π ( a ∣ s t ) ≈ π ( a ∣ s t ; θ ) π(a|s_t)≈π(a|s_t;\theta) π(a∣st)≈π(a∣st;θ) - 状态价值函数及其近似
V π ( s t ) = ∑ a π ( a ∣ s t ) Q π ( s t , a ) V_π(s_t)=\sum_aπ(a|s_t)Q_π(s_t,a) Vπ(st)=a∑π(a∣st)Qπ(st,a)
V ( s t ; θ ) = ∑ a π ( a ∣ s t ; θ ) ⋅ Q π ( s t , a ) V(s_t;\theta)=\sum_aπ(a|s_t;\theta)·Q_π(s_t,a) V(st;θ)=a∑π(a∣st;θ)⋅Qπ(st,a) - 策略学习最大化的目标函数
J ( θ ) = E S [ V ( S ; θ ) ] J(\theta)=E_S[V(S;\theta)] J(θ)=ES[V(S;θ)] - 依据策略梯度上升进行
θ ← θ + β ⋅ ∂ V ( s ; θ ) ∂ θ \theta\gets\theta+\beta·\frac{\partial V(s;\theta)}{\partial \theta} θ←
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









